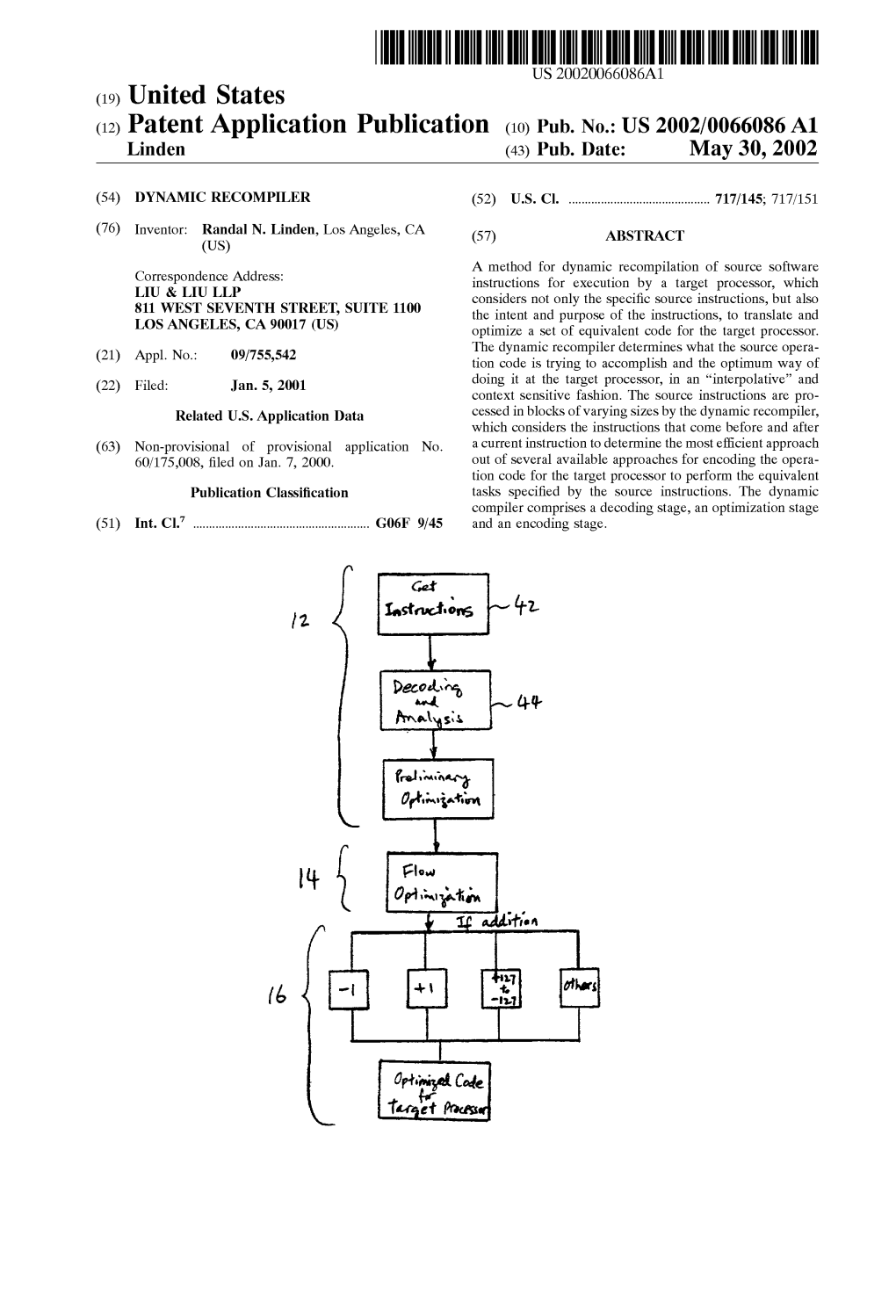
US 2002/0066086 A1 Linden (43) Pub
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Dynamically Recompiling ARM Emulator POWERED
POWERED TACARM A Dynamically Recompiling ARM Emulator 3rd year project report 2000-2001 University of Warwick Written by David Sharp Supervised by Graham Martin 2 Abstract Dynamically recompiling from one machine code to another can be used to emulate modern microprocessors at realistic speeds. This report is a discussion of the techniques used in implementing a dynamically recompiling emulator of an ARM processor for use in an emulation of a complete computer system. Keywords Emulation, Dynamic Recompilation, Binary Translation, Just-In-Time compilation, Virtual Machine, Microprocessor Simulation, Intermediate Code, ARM. 3 Contents 1. Introduction 7 1.1. What is emulation? 7 1.2. Applications of emulation 7 1.3. Processor emulation techniques 9 1.4. This Project 13 2. Analysis 16 2.1. Introduction to the ARM 16 2.2. Identifying the problem 18 2.3. Getting started 20 2.4. The System Design 21 3. Disassembler 23 3.1. Purpose 23 3.2. ARM decoding 23 3.3. Design 24 4. Interpreter 26 4.1. Purpose 26 4.2. The problem with JIT 26 4.3. The HotSpotTM alternative 26 4.4. Quantifying the JIT problem 27 4.5. Faster decoding 28 4.6. Interfaces 29 4.7. The emulation loop 30 4.8. Implementation 31 4.9. Debugging 32 4.10. Compatibility 33 5. Recompilation 35 5.1. Overview 35 5.2. Methods of generating native code 35 5.3. The use of intermediate code 36 6. Armlets – An Intermediate Code 38 6.1. Purpose 38 6.2. The ‘explicit-implicit problem’ 38 6.3. Options 39 6.4. -

A Brief History of Just-In-Time Compilation
A Brief History of Just-In-Time JOHN AYCOCK University of Calgary Software systems have been using “just-in-time” compilation (JIT) techniques since the 1960s. Broadly, JIT compilation includes any translation performed dynamically, after a program has started execution. We examine the motivation behind JIT compilation and constraints imposed on JIT compilation systems, and present a classification scheme for such systems. This classification emerges as we survey forty years of JIT work, from 1960–2000. Categories and Subject Descriptors: D.3.4 [Programming Languages]: Processors; K.2 [History of Computing]: Software General Terms: Languages, Performance Additional Key Words and Phrases: Just-in-time compilation, dynamic compilation 1. INTRODUCTION into a form that is executable on a target platform. Those who cannot remember the past are con- What is translated? The scope and na- demned to repeat it. ture of programming languages that re- George Santayana, 1863–1952 [Bartlett 1992] quire translation into executable form covers a wide spectrum. Traditional pro- This oft-quoted line is all too applicable gramming languages like Ada, C, and in computer science. Ideas are generated, Java are included, as well as little lan- explored, set aside—only to be reinvented guages [Bentley 1988] such as regular years later. Such is the case with what expressions. is now called “just-in-time” (JIT) or dy- Traditionally, there are two approaches namic compilation, which refers to trans- to translation: compilation and interpreta- lation that occurs after a program begins tion. Compilation translates one language execution. into another—C to assembly language, for Strictly speaking, JIT compilation sys- example—with the implication that the tems (“JIT systems” for short) are com- translated form will be more amenable pletely unnecessary. -

Program Dynamic Analysis Overview
