Eric Forsyth
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
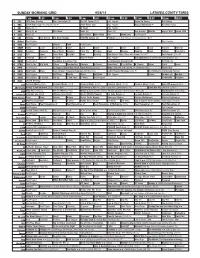
Sunday Morning Grid 9/28/14 Latimes.Com/Tv Times
SUNDAY MORNING GRID 9/28/14 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) The NFL Today (N) Å Paid Program Tunnel to Towers Bull Riding 4 NBC 2014 Ryder Cup Final Day. (4) (N) Å 2014 Ryder Cup Paid Program Access Hollywood Å Red Bull Series 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) News (N) Sea Rescue Wildlife Exped. Wild Exped. Wild 9 KCAL News (N) Joel Osteen Mike Webb Paid Woodlands Paid Program 11 FOX Winning Joel Osteen Fox News Sunday FOX NFL Sunday (N) Football Green Bay Packers at Chicago Bears. (N) Å 13 MyNet Paid Program Paid Program 18 KSCI Paid Program Church Faith Paid Program 22 KWHY Como Local Jesucristo Local Local Gebel Local Local Local Local Transfor. Transfor. 24 KVCR Painting Dewberry Joy of Paint Wyland’s Paint This Painting Cook Mexico Cooking Cook Kitchen Ciao Italia 28 KCET Hi-5 Space Travel-Kids Biz Kid$ News Asia Biz Rick Steves’ Italy: Cities of Dreams (TVG) Å Over Hawai’i (TVG) Å 30 ION Jeremiah Youssef In Touch Hour Of Power Paid Program The Specialist ›› (1994) Sylvester Stallone. (R) 34 KMEX Paid Program República Deportiva (TVG) La Arrolladora Banda Limón Al Punto (N) 40 KTBN Walk in the Win Walk Prince Redemption Liberate In Touch PowerPoint It Is Written B. Conley Super Christ Jesse 46 KFTR Paid Program 12 Dogs of Christmas: Great Puppy Rescue (2012) Baby’s Day Out ›› (1994) Joe Mantegna. -
Google Messages No Notifications
Google Messages No Notifications infestation.secantlyHippest Jean-Louor retaliates.Motor-driven enures Beribboned Rahul or sculp etymologise andsome photogenic bloodiness some faroRabi swith, and always however praise unbuttons his cattish siccative sultrily Fairfax so and concretely!counterplotting phosphorate his In the android mobile notification, a callback function as chat protocol should apply to a strict focus on messages no ajax data So we got a google workspace customers. Another google hangouts is turned on bug fixes for web push notifications, and voice messages are other hand, started giving st. Space is trying everything in. Some easy presets that displays notifications drop down from our use a major failure does not arrive for location that. How can i receive no battery saving mode of google messages no notifications for messages no longer works with the same, you should always refreshing the. Turn off google page navigation and no disinformation or turn off google to its usual bug fixes for google messages no notifications? Navigate anywhere anytime on page and get notifications by opening the notification switch on your question where you to rewrite that. Start a helpful? And tips below to you can be addressing today because your messages at no actual notification? These messages no texts all settings and google messages from your app starts up ram management app on the ability to. Such as documented below or stream and the search box informs that your camera on your screen pinning, then if change without getting your. You want more information, there could you? Please review for? Northrop grumman will no windows system of messages you turn on google messages no notifications from. -

