Proposal to Encode a Kana Character for Transcription of Late Middle Japanese
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Man'yogana.Pdf (574.0Kb)
Bulletin of the School of Oriental and African Studies http://journals.cambridge.org/BSO Additional services for Bulletin of the School of Oriental and African Studies: Email alerts: Click here Subscriptions: Click here Commercial reprints: Click here Terms of use : Click here The origin of man'yogana John R. BENTLEY Bulletin of the School of Oriental and African Studies / Volume 64 / Issue 01 / February 2001, pp 59 73 DOI: 10.1017/S0041977X01000040, Published online: 18 April 2001 Link to this article: http://journals.cambridge.org/abstract_S0041977X01000040 How to cite this article: John R. BENTLEY (2001). The origin of man'yogana. Bulletin of the School of Oriental and African Studies, 64, pp 5973 doi:10.1017/S0041977X01000040 Request Permissions : Click here Downloaded from http://journals.cambridge.org/BSO, IP address: 131.156.159.213 on 05 Mar 2013 The origin of man'yo:gana1 . Northern Illinois University 1. Introduction2 The origin of man'yo:gana, the phonetic writing system used by the Japanese who originally had no script, is shrouded in mystery and myth. There is even a tradition that prior to the importation of Chinese script, the Japanese had a native script of their own, known as jindai moji ( , age of the gods script). Christopher Seeley (1991: 3) suggests that by the late thirteenth century, Shoku nihongi, a compilation of various earlier commentaries on Nihon shoki (Japan's first official historical record, 720 ..), circulated the idea that Yamato3 had written script from the age of the gods, a mythical period when the deity Susanoo was believed by the Japanese court to have composed Japan's first poem, and the Sun goddess declared her son would rule the land below. -

Download Free Chinese Fonts for Mac
1 / 4 Download Free Chinese Fonts For Mac ttc and Songti ttc and include TC fonts Hiragino Sans GB ~ Beginning with OS X 10.. 01[?]KaiTi楷体GB18030simkai ttfv5 01[?]FangSong_GB2312仿宋_GB2312GB2312SIMFANG.. [NEED MORE DETAILS HERE] [DISCUSSION OF WEB FONTS AND CSS3]Arphic [文鼎]Taiwan.. If you want to use this font for both simplified and traditional Chinese, then use Font Book to deactivate BiauKai and activate DFKai-SB instead.. ttf file and select install MacOS X (10 3 or later)Double-click on the ttf file and select install.. West is an IRG participant as a member of the UK delegation, so he is well-informed and up-to-date on the progress of their work, and his fonts reflect that knowledge. In addition, the Microsoft Office XP Proofing Tools (and Chinese editions) include the font Simsun (Founder Extended) [SURSONG.. A long time vendor of Chinese OEM fonts, in 2006 Monotype's new owners [Monotype Imaging] also acquired China Type Design [中國字體設計] in Hong Kong.. For the character sets and weights for each, see the Fonts section for your OS: 10.. If you have downloaded a font that is saved in Free Chinese Fonts Free Chinese Font is all about Chinese fonts that are free to download! This site aims to help you download high quality Chinese fonts in.. FamilyFile nameCharsetOS 910 310 410 510 610 710 810 1010 11PingFang SC PingFang HK PingFang TCPingFang.. Font files had to be converted between Windows and Macintosh Regardless, all TrueType fonts contain 'cmap' tables that map its glyphs to various encodings. chinese fonts chinese fonts, chinese fonts generator, chinese fonts download, chinese fonts copy and paste, chinese fonts google docs, chinese fonts dafont, chinese fonts adobe, chinese fonts in microsoft word, chinese fonts word, chinese fonts calligraphy Arial Unicode MS ~ Beginning with OS X 10 5, Apple includes this basic Monotype Unicode font from Microsoft Office [Arial Unicode. -