4/14/16 Program Dynamic Analysis Overview • Dynamic Analysis • JVM & Java Bytecode [2] • A Java bytecode engineering library: ASM [1] 2 1 4/14/16 What is dynamic analysis? [3] • The investigation of the properties of a running software system over one or more executions 3 Has anyone done dynamic analysis? [3] • Loggers • Debuggers • Profilers • … 4 2 4/14/16 Why dynamic analysis? [3] • Gap between run-time structure and code structure in OO programs Trying to understand one [structure] from the other is like trying to understand the dynamism of living ecosystems from the static taxonomy of plants and animals, and vice-versa. -- Erich Gamma et al., Design Patterns 5 Why dynamic analysis? • Collect runtime execution information – Resource usage, execution profiles • Program comprehension – Find bugs in applications, identify hotspots • Program transformation – Optimize or obfuscate programs – Insert debugging or monitoring code – Modify program behaviors on the fly 6 3 4/14/16 How to do dynamic analysis? • Instrumentation – Modify code or runtime to monitor specific components in a system and collect data – Instrumentation approaches • Source code modification • Byte code modification • VM modification • Data analysis 7 A Running Example • Method call instrumentation – Given a program’s source code, how do you modify the code to record which method is called by main() in what order? public class Test { public static void main(String[] args) { if (args.length == 0) return; if (args.length % 2 == 0) printEven(); else printOdd(); } public -

Transparent Dynamic Optimization: the Design and Implementation of Dynamo
Transparent Dynamic Optimization: The Design and Implementation of Dynamo Vasanth Bala, Evelyn Duesterwald, Sanjeev Banerjia HP Laboratories Cambridge HPL-1999-78 June, 1999 E-mail: [email protected] dynamic Dynamic optimization refers to the runtime optimization optimization, of a native program binary. This report describes the compiler, design and implementation of Dynamo, a prototype trace selection, dynamic optimizer that is capable of optimizing a native binary translation program binary at runtime. Dynamo is a realistic implementation, not a simulation, that is written entirely in user-level software, and runs on a PA-RISC machine under the HPUX operating system. Dynamo does not depend on any special programming language, compiler, operating system or hardware support. Contrary to intuition, we demonstrate that it is possible to use a piece of software to improve the performance of a native, statically optimized program binary, while it is executing. Dynamo not only speeds up real application programs, its performance improvement is often quite significant. For example, the performance of many +O2 optimized SPECint95 binaries running under Dynamo is comparable to the performance of their +O4 optimized version running without Dynamo. Internal Accession Date Only Ó Copyright Hewlett-Packard Company 1999 Contents 1 INTRODUCTION ........................................................................................... 7 2 RELATED WORK ......................................................................................... 9 3 OVERVIEW -

Infrastructures and Compilation Strategies for the Performance of Computing Systems Erven Rohou
