RIKEN Super Combined Cluster (RSCC) System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

End-To-End Performance of 10-Gigabit Ethernet on Commodity Systems
END-TO-END PERFORMANCE OF 10-GIGABIT ETHERNET ON COMMODITY SYSTEMS INTEL’SNETWORK INTERFACE CARD FOR 10-GIGABIT ETHERNET (10GBE) ALLOWS INDIVIDUAL COMPUTER SYSTEMS TO CONNECT DIRECTLY TO 10GBE ETHERNET INFRASTRUCTURES. RESULTS FROM VARIOUS EVALUATIONS SUGGEST THAT 10GBE COULD SERVE IN NETWORKS FROM LANSTOWANS. From its humble beginnings as such performance to bandwidth-hungry host shared Ethernet to its current success as applications via Intel’s new 10GbE network switched Ethernet in local-area networks interface card (or adapter). We implemented (LANs) and system-area networks and its optimizations to Linux, the Transmission anticipated success in metropolitan and wide Control Protocol (TCP), and the 10GbE area networks (MANs and WANs), Ethernet adapter configurations and performed sever- continues to evolve to meet the increasing al evaluations. Results showed extraordinari- demands of packet-switched networks. It does ly higher throughput with low latency, so at low implementation cost while main- indicating that 10GbE is a viable intercon- taining high reliability and relatively simple nect for all network environments. (plug and play) installation, administration, Justin (Gus) Hurwitz and maintenance. Architecture of a 10GbE adapter Although the recently ratified 10-Gigabit The world’s first host-based 10GbE adapter, Wu-chun Feng Ethernet standard differs from earlier Ether- officially known as the Intel PRO/10GbE LR net standards, primarily in that 10GbE oper- server adapter, introduces the benefits of Los Alamos National ates only over fiber and only in full-duplex 10GbE connectivity into LAN and system- mode, the differences are largely superficial. area network environments, thereby accom- Laboratory More importantly, 10GbE does not make modating the growing number of large-scale obsolete current investments in network infra- cluster systems and bandwidth-intensive structure. -

Parallel Computing at DESY Peter Wegner Outline •Types of Parallel
Parallel Computing at DESY Peter Wegner Outline •Types of parallel computing •The APE massive parallel computer •PC Clusters at DESY •Symbolic Computing on the Tablet PC Parallel Computing at DESY, CAPP2005 1 Parallel Computing at DESY Peter Wegner Types of parallel computing : •Massive parallel computing tightly coupled large number of special purpose CPUs and special purpose interconnects in n-Dimensions (n=2,3,4,5,6) Software model – special purpose tools and compilers •Event parallelism trivial parallel processing characterized by communication independent programs which are running on large PC farms Software model – Only scheduling via a Batch System Parallel Computing at DESY, CAPP2005 2 Parallel Computing at DESY Peter Wegner Types of parallel computing cont.: •“Commodity ” parallel computing on clusters one parallel program running on a distributed PC Cluster, the cluster nodes are connected via special high speed, low latency interconnects (GBit Ethernet, Myrinet, Infiniband) Software model – MPI (Message Passing Interface) •SMP (Symmetric MultiProcessing) parallelism many CPUs are sharing a global memory, one program is running on different CPUs in parallel Software model – OpenPM and MPI Parallel Computing at DESY, CAPP2005 3 Parallel computing at DESY: Zeuthen Computer Center Massive parallel PC Farms PC Clusters computer Parallel Computing Parallel Computing at DESY, CAPP2005 4 Parallel Computing at DESY Massive parallel APE (Array Processor Experiment) - since 1994 at DESY, exclusively used for Lattice Simulations for simulations of Quantum Chromodynamics in the framework of the John von Neumann Institute of Computing (NIC, FZ Jülich, DESY) http://www-zeuthen.desy.de/ape PC Cluster with fast interconnect (Myrinet, Infiniband) – since 2001, Applications: LQCD, Parform ? Parallel Computing at DESY, CAPP2005 5 Parallel computing at DESY: APEmille Parallel Computing at DESY, CAPP2005 6 Parallel computing at DESY: apeNEXT Parallel computing at DESY: apeNEXT Parallel Computing at DESY, CAPP2005 7 Parallel computing at DESY: Motivation for PC Clusters 1. -

