Text and Braille Computer Translation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Braillesketch: a Gesture-Based Text Input Method for People with Visual Impairments Mingzhe Li, Mingming Fan, Khai N
Session: Interaction Techniques and Frameworks ASSETS'17, Oct. 29–Nov. 1, 2017, Baltimore, MD, USA BrailleSketch: A Gesture-based Text Input Method for People with Visual Impairments Mingzhe Li, Mingming Fan, Khai N. Truong Department of Computer Science University of Toronto [email protected], [email protected], [email protected] ABSTRACT onscreen keyboard with screen reader software, such as Apple’s In this paper, we present BrailleSketch, a gesture-based text input VoiceOver. However, this approach results in a very low text method on touchscreen smartphones for people with visual entry speed [4]. Alternatively, people can use speech recognition impairments. To input a letter with BrailleSketch, a user simply software to input text at a much faster rate [3]. However, speaking sketches a gesture that passes through all dots in the in public places may not always be appropriate and can introduce corresponding Braille code for that letter. BrailleSketch allows privacy concerns. A growing body of research has been exploring users to place their fingers anywhere on the screen to begin a ways to leverage the user’s ability to perform touch and multi- gesture and draw the Braille code in many ways. To encourage touch gesture inputs on mobile devices. For example, BrailleTap users to type faster, BrailleSketch does not provide immediate [9], TypeInBraille [15], Perkinput [4], and BrailleEasy [23] enable letter-level audio feedback but instead provides word-level audio the user to type Braille by performing multiple taps sequentially to feedback. It uses an auto-correction algorithm to correct typing specify the dot codes for the desire letter—this can be time errors. -

Průvodce Formátováním Braillského Textu V Editoru Duxbury
Průvodce formátováním braillského textu v editoru Duxbury Břetislav Verner, CSc. © Spektra, 2019 Průvodce editorem DBT v českém prostředí OBSAH Předmluva ........................................................................................................ 8 Úvod .................................................................................................................. 8 Co a kdy z Průvodce číst ........................................................................................ 8 Zpřístupnění ............................................................................................................ 9 Instalace DBT ................................................................................................. 10 Jednoduchá instalace ........................................................................................... 10 Krok 1: Spuštění instalátoru ..........................................................................................10 Krok 2: Licenční podmínky............................................................................................11 Krok 3: Údaje o uživateli ...............................................................................................12 Krok 4: Typ nastavení ...................................................................................................13 Krok 5: Potvrzení ..........................................................................................................13 Krok 6: Dokončení ........................................................................................................14 -

Independent-Living-Mini-Catalogue
Alternative Thinking INDEPENDENT LIVING DAILY LIVING AIDS MAGNIFIERS ALERT SYSTEMS ASSISTIVE DEVICES Page 24 Page 29 Page 4 Page 16 ...AND MUCH MORE AUDITORY AND HEARING IMPAIRMENT BLIND & VISUALLY IMPAIRED Tel: +27 (0) 86 111 3973 Email: [email protected] Web: www.editmicro.co.za DOCUMENT CAMERAS Solo 8 Ultra Ultra Plus 8 10 Solo 8 Plus Features Ultra 8 Features Ultra 10 Features The HoverCam Solo 8 is a new, The HoverCam Ultra 8 is the the first The HoverCam Ultra 10 takes the state-of-the-art document camera document camera with HDMI, VGA document camera experience to that will revolutionize learning in & SuperSpeed USB 3.0 outputs and a whole new level with a 7.1” HD your classroom. Record videos or includes an LCD monitor for preview MultiTouch screen. Pinch to Zoom, capture images straight to your and touchscreen control. Record Annotate, and Cast 4K video to any PC or Mac with the world’s first videos or capture images straight display. SuperSpeed USB3.0 Document to your PC or Mac with the world’s Camera. Use the HoverCam Solo first SuperSpeed USB3.0 Document Download your favorite apps and 8 to bring your classroom into the Camera. experience Augmented Reality and digital age! The HoverCam Solo Optical Character Recognition right 8 does everything except travel Specifications from the device. through time. • 8 megapixel camera Specifications • 60FPS FullMotion HD Specifications • HDMI VGA • Battery Powered • 8 megapixel camera • USB 3.0 SuperSpeed • 3 Wireless Casting Modes • 3x magnification with 8 million • 12x Optical Zoom Equivalent • 16 MP Camer Sensor uncompressed pixels • LCD Control Panel • 4K @ 30FPS Lesson Recording • 10x magnification mechanically • 4x ASR Zoom, 8x Interpolated • WiFi and Bluetooth Connectivity • 8x magnification digitally with Digital Zoom, 10x Mechanical • Powerful Android Operating System interpolation Zoom. -