Infrastructures and Compilation Strategies for the Performance of Computing Systems Erven Rohou To cite this version: Erven Rohou. Infrastructures and Compilation Strategies for the Performance of Computing Systems. Other [cs.OH]. Universit´ede Rennes 1, 2015. <tel-01237164> HAL Id: tel-01237164 https://hal.inria.fr/tel-01237164 Submitted on 2 Dec 2015 HAL is a multi-disciplinary open access L'archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destin´eeau d´ep^otet `ala diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publi´esou non, lished or not. The documents may come from ´emanant des ´etablissements d'enseignement et de teaching and research institutions in France or recherche fran¸caisou ´etrangers,des laboratoires abroad, or from public or private research centers. publics ou priv´es. Distributed under a Creative Commons Attribution - NonCommercial - NoDerivatives 4.0 International License HABILITATION À DIRIGER DES RECHERCHES présentée devant L’Université de Rennes 1 Spécialité : informatique par Erven Rohou Infrastructures and Compilation Strategies for the Performance of Computing Systems soutenue le 2 novembre 2015 devant le jury composé de : Mme Corinne Ancourt Rapporteur Prof. Stefano Crespi Reghizzi Rapporteur Prof. Frédéric Pétrot Rapporteur Prof. Cédric Bastoul Examinateur Prof. Olivier Sentieys Président M. André Seznec Examinateur Contents 1 Introduction 3 1.1 Evolution of Hardware . .3 1.1.1 Traditional Evolution . .4 1.1.2 Multicore Era . .4 1.1.3 Amdahl’s Law . .5 1.1.4 Foreseeable Future Architectures . .6 1.1.5 Extremely Complex Micro-architectures . .6 1.2 Evolution of Software Ecosystem . -

Costing JIT Traces
Costing JIT Traces John Magnus Morton, Patrick Maier, and Philip Trinder University of Glasgow [email protected], {Patrick.Maier, Phil.Trinder}@glasgow.ac.uk Abstract. Tracing JIT compilation generates units of compilation that are easy to analyse and are known to execute frequently. The AJITPar project aims to investigate whether the information in JIT traces can be used to make better scheduling decisions or perform code transformations to adapt the code for a specific parallel architecture. To achieve this goal, a cost model must be developed to estimate the execution time of an individual trace. This paper presents the design and implementation of a system for ex- tracting JIT trace information from the Pycket JIT compiler. We define three increasingly parametric cost models for Pycket traces. We perform a search of the cost model parameter space using genetic algorithms to identify the best weightings for those parameters. We test the accuracy of these cost models for predicting the cost of individual traces on a set of loop-based micro-benchmarks. We also compare the accuracy of the cost models for predicting whole program execution time over the Py- cket benchmark suite. Our results show that the weighted cost model using the weightings found from the genetic algorithm search has the best accuracy. 1 Introduction Modern hardware is increasingly multicore, and increasingly, software is required to exhibit decent parallel performance in order to match the hardware’s poten- tial. Writing performant parallel code is non-trivial for a fixed architecture, yet it is much harder if the target architecture is not known in advance, or if the code is meant to be portable across a range of architectures. -
![Arxiv:2106.08833V1 [Cs.NI] 16 Jun 2021 Mented on Commodity Servers, Are Widely Adopted in Real Tion Deployments](https://docslib.b-cdn.net/cover/6511/arxiv-2106-08833v1-cs-ni-16-jun-2021-mented-on-commodity-servers-are-widely-adopted-in-real-tion-deployments-1656511.webp)
Arxiv:2106.08833V1 [Cs.NI] 16 Jun 2021 Mented on Commodity Servers, Are Widely Adopted in Real Tion Deployments