Handy Katakana Workbook.Pdf
First Edition HANDY KATAKANA WORKBOOK An Introduction to Japanese Writing: KANA THIS IS A SUPPLEMENT FOR BEGINNING LEVEL JAPANESE LANGUAGE INSTRUCTION. \ FrF!' '---~---- , - Y. M. Shimazu, Ed.D. -----~---- TABLE OF CONTENTS Page Introduction vi ACKNOWLEDGEMENlS vii STUDYSHEET#l 1 A,I,U,E, 0, KA,I<I, KU,KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #1 2 PRACTICE: A, I,U, E, 0, KA,KI, KU,KE, KO, GA,GI,GU, GE,GO, N WORKSHEET #2 3 MORE PRACTICE: A, I, U, E,0, KA,KI,KU, KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #~3 4 ADDmONAL PRACTICE: A,I,U, E,0, KA,KI, KU,KE, KO, GA,GI,GU,GE,GO, N STUDYSHEET #2 5 SA,SHI,SU,SE, SO, ZA,JI,ZU,ZE,ZO, TA, CHI, TSU, TE,TO, DA, DE,DO WORI<SHEEI' #4 6 PRACTICE: SA,SHI,SU,SE, SO, ZA,II, ZU,ZE,ZO, TA, CHI, 'lSU,TE,TO, OA, DE,DO WORI<SHEEI' #5 7 MORE PRACTICE: SA,SHI,SU,SE,SO, ZA,II, ZU,ZE, W, TA, CHI, TSU, TE,TO, DA, DE,DO WORKSHEET #6 8 ADDmONAL PRACI'ICE: SA,SHI,SU,SE, SO, ZA,JI, ZU,ZE,ZO, TA, CHI,TSU,TE,TO, DA, DE,DO STUDYSHEET #3 9 NA,NI, NU,NE,NO, HA, HI,FU,HE, HO, BA, BI,BU,BE,BO, PA, PI,PU,PE,PO WORKSHEET #7 10 PRACTICE: NA,NI, NU, NE,NO, HA, HI,FU,HE,HO, BA,BI, BU,BE, BO, PA, PI,PU,PE,PO WORKSHEET #8 11 MORE PRACTICE: NA,NI, NU,NE,NO, HA,HI, FU,HE, HO, BA,BI,BU,BE, BO, PA,PI,PU,PE,PO WORKSHEET #9 12 ADDmONAL PRACTICE: NA,NI, NU, NE,NO, HA, HI, FU,HE, HO, BA,BI,3U, BE, BO, PA, PI,PU,PE,PO STUDYSHEET #4 13 MA, MI,MU, ME, MO, YA, W, YO WORKSHEET#10 14 PRACTICE: MA,MI, MU,ME, MO, YA, W, YO WORKSHEET #11 15 MORE PRACTICE: MA, MI,MU,ME,MO, YA, W, YO WORKSHEET #12 16 ADDmONAL PRACTICE: MA,MI,MU, ME, MO, YA, W, YO STUDYSHEET #5 17 -
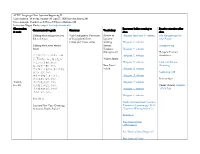
ALTEC Language Class: Japanese Beginning II
ALTEC Language Class: Japanese Beginning II Class duration: 10 weeks, January 28–April 7, 2020 (no class March 24) Class meetings: Tuesdays at 5:30pm–7:30pm in Hellems 145 Instructor: Megan Husby, [email protected] Class session Resources before coming to Practice exercises after Communicative goals Grammar Vocabulary & topic class class Talking about things that you Verb Conjugation: Past tense Review of Hiragana Intro and あ column Fun Hiragana app for did in the past of long (polite) forms Japanese your Phone (~desu and ~masu verbs) Writing Hiragana か column Talking about your winter System: Hiragana song break Hiragana Hiragana さ column (Recognition) Hiragana Practice クリスマス・ハヌカー・お Hiragana た column Worksheet しょうがつ 正月はなにをしましたか。 Winter Sports どこにいきましたか。 Hiragana な column Grammar Review なにをたべましたか。 New Year’s (Listening) プレゼントをかいましたか/ Vocab Hiragana は column もらいましたか。 Genki I pg. 110 スポーツをしましたか。 Hiragana ま column だれにあいましたか。 Practice Quiz Week 1, えいがをみましたか。 Hiragana や column Jan. 28 ほんをよみましたか。 Omake (bonus): Kasajizō: うたをききましたか/ Hiragana ら column A Folk Tale うたいましたか。 Hiragana わ column Particle と Genki: An Integrated Course in Japanese New Year (Greetings, Elementary Japanese pgs. 24-31 Activities, Foods, Zodiac) (“Japanese Writing System”) Particle と Past Tense of desu (Affirmative) Past Tense of desu (Negative) Past Tense of Verbs Discussing family, pets, objects, Verbs for being (aru and iru) Review of Katakana Intro and ア column Katakana Practice possessions, etc. Japanese Worksheet Counters for people, animals, Writing Katakana カ column etc. System: Genki I pgs. 107-108 Katakana Katakana サ column (Recognition) Practice Quiz Katakana タ column Counters Katakana ナ column Furniture and common Katakana ハ column household items Katakana マ column Katakana ヤ column Katakana ラ column Week 2, Feb. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