Education Specialist Teaching Performance Expectations (Tpes) As These Apply to the Subjects and Specialties Authorized by the Credential
Preliminary Education Specialist Teaching Credential Preconditions, Program Standards, and Teaching Performance Expectations Commission on Teacher Credentialing Standards and Performance Expectations Adopted August 2018 Published February 2020 Handbook Updated April 2021 This publication by the Commission on Teacher Credentialing is not copyright. It may be reproduced in the public interest, but proper attribution is requested. Commission on Teacher Credentialing 1900 Capitol Avenue Sacramento, California 95811 Commission on Teacher Credentialing Program Standards Preliminary Education Specialist Teaching Credential: Preconditions adopted December 2008, updated February 2017 Program Standards adopted August 2018 Teaching Performance Expectations (TPEs) adopted August 2018 Table of Contents Preliminary Education Specialist Teaching Credential Preconditions, Program Standards, and Teaching Performance Expectations i Table of Contents i Preliminary Education Specialist Credential Preconditions 1 Preliminary Education Specialist Credential Program Standards (2018) 3 Standard 1: Program Design and Curriculum 3 Standard 2: Preparing Candidates to Master the Teaching Performance Expectations (TPEs) 4 Standard 3: Clinical Practice 4 A. Organization of Clinical Practice Experiences 4 B. Preparation of Faculty and/or Site Supervisors and/or Program Directors 6 C. Criteria for School Placements 6 D. Criteria for the Selection of District Employed Supervisors 6 (also may be known as the 6 Standard 4: Monitoring, Supporting, and Assessing Candidate -

MOHAMMED SAMI FADALI Resume
MOHAMMED SAMI FADALI CURRICULUM VITAE PRESENT POSITION: Professor and Chair Department of Electrical & Biomedical Engineering College of Engineering University of Nevada Reno, NV 89557-0153 PRINCIPAL PAST POSITION: Assistant Professor, King Abdul Aziz University, Jeddah, 1981-83. PLACE AND DATE OF BIRTH: Cairo, Egypt, May 22, 1952. NATIONALITY: U.S. LANGUAGES: English, Arabic, Spanish, French. PERMANENT ADDRESS: 3959 Regal Dr., Reno, NV 89503 Work Phone: (775)784-6951 Home Phone: (775)747-4832 MARITAL STATUS: Married RESEARCH INTERESTS: Intelligent control, fuzzy logic, fault detection, control of renewable energy systems, structural control, random signals, mathematical modeling of biological systems, engineering education. EDUCATION: DEGREE DEPARTMENT UNIVERSITY YEAR B.S. Electrical Engineering Cairo Univ., Cairo, Egypt. 1974 M.S. Control Systems Center UMIST, Manchester, England 1977 Ph.D. Electrical Engineering Univ. of Wyoming, Laramie, Wy, USA 1980 POSITIONS HELD: University of Nevada-Reno, Professor 1995-Present, Associate Professor 1989 to 1995, Assistant Professor, 1985-89, tenured 1991 Duties include teaching, funded research, graduate and undergraduate advising, Assessment Coordinator. Chairman Department Curriculum Committee, Past: Graduate Student MOHAMMED SAMI FADALI PAGE 2 Coordinator and Chair of Graduate Admission Committee 1989-98, Member Univeristy Conflict of Interest Committee, Past Chair College Personnel Committee. Colorado State University, Post Doctoral Fellow, 1984-1985 Investigated problems in robotics, satellite maneuvering,biochemical process control and physiological system identification. King Abdul Aziz University, Jeddah, Assistant Professor, 1981-1983. Duties included teaching, undergraduate advising and research. Participated in starting a new bioengineering program. University of Wyoming, Teaching Assistant, 1979-80. Taught several introductory electrical engineering labs. Cairo Research Center, Engineer, 1975. Participated in research on computer control of electrical machines. -
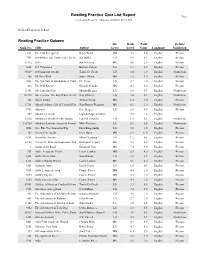
Reading Practice Quiz List Report Page 1 Accelerated Reader®: Thursday, 05/20/10, 09:41 AM
Reading Practice Quiz List Report Page 1 Accelerated Reader®: Thursday, 05/20/10, 09:41 AM Holden Elementary School Reading Practice Quizzes Int. Book Point Fiction/ Quiz No. Title Author Level Level Value Language Nonfiction 661 The 18th Emergency Betsy Byars MG 4.1 3.0 English Fiction 7351 20,000 Baseball Cards Under the Sea Jon Buller LG 2.6 0.5 English Fiction 11592 2095 Jon Scieszka MG 4.8 2.0 English Fiction 6201 213 Valentines Barbara Cohen LG 3.1 2.0 English Fiction 30629 26 Fairmount Avenue Tomie De Paola LG 4.4 1.0 English Nonfiction 166 4B Goes Wild Jamie Gilson MG 5.2 5.0 English Fiction 9001 The 500 Hats of Bartholomew CubbinsDr. Seuss LG 3.9 1.0 English Fiction 413 The 89th Kitten Eleanor Nilsson MG 4.3 2.0 English Fiction 11151 Abe Lincoln's Hat Martha Brenner LG 2.6 0.5 English Nonfiction 61248 Abe Lincoln: The Boy Who Loved BooksKay Winters LG 3.6 0.5 English Nonfiction 101 Abel's Island William Steig MG 6.2 3.0 English Fiction 13701 Abigail Adams: Girl of Colonial Days Jean Brown Wagoner MG 4.2 3.0 English Nonfiction 9751 Abiyoyo Pete Seeger LG 2.8 0.5 English Fiction 907 Abraham Lincoln Ingri & Edgar d'Aulaire 4.0 1.0 English 31812 Abraham Lincoln (Pebble Books) Lola M. Schaefer LG 1.5 0.5 English Nonfiction 102785 Abraham Lincoln: Sixteenth President Mike Venezia LG 5.9 0.5 English Nonfiction 6001 Ace: The Very Important Pig Dick King-Smith LG 5.0 3.0 English Fiction 102 Across Five Aprils Irene Hunt MG 8.9 11.0 English Fiction 7201 Across the Stream Mirra Ginsburg LG 1.2 0.5 English Fiction 17602 Across the Wide and Lonesome Prairie:Kristiana The Oregon Gregory Trail Diary.. -