Dynamic Recompilation of Software Network Services with Morpheus Sebastiano Miano1, Alireza Sanaee1, Fulvio Risso2, Gábor Rétvári3, Gianni Antichi1, 1Queen Mary University of London, UK 2Politecnico di Torino, IT 3MTA-BME Information Systems Research Group & Ericsson Research, HU Abstract that are only known at run time, and take difficult-to-predict branches conditioned on variable data. State-of-the-art approaches to design, develop and optimize Dynamic compilation, in contrast, enables program opti- software packet-processing programs are based on static com- mization based on invariant data computed at run time and pilation: the compiler’s input is a description of the forward- produces code that is specialized to the input the program ing plane semantics and the output is a binary that can accom- is processing [7, 24, 34]. The idea is to continuously collect modate any control plane configuration or input traffic. run-time data about program execution and then re-compile In this paper, we demonstrate that tracking control plane it to improve performance. This is a well-known practice actions and packet-level traffic dynamics at run time opens up adopted by generic programming languages (e.g., Java [24], new opportunities for code specialization. We present Mor- JavaScript [34], and C/C++ [7]) and often produces orders pheus, a system working alongside static compilers that con- of magnitude more efficient code in the context of, e.g., data- tinuously optimizes the targeted networking code. We intro- caching services [67], data mining [21] and databases [51,90]. duce a number of new techniques, from static code analysis to adaptive code instrumentation, and we implement a tool- To our surprise, we found that state-of-the-art dynamic box of domain specific optimizations that are not restricted optimization tools for generic software, including Google’s to a specific data plane framework or programming language. -

A Dynamic Optimization Framework for a Java Just-In-Time Compiler
A Dynamic Optimization Framework for a Java Just-in-Time Compiler Toshio $uganuma, Toshiaki Yasue, Motohiro Kawahito, Hideaki Kornatsu, Toshio Nakatani IBM Tokyo Research Laboratory 1623-14 Shimotururna, Yamato-shi, Kanagawa 242-8502, Japan Phone: +81-46-215-4658 Email: {suganuma, yasue, jl25131, komatsu, nakatani}@jp.ibm.com ABSTRACT from the compiled code. Once program hot regions are detected, the The high performance implementation of Java Virtual Machines dynamic compiler must be very aggressive in identifying good op- (JVM) and Just-In-Time (JIT) compilers is directed toward adaptive portunities for optimizations that can achieve higher total perform- compilation optimizations on the basis of online runtime profile in- ance. This tradeoff between compilation overhead and its perform- formation. This paper describes the design and implementation of a ance benefit is a crucial issue for dynamic compilers. dynamic optimization framework in a production-level Java JIT In the above context, the high performance implementation of Java compiler. Our approach is to employ a mixed mode interpreter and Virtual Machines (JVM) and Just-In-Time (JIT) compilers is mov- a three level optimizing compiler, supporting quick, full, and spe- ing toward exploitation of adaptive compilation optimizations on cial optimization, each of which has a different set of tradeoffs be- the basis of runtime profile information. Although there is a long tween compilation overhead and execution speed. A lightweight history of research on mntime feedback-directed optimizations sampling profiler operates continuously during the entire program's (FDO), many of these techniques are not directly applicable for use execution. When necessary, detailed information on runtime behav- in JVMs because of the requirements for programmer intervention. -