CANON INC. (Exact Name of the Registrant As Specified in Its Charter)
UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 FORM SD SPECIALIZED DISCLOSURE REPORT CANON INC. (Exact name of the registrant as specified in its charter) JAPAN 001-15122 (State or other jurisdiction of (Commission (IRS Employer incorporation or organization) File Number) Identification No.) 30-2, Shimomaruko 3-chome , Ohta-ku, Tokyo 146-8501, Japan (Address of principle executive offices) (Zip code) Eiji Shimizu, +81-3-3758-2111, 30-2, Shimomaruko 3-chome, Ohta-ku, Tokyo 146-8501, Japan (Name and telephone number, including area code, of the person to contact in connection with this report.) Check the appropriate box to indicate the rule pursuant to which this form is being filed and provide the period to which the information in this form applies: Rule 13p-1 under the Securities Exchange Act (17 CFR 240.13p-1) for the reporting period from January 1, 2017 to December 31, 2017. Section 1 - Conflict Minerals Disclosure Established in 1937, Canon Inc. is a Japanese corporation with its headquarters in Tokyo, Japan. Canon Inc. is one of the world’s leading manufacturers of office multifunction devices (“MFDs”), plain paper copying machines, laser printers, inkjet printers, cameras, diagnostic equipment and lithography equipment. Canon Inc. earns revenues primarily from the manufacture and sale of these products domestically and internationally. Canon Inc. and its consolidated companies fully have been aware of conflict minerals issue and have been working together with business partners and industry entities to address the issue of conflict minerals. In response to Rule 13p-1, Canon Inc. conducted Reasonable Country of Origin Inquiry and due diligence based on the “OECD Due Diligence Guidance for Responsible Supply Chains of Minerals from Conflict-Affected and High-Risk Areas,” for its various products. -

J-PARC MLF MUSE Muon Beams
For Project X muSR forum at Fermilab Oct 17th-19th,2012 J-PARC MLF MUSE muon beams J-PARC MLF Muon Section/KEK IMSS Yasuhiro Miyake N D-Line In operation N U-Line Commissioning started! N S-Line Partially constructed! N H-Line Partially constructed! Proton Beam Transport from 3GeV RCS to MLF� On the way, towards neutron source� Graphite Muon Target! G-2, DeeMe Mu-Hf Super Highexperiments Resolution Powder etc. H-LineDiffractometer (SHRPD) – KEK are planned 100 m LineBL8� NOBORU - IBARAKI Biological S-Line JAEA BL4� Crystal Diffractometer Nuclear Data - Hokkaido Univ. High Resolution Chopper 4d Space Access Neutron Spectrometer Spectrometer(4SEASONS) Muon Target Grant - in - Aid for Specially Promoted Research, MEXT, Neutron Target U-Line HI - SANS Versatile High Intensity (JAEA) Total Diffractometer(KEK /NEDO) D-Line&9&$3/-&3&1 (KEK) Cold Neutron Double Chopper Spectrometer IBARAKI Materials Design (CNDCS) - JAEA Diffractometer 30 m Muon Engineering Materials and Life Science Facility (MLF) for Muon & NeutronDiffractometer - JAEA Edge-cooling Rotating Graphite Graphite Fixed Target Target From January 2014! At Present! Will be changed in Summer 2013! Inves�gated during shut-‐down! Fixed Target Rota�ng Target S-Line H-Line Surface µ+(30 MeV/c) Surface µ+ For HF, g-2 exp. For material sciences e- up to 120 MeV/c For DeeMe µ- up to 120 MeV/c For µCF Muon Target U-Line D-Line Ultra Slow µ+(0.05-30keV) Surface µ+(30 MeV/c) For multi-layered thin Decay µ+/µ-(up to 120 MeV/c) foils, nano-materials, catalysis, etc Users’ RUN, in Operation MUSE D-Line, since Sep., 2008 [The world-most intense pulsed muon beam achieved at J-PARC MUSE] ZZZAt the J-PARC Muon Facility (MUSE), the intensity of the pulsed surface muon beam was recorded to be 1.8 x 106/s on November 2009, which was produced by a primary proton beam at a corresponding power of 120 kW delivered from the Rapid Cycle Synchrotron (RCS). -

