ISO/IEC International Standard 10646-1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Submits Addl Info Re SER Open Items.Forwards Draft Copy of Pending
. * .' * ** 4 LONG ISLAND LIGHTING COM PANY #Ed"O w SHOREHAM NUCLEAR POWER STATION P.O. DOX Gia, NORTH COUNTRY ROAD e WADING RIVER, N.Y.11792 ? February 5, 1979 SNRC-357 Mr. Harold R. Denton, Director Office of Nuclear Reacter Regulation U. S. Nuclear Regulatory Commission Washington, D. C. 20555 Shoreham Nuclear Power Station - Unit 1 Docket No. 50-322 Dear Mr. Denton: During a meeting held in your office on Decemoer 14, 1978, the status of tM remaining SER open items were discussed with the NRC Staff. As a result of those discussions, it was agreed that we would provide additional information clarifying a number of the open items. Enclosed herewith are fifteen (15) sets of the additional information provided in response to those requests for SER open items numbered 6, 7, 11, 13, 19, and 20 plus confirmatory issues numbered 4 and 12. In addition, we are enclosing draft copies of a pending FSAR figure change to reflect an improvement in the intake canal slope stability, the bases of which are discussed in FSAR Section 2.5.5 and Appendix 2L. Subsequent submittals will be made on or about Feb uary 28, 1979 which will provide additional information relative to SER open items 2, 5, and 20 plus confirmatory issues 1, 8, 15, 16 and 17. Information for any remaining Applicant-action items will be forwarded to the NRC as it becomes available. - ry t uly yours, MS DOCUME;T CO?iTNilS .; POOR QUAUTY PAGES o - [D M . i . P. No arro, Project' Manager Shoreham Nuclear Power Station JPM/cl 90 Encls. -

Unicode Request for Cyrillic Modifier Letters Superscript Modifiers
Unicode request for Cyrillic modifier letters L2/21-107 Kirk Miller, [email protected] 2021 June 07 This is a request for spacing superscript and subscript Cyrillic characters. It has been favorably reviewed by Sebastian Kempgen (University of Bamberg) and others at the Commission for Computer Supported Processing of Medieval Slavonic Manuscripts and Early Printed Books. Cyrillic-based phonetic transcription uses superscript modifier letters in a manner analogous to the IPA. This convention is widespread, found in both academic publication and standard dictionaries. Transcription of pronunciations into Cyrillic is the norm for monolingual dictionaries, and Cyrillic rather than IPA is often found in linguistic descriptions as well, as seen in the illustrations below for Slavic dialectology, Yugur (Yellow Uyghur) and Evenki. The Great Russian Encyclopedia states that Cyrillic notation is more common in Russian studies than is IPA (‘Transkripcija’, Bol’šaja rossijskaja ènciplopedija, Russian Ministry of Culture, 2005–2019). Unicode currently encodes only three modifier Cyrillic letters: U+A69C ⟨ꚜ⟩ and U+A69D ⟨ꚝ⟩, intended for descriptions of Baltic languages in Latin script but ubiquitous for Slavic languages in Cyrillic script, and U+1D78 ⟨ᵸ⟩, used for nasalized vowels, for example in descriptions of Chechen. The requested spacing modifier letters cannot be substituted by the encoded combining diacritics because (a) some authors contrast them, and (b) they themselves need to be able to take combining diacritics, including diacritics that go under the modifier letter, as in ⟨ᶟ̭̈⟩BA . (See next section and e.g. Figure 18. ) In addition, some linguists make a distinction between spacing superscript letters, used for phonetic detail as in the IPA tradition, and spacing subscript letters, used to denote phonological concepts such as archiphonemes. -

+1. Introduction 2. Cyrillic Letter Rumanian Yn