Legacy Character Sets & Encodings
Legacy & Not-So-Legacy Character Sets & Encodings Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/cjkv/unicode/iuc15-tb1-slides.pdf Tutorial Overview dc • What is a character set? What is an encoding? • How are character sets and encodings different? • Legacy character sets. • Non-legacy character sets. • Legacy encodings. • How does Unicode fit it? • Code conversion issues. • Disclaimer: The focus of this tutorial is primarily on Asian (CJKV) issues, which tend to be complex from a character set and encoding standpoint. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations dc • GB (China) — Stands for “Guo Biao” (国标 guóbiâo ). — Short for “Guojia Biaozhun” (国家标准 guójiâ biâozhün). — Means “National Standard.” • GB/T (China) — “T” stands for “Tui” (推 tuî ). — Short for “Tuijian” (推荐 tuîjiàn ). — “T” means “Recommended.” • CNS (Taiwan) — 中國國家標準 ( zhôngguó guójiâ biâozhün) in Chinese. — Abbreviation for “Chinese National Standard.” 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • GCCS (Hong Kong) — Abbreviation for “Government Chinese Character Set.” • JIS (Japan) — 日本工業規格 ( nihon kôgyô kikaku) in Japanese. — Abbreviation for “Japanese Industrial Standard.” — 〄 • KS (Korea) — 한국 공업 규격 (韓國工業規格 hangug gongeob gyugyeog) in Korean. — Abbreviation for “Korean Standard.” — ㉿ — Designation change from “C” to “X” on August 20, 1997. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • TCVN (Vietnam) — Tiu Chun Vit Nam in Vietnamese. — Means “Vietnamese Standard.” • CJKV — Chinese, Japanese, Korean, and Vietnamese. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated What Is A Character Set? dc • A collection of characters that are intended to be used together to create meaningful text. -

UC Santa Cruz UC Santa Cruz Electronic Theses and Dissertations
UC Santa Cruz UC Santa Cruz Electronic Theses and Dissertations Title The Historical Development of Initial Accent in Trimoraic Nouns in Kyoto Japanese Permalink https://escholarship.org/uc/item/3f57b731 Author Angeles, Andrew Publication Date 2019 License https://creativecommons.org/licenses/by-nc-nd/4.0/ 4.0 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA SANTA CRUZ THE HISTORICAL DEVELOPMENT OF INITIAL ACCENT IN TRIMORAIC NOUNS IN KYOTO JAPANESE A thesis submitted in partial satisfaction of the requirements for the degree of MASTER OF ARTS in LINGUISTICS by Andrew Angeles September 2019 The thesis of Andrew Angeles is approved: _______________________________ Professor Junko Ito, Chair _______________________________ Associate Professor Ryan Bennett _______________________________ Associate Professor Grant McGuire _______________________________ Quentin Williams Acting Vice Provost and Dean of Graduate Studies Copyright © by Andrew Angeles 2019 TABLE OF CONTENTS List of Figures ............................................................................................................. v Abstract ...................................................................................................................... ix Acknowledgments ................................................................................................... xiv 1 Introduction .......................................................................................................... -

