Cats and Dogs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Annual General Assembly Agenda
FEDERATION INTERNATIONALE FELINE – FIFe ANNUAL GENERAL ASSEMBLY AGENDA 24/25.05.2007 HOTEL MONTECHORO Rua Alexandre O’Neill Albufeira, Portugal FEDERATION INTERNATIONALE FELINE – FIFe ANNUAL GENERAL ASSEMBLY HOTEL MONTECHORO, ALBUFEIRA, PORTUGAL 24th - 25th May, 2007, from 09.00 to 17.30 AGENDA Page nr. 1. Welcome speech of the President 2. Roll call of the Delegates 3. Election of two Scrutineers and three Supervisors for the Minutes of the GA 2007 4. Drafting of the Minutes 5. Approval of the Agenda – request ZFDS (SI)……………………………………………………………1 6. Ratifications a) Ratification of the appointment of a Probational Member…………………………………….……….. 2-3 From 13.09.2006 until the General Assembly 2007 b) Ratification of cooption of two Members to the Judges and Standard …………………………………..4 Commission from 15.11.2006 until the General Assembly 2007 7. Approval of the Minutes of the General Assembly 2006 in Rome 8. Report of the President ………………………………………………………………………………….….5 9. Report of the General Secretary ………………………………………………………………….……….6 10. Report of the Treasurer …………………………………………………..………………..……7-18 11. Report of the two Auditors (issued at the meeting) 12. Discussion on the reports of the Treasurer and the two Auditors 13. Discharge of responsibility: a) Of the Executive Board b) Of the Treasurer 14. Reports of the Commissions: a) Disciplinary Commission (issued at the meeting) b) Health & Welfare Commission …………………………………………………………………………...…19 c) Judges and Standard Commission ……………………………………………………………………...…20 d) LO Commission ………………………………………………………………………………………….…...21 e) Show Commission …………………………………………………………………………………….……..22 15. Elections: Members, who supported candidates, appear below or behind their names: a) Election of a President for a period of three years. Mrs Annette Sjödin (SE) is proposed for this function by: SVERAK (SE), ÖVEK (AT), NFFe (BU), ČSCH (CZ), AMIL (IL), NRR (NO), CPF (PT), ARCCA (RU), ZFDS (SI), SZCH (SK) and the Board b) Election of a General Secretary for a period of three years. -

Snomed Ct Dicom Subset of January 2017 Release of Snomed Ct International Edition
SNOMED CT DICOM SUBSET OF JANUARY 2017 RELEASE OF SNOMED CT INTERNATIONAL EDITION EXHIBIT A: SNOMED CT DICOM SUBSET VERSION 1. -