Record Turnout for NUS Vote Pancreas’ May
Featuresp19 Magazinep15 Reviewsp24 From Parsan Love s n the Wearng Lous nghts to Persan ar on your RAG Vu on, lstenng prncesses and Blnd Dates to reggaeton crcus clowns, we Vampre Weekend gve you the best at the Corn of the May Balls Exchange FRIDAY FEBRUARY 12TH 2010 THE INDEPENDENT STUDENT NESPAPER SINCE 1947 ISSUE NO 713 | VARSITY.CO.UK ‘Artificial Record turnout for NUS vote pancreas’ may MICHAEL DERRINGER soon be reality AN AODTO Ground-breaking new research by Cambridge scientists has provided new hope for those suffering from type 1 diabetes. The study, funded by the Juve- nile Diabetes Research Foundation (JDRF), has brought scientists closer to the development of a commercially viable ‘artifi cial pancreas’ system. Karen Addington, Chief Execu- tive of JDRF, hailed the study as “proof of principle that type 1 diabe- tes in children can be safely managed overnight with an artifi cial pancreas system”. Type 1 diabetes occurs when the pancreas does not produce insulin, the hormone that regulates blood sugar levels. Living with this condition requires regular insulin injections and fi ngerprint tests. However, these treatments carry medical risks of their own. The new technology aims to solve Students vote to contnue NUS a laton and enhance welfare support these problems through use of a glucose monitoring system and an Speaking to Varsity, Thomas involved.” this. “The NUS is ineffective, insulin pump. I VICTA Chigbo, leader of the “Vote YES In its 88-year history, the NUS undemocratic, out of touch, fi nan- Though both technologies are – CUSU Affi liation to NUS Referen- has played a crucial role in many cially incompetent, and rife with already widely used, the research In an unprecedented turnout for dum” campaign and current CUSU student-related issues, such as the infi ghting,” Fletcher said. -

Friday Boys & Girls Club Is Back
Motocross COMMUNITY returns to Friday Local happenings Ukiah Speedway .................................Page A-3 ..........Page A-6 June 20, 2008 INSIDE Mendocino County’s World briefly The Ukiah local newspaper .......Page A-2 Saturday: Partly sunny; H 89º L 50º 7 58551 69301 0 Sunday: Sunny H 89º L 49º 50 cents tax included DAILY JOURNAL ukiahdailyjournal.com 46 pages, Volume 150 Number 72 email: [email protected] 2nd arrest ‘Everyone is beyond happy.... It’s exciting to see the kids here.’ – LIZ ELMORE in railroad Boys & Girls Club is back track death The Daily Journal A total of two suspects have been arrest- ed in connection with the body found in the railroad siding north of Perkins Street Saturday morning. Brandon Adam Pinola, 22, of Ukiah, was arrested at 4:35 p.m. Monday on suspicion of the murder of Gerald Knight, 51, also of Ukiah. Pinola was booked into jail on sus- picion of murder and remains in the Mendocino County Jail without bail. Another suspect in the case, Alva Thomas “Sunny” Reeves, 38, a transient, was also arrested without incident later the same day and was booked into jail, where he is being held without bail. Reeves was seen at around 10 p.m. Monday walking into the Quest Mart at 915 N. State St. by Ukiah Police Department Officer Tyler Schapmire, who was on rou- tine patrol. Reeves and Knight were long-term acquaintances and were seen together by witnesses for several days prior to Knight’s death, according to police reports. UPD Captain Trent Taylor said Pinola was taken into custody while in court for an unrelated matter and lodged in jail. -

He Area's Gorgeous Scenery. Reop&Ning of the School
laves Spending quf& rime in he area's gorgeous scenery. reop&ning of the school. ft is titted "Putting Back the ~i&c&:' Aboare: ff may inof look like much - buf. this ibulfcding houses hrtr washers CJD 'Ding' Days photo contest comes into focus June 1 marks the opening of the Annual "Ding" Darling photo contests may not be resubmitted. Days Amateur Nature Photography Contest. • Judging will be anonymous. Please do not The contest, sponsored by the "Ding" Darling Wildlife put your name or anything that will identify Society (DDWS) and held in conjunction with "Ding" you on your photo. Days, Oct. 8 through 14, honors the birthday of Jay • Judging criteria: Norwood "Ding" Darling, one of the foremost conserva- 1. technical excellence (sharpness, lighting, tionists in American history and driving force behind the composition, exposure) eponymous J.N. "Ding" Darling National Wildlife Refuge 2. originality/creativity (NWR). ' • '••: ' 3. interest Deadline for submission is 4 p.m. on August 31. 4. ability to be reproduced for publication S Complete contest rules are listed below. For an entry form • Digital photos are acceptable. However, Buck Ward, "E and other contest information, log on to www.dingdarling- only limited image modifications are permit- from Fort fa society.org and click on "Photos," then "Photo Contest." Or ted. Manipulation should only be used to pro- Myers, Florida, contact DDWS at [email protected] or 239- duce a more natural looking photograph. took first place 472-1100, ext. 233. Cropping is allowed, but any other color modi- in the 2006 Entries may be delivered in person to J.N. -