FROM KEK-PS to J-PARC Yoshishige Yamazaki, J-PARC, KEK & JAEA, Japan
FROM KEK-PS TO J-PARC Yoshishige Yamazaki, J-PARC, KEK & JAEA, Japan Abstract target are located in series. Every 3 s or so, depending The user experiments at J-PARC have just started. upon the usage of the main ring (MR), the beam is JPARC, which stands for Japan Proton Accelerator extracted from the RCS to be injected to the MR. Here, it Research Complex, comprises a 400-MeV linac (at is ramped up to 30 GeV at present and slowly extracted to present: 180 MeV, being upgraded), a 3-GeV rapid- Hadron Experimental Hall, where the kaon-production cycling synchrotron (RCS), and a 50-GeV main ring target is located. The experiments using the kaons are (MR) synchrotron, which is now in operation at 30 GeV. conducted there. Sometimes, it is fast extracted to The RCS will provide the muon-production target and the produce the neutrinos, which are sent to the Super spallation-neutron-production target with a beam power Kamiokande detector, which is located 295-km west of of 1 MW (at present: 120 kW) at a repetition rate of 25 the J-PARC site. In the future, we are conceiving the Hz. The muons and neutrons thus generated will be used possibility of constructing a test facility for an in materials science, life science, and others, including accelerator-driven nuclear waste transmutation system, industrial applications. The beams that are fast extracted which was shifted to Phase II. We are trying every effort from the MR generate neutrinos to be sent to the Super to get funding for this facility. -

EARLY SCHIZOPHRENIA DETECTION Biomarker Found in Hair
SPRING 2020 SHOWCASING THE BEST OF JAPAN’S PREMIER RESEARCH ORGANIZATION • www.riken.jp/en EARLY SCHIZOPHRENIA DETECTION Biomarker found in hair WHAT'S THE MATTER? LIVING UNTIL 110 READING THE MIND OF AI Possible link between Abundance of immune Cancer prognosis two cosmic mysteries cell linked to longevity method revealed ▲ Web of dark matter A supercomputer simulation showing the distribution of dark matter in the local universe. RIKEN astrophysicists have performed the first laboratory experiments to see whether the interaction between dark matter and antimatter differs from that between dark matter and normal matter. If such a difference exists, it could explain two cosmological mysteries: why there is so little antimatter in the Universe and what is the true nature of dark matter (see page 18). ADVISORY BOARD RIKEN, Japan’s flagship publication is a selection For further information on the BIOLOGY ARTIFICIAL INTELLIGENCE research institute, conducts of the articles published research in this publication or • Kuniya Abe (BRC) • Hiroshi Nakagawa (AIP) basic and applied research in by RIKEN at: https://www. to arrange an interview with a • Makoto Hayashi (CSRS) • Satoshi Sekine (AIP) a wide range of fields riken.jp/en/news_pubs/ researcher, please contact: • Shigeo Hayashi (BDR) including physics, chemistry, research_news/ RIKEN International • Joshua Johansen (CBS) PHYSICS medical science, biology Please visit the website for Affairs Division • Atsuo Ogura (BRC) • Akira Furusaki (CEMS) and engineering. recent updates and related 2-1, Hirosawa, Wako, • Yasushi Okada (BDR) • Hiroaki Minamide (RAP) articles. Articles showcase Saitama, 351-0198, Japan • Hitoshi Okamoto (CBS) • Yasuo Nabekawa (RAP) Initially established RIKEN’s groundbreaking Tel: +81 48 462 1225 • Kensaku Sakamoto (BDR) • Shigehiro Nagataki (CPR) as a private research results and are written for a Fax: +81 48 463 3687 • Kazuhiro Sakurada (MIH) • Masaki Oura (RSC) foundation in Tokyo in 1917, non-specialist audience. -

Data Center Architecture and Topology
CENTRAL TRAINING INSTITUTE JABALPUR Data Center Architecture and Topology Data Center Architecture Overview The data center is home to the computational power, storage, and applications necessary to support an enterprise business. The data center infrastructure is central to the IT architecture, from which all content is sourced or passes through. Proper planning of the data center infrastructure design is critical, and performance, resiliency, and scalability need to be carefully considered. Another important aspect of the data center design is flexibility in quickly deploying and supporting new services. Designing a flexible architecture that has the ability to support new applications in a short time frame can result in a significant competitive advantage. Such a design requires solid initial planning and thoughtful consideration in the areas of port density, access layer uplink bandwidth, true server capacity, and oversubscription, to name just a few. The data center network design is based on a proven layered approach, which has been tested and improved over the past several years in some of the largest data center implementations in the world. The layered approach is the basic foundation of the data center design that seeks to improve scalability, performance, flexibility, resiliency, and maintenance. Figure 1-1 shows the basic layered design. 1 CENTRAL TRAINING INSTITUTE MPPKVVCL JABALPUR Figure 1-1 Basic Layered Design Campus Core Core Aggregation 10 Gigabit Ethernet Gigabit Ethernet or Etherchannel Backup Access The layers of the data center design are the core, aggregation, and access layers. These layers are referred to extensively throughout this guide and are briefly described as follows: • Core layer—Provides the high-speed packet switching backplane for all flows going in and out of the data center. -