JAHIS 病理・臨床細胞 DICOM 画像データ規約 Ver.2.1
JAHIS標準 15-005 JAHIS 病理・臨床細胞 DICOM 画像データ規約 Ver.2.1 2015年9月 一般社団法人 保健医療福祉情報システム工業会 検査システム委員会 病理・臨床細胞部門システム専門委員会 JAHIS 病理・臨床細胞 DICOM 画像データ規約 Ver.2.1 ま え が き 院内における病理・臨床細胞部門情報システム(APIS: Anatomic Pathology Information System) の導入及び運用を加速するため、一般社団法人 保健医療福祉情報システム工業会(JAHIS)では、 病院情報システム(HIS)と病理・臨床細胞部門情報システム(APIS)とのデータ交換の仕組みを 検討しデータ交換規約(HL7 Ver2.5 準拠の「病理・臨床細胞データ交換規約」)を作成した。 一方、医用画像の標準規格である DICOM(Digital Imaging and Communications in Medicine) においては、臓器画像と顕微鏡画像、WSI(Whole Slide Images)に関する規格が制定された。 しかしながら、病理・臨床細胞部門では対応実績を持つ製品が未だない実状に鑑み、この規格 の普及を促進すべく「病理・臨床細胞 DICOM 画像データ規約」を作成した。 本規約をまとめるにあたり、ご協力いただいた関係団体や諸先生方に深く感謝する。本規約が 医療資源の有効利用、保健医療福祉サービスの連携・向上を目指す医療情報標準化と相互運用性 の向上に多少とも貢献できれば幸いである。 2015年9月 一般社団法人 保健医療福祉情報システム工業会 検査システム委員会 << 告知事項 >> 本規約は関連団体の所属の有無に関わらず、規約の引用を明示することで自由に使用す ることができるものとします。ただし一部の改変を伴う場合は個々の責任において行い、 本規約に準拠する旨を表現することは厳禁するものとします。 本規約ならびに本規約に基づいたシステムの導入・運用についてのあらゆる障害や損害 について、本規約作成者は何らの責任を負わないものとします。ただし、関連団体所属の 正規の資格者は本規約についての疑義を作成者に申し入れることができ、作成者はこれに 誠意をもって協議するものとします。 << DICOM 引用に関する告知事項 >> DICOM 規格の規範文書は、英語で出版され、NEMA(National Electrical Manufacturers Association) に著作権があり、最新版は公式サイト http://dicom.nema.org/standard.html から無償でダウンロードが可能です。 この文書で引用する DICOM 規格と NEMA が発行する英語版の DICOM 規格との間に差が生 じた場合は、英 語版が規範であり優先します。 実装する際は、規範 DICOM 規格への適合性を宣言しなければなりません。 © JAHIS 2015 i 目 次 1. はじめに ................................................................................................................................ 1 2. 適用範囲 ............................................................................................................................... -
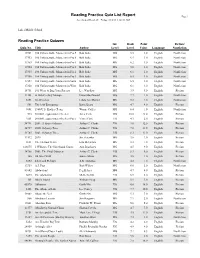
Reading Practice Quiz List Report Page 1 Accelerated Reader®: Friday, 03/04/11, 08:41 AM
Reading Practice Quiz List Report Page 1 Accelerated Reader®: Friday, 03/04/11, 08:41 AM Lakes Middle School Reading Practice Quizzes Int. Book Point Fiction/ Quiz No. Title Author Level Level Value Language Nonfiction 17351 100 Unforgettable Moments in Pro BaseballBob Italia MG 5.5 1.0 English Nonfiction 17352 100 Unforgettable Moments in Pro BasketballBob Italia MG 6.5 1.0 English Nonfiction 17353 100 Unforgettable Moments in Pro FootballBob Italia MG 6.2 1.0 English Nonfiction 17354 100 Unforgettable Moments in Pro GolfBob Italia MG 5.6 1.0 English Nonfiction 17355 100 Unforgettable Moments in Pro HockeyBob Italia MG 6.1 1.0 English Nonfiction 17356 100 Unforgettable Moments in Pro TennisBob Italia MG 6.4 1.0 English Nonfiction 17357 100 Unforgettable Moments in SummerBob Olympics Italia MG 6.5 1.0 English Nonfiction 17358 100 Unforgettable Moments in Winter OlympicsBob Italia MG 6.1 1.0 English Nonfiction 18751 101 Ways to Bug Your Parents Lee Wardlaw MG 3.9 5.0 English Fiction 11101 A 16th Century Mosque Fiona MacDonald MG 7.7 1.0 English Nonfiction 8251 18-Wheelers Linda Lee Maifair MG 5.2 1.0 English Nonfiction 661 The 18th Emergency Betsy Byars MG 4.7 4.0 English Fiction 9801 1980 U.S. Hockey Team Wayne Coffey MG 6.4 1.0 English Nonfiction 523 20,000 Leagues under the Sea Jules Verne MG 10.0 28.0 English Fiction 9201 20,000 Leagues under the Sea (Pacemaker)Verne/Clare UG 4.3 2.0 English Fiction 34791 2001: A Space Odyssey Arthur C. -

DYNAMITE First for Blue the Washboard and Hours T, ALBERT W, Xjlliibridge, Andalusia, First for Whits Minorca ' Chicks, First for Pair of Black Spanish
1 NORWICH BULLETIN, THURSDAY, SEPTEMBER 21, 1911 get horse on the grounds. Near him TRAVELERS' DIRECTORY. in contrast stood diminutive ponies of NORTH STONINGTON GRANGE FAIR only a few hundred pounds Weight. In the place reserved for the cattle, all the standard breeds were shown, pure bred and grade, 125 in all,' Noticeable Norwich Line here were some of the big yoke of oxen t TO Second Annual Event- - Drew an Attendance of 2500 Big among which were a yoke of grade Hereford, and a yoke of Dutch Belted. Over Last . Sheep- and pigs are represented m NEW YORK Improvement In Displays and Attractions the pens near the back of the grounds, STEAMERS 25 woolly Shropshires - being seen, Year. while the hog pens contain , both the CITY OF LOWELL black Berkshires and the Chester '' AND , -- - " white. Several litters of lusty pigs IV. A bring out admiring eomnjent. A pair .CHESTER Ill PIN Jiorth Stonington turned out en to greet the visitor. Here the West- of goats completes the livestock ex- Choose this route next time you jr triaiwe om Wednesday for th eeoivd erly Furniture company had a ten dis- hibit. ...... to Xe. Y.wk. Vou'll iia.ve..a delightful oiinal fair of the North Stonington playing stoves, graphophones and fur- The grounds..,'..are well looked after by voyage on Lonj? Island Sound and rranee, incorporated. Aided by the niture- next was the tent of. the H. J. Edwin Thompson, who is in charge superb view of the wonderful sky iinn iinmbcr who were on hand from Nor B. -