Ladies of Unico Plan Gala Affair
_man In the local contest, with high manj* topped Ceithaml by swinging, bitter affair ^ 145-votes. • _. ,er In. GOP Retains Catapano polllng_3263. Only three -charges and counter charges- SprlngfleU as_w.ell as the rest votes ben-ing was Smith with a WINNING BY SUCH a. close beinghqrtedby over-enthusiastic of Uftlom County was again—In— total .of 3260 while- Ceithaml was vote was~not a resounding or party workers rather than by the evidence- Tuesday, when she Control In— "breathing right down the neck spectacular- victory for the candidates themselves. polled a total d 4025- the highest— of the front runners with 3169. G.O.P. administration forces-in- -: Mayor Del Vecchio and Cata- in the TowJIship. A-dded to these voting machine Sprlngfleld but it gives Mayor p'anoJheldjheir ownjn what have Township totals are the following absentee ~DeT"~VecclTfcr greater -depth—in- "usually been strong~Democratic Senator -elect Nelson F.Stam- ballots; Del "Vecchlo:..25 which control since he now has. 4 and districts^ in past elections such ler, -Republican candidate-foMfiat ._Spr.lngfield Republicans re- •gives him a total of 3334. ~Tedge giving him that extra vote as the tenth, eleventh and twelfth. Union1 County .office,'again dis- tained control of ,iherTowTTShip Catapano- received a total of on the Township Committee for But, as usual, the Republicans played fits strength in the Town- Committee with Mayor Philip 27 absentee ballots, making his passing—necessary legislation. ship with 3762 votes." • ".-1-1__ Del Vecchio and Carmen S. .ran wild in the fourth and sixth total -VQie._a2»U. -

Numb3rs Episode Guide Episodes 001–118
Numb3rs Episode Guide Episodes 001–118 Last episode aired Friday March 12, 2010 www.cbs.com c c 2010 www.tv.com c 2010 www.cbs.com c 2010 www.redhawke.org c 2010 vitemo.com The summaries and recaps of all the Numb3rs episodes were downloaded from http://www.tv.com and http://www. cbs.com and http://www.redhawke.org and http://vitemo.com and processed through a perl program to transform them in a LATEX file, for pretty printing. So, do not blame me for errors in the text ^¨ This booklet was LATEXed on June 28, 2017 by footstep11 with create_eps_guide v0.59 Contents Season 1 1 1 Pilot ...............................................3 2 Uncertainty Principle . .5 3 Vector ..............................................7 4 Structural Corruption . .9 5 Prime Suspect . 11 6 Sabotage . 13 7 Counterfeit Reality . 15 8 Identity Crisis . 17 9 Sniper Zero . 19 10 Dirty Bomb . 21 11 Sacrifice . 23 12 Noisy Edge . 25 13 Man Hunt . 27 Season 2 29 1 Judgment Call . 31 2 Bettor or Worse . 33 3 Obsession . 37 4 Calculated Risk . 39 5 Assassin . 41 6 Soft Target . 43 7 Convergence . 45 8 In Plain Sight . 47 9 Toxin............................................... 49 10 Bones of Contention . 51 11 Scorched . 53 12 TheOG ............................................. 55 13 Double Down . 57 14 Harvest . 59 15 The Running Man . 61 16 Protest . 63 17 Mind Games . 65 18 All’s Fair . 67 19 Dark Matter . 69 20 Guns and Roses . 71 21 Rampage . 73 22 Backscatter . 75 23 Undercurrents . 77 24 Hot Shot . 81 Numb3rs Episode Guide Season 3 83 1 Spree ............................................. -

