Parallel Computing at DESY Peter Wegner Outline •Types of Parallel
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

End-To-End Performance of 10-Gigabit Ethernet on Commodity Systems
END-TO-END PERFORMANCE OF 10-GIGABIT ETHERNET ON COMMODITY SYSTEMS INTEL’SNETWORK INTERFACE CARD FOR 10-GIGABIT ETHERNET (10GBE) ALLOWS INDIVIDUAL COMPUTER SYSTEMS TO CONNECT DIRECTLY TO 10GBE ETHERNET INFRASTRUCTURES. RESULTS FROM VARIOUS EVALUATIONS SUGGEST THAT 10GBE COULD SERVE IN NETWORKS FROM LANSTOWANS. From its humble beginnings as such performance to bandwidth-hungry host shared Ethernet to its current success as applications via Intel’s new 10GbE network switched Ethernet in local-area networks interface card (or adapter). We implemented (LANs) and system-area networks and its optimizations to Linux, the Transmission anticipated success in metropolitan and wide Control Protocol (TCP), and the 10GbE area networks (MANs and WANs), Ethernet adapter configurations and performed sever- continues to evolve to meet the increasing al evaluations. Results showed extraordinari- demands of packet-switched networks. It does ly higher throughput with low latency, so at low implementation cost while main- indicating that 10GbE is a viable intercon- taining high reliability and relatively simple nect for all network environments. (plug and play) installation, administration, Justin (Gus) Hurwitz and maintenance. Architecture of a 10GbE adapter Although the recently ratified 10-Gigabit The world’s first host-based 10GbE adapter, Wu-chun Feng Ethernet standard differs from earlier Ether- officially known as the Intel PRO/10GbE LR net standards, primarily in that 10GbE oper- server adapter, introduces the benefits of Los Alamos National ates only over fiber and only in full-duplex 10GbE connectivity into LAN and system- mode, the differences are largely superficial. area network environments, thereby accom- Laboratory More importantly, 10GbE does not make modating the growing number of large-scale obsolete current investments in network infra- cluster systems and bandwidth-intensive structure. -

Data Center Architecture and Topology
CENTRAL TRAINING INSTITUTE JABALPUR Data Center Architecture and Topology Data Center Architecture Overview The data center is home to the computational power, storage, and applications necessary to support an enterprise business. The data center infrastructure is central to the IT architecture, from which all content is sourced or passes through. Proper planning of the data center infrastructure design is critical, and performance, resiliency, and scalability need to be carefully considered. Another important aspect of the data center design is flexibility in quickly deploying and supporting new services. Designing a flexible architecture that has the ability to support new applications in a short time frame can result in a significant competitive advantage. Such a design requires solid initial planning and thoughtful consideration in the areas of port density, access layer uplink bandwidth, true server capacity, and oversubscription, to name just a few. The data center network design is based on a proven layered approach, which has been tested and improved over the past several years in some of the largest data center implementations in the world. The layered approach is the basic foundation of the data center design that seeks to improve scalability, performance, flexibility, resiliency, and maintenance. Figure 1-1 shows the basic layered design. 1 CENTRAL TRAINING INSTITUTE MPPKVVCL JABALPUR Figure 1-1 Basic Layered Design Campus Core Core Aggregation 10 Gigabit Ethernet Gigabit Ethernet or Etherchannel Backup Access The layers of the data center design are the core, aggregation, and access layers. These layers are referred to extensively throughout this guide and are briefly described as follows: • Core layer—Provides the high-speed packet switching backplane for all flows going in and out of the data center. -