Small Animals and Veterinary Science Smallcountdown Animals and Chapter 1 Smallveterinary Animals Scienceand Veterinary Science Contents Small Animals Crossword
Countdown Chapter 1 Small Animals and Veterinary Science SmallCountdown Animals and Chapter 1 SmallVeterinary Animals Scienceand Veterinary Science Contents Small Animals Crossword ................................................................................................. 1 Small Animal Vocabulary ................................................................................................. 3 Parts of a Dog................................................................................................................ 5 Breeds of Dogs: The Groups ............................................................................................. 7 Breeds of Dogs—Group 1: Sporting Dogs.......................................................................... 9 Breeds of Dogs—Group 2: Hounds................................................................................. 11 Breeds of Dogs—Group 3: Working Dogs........................................................................ 13 Breeds of Dogs—Group 4: Terriers ................................................................................. 15 Breeds of Dogs—Group 5: Toys..................................................................................... 17 Breeds of Dogs—Group 6: Non-Sporting ......................................................................... 19 Breeds of Dogs—Group 7: Herding ................................................................................ 21 The Body Language of Dogs.......................................................................................... -

Alexander and Some Other Cats
UNIVERSITE mm i$z&y UNIVERSITY LIBRARIES Date Due APR 0 7 1991 *nmn— SfP j 5 ^ 1770fQQS—00ST751 JUN 2 0 1995 sc York Form — Cooper Graphics Digitized by the Internet Archive in 2014 https://archive.org/details/alexandersomeothOOeddy ALEXANDER AND SOME OTHER CATS Alexander ALEXANDER AND SOME OTHER CATS Compiled and arranged by SARAH J. EDDY MARSHALL JONES COMPANY BOSTON • MASSACHUSETTS COPYRIGHT 1929 BY MARSHALL JONES INCORPORATED Printed in April, 1929 THE PLIMPTON PRESS • NORWOOD • MASSACHUSETTS MANUFACTURED IN THE UNITED STATES OF AMERICA { Dedicated TO ALL THOSE WHO LOVE CATS AND TO ALL THOSE WHO DO NOT LOVE THEM BECAUSE THEY DO NOT KNOW THEM CONTENTS Foreword What has been Said about Cats Quotations from Edward E. Whiting, Philip G. Hamerton, Agnes Repplier, Theophile Gautier, William Lyon Phelps, St. George Mivart, Professor Romanes and many others. Grace and beauty of cats — their sensitiveness and intelligence — their capacity for affection — their possession of language. Famous Persons who have Loved Cats. The Intelligence of Cats Incidents to show that cats understand human language; easily become adept at using mechanical appliances, clearly express their needs and desires and often show interest and helpfulness toward other animals. Mother Love of Cats Dr. Gordon Stables on the depth of the maternal instinct in cats. Stories to illustrate the devotion of cats to their young. Cats as foster mothers. Kittens The Poets on Kittens. Miss Repplier's description of a kitten. Kittens and little children. Affection for Persons Stories that show how much affection cats have for their owners. Individual Cats Alexander, Togo, Toby and Timothy, Tabs, Tootsie, Tom, Agrippina, Friday, Tripp, Mephisto, Thomas Erastus, John Steven McCroarty's " Yellow Cat," Fluffy, Bialka. -