Texture Perception in Sighted and Blind Observers
Perception & Psychophysics /989. 45 (I). 49-54 Texture perception in sighted and blind observers MORTON A. HELLER Winston-Salem State University, Winston-Salem, North Carolina The purpose of the present study was to evaluate the utility of visual imagery for texture per ception. In Experiment 1, sighted, early-blind, and late-blind observers made relative smooth ness judgments of abrasive surfaces using active or passive touch. In Experiment 2, subjects com pared vision and touch in the accuracy of smoothness detection, using a broad range of textures, including very fine surfaces. No differences appeared between the sighted and the blind, and it did not matter iftouch were active or passive. Vision and touch showed similar performance with relatively coarse textures, but touch was superior to vision for much finer surface textures. The results were consistent with the notion that visual coding oftactual stimuli is not advantageous (or necessary) for texture perception, since touch may hold advantages for the detection of the smoothness of surfaces. The present study was directed toward an evaluation subjected to tilt. Although the benefits of visual imagery ofthe necessity ofvisual imagery for texture perception. are likely to be pronounced in form perception, it is not Some researchers have claimed that visual images are known whether visualization aids in texture judgments. necessary for tactual perception of form by sighted in One would expect that observers would tend to visual dividuals (e.g., Pick, 1974). There are numerous reports ize for stimulus dimensions in which vision provides su of the benefits of visual imagery for memory in the sighted perior performance, as in form perception. -

Economic and Social Council Distr.: General 22 February 2021
United Nations E/C.12/2021/SR.5 Economic and Social Council Distr.: General 22 February 2021 Original: English Committee on Economic, Social and Cultural Rights Sixty-ninth session Summary record of the 5th meeting* Held via videoconference, on Wednesday, 17 February 2021, at 12.30 p.m. Central European Time Chair: Mr. Zerbini Ribeiro Leão Contents Consideration of reports (a) Reports submitted by States parties in accordance with articles 16 and 17 of the Covenant Seventh periodic report of Finland * No summary records were issued for the 2nd to 4th meetings. This record is subject to correction. Corrections should be set forth in a memorandum and also incorporated in a copy of the record. They should be sent within one week of the date of the present record to the Documents Management Section ([email protected]). Any corrected records of the public meetings of the Committee at this session will be reissued for technical reasons after the end of the session. GE.21-02222 (E) 190221 220221 E/C.12/2021/SR.5 The meeting was called to order at 12.35 p.m. Consideration of reports (a) Reports submitted by States parties in accordance with articles 16 and 17 of the Covenant Seventh periodic report of Finland (E/C.12/FIN/7; E/C.12/FIN/QPR/7) 1. At the invitation of the Chair, the delegation of Finland joined the meeting. 2. Ms. Oinonen (Finland) said that the promotion of human rights was a clear cross- cutting objective in the Government’s programme. The Government was currently preparing its third National Action Plan on Fundamental and Human Rights, which would focus on the development of monitoring. -