Comparing Ethernet and Myrinet for MPI Communication
Comparing Ethernet and Myrinet for MPI Communication Supratik Majumder Scott Rixner Rice University Rice University Houston, Texas Houston, Texas [email protected] [email protected] ABSTRACT operating system. In addition, TCP is a carefully developed This paper compares the performance of Myrinet and Eth- network protocol that gracefully handles lost packets and ernet as a communication substrate for MPI libraries. MPI flow control. User-level protocols can not hope to achieve library implementations for Myrinet utilize user-level com- the efficiency of TCP when dealing with these issues. Fur- munication protocols to provide low latency and high band- thermore, there has been significant work in the network width MPI messaging. In contrast, MPI library impleme- server domain to optimize the use of TCP for efficient com- nations for Ethernet utilize the operating system network munication. protocol stack, leading to higher message latency and lower message bandwidth. However, on the NAS benchmarks, GM This paper evaluates the performance differences between messaging over Myrinet only achieves 5% higher applica- GM over 1.2 Gbps Myrinet and TCP over 1 Gbps Ethernet tion performance than TCP messaging over Ethernet. Fur- as communication substrates for the Los Alamos MPI (LA- thermore, efficient TCP messaging implmentations improve MPI) library. The raw network unidirectional ping latency communication latency tolerance, which closes the perfor- of Myrinet is lower than Ethernet by almost 40 µsec. How- mance gap between Myrinet and Ethernet to about 0.5% ever, a considerable fraction of this difference is due to in- on the NAS benchmarks. This shows that commodity net- terrupt coalescing employed by the Ethernet network inter- working, if used efficiently, can be a viable alternative to face driver. -

Designing High-Performance and Scalable Clustered Network Attached Storage with Infiniband
DESIGNING HIGH-PERFORMANCE AND SCALABLE CLUSTERED NETWORK ATTACHED STORAGE WITH INFINIBAND DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Ranjit Noronha, MS * * * * * The Ohio State University 2008 Dissertation Committee: Approved by Dhabaleswar K. Panda, Adviser Ponnuswammy Sadayappan Adviser Feng Qin Graduate Program in Computer Science and Engineering c Copyright by Ranjit Noronha 2008 ABSTRACT The Internet age has exponentially increased the volume of digital media that is being shared and distributed. Broadband Internet has made technologies such as high quality streaming video on demand possible. Large scale supercomputers also consume and cre- ate huge quantities of data. This media and data must be stored, cataloged and retrieved with high-performance. Researching high-performance storage subsystems to meet the I/O demands of applications in modern scenarios is crucial. Advances in microprocessor technology have given rise to relatively cheap off-the-shelf hardware that may be put together as personal computers as well as servers. The servers may be connected together by networking technology to create farms or clusters of work- stations (COW). The evolution of COWs has significantly reduced the cost of ownership of high-performance clusters and has allowed users to build fairly large scale machines based on commodity server hardware. As COWs have evolved, networking technologies like InfiniBand and 10 Gigabit Eth- ernet have also evolved. These networking technologies not only give lower end-to-end latencies, but also allow for better messaging throughput between the nodes. This allows us to connect the clusters with high-performance interconnects at a relatively lower cost. -

Inside the Lustre File System
Inside The Lustre File System Technology Paper An introduction to the inner workings of the world’s most scalable and popular open source HPC file system Torben Kling Petersen, PhD Inside The Lustre File System The Lustre High Performance Parallel File System Introduction Ever since the precursor to Lustre® (known as the Object- Based Filesystem, or ODBFS) was developed at Carnegie Mellon University in 1999, Lustre has been at the heart of high performance computing, providing the necessary throughput and scalability to many of the fastest supercomputers in the world. Lustre has experienced a number of changes and, despite the code being open source, the ownership has changed hands a number of times. From the original company started by Dr. Peter Braam (Cluster File Systems, or CFS), which was acquired by Sun Microsystems in 2008—which was in turn acquired by Oracle in 2010—to the acquisition of the Lustre assets by Xyratex in 2013, the open source community has supported the proliferation and acceptance of Lustre. In 2011, industry trade groups like OpenSFS1, together with its European sister organization, EOFS2, took a leading role in the continued development of Lustre, using member fees and donations to drive the evolution of specific projects, along with those sponsored by users3 such as Oak Ridge National Laboratory, Lawrence Livermore National Laboratory and the French Atomic Energy Commission (CEA), to mention a few. Today, in 2014, the Lustre community is stronger than ever, and seven of the top 10 high performance computing (HPC) systems on the international Top 5004 list (as well as 75+ of the top 100) are running the Lustre high performance parallel file system. -