MAIN.HTM 10/13/2006 06:42 PM +1. INTRODUCTION These are comments to "Additional Cyrillic Characters In Unicode: A Preliminary Proposal". I'm examining each section of that document, as well as adding some extra notes (marked "+" in titles). Below I use standard Russian Cyrillic characters; please be sure that you have appropriate fonts installed. If everything is OK, the following two lines must look similarly (encoding CP-1251): (sample Cyrillic letters) АабВЕеЗКкМНОопРрСсТуХхЧЬ (Latin letters and digits) Aa6BEe3KkMHOonPpCcTyXx4b 2. CYRILLIC LETTER RUMANIAN YN In the late Cyrillic semi-uncial Rumanian/Moldavian editions, the shape of YN was very similar to inverted PSI, see the following sample from the Ноул Тестамент (New Testament) of 1818, Neamt/Нямец, folio 542 v.: file:///Users/everson/Documents/Eudora%20Folder/Attachments%20Folder/Addons/MAIN.HTM Page 1 of 28 MAIN.HTM 10/13/2006 06:42 PM Here you can see YN and PSI in both upper- and lowercase forms. Note that the upper part of YN is not a sharp arrowhead, but something horizontally cut even with kind of serif (in the uppercase form). Thus, the shape of the letter in modern-style fonts (like Times or Arial) may look somewhat similar to Cyrillic "Л"/"л" with the central vertical stem looking like in lowercase "ф" drawn from the middle of upper horizontal line downwards, with regular serif at the bottom (horizontal, not slanted): Compare also with the proposed shape of PSI (Section 36). 3. CYRILLIC LETTER IOTIFIED A file:///Users/everson/Documents/Eudora%20Folder/Attachments%20Folder/Addons/MAIN.HTM Page 2 of 28 MAIN.HTM 10/13/2006 06:42 PM I support the idea that "IA" must be separated from "Я". -

An Exploratory Study on Functionally Graded Materials with Applications to Multilayered Pavement Design
An Exploratory Study on Functionally Graded Materials with Applications to Multilayered Pavement Design Ernie Pan, Wael Alkasawneh, and Ewan Chen Prepared in cooperation with The Ohio Department of Transportation and the U.S. Department of Transportation, Federal Highway Administration State Job Number 134256 August 2007 1. Report No. 2. Government Accession No. 3. Recipient’s Catalog No. FHWA/OH-2007/12 4. Title and subtitle 5. Report Date An Exploratory Study on Functionally Graded Materials with August 2007 Applications to Multilayered Pavement Design 6. Performing Organization Code 7. Author(s) 8. Performing Organization Report No. Ernie Pan, Wael Alkasawneh, Ewan Chen 10. Work Unit No. (TRAIS) 9. Performing Organization Name and Address 11. Contract or Grant No. 134256 Department of Civil Engineering The University of Akron 13. Type of Report and Period Akron, OH 44325-3905 Covered Final Report 12. Sponsoring Agency Name and Address 14. Sponsoring Agency Code Ohio Department of Transportation 1980 West Broad Street Columbus, OH 43223 15. Supplementary Notes 16. Abstract The response of flexible pavement is largely influenced by the resilient modulus of the pavement profile. Different methods/approaches have been adopted in order to estimate or measure the resilient modulus of each layer assuming an average modulus within the layer. In order to account for the variation in the modulus of elasticity with depth within a layer in elastic pavement analysis, which is due to temperature or moisture variation with depth, the layer should be divided into several sublayers and the modulus should be gradually varied between the layers. A powerful and innovative computer program has been developed for elastic pavement analysis that overcomes the limitations of the existing pavement analysis programs. -

Fgekpy Izns”K Ljdkj “Kgjh Fodkl Fohkkx La[;K% ;W0mh0&, ¼3½&7@2011&1 F”Keyk&2 2&9&2015