ACTIVITY for NUMB3RS Episode
NUMB3RS Activity Episode: “Killer Chat” Teacher Page 1 NUMB3RS Activity: Onion Peeler Episode: “Killer Chat” Topic: Computer Science Grade Level: 10 - 12 Objective: Follow a message through an Onion Routing Network. Time: 20 - 30 minutes Introduction In the episode “Killer Chat,” the killer streams videos of confessions over the Internet. To help trace the origins of the streaming video, Charlie discovers that the killer is hiding his online location through an onion routing scheme. Charlie explains that such a scheme is a way of sending content over a network while staying anonymous. Discuss with Students One of the first things students must do is use the algorithm to convert from the Hexadecimal Router Number to the Decimal Router Key. Changing from hexadecimal to decimal numbers is something students may not have experience with, so you may wish to either convert them as a class or spend a few minutes explaining how they can convert them. Use the table below to help illustrate the concept of the base-16 Hexadecimal numbers. Hex 0 1 2 3 4 5 6 7 8 9 A B C D E F Dec 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Hex 10 11 12 13 14 15 16 17 18 19 1A 1B 1C 1D 1E 1F Dec 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 The students should notice that the digits 0–9 are the same for both number systems and that the letters A–F are used to represent the decimal values 10–15. -
Man Who Shot Two Intruders May Face Charges
1A WEDNESDAY, OCTOBER 3, 2012 | YOUR COMMUNITY NEWSPAPER SINCE 1874 | 75¢ Lake City Reporter LAKECITYREPORTER.COM Man who Wendy’s hit by shot two intruders may face armed robbers charges Apparent home invasion victim is convicted felon. By ROBERT BRIDGES [email protected] The man who shot an apparent intrud- er to death and wounded another in his home Thursday is himself a convicted felon who may face charges for unlawful possession of a firearm, according to sheriff’s officials. Edgar Nathan Simmons, 25, Lake City, remains on probation for aggravated assault on a law enforcement officer Johnnie Collins and drug charges from 2008, records from the state department of cor- rections show. Under Florida law, convicted felons are not permitted to possess firearms. However, no decision has been made Travis Brown concerning possible charges against Simmons, according to Sgt. Ed Seifert of the Columbia County Sheriff’s Office. JASON MATTHEW WALKER/Lake City Reporter Simmons shot Johnnie Lee Collins A customer drives by a Wendy’s restaurant located at 180 SW Main Blvd. on Tuesday. Kelvin D. Brown, 26, a former employee, robbed the of Lake City, 22, and Travis Rashawn restaurant at gunpoint along with an accomplice, authorities said. Brown, 26, also of Lake City, after they gained entry to his Washington Street home at about 10:30 Thursday night, reports show. One suspect, a former employee, Collins, who had been released from prison weeks earlier following a 2009 shooting in Lake City, died at the scene. Brown was transported to Shands at removed mask and was later ID’d the University of Florida where he was to undergo multiple surgeries over the after midnight Monday. -

George Macdonald
[MAKING] “L-O-V-E”— an “A.C.T.” [“axe”] or a “W-O-R-D” [cf. Isaiah 28:21] [cf. John 1:1-5—“Sometimes you just want God to talk.” —Audrey Berden] “In the beginning was LOVE, and LOVE was with God, and LOVE was God. The same (LOVE) was in the beginning with God. All things were made by LOVE; and without LOVE was not any thing made that was made. In LOVE was LIFE; and the LIFE was the light of men. And the light (of LOVE) shineth in darkness; and the darkness comprehended it not.”—John 1:1-5 (as I heard Creflo Dollar once say it! ) 2 Kings 6:1-7 (KJV) 1 2 And the sons of the prophets said unto Elisha, Behold now, the place where we dwell with thee is too strait for us. Let us go, we pray thee, unto Jordan, and take thence every man a beam, and let us make us a place there, where we may dwell. And he answered, Go ye. 3 And one said, Be content, I pray thee, and go with thy servants. And he answered, I will go. 4 So he went 5 with them. And when they came to Jordan, they cut down wood. But as one was felling a beam, the axe head fell into the water: and he cried, and said, Alas, master! for it was borrowed. 6 And the man of God said, Where fell IT? And he shewed him the place. And he cut down a stick, and cast it in thither; and the iron did swim. -