High-End HPC Architectures
High-end HPC architectures Mithuna Thottethodi School of Electrical and Computer Engineering Purdue University What makes a Supercomputer a Supercomputer • Top 500 (www.top500.org) – Processor family: Intel/AMD/Power families • 96% of top 500 – Operating systems • Linux/Unix/BSD dominate –Scale • Range from 128-128K processors – Interconnect • Also varies significantly • Is this really surprising? • Better interconnect can scale to more CPUs #1 and #500 over time The Pyramid • 3 of top 5 and 13 of top 50 - BlueGene solutions Number ofSystems • MPPs (60% of top 50 vs Cost/Performance 21% of top 500) • Clusters (~75%) – with High-performance interconnect (#8, #9 on top 10) – with Gigabit Ethernet (41% of top 500, only 1 in top 50) Outline • Interconnects? – Connectivity: MPP vs. cluster – Latency, Bandwidth, Bisection • When is computer A faster than computer B? – Algorithm Scaling, Concurrency, Communication • Other issues – Storage I/O, Failures, Power • Case Studies Connectivity • How fast/slow can the processor get information on/off the network – How far is the on-ramp/the exit from the source/destination? – Can limit performance even if network is fast Massively Parallel Processing (MPP) • Network interface typically Processor close to processor – Memory bus: Cache Network • locked to specific processor Interface architecture/bus protocol – Registers/cache: Memory Bus I/O Bridge • only in research machines Network • Time-to-market is long I/O Bus – processor already available or Main Memory work closely with processor Disk designers -

Guaranteed Periodic Real-Time Communication Over Wormhole
Guaranteed Perio dic Real-Time Communication over Wormhole Switched Networks Alejandro Garcia, Lisb eth Johansson, Magnus Jonsson, and Mattias Weckstén Scho ol of Information Science, Computer and Electrical Engineering, Halmstad University, Halmstad, Sweden [email protected], http://www.hh.se/ide ket, e.g., Myrinet [1] and Gigabit Ethernet [2]. How- Abstract ever, these networks typically have no or very little supp ort for real-time trac, esp ecially hard real-time In this paper, we investigate how to eciently im- trac which is required in applications like those men- plement TDMA (Time Division Multiple Access) on a tioned ab ove. Networks like ATM are available but wormhole switched network using a pure software solu- less complex aordable alternatives are needed where tion in the end nodes. Transmission is conict freeon eachnode can be connected directly to the switched the time-slot level and hencedead lock free. On the sub- network. slot level, however, conicts are possible when using early sending, a methodwepropose in ordertoreduce In this pap er, we present work done on time- latency while stil l not hazarding the TDMA schedule. deterministic communication to supp ort cyclic traf- Wepropose a complete system to oer services for dy- c in a class of switched networks. By using TDMA namic establishment of guaranteed periodic real-time (Time Division Multiple Access), the access to each virtual channels. Two dierent clock synchronization link in the network is divided into time-slots. When approaches for integration into the TDMA system are the trac is changed (e.g., a new real-time virtual discussed. -

Analysis and Optimisation of Communication Links for Signal Processing Applications
Analysis and Optimisation of Communication Links for Signal Processing Applications ANDREAS ÖDLING Examensarbete inom elektronik- och datorsystem, avancerad nivå, 30 hp Degree Project, in Electronic- and Computer Systems, second level School of Information and Communication Technology, ICT Royal Institute of Technology, KTH Supervisor: Johnny Öberg Examiner: Ingo Sander Stockholm, November 12, 2012 TRITA-ICT-EX-2012:287 Abstract There are lots of communication links and standards cur- rently being employed to build systems today. These meth- ods are in many way standardised, but far from everyone of them are. The trick is to select the communication method that best suit your needs. Also there is currently a trend that things have to be cheaper and have shorter time to market. That leads to more Component Off The Shelf (COTS) systems being build using commodity components. As one part of this work, Gigabit Ethernet is evaluated as a COTS-solution to building large, high-end systems. The computers used are running Windows and the pro- tocol used over Ethernet will be both TCP and UDP. In this work an attempt is also made to evaluate one of the non-standard protocols, the Link Port protocol for the TigerSHARC 20X-series, which is a narrow-bus, double- data-rate protocol, able to provide multi-gigabit-per-second performance. The studies have shown lots of interesting things, e.g. that using a standard desktop computer and network card, the theoretical throughput of TCP over Gigabit Ethernet can almost be met, reaching well over 900 Mbps. UDP performance gives on the other hand birth to a series of new questions about how to achieve good performance in a Windows environment, since it is constantly outperformed by the TCP connections. -