fgekpy izns”k ljdkj “kgjh fodkl foHkkx la[;k% ;w0Mh0&, ¼3½&7@2011&1 f”keyk&2 2&9&2015 vf/klwpuk fgekpy izns”k uxjikfydk fuokZpu fu;e] 2015 dk izk:Ik] fgekpy izns”k uxjikfydk vf/kfu;e] 1994 ¼1994 dk vf/kfu;e la[;kad 13½ dh /kkjk 279 ds micU/kksa ds v/khu ;Fkk visf{kr ds vuqlkj] bl foHkkx dh lela[;d vf/klwpuk rkjh[k 27 tqykbZ] 2015 }kjk jkti=] fgekpy izns”k esa 29 tqykbZ] 2015 dks tu lk/kkj.k ls vk{ksi ¼iksa½ vkSj lq>ko ¼oksa½ dks vkeaf=r djus ds fy, izdkf”kr fd;k x;k Fkk ; vkSj fu;r vof/k ds Hkhrj bl fufeÙk dksbZ vk{ksi ¼iksa½ vkSj lq>ko ¼oksa½ izkIr ugha gq, gSa ; vr% fgekpy izns”k ds jkT;iky] jkT; vk;ksx ds ijke”kZ ls fgekpy izns”k uxjikfydk vf/kfu;e] 1994 ¼1994 dk vf/kfu;e la[;kad 13½ dh /kkjk 279 vkSj 304 }kjk iznŸk “kfDr;ksa dk iz;ksx djrs gq,] vf/kfu;e ds iz;kstuksa dks dk;kZfUor djus ds fy, fuEufyf[kr fu;e cukrs gSa] vFkkZr~ %& v/;k;&1 izkjfEHkd 1. laf{kIr uke -& bu fu;eksa dk laf{kIr uke fgekpy izns”k uxjikfydk fuokZpu fu;e] 2015 gSA 2. ifjHkk’kk,¡-&¼1½ bu fu;eksa esa] tc rd fd dksbZ ckr fo’k; ;k lanHkZ esa fo:) u gks]&& ¼d½ “vf/kfu;e ” ls fgekpy izns”k uxjikfydk vf/kfu;e] 1994 ¼1994 dk vf/kfu;e la[;kad 13½ vfHkizsr gS ; ¼[k½ “vfHkdrkZ ” ls fdlh fuokZpu esa] vH;FkhZ }kjk] fyf[kr esa] bu fu;eksa ds iz;kstu ds fy, vfHkdrkZ cuus ds fy, fu;qDr dksbZ O;fDr vfHkizsr gsS; ¼x½ “erisVh ” ls fuokZpdksas }kjk eri= j[kus ds fy, iz;qDr dksbZ isVh] cSx ;k vU; ik= vfHkizsr gS vkSj blds vUrZxr bySDVªkWfud oksfVax e”khu Hkh gksxh ; ¼?k½ “v/;{k ” ls fuokZfpr lnL;ksa }kjk v/;{k dk in /kkj.k djus vkSj v/;{k ds d`R;ksa dk ikyu djus ds fy, v/;{k ds -

Phonics Spelling Words Grade K 1 2.CA
Benchmark Advance Grade 1 Phonics Skills and Spelling Words Unit Week Phonics Spiral Review Spelling Words had, has, pack, ran, see, she, back, cap, sack, 1 Short a N/A pans Short i; 1 2 Short a big, him, hit, kick, kids, lid, little, you, fit, lips Plural Nouns Short o; box, doll, hot, jump, lock, mop, one, rock, 3 Short i Double Final Consonants tops, cots ten, jet, fed, neck, let, mess, look, are, beg, 1 Short e Short o sell Short u; come, cup, duck, dull, here, nut, rug, cub, sun, 2 2 Short e Inflectional Ending -s cuff class, clock, flat, glad, plan, put, what, slip, 3 l-Blends Short u black, plums r-Blends: br, cr, dr, fr, gr, pr, tr; brim, crab, trim, went, frog, drip, grass, prop, 1 l-Blends Singular Possessives trip, now s-Blends: sk, sl, sm, sn, sp, st, sw; skip, step, skin, smell, out, was, spin, sled, 3 2 r-Blends Contractions with ’s spot, slip Final Consonant Blends: nd, nk, nt, mp, st; jump, and, pink, hand, nest, went, who, good, 3 s-Blends Inflectional Ending -ed trunk, best Consonant Digraphs th, sh, ng; bath, bring, our, shop, shut, these, thing, 1 Final Consonant Blends nd, nk, nt, mp, st Inflectional Ending -ing wish, this, rang Consonant Digraphs ch, tch, wh; Consonant Digraphs chop, lunch, catch, check, once, when, whiff, 4 2 Closed Syllables th, sh, ng much, match, hurt Three-Letter Blends scr, spl, spr, squ, str; split, strap, scrub, squid, stretch, scratch, 3 Consonant Digraphs ch, tch, wh Plurals (-es) because, when, sprint, squish take, made, came, plate, brave, game, right, 1 Long a (final -e) Three-Letter -

Sacred Concerto No. 6 1 Dmitri Bortniansky Lively Div