Happy Hamster
THE_ ANIMAL HEALTH MAGAZINE HAPPY HOLIDAYS VETERINARY DIAGNOSIS CARE OF THE REJECTED KITTEN LOOK OUT FOR EYE DISEASES IN YOUR PUP rwmm EDITOR'S NOTEBOOK «feiDE Official Journal of the Animal Health Foundation on animal care and health. NOV/DEC 1975 Volume 6 Number 6 ARTICLES The How of-a Diagnosis, C. P. Ryan, D. V.M 8 EDITOR'S NOTEBOOK Caring for the Orphaned or Rejected Kitten, Jane Taylor 10 Problems with Tabby, Ruby Harris Arnoth 12 'TIS THE SEASON Be on the Lookout for these Eye Diseases in your Dog 14 Pannus in Dogs Studied 15 As the holiday season approaches, "Giving Power" 16 we have pleasant thoughts and reflec A Look at Canine Behavior, Michael W. Fox, M.R.C. V.S., Ph.D 17 tions of the recent months and years. How to Raise a Happy Hamster, Sue Kizer 18 Inevitably, some of the warmest A Marble Sarcophagus for a Pretty Cat, Mary Wells Geer 21 recollections relate to animals we have Solving Birth Defects in Cattle 21 encountered or owned. It is a time to sort of pull the Pet Doctors Respond Around-the-Clock 22 strings together and prepare for Cage Birds Need Special Attention Now 29 another year. We are hopeful that our Can Cats Be Trained?, Louis J. Camuti, B.S., D.V.S 30 readers will devote a little extra time and thought to their animals, being DEPARTMENTS sure they are in comfortable quarters, Editor's Notebook 3 properly fed, and their health pro Doctor's Advice 4 tected. Cavalcade Health News 6 Faithful, contributing members of Children's Page the ANIMAL HEALTH FOUNDA When Pets Were Gods, Letha Curtis Musgrave 24 TION, are protecting hard earned Book Review 31 avings during these burdensome times id, yet, are lending strong support to the FOUNDATION in its promotion of better health for all animals. -

Using Petlink's Mass Import Feature
Using PetLink’s Mass Import Feature Instructions for Animal Professionals (Shelters, Rescues and Humane Societies) Overview PetLink offers Mass Import of multiple prepaid microchip registrations and transfers of ownership for Animal Professionals, so that you can upload pet data in bulk, saving valuable time entering individual records. PetLink’s Mass Import is based on a simple, easy to use Microsoft Excel spreadsheet template, where owner and pet data are input into one document, which then can be uploaded into PetLink directly at one time. Mass Import enables immediate registration, and eliminates the need for individual registration and transfer of ownership forms that have to be mailed or faxed to PetLink. Mass Import also helps ensure that pet owner contact data Guardian: remains in secure hands. We are committed to our customers’ Linking You, Your Clients and Pets privacy; Mass Import creates an efficient and effective means to complete registration or transfer of ownership quickly By using PetLink’s Mass Import feature, your facility will and ensures that the privacy of both you and your clients is automatically be listed as “guardian” for every pet registered - protected. Your facility will receive a confirmation report and something that a pet owner or adopter cannot edit. This adds your each individual pet owner will receive a PetLink welcome email facility as a permanent contact in case the pet is ever found far following a successful import. from home but its family cannot be reached. It helps ensure that you can remain involved in the pet’s care and in making decisions In order to use Mass Import, your facility needs to have a valid, on how it is to be treated and possibly rehomed if that animal is free, Animal Professional account with PetLink. -

Murthy's Cattage
♦ ♦ Murthy's Cattage A BIOGRAPHICAL DICTIONARY OF CATS IN LITERATURE - C4&,Vn By HOWARD M. CHAPIN ♦ ♦ 1 MURTHi A Biograp Cats f HO\ Author of " L " How tr By b c MURTHY'S CATTAGE A Biographical Dictionary of Cats in Literature (T^^^^l) By HOWARD M. CHAPIN Author of " Life of Deacon Samuel Chapin' "How to Enamel" (now in presd) Copyright 1911 By HOWARD M. CHAPIN Providence, R. I. Q MURTH THIS work is a brief hi that is of cats mentior historical personages, winning are not considered eli: Aaron. — England. —A dark 1 tabby, male. Brother of R Belonged to Harrison Weir. Abuhareira.—See Meuzza. Agrippina.—United States.—A cat, to whom Agnes Repplier ♦ cated her book, "The Fii £ Sphinx." Belonged to Miss plier. Ajax.—See Banjo. Apollinaris.—TJ. S.—Belonged to Twain. Arreopagite "cadet." — Franc Younger kitten of Manon I.. tioned by Moncrif. Arreopagite "Paine."—Fr.—Eldei ten of Manon I. Moncrif. Atossa.—Eng.—A Persian cat. ( "Toss." Belonged to Matthew nold who wrote a poem about 1 Atossa.—Eng.—Belonged to borne. Winslow. Augustus.—U. S.—Belonged to Mary E. Wilkins. Portrait in B low. 4 Babylon.—U. S.—Maltese cat. *E longed to E. C. Stedman. Po MURTHY * ' in Winslow. Banjo.—U. S.—Chinchilla cat. To whose memory this woii is respectfully of Ajax and Madame Ref. Bel< dedicatee) to Ella Wheeler Wilcox. Portr Winslow. •* ' - I * • Beauty.—U. S.—Belonged to Proctor. Winslow. Beauty Spot.—U. S.—Black ' Daughter of Miss Spot. Belc - to Mrs. Spofford. Belaud.—Fr.—The first cat praisi a French poet. Subject of a by Joachim du Bellay to whor laud belonged. -