Riken Research Volume % Number &
APRIL !"#$ RIKEN RESEARCH VOLUME % NUMBER & Melting point 900 MHz NMR facility in Yokohama © 2013 RIKEN TABLE OF CONTENTS Table of contents HIGHLIGHT OF THE MONTH 4 A vertebrate family reunion RESEARCH HIGHLIGHTS 6 Melting back and forth 7 Silicon’s double magic # 8 Watching bioactive molecules at work 9 Cancer drugs taking shape 10 Stopping the rot 11 Understanding metabolism through computer predictions 12 Cellular networks up close 13 Stem cell therapy for Parkinson’s disease $ FRONTLINE 14 Generating cancer blueprints for future therapies RIKEN PEOPLE 18 Masayo Takahashi, Laboratory for Retinal Regeneration !# !" RIKEN RESEARCH RIKEN, Japan’s flagship research institute, makers interested in science and aims to raise conducts basic and applied experimental global awareness of RIKEN and its research. research in a wide range of science and Sendai technology fields including physics, For further information on the research chemistry, medical science, biology and presented in this publication or to arrange an Wako engineering. Initially established as a private interview with a researcher, please contact: Nagoya research foundation in Tokyo in !"!#, RIKEN Tsukuba became an independent administrative RIKEN Global Relations Office Tokyo Yokohama institution in $%%&. $'!, Hirosawa, Wako, Saitama, &(!'%!"), Japan Osaka TEL: +)! *) *+$ !$$( Kobe RIKEN RESEARCH is a website and print FAX: +)! *) *+& &+)# Harima publication intended to highlight the best E'Mail: [email protected] research being published by RIKEN. It is written URL: www.riken -

Table of Contents
AMMRA Annual Report 2012 Table of Contents AMMRA, the Past and Future ............................................................... 1 Welcome Address ................................................................................ 4 AMMRA Members ............................................................................... 6 AMMRA Charter .................................................................................. 7 AMMRA Organizations ........................................................................11 Briefing from Member Institutions ......................................................13 Biological Resource Centre, A-STAR, Singapore ...................................15 Center for Animal Resources and Development, Kumamoto ...............17 Laboratory Animal Resource Center, KRIBB, Ochang ...........................23 National Applied Research Laboratories, Taipei ..................................29 National Center for Mutant Mice of China, Nanjing ............................35 RIKEN BioResource Center (BRC), Tsukuba ..........................................43 AMMRA Annual meetings… ............................................................. ..51 Contact List .........................................................................................53 AMMRA, the Past and Future President – Dr. Xiang Gao AMMRA services as a strong bondage for us all. Personally, I wish to express my appreciation to Dr. Ken-ichi Yamamura for his vision and tremendous efforts over last 6 years. Of course I am also in debt to all members -