Sacred Concerto No. 6 1 Dmitri Bortniansky Lively div. Sla va vo vysh nikh bo gu, sla va vo vysh nikh bo gu, sla va vo Sla va vo vysh nikh bo gu, sla va vo vysh nikh bo gu, 8 Sla va vo vysh nikh bo gu, sla va, Sla va vo vysh nikh bo gu, sla va, 6 vysh nikh bo gu, sla va vovysh nikh bo gu, sla va vovysh nikh sla va vo vysh nikh bo gu, sla va vovysh nikh bo gu, sla va vovysh nikh 8 sla va vovysh nikh bo gu, sla va vovysh nikh bo gu sla va vovysh nikh bo gu, sla va vovysh nikh bo gu 11 bo gu, i na zem li mir, vo vysh nikh bo gu, bo gu, i na zem li mir, sla va vo vysh nikh, vo vysh nikh bo gu, i na zem 8 i na zem li mir, i na zem li mir, sla va vo vysh nikh, vo vysh nikh bo gu, i na zem i na zem li mir, i na zem li mir 2 16 inazem li mir, sla va vo vysh nikh, vo vysh nikh bo gu, inazem li mir, i na zem li li, i na zem li mir, sla va vo vysh nikh bo gu, i na zem li 8 li, inazem li mir, sla va vo vysh nikh, vo vysh nikh bo gu, i na zem li, ina zem li mir, vo vysh nikh bo gu, i na zem li 21 mir, vo vysh nikh bo gu, vo vysh nikh bo gu, i na zem li mir, i na zem li mir, vo vysh nikh bo gu, vo vysh nikh bo gu, i na zem li mir, i na zem li 8 mir, i na zem li mir, i na zem li mir, i na zem li, i na zem li mir,mir, i na zem li mir, i na zem li mir, inazem li, i na zem li 26 mir, vo vysh nikh bo gu, i na zem li mir. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Kyrillische Schrift Für Den Computer
Hanna-Chris Gast Kyrillische Schrift für den Computer Benennung der Buchstaben, Vergleich der Transkriptionen in Bibliotheken und Standesämtern, Auflistung der Unicodes sowie Tastaturbelegung für Windows XP Inhalt Seite Vorwort ................................................................................................................................................ 2 1 Kyrillische Schriftzeichen mit Benennung................................................................................... 3 1.1 Die Buchstaben im Russischen mit Schreibschrift und Aussprache.................................. 3 1.2 Kyrillische Schriftzeichen anderer slawischer Sprachen.................................................... 9 1.3 Veraltete kyrillische Schriftzeichen .................................................................................... 10 1.4 Die gebräuchlichen Sonderzeichen ..................................................................................... 11 2 Transliterationen und Transkriptionen (Umschriften) .......................................................... 13 2.1 Begriffe zum Thema Transkription/Transliteration/Umschrift ...................................... 13 2.2 Normen und Vorschriften für Bibliotheken und Standesämter....................................... 15 2.3 Tabellarische Übersicht der Umschriften aus dem Russischen ....................................... 21 2.4 Transliterationen veralteter kyrillischer Buchstaben ....................................................... 25 2.5 Transliterationen bei anderen slawischen -

AIX Globalization
AIX Version 7.1 AIX globalization IBM Note Before using this information and the product it supports, read the information in “Notices” on page 233 . This edition applies to AIX Version 7.1 and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 2010, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document............................................................................................vii Highlighting.................................................................................................................................................vii Case-sensitivity in AIX................................................................................................................................vii ISO 9000.....................................................................................................................................................vii AIX globalization...................................................................................................1 What's new...................................................................................................................................................1 Separation of messages from programs..................................................................................................... 1 Conversion between code sets............................................................................................................. -