Catalogo De Livros Braille
BIBLIOTECA NACIONAL DE PORTUGAL ÁREA DE LEITURA PARA DEFICIENTES VISUAIS LIVROS BRAILLE Catálogo de Autores - 2011 - BIBLIOTECA NACIONAL DE PORTUGAL - Área de Leitura para Deficientes Visuais Campo Grande, 83 - 1749-081 Lisboa Tel.: 217982129; Fax: 217982138 www.bnportugal.pt E-mail: [email protected] ÍNDICE NOTA PRÉVIA ........................................................................................................ 3 A .......................................................................................................................... 4 B ........................................................................................................................ 11 C ........................................................................................................................ 18 D ........................................................................................................................ 30 E ........................................................................................................................ 34 F ........................................................................................................................ 36 G ........................................................................................................................ 41 H ........................................................................................................................ 46 I ......................................................................................................................... -

Guidelines and Standards for Tactile Graphics, 2010
Guidelines and Standards for Tactile Graphics, 2010 Developed as a Joint Project of the Braille Authority of North America and the Canadian Braille Authority L'Autorité Canadienne du Braille Published by The Braille Authority of North America ©2011 by The Braille Authority of North America All rights reserved. This material may be downloaded and printed, but not altered or sold. The mission and purpose of the Braille Authority of North America are to assure literacy for tactile readers through the standardization of braille and/or tactile graphics. BANA promotes and facilitates the use, teaching, and production of braille. It publishes rules, interprets, and renders opinions pertaining to braille in all existing codes. It deals with codes now in existence or to be developed in the future, in collaboration with other countries using English braille. In exercising its function and authority, BANA considers the effects of its decisions on other existing braille codes and formats; the ease of production by various methods; and acceptability to readers. For more information and resources, visit www.brailleauthority.org. ii Canadian Braille Authority (CBA) Members CNIB (Canadian National Institute for the Blind) Canadian Council of the Blind Braille Authority of North America (BANA) Members American Council of the Blind, Inc. (ACB) American Foundation for the Blind (AFB) American Printing House for the Blind (APH) Associated Services for the Blind (ASB) Association for Education & Rehabilitation of the Blind & Visually Impaired (AER) Braille Institute of America (BIA) California Transcribers & Educators for the Blind and Visually Impaired (CTEBVI) CNIB (Canadian National Institute for the Blind) The Clovernook Center for the Blind (CCBVI) National Braille Association, Inc. -

A STUDY of WRITING Oi.Uchicago.Edu Oi.Uchicago.Edu /MAAM^MA
oi.uchicago.edu A STUDY OF WRITING oi.uchicago.edu oi.uchicago.edu /MAAM^MA. A STUDY OF "*?• ,fii WRITING REVISED EDITION I. J. GELB Phoenix Books THE UNIVERSITY OF CHICAGO PRESS oi.uchicago.edu This book is also available in a clothbound edition from THE UNIVERSITY OF CHICAGO PRESS TO THE MOKSTADS THE UNIVERSITY OF CHICAGO PRESS, CHICAGO & LONDON The University of Toronto Press, Toronto 5, Canada Copyright 1952 in the International Copyright Union. All rights reserved. Published 1952. Second Edition 1963. First Phoenix Impression 1963. Printed in the United States of America oi.uchicago.edu PREFACE HE book contains twelve chapters, but it can be broken up structurally into five parts. First, the place of writing among the various systems of human inter communication is discussed. This is followed by four Tchapters devoted to the descriptive and comparative treatment of the various types of writing in the world. The sixth chapter deals with the evolution of writing from the earliest stages of picture writing to a full alphabet. The next four chapters deal with general problems, such as the future of writing and the relationship of writing to speech, art, and religion. Of the two final chapters, one contains the first attempt to establish a full terminology of writing, the other an extensive bibliography. The aim of this study is to lay a foundation for a new science of writing which might be called grammatology. While the general histories of writing treat individual writings mainly from a descriptive-historical point of view, the new science attempts to establish general principles governing the use and evolution of writing on a comparative-typological basis. -

Braille Teaching and Literacy a Report for the European Blind
Braille Teaching and Literacy A Report for the European Blind Union and European Commission January 2018 Danish Association of the Blind and the International Council for Education of People with Visual Impairment and Dr Sarah Woodin Contents Introduction ............................................................................................... 1 Background to the Project ........................................................................ 3 Aims of the Project ................................................................................... 4 Main Activities of the Project .................................................................... 6 Desk Based Research ........................................................................... 6 Questionnaires for Participating Countries ............................................ 6 Country Visits ........................................................................................ 7 Seminars and Conferences ................................................................... 8 Summary of Findings from the National Surveys ................................... 10 Introductory Information: Registration of Children ............................... 10 Section 1 Children Using Braille Publications ..................................... 10 Section 2 Braille Training .................................................................... 10 Section 3 National Braille Systems ..................................................... 11 Section 4 Electronic Braille .................................................................