Virtual Machines Uses for Virtual Machines
Virtual Machines Uses for Virtual Machines • Virtual machine technology, often just called There are several uses for virtual machines: virtualization, makes one computer behave as several • Running several operating systems simultaneously on computers by sharing the resources of a single the same desktop. computer between multiple virtual machines. → • Each of the virtual machines is able to run a complete May need to run both Unix and Windows programs. → operating system. Useful in program development for testing programs on different platforms. • This is an old idea originally used in the IBM VM370 → Some legacy applications my not work with the system, released in 1972. standard system libraries. • The VM370 system was running on big mainframe • Running several virtual servers on the same hardware computers that easily could support multiple virtual server. machines. → One big server running many virtual machines is less • As expensive mainframes were replaced by cheap expensive than many small servers. microprocessors, barely capable of running one → With virtual machines it is possible to hand out application at a time, the interest in virtualization complete administration rights of a specific virtual vanished. machine to a customer. • For many years the trend was to replace big expensive computers with many small inexpensive computers. • Today single microprocessors have at least two cores each and is more powerful than the supercomputers of yesterday, thus most programs only need a fraction of the CPU-cycles available in a single microprocessor. • Together with the discovery that small machines are expensive to administrate, if you have too many of them, this has created a renewed interest in virtualization. -

Improving Whole Program Code Locality in Managed Runtimes
Dynamic Code Management: Improving Whole Program Code Locality in Managed Runtimes Xianglong Huang Brian T Lewis Kathryn S McKinley ∗ The University of Texas at Austin Intel Corporation The University of Texas at Austin [email protected] [email protected] [email protected] Abstract Keywords Locality, Code Layout, Code Generation, Performance Poor code locality degrades application performance by increasing Monitoring, Dynamic Optimization, Virtual Machines memory stalls due to instruction cache and TLB misses. This prob- lem is particularly an issue for large server applications written in 1. Introduction languages such as Java and C# that provide just-in-time (JIT) com- The gap between processor and memory speed continues to present pilation, dynamic class loading, and dynamic recompilation. How- a major performance bottleneck. Applications spend much of their ever, managed runtimes also offer an opportunity to dynamically time waiting because of cache and TLB misses. For example, on the profile applications and adapt them to improve their performance. Intel R Itanium R 2 processor, the SPEC JBB20001 server bench- This paper describes a Dynamic Code Management system (DCM) mark spends 54% of its cycles waiting for memory. While the ma- in a managed runtime that performs whole program code layout jority of stalls are from data access, instruction related misses such optimizations to improve instruction locality. as instruction cache misses, ITLB misses, and branch mispredic- We begin by implementing the widely used Pettis-Hansen algo- tions also contribute. Zorn [18] notes that Word XP, Excel Xp, and rithm for method layout to improve code locality. Unfortunately, Internet Explorer have large code working sets, and that much of this algorithm is too costly for a dynamic optimization system, the latency users perceive is caused by page faults fetching code. -