Unit #1 Short a and I Unit #2 Short O and E Land Crop Plan Clock Stand
Unit #1 Short a and i Unit #2 Short o and e land crop plan clock stand drop act plot last block band flock grand test stamp spent sand left stick sled trip spend thing west lift tent swim desk list nest Unit #3 Short u sound Spelling Unit #4 /oi/ and /ou/ lunch boil until join buzz voice stuff oil dull point study soil uncle proud cuff loud under house cover cloud become sound nothing round month south love found none ground Unit #5 ew and oo Unit #7 Vowel-Consonant-e crew state news face drew pave knew flame threw skate chew plane loose slide school size smooth prize pool smile shoot close roof globe fool smoke balloon broke choose stone Unit #8 Long a: ai, ay Unit #9 Long e: ee, ea aid sheep chain street mail wheels paint cheese plain sweet main dream pail east laid treat paid mean pay peace tray real maybe leave lay stream always teacher away heat Unit #10 Long i: i, igh Unit #11 Long o: ow, oa, o night snow bright load find almost light row wild soak high window blind foam fight most sight flow kind goat sign throw knight float mild blow right below sigh soap Unit #13 sh,ch,tch,wr,ck Unit #14 Consonants /j/,/s/ shape change church age watch large father page wrap fence check space finish center sharp since mother price write ice catch dance chase pencil shall slice thick place wrote city Unit #15 Digraphs, Clusters Unit #16 Schwa Sound shook afraid flash around fresh upon splash never speech open stitch animal scratch ever switch about stretch again strong another string couple spring awake think over cloth asleep brook above Unit -
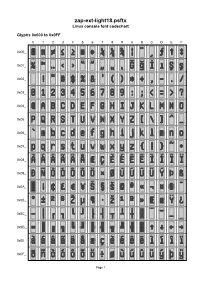
Zap-Ext-Light18.Psftx Linux Console Font Codechart
zap-ext-light18.psftx Linux console font codechart Glyphs 0x000 to 0x0FF 0 1 2 3 4 5 6 7 8 9 A B C D E F 0x00_ 0x01_ 0x02_ 0x03_ 0x04_ 0x05_ 0x06_ 0x07_ 0x08_ 0x09_ 0x0A_ 0x0B_ 0x0C_ 0x0D_ 0x0E_ 0x0F_ Page 1 Glyphs 0x100 to 0x1FF 0 1 2 3 4 5 6 7 8 9 A B C D E F 0x10_ 0x11_ 0x12_ 0x13_ 0x14_ 0x15_ 0x16_ 0x17_ 0x18_ 0x19_ 0x1A_ 0x1B_ 0x1C_ 0x1D_ 0x1E_ 0x1F_ Page 2 Font information 0x013 U+2039 SINGLE LEFT-POINTING ANGLE QUOTATION MARK Filename: zap-ext-light18.psftx PSF version: 1 0x014 U+203A SINGLE RIGHT-POINTING ANGLE QUOTATION MARK Glyph size: 8 × 18 pixels Glyph count: 512 0x015 U+201C LEFT DOUBLE QUOTATION Unicode font: Yes (mapping table present) MARK, U+201F DOUBLE HIGH-REVERSED-9 QUOTATION MARK Unicode mappings 0x016 U+201D RIGHT DOUBLE 0x000 U+FFFD REPLACEMENT QUOTATION MARK, CHARACTER U+02EE MODIFIER LETTER DOUBLE 0x001 U+03C0 GREEK SMALL LETTER PI APOSTROPHE 0x002 U+2260 NOT EQUAL TO 0x017 U+201E DOUBLE LOW-9 QUOTATION MARK 0x003 U+2264 LESS-THAN OR EQUAL TO 0x018 U+2E42 DOUBLE LOW-REVERSED-9 0x004 U+2265 GREATER-THAN OR EQUAL QUOTATION MARK TO 0x019 U+2E41 REVERSED COMMA, 0x005 U+25A0 BLACK SQUARE, U+02CE MODIFIER LETTER LOW U+25AC BLACK RECTANGLE, GRAVE ACCENT U+25AE BLACK VERTICAL 0x01A U+011E LATIN CAPITAL LETTER G RECTANGLE, WITH BREVE U+25FC BLACK MEDIUM SQUARE, U+25FE BLACK MEDIUM SMALL 0x01B U+011F LATIN SMALL LETTER G SQUARE, WITH BREVE U+2B1B BLACK LARGE SQUARE, 0x01C U+0130 LATIN CAPITAL LETTER I U+220E END OF PROOF WITH DOT ABOVE 0x006 U+25C6 BLACK DIAMOND, 0x01D U+0131 LATIN SMALL LETTER U+2666 BLACK DIAMOND SUIT,