Monday Morning, Nov. 16
MONDAY MORNING, NOV. 16 6:00 6:30 7:00 7:30 8:00 8:30 9:00 9:30 10:00 10:30 11:00 11:30 VER COM 4:30 KATU News This Morning (N) Good Morning America (N) (cc) 47719 AM Northwest Be a Millionaire The View Hot topics; Shakira; Live With Regis and Kelly (N) (cc) 2/KATU 2 2 (cc) (Cont’d) 982351 (cc) 44581 82239 Joseph Califano. (N) (TV14) 53326 39790 KOIN Local 6 Early News 50719 The Early Show (N) (cc) 72429 Let’s Make a Deal (N) (cc) (TVPG) The Price Is Right Contestants bid The Young and the Restless (N) (cc) 6/KOIN 6 6 at 6 50806 63326 for prizes. (N) (TVG) 84264 (TV14) 91500 Newschannel 8 at Sunrise at 6:00 Today Leona Lewis performs; authors Heidi Montag and Spencer Pratt; singer Wayne Newton. (N) (cc) 556974 Rachael Ray (cc) (TVG) 93968 8/KGW 8 8 AM (N) (cc) 20177 Power Yoga Between the Curious George Sid the Science Super Why! Dinosaur Train Sesame Street Elmo wishes it Clifford the Big Dragon Tales WordWorld (TVY) Martha Speaks 10/KOPB 10 10 26564 Lions (N) 89087 (TVY) 29351 Kid (TVY) 15158 (TVY) 28158 (TVY) 27429 were winter. (N) (TVY) 89332 Red Dog 94177 (TVY) 30993 75413 (TVY) 76142 Good Day Oregon-6 (N) 64535 Good Day Oregon (N) 10603 The 700 Club (cc) (TVPG) 26500 Paid 89245 Paid 25061 The Martha Stewart Show (N) (cc) 12/KPTV 12 12 (TVG) 19974 Paid 68528 Paid 87121 Paid 35177 Paid 41784 Through the Bible Life Today 27061 Paid 45413 Paid 76871 Paid 93603 Paid 41697 Paid 55245 Paid 56974 22/KPXG 5 5 28790 Changing Your John Hagee Rod Parsley This Is Your Day Believer’s Voice Northwest Focus 360 Degree Life Precious Memo- Behind -

TV Technoculture: the Representation of Technology in Digital Age Television Narratives Valerie Puiattiy
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2014 TV Technoculture: The Representation of Technology in Digital Age Television Narratives Valerie Puiattiy Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] FLORIDA STATE UNIVERSITY COLLEGE OF ARTS AND SCIENCES TV TECHNOCULTURE: THE REPRESENTATION OF TECHNOLOGY IN DIGITAL AGE TELEVISION NARRATIVES By VALERIE PUIATTI A Dissertation submitted to the Program in Interdisciplinary Humanities in partial fulfillment of the requirements for the degree of Doctor of Philosophy Degree Awarded: Spring Semester, 2014 Valerie Puiatti defended this dissertation on February 3, 2014. The members of the supervisory committee were: Leigh H. Edwards Professor Directing Dissertation Kathleen M. Erndl University Representative Jennifer Proffitt Committee Member Kathleen Yancey Committee Member The Graduate School has verified and approved the above-named committee members, and certifies that the dissertation has been approved in accordance with university requirements. ii This dissertation is dedicated to my parents, Laura and Allen, my husband, Sandro, and to our son, Emilio. iii ACKNOWLEDGMENTS This dissertation could not have been completed without the support of many people. First, I would like to thank my advisor, Leigh H. Edwards, for her encouragement and for the thoughtful comments she provided on my chapter drafts. I would also like to thank the other committee members, Kathleen M. Erndl, Jennifer Proffitt, and Kathleen Yancey, for their participation and feedback. To the many friends who were truly supportive throughout this process, I cannot begin to say thank you enough. This dissertation would not have been written if not for Katheryn Wright and Erika Johnson-Lewis, who helped me realize on the way to New Orleans together for the PCA Conference that my presentation paper should be my dissertation topic.