SPRING 2019 Newsletter
The Scratching Post SABCCI Newsletter - Spring 2019 www.sabcci.com The Scratching Post Contents - Spring 2019 Page Editorial, Dublin Cat Fair, Pet Travel & Brexit 3 Rainbow Bridge 4 The Pedigree 5 The Cat Brain 5/6 A Campus Cat 6 The Quiz & Fun Stuff 7 Dublin Championship Cat Show 2018 8 UK - Cat Welfare Put On The Political Agenda 9 Plants With Feline Names 9 The Cat Walk 10/11 Pip NYC To Dublin, The Visitor 12 Two Cat In The News Stories 13 Health 14 Kits Korner 15 The Final Miaow & More 16 www.sabcci.com SABCCI Committee Ronnie Brooks, Dionne Dixon, Hugh Gibney, Gloria Hehir, Aedamair Kiely, Norman O’Galligan, Karen Sluiters, Jim Stephens, Lorna Taylor, Aimee Weldon Membership Secretary - Betty Dobbs Black Cat A cat as black As blackest coal Is out upon His midnight stroll, His steps are soft, His walk is slow, His eyes are gold, They flash and glow, And so I run And so I duck, I do not need His black-cat luck. ‘Mom, am I Adopted?’ Author Unknown 2 Editorial Welcome to our Spring 2019 issue of The Scratching Post. So if you’re ready, sit back with a Blueberry Ginger and enjoy the newsletter! Karen and Gloria ^..^ Do you have any photos or articles for the newsletter? Please send them to [email protected] or [email protected] A Date For Your Diary The GCCFI Supreme Cat Show Sunday the 7th of April Ballinteer Community School, Broadford Road, Ballinteer, Dublin 16 Open to the Public 12:00 to 5:00 Best In Show 4:00 onwards The GCCFI At The Dublin Cat Fair 2018 The Dublin Cat Fair, now in its second year, is a full day of lectures by cat experts on various subjects. -

Humane Cat Population Management Guidance
WellBeing International WBI Studies Repository 2011 Humane Cat Population Management Guidance International Companion Animal Management Coalition Follow this and additional works at: https://www.wellbeingintlstudiesrepository.org/strfapop Part of the Animal Studies Commons, Nature and Society Relations Commons, and the Population Biology Commons Recommended Citation International Companion Animal Management Coalition, "Humane Cat Population Management Guidance" (2011). Stray and Feral Animal Populations Collection. 1. https://www.wellbeingintlstudiesrepository.org/strfapop/1 This material is brought to you for free and open access by WellBeing International. It has been accepted for inclusion by an authorized administrator of the WBI Studies Repository. For more information, please contact [email protected]. HUMANE CAT POPULATION MANAGEMENT GUIDANCE International Companion Animal Management Coalition Executive summary The International Companion Animal Management A The initial data collection and assessment: understanding Coalition has produced this document to provide the problem you are facing by asking the right questions, government bodies and non-governmental finding out the relevant information and involving everyone organisations with a detailed resource to support who needs to be involved. them in their development and implementation of effective and humane programmes to manage B Analysing and interpreting assessment data with cat populations. consideration of the influential factors in cat population management: what influences the size and make-up of Over thousands of years, the relationship between cats and the cat population and people’s desire to control that humans has evolved, with an estimated 500 million cats population? living throughout the world today. The size and make-up of individual cat populations can vary significantly, as can the C The components of a comprehensive cat population circumstances and environments in which they are found.