Adaptive Optimization in the Jalape ˜No
Adaptive Optimization in the Jalapeno˜ JVM £ £ £ £ £ Matthew Arnold ¢¡ Stephen Fink David Grove Michael Hind Peter F. Sweeney £ IBM T.J. Watson Research Center Rutgers University ¤¦¥¨§ © ¦ ! " #$¥%'&)(*¥,+ .- !+ /, 102 3¨&4/,¥,+ 2(52¥,+ ,6( ABSTRACT /2*6'¥2)/ Q" 3¨058¨¦ !520¦,52¥,m58T" ¨/,033¨T:/ Q" 3 *1,0/2: 1,58*6 =?¨58Y0J© ^ ,Z¥2,5C#;¦"*58¨ @¨F,058¨¦ ¥X58*!© ¥25C58¨ :!¨5C=?0¥: 9 (*58( ) ¨ 9$"¢2#$¦ :0 /,;58(03< 10/2 ,¥>=?33¨ @"¦>"¢29 7 ¦ 6,+XG?,¥2C58(*0¦34 10/2 ,¥: */3(* X,023¨Ta=?2 I¥8(/ Z0'¥ #A :0¦ */,B58¦(*¦C¥2" ¨¥258¨/052,D 3 *>#$,,6-*0'/ 69E6,/,52,C¦"9 58CRU 1033¨5203 69E®'¯yst¦°vj0¦ *aRU3#9E±²Xs¨²,uvj¥2T6¥252 :¥,<0¥;=B¢33j0¥;0 58¨ @¨F,058¨¦ *¥,+HG? ¨¥!"*0¦"¢I"¥2¢ 52¥J58K0¦/ ¨52,/,58( L#C58 6( b-j# :/,¢ 5 0¦¦0)¥2T6¥252 :¥?s.²'³'u ²,° °m´vE+cOL¥2,/,¦ * 0¦3¨0"6N *IO4 0"58¨DP)"58¨ Q¨F,058¨¦ SRUT6¥252, D<0!¥2T6¥252, V52!¥8( "9 M M =?0¦;¦#j :;¥2¦" ¨¥258¨/,0'52,K58(03j :0'/ *¥4 :¦!-,T¦ * "W5X3¨,06 *¦9E,'Y58(*0¦3C :0'/ *Z52,/2 3¨'T[0¦ *[ *0¦-3¨ 58 ¨¥)¥8¨ @"3¨@¥258052,'T:- T\ T 0 Q¨/,0¦33¨TJ¥23¨,/,58 \01¥8(-¥2,5>#q033 ¦ *' \,¥20/2X D¦ 3 Q#$,U-0/2 69EU,/52,X"58¨ Q¨F,0'58¨ ¥,+ ¢^ ,/(*52,D :,586¥?#$¦?¦"*58¨ @¨F,058¨¦ cf05252, @"*58 :52;#$6/¢(¥?" 9 I,¥2/2-K58X¢^ 52¢ ¥8-3¨L¥2T6¥252, _0/2¨52/,58('4-*0'¥2,Y ] 58¨ Q¨F,0'58¨ I¢~W5?¦ \" ¦0 µ5?¥8"W52¥,+BRUT6¥252 :¥ X58 ¨¥?/,0'589 0C#$, ¢058¨¦ Z#>58 ,0 ¥@=`¨58a0¥2T /2¦ *¦(*¥C/,' : b( ¨/,058¨¦ c+ ,'T! /¢3(* DRU3#9E±³Js ³6t,v858@45R"'5 {Hs ³'°vE58*1B{ M6z \" ,¥2¢ 5C0¦ d¨ @"3¨, 1¢ 52058¨¦ [¦#;58! *¢0¦3e0/2¨52,/58( ] 0¦¦0 (¥2589$ 9EG?¨ :X/,' Q"3¨J|$'¢¥8¨ S³+ ¯6}\s °³¦v8 P¸s.²®vE M M M6¶e· 5805f¥8(" -

Continuous Program Optimization Via Advanced Dynamic Compilation Techniques
Continuous Program Optimization via Advanced Dynamic Compilation Techniques Marco Festa, Nicole Gervasoni, Stefano Cherubin, Giovanni Agosta Politecnico di Milano, DEIB {marco2.festa,nicoleannamaria.gervasoni}@mail.polimi.it,[email protected],[email protected] ABSTRACT together with the growth of HPC infrastructures toward the Ex- In High Performance Computing, it is often useful to fine tune an ascale, will strain the ability of HPC centers to provide sufficient application code via recompilation of specific computational inten- personnel for these activities, due to the increased number of users. sive code fragments to leverage runtime knowledge. Traditional To ease this strain, practices such as autotuning and continuous compilers rarely provide such capabilities, but solutions such as optimisation [6–8] can be successfully applied to make the appli- libVC exist to allow C/C++ code to employ dynamic compilation. cation itself more aware of its performance and able to cope with We evaluate the impact of the introduction of Just-in-Time compila- platform heterogeneity and workload changes which are not pre- tion in a framework supporting partial dynamic (re-)compilation of dictable at compile-time, and for which traditional techniques such functions to provide continuous optimization in high performance as profile-guided optimisation may fail due to the difficulty offind- environments. We show that Just-In-Time solutions can have com- ing small profile data sets that are representative of the large ones parable performance in terms of code quality with respect to the actually used in the HPC runs. In these cases, which are becoming libVC alternatives, and it can provide smaller compilation over- more and more common [9], dynamic approaches can prove more head.