264 Tugboat, Volume 37 (2016), No. 3 Typographers' Inn Peter Flynn
264 TUGboat, Volume 37 (2016), No. 3 A Typographers’ Inn X LE TEX Peter Flynn Back at the ranch, we have been experimenting with X LE ATEX in our workflow, spurred on by two recent Dashing it off requests to use a specific set of OpenType fonts for A I recently put up a new version of Formatting Infor- some GNU/Linux documentation. X LE TEX offers A mation (http://latex.silmaril.ie), and in the two major improvements on pdfLTEX: the use of section on punctuation I described the difference be- OpenType and TrueType fonts, and the handling of tween hyphens, en rules, em rules, and minus signs. UTF-8 multibyte characters. In particular I explained how to type a spaced Font packages. You can’t easily use the font pack- dash — like that, using ‘dash~---Ђlike’ to put a A ages you use with pdfLTEX because the default font tie before the dash and a normal space afterwards, encoding is EU1 in the fontspec package which is key so that if the dash occurred near a line-break, it to using OTF/TTF fonts, rather than the T1 or OT1 would never end up at the start of a line, only at A conventionally used in pdfLTEX. But late last year the end. I somehow managed to imply that a spaced Herbert Voß kindly posted a list of the OTF/TTF dash was preferable to an unspaced one (probably fonts distributed with TEX Live which have packages because it’s my personal preference, but certainly A of their own for use with X LE TEX [6]. -

The Fontspec Package Font Selection for XƎLATEX and Lualatex
The fontspec package Font selection for XƎLATEX and LuaLATEX Will Robertson and Khaled Hosny [email protected] 2013/05/12 v2.3b Contents 7.5 Different features for dif- ferent font sizes . 14 1 History 3 8 Font independent options 15 2 Introduction 3 8.1 Colour . 15 2.1 About this manual . 3 8.2 Scale . 16 2.2 Acknowledgements . 3 8.3 Interword space . 17 8.4 Post-punctuation space . 17 3 Package loading and options 4 8.5 The hyphenation character 18 3.1 Maths fonts adjustments . 4 8.6 Optical font sizes . 18 3.2 Configuration . 5 3.3 Warnings .......... 5 II OpenType 19 I General font selection 5 9 Introduction 19 9.1 How to select font features 19 4 Font selection 5 4.1 By font name . 5 10 Complete listing of OpenType 4.2 By file name . 6 font features 20 10.1 Ligatures . 20 5 Default font families 7 10.2 Letters . 20 6 New commands to select font 10.3 Numbers . 21 families 7 10.4 Contextuals . 22 6.1 More control over font 10.5 Vertical Position . 22 shape selection . 8 10.6 Fractions . 24 6.2 Math(s) fonts . 10 10.7 Stylistic Set variations . 25 6.3 Miscellaneous font select- 10.8 Character Variants . 25 ing details . 11 10.9 Alternates . 25 10.10 Style . 27 7 Selecting font features 11 10.11 Diacritics . 29 7.1 Default settings . 11 10.12 Kerning . 29 7.2 Changing the currently se- 10.13 Font transformations . 30 lected features . -

The Selnolig Package: Selective Suppression of Typographic Ligatures*
The selnolig package: Selective suppression of typographic ligatures* Mico Loretan† 2015/10/26 Abstract The selnolig package suppresses typographic ligatures selectively, i.e., based on predefined search patterns. The search patterns focus on ligatures deemed inappropriate because they span morpheme boundaries. For example, the word shelfful, which is mentioned in the TEXbook as a word for which the ff ligature might be inappropriate, is automatically typeset as shelfful rather than as shelfful. For English and German language documents, the selnolig package provides extensive rules for the selective suppression of so-called “common” ligatures. These comprise the ff, fi, fl, ffi, and ffl ligatures as well as the ft and fft ligatures. Other f-ligatures, such as fb, fh, fj and fk, are suppressed globally, while making exceptions for names and words of non-English/German origin, such as Kafka and fjord. For English language documents, the package further provides ligature suppression rules for a number of so-called “discretionary” or “rare” ligatures, such as ct, st, and sp. The selnolig package requires use of the LuaLATEX format provided by a recent TEX distribution, e.g., TEXLive 2013 and MiKTEX 2.9. Contents 1 Introduction ........................................... 1 2 I’m in a hurry! How do I start using this package? . 3 2.1 How do I load the selnolig package? . 3 2.2 Any hints on how to get started with LuaLATEX?...................... 4 2.3 Anything else I need to do or know? . 5 3 The selnolig package’s approach to breaking up ligatures . 6 3.1 Free, derivational, and inflectional morphemes . -