Integrative Medical Sciences Stratified Medicine for a Healthy Long-Lived Society
RIKEN Center for Integrative Medical Sciences Stratified medicine for a healthy long-lived society. Creation of a research platform for new biomedical science. Japan is facing urgent health issues, such as lifestyle-related diseases, various cancers and brain-function disorders, in an increasingly aging society. It has become apparent that the human immune system not only relates to autoimmune diseases, infectious diseases and allergies, but also to many other age-related disorders. It is now thought that disease onset is caused by highly complex combinations of environmental stresses and body reactions, in addition to genomic variations, in each individual. At the RIKEN Center for Integrative Medical Sciences (IMS), we aim to clarify the pathogenic mechanisms underlying human diseases and to translate this knowledge into novel therapies for the benefit of society. IMS will tackle various research questions Director to expound the functions of the human genome and immune system. IMS research is Kazuhiko Yamamoto based on the concept of disease as a dynamic body system interacting with environmental stresses. We will create a research platform to clarify the processes that maintain or disrupt body homeostasis and then transfer that knowledge into the creation of new therapies and medicines. In particular, IMS will strengthen its genome and immunology research platforms through new inputs from functional genomics research, with special emphasis on gene expression networks such as the FANTOM project. Based on this new research platform, IMS will integrate the knowledge of both human genome function and immune system, and lead cutting edge science to solve the problems of various diseases. IMS will promote comprehensive multi-layered analysis of the genome, epigenome, proteins, lipids, cells, organs and individuals. -
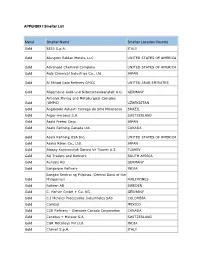
2020 Appendix I Smelter List
APPENDIX I Smelter List Metal Smelter Name Smelter Location Country Gold 8853 S.p.A. ITALY Gold Abington Reldan Metals, LLC UNITED STATES OF AMERICA Gold Advanced Chemical Company UNITED STATES OF AMERICA Gold Aida Chemical Industries Co., Ltd. JAPAN Gold Al Etihad Gold Refinery DMCC UNITED ARAB EMIRATES Gold Allgemeine Gold-und Silberscheideanstalt A.G. GERMANY Almalyk Mining and Metallurgical Complex Gold (AMMC) UZBEKISTAN Gold AngloGold Ashanti Corrego do Sitio Mineracao BRAZIL Gold Argor-Heraeus S.A. SWITZERLAND Gold Asahi Pretec Corp. JAPAN Gold Asahi Refining Canada Ltd. CANADA Gold Asahi Refining USA Inc. UNITED STATES OF AMERICA Gold Asaka Riken Co., Ltd. JAPAN Gold Atasay Kuyumculuk Sanayi Ve Ticaret A.S. TURKEY Gold AU Traders and Refiners SOUTH AFRICA Gold Aurubis AG GERMANY Gold Bangalore Refinery INDIA Bangko Sentral ng Pilipinas (Central Bank of the Gold Philippines) PHILIPPINES Gold Boliden AB SWEDEN Gold C. Hafner GmbH + Co. KG GERMANY Gold C.I Metales Procesados Industriales SAS COLOMBIA Gold Caridad MEXICO Gold CCR Refinery - Glencore Canada Corporation CANADA Gold Cendres + Metaux S.A. SWITZERLAND Gold CGR Metalloys Pvt Ltd. INDIA Gold Chimet S.p.A. ITALY Gold Chugai Mining JAPAN Gold Daye Non-Ferrous Metals Mining Ltd. CHINA Gold Degussa Sonne / Mond Goldhandel GmbH GERMANY Gold DODUCO Contacts and Refining GmbH GERMANY Gold Dowa JAPAN Gold DSC (Do Sung Corporation) KOREA, REPUBLIC OF Gold Eco-System Recycling Co., Ltd. East Plant JAPAN Gold Eco-System Recycling Co., Ltd. North Plant JAPAN Gold Eco-System Recycling Co., Ltd. West Plant JAPAN Gold Emirates Gold DMCC UNITED ARAB EMIRATES Gold GCC Gujrat Gold Centre Pvt. -

RIKEN Bioresource Center Brochure
RIKEN TSUKUBA BRANCH RIKEN BioResource Research Center July, 2020 Contents ●Greetings…………………………………… 3 ●Overview of the RIKEN BRC……………… 5 For Trust, Sustainability and Leadership ! ●Mouse……………………………………… 7 ●Arabidopsis & Brachypodium……………… 8 ●Cell…………………………………………… 9 ●Gene…………………………………………10 ●Microbe……………………………………… 11 ●Laboratories………………………………12 ●History, Budget, Personnel, Facilities ……15 ●Organization…………………………………16 ●Activities of RIKEN BRC……………………17 ●NBRP (National Bioresource Project) ……18 not only to researchers in academia but also to those in the private sector, with large-scale facilities and equipment such as supercomputers Hiroshi Matsumoto, Ph.D and the SPring-8 synchrotron facility, as well Toshihiko Shiroishi, Ph.D President as bioresources. In this regard, the RIKEN Director RIKEN BioResource Research Center (BRC) has long RIKEN BioResource Rresearch Center served as one of RIKEN’s core infrastructure At present, numerous new bioresources are centers. being developed in a wide range of fields of the RIKEN celebrated its centennial on March 20, Finally, precisely because RIKEN is not Bioresources are essential experimental life science, with the advances in genome science 2017. The current year of 2018 marks another limited to any specific one research field, our third materials for researches in life science and and the emergence of innovative genome editing milestone, the 60th anniversary of RIKEN’s strategy is to pioneer new research fields. One innovation based on the life science. In January technologies. These are experimental