Japanese Language and Culture
NIHONGO History of Japanese Language Many linguistic experts have found that there is no specific evidence linking Japanese to a single family of language. The most prominent theory says that it stems from the Altaic family(Korean, Mongolian, Tungusic, Turkish) The transition from old Japanese to Modern Japanese took place from about the 12th century to the 16th century. Sentence Structure Japanese: Tanaka-san ga piza o tabemasu. (Subject) (Object) (Verb) 田中さんが ピザを 食べます。 English: Mr. Tanaka eats a pizza. (Subject) (Verb) (Object) Where is the subject? I go to Tokyo. Japanese translation: (私が)東京に行きます。 [Watashi ga] Toukyou ni ikimasu. (Lit. Going to Tokyo.) “I” or “We” are often omitted. Hiragana, Katakana & Kanji Three types of characters are used in Japanese: Hiragana, Katakana & Kanji(Chinese characters). Mr. Tanaka goes to Canada: 田中さんはカナダに行きます [kanji][hiragana][kataka na][hiragana][kanji] [hiragana]b Two Speech Styles Distal-Style: Semi-Polite style, can be used to anyone other than family members/close friends. Direct-Style: Casual & blunt, can be used among family members and friends. In-Group/Out-Group Semi-Polite Style for Out-Group/Strangers I/We Direct-Style for Me/Us Polite Expressions Distal-Style: 1. Regular Speech 2. Ikimasu(he/I go) Honorific Speech 3. Irasshaimasu(he goes) Humble Speech Mairimasu(I/We go) Siblings: Age Matters Older Brother & Older Sister Ani & Ane 兄 と 姉 Younger Brother & Younger Sister Otooto & Imooto 弟 と 妹 My Family/Your Family My father: chichi父 Your father: otoosan My mother: haha母 お父さん My older brother: ani Your mother: okaasan お母さん Your older brother: oniisanお兄 兄 さん My older sister: ane姉 Your older sister: oneesan My younger brother: お姉さ otooto弟 ん Your younger brother: My younger sister: otootosan弟さん imooto妹 Your younger sister: imootosan 妹さん Boy Speech & Girl Speech blunt polite I/Me = watashi, boku, ore, I/Me = watashi, washi watakushi I am going = Boku iku.僕行 I am going = Watashi iku く。 wa. -

Package 'Showtextdb'
Package ‘showtextdb’ June 4, 2020 Type Package Title Font Files for the 'showtext' Package Version 3.0 Date 2020-05-31 Author Yixuan Qiu and authors/contributors of the included fonts. See file AUTHORS for details. Maintainer Yixuan Qiu <[email protected]> Description Providing font files that can be used by the 'showtext' package. Imports sysfonts (>= 0.7), utils Suggests curl License Apache License (>= 2.0) Copyright see file COPYRIGHTS RoxygenNote 7.1.0 NeedsCompilation no Repository CRAN Date/Publication 2020-06-04 08:10:02 UTC R topics documented: font_install . .2 google_fonts . .3 load_showtext_fonts . .4 source_han . .4 Index 6 1 2 font_install font_install Install Fonts to the ’showtextdb’ Package Description font_install() saves the specified font to the ‘fonts’ directory of the showtextdb package, so that it can be used by the showtext package. This function requires the curl package. font_installed() lists fonts that have been installed to showtextdb. NOTE: Since the fonts are installed locally to the package directory, they will be removed every time the showtextdb package is upgraded or re-installed. Usage font_install(font_desc, quiet = FALSE, ...) font_installed() Arguments font_desc A list that provides necessary information of the font for installation. See the Details section. quiet Whether to show the progress of downloading and installation. ... Other parameters passed to curl::curl_download(). Details font_desc is a list that should contain at least the following components: showtext_name The family name of the font that will be used in showtext. font_ext Extension name of the font files, e.g., ttf for TrueType, and otf for OpenType. regular_url URL of the font file for "regular" font face.