Comparative Performance Analysis with Infiniband and Myrinet-10G
IEEE CAC-2007 10-Gigabit iWARP Ethernet: Comparative Performance Analysis with InfiniBand and Myrinet-10G Mohammad J. Rashti and Ahmad Afsahi Department of Electrical and Computer Engineering Queen’s University Kingston, ON, Canada 2007 Workshop on Communication Architectures for Clusters March 26, 2007 Parallel Processing Research Laboratory 0 Department of Electrical and Computer Engineering Presentation Outline IEEE CAC-2007 • Introduction • Overview of iWARP Ethernet • Experimental Platform • Performance Results • Conclusions and Future Work Parallel Processing Research Laboratory 1 Department of Electrical and Computer Engineering High-Performance Clusters IEEE CAC-2007 • More than 72% of the top500 computers in Nov. 2006 ranking are clusters. • Clusters have become the predominant computing platforms providing high-performance mostly due to availability of : Fast computational engines High-speed interconnects • High-performance clusters are extremely desirable to tackle challenging and emerging applications. A new era in parallel processing is shaping with the emergence of multi-core SMP/NUMA nodes. It is believed that research will be more focused at optimizing applications, parallel programming models, as well as improving the communication subsystems. Parallel Processing Research Laboratory 2 Department of Electrical and Computer Engineering High-Performance Interconnects IEEE CAC-2007 • High-performance clusters need high-performance networks and efficient communication system software. Such networks include: Myrinet Quadrics -
GSN the Ideal Application(S) More Virtual Applications for HEP and Others Some Thoughts About Network Storage
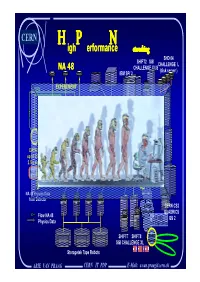
CERN igh erformance etworking H P N SHD 04 SHIFT2 SGI CHALLENGE L NA 48 CHALLENGE XLIS (disk server ) DISKS I . IBM SP/ 2 O . S . C . FDDI EXPERIMENT ALPHA 50 HIPPI SWITCH HIPPI-TC HIPPI-TC HIPPI-TC Turbo- ALPHA channel 400 HIPPI Long Wavelength GIGA HIPPI HIPPI Serial-HIPPI 500 m ROUTER SWITCH DATA RATE: HIPPI Long Wavelength SWITCH up to 250 MB in 2.5 s every 15 s Serial-HIPPI ( 10 Km ) NA48 EVENT Short Wavelength HIPPI HIPPI BUILDER SWITCH SWITCH Serial-HIPPI GIGA ROUTER NA 48 Physics Data from Detector 4 FFDI CERN CS2 Connections QUADRICS Flow NA 48 14 DEC QS 2 Physics Data DLT Tape drives SHIFT7 SHIFT8 GIGA SGI CHALLENGE XL Switch Storagetek Tape Robots ARIE VAN PRAAG CERN IT PDP E-Mail: [email protected] CERN H igh P erformance N etworking High Performance Networking as sign of its time. A Historical Overview H.P.N Now to day means 10 Gbit/s Infiniband IB 10 Gigabit Ethernet 10 GigE Gigabyte System network GSN The Ideal Application(s) More Virtual Applications for HEP and Others Some thoughts about Network Storage Arie Van Praag CERN IT/PDP 1211 Geneva 23 Switzerland E-mail [email protected] ARIE VAN PRAAG CERN IT PDP E-Mail: [email protected] CERN H igh P erformance N etworking Wireless Networks Every New Network has been High Performance in its Time The Very First Networks have been Wireless !! With wavelength multiplexing Some Clever People Invented Broadcasting Distance: 2 - 5 Km Distance : About 5 Km Bandwidth: 0.02 Baud Remark: Faster than a running slave 300 B Chr. -

State-Of-The-Art Network Interconnects for Computer Clusters in High Performance Computing
State-of-the-art Network Interconnects for Computer Clusters in High Performance Computing Rubén D. Sousa De León Technische Universität München, Computational Science and Engineering M.Sc. Program, Boltzmannstr. 3, Munich, Germany [email protected] Abstract. This paper presents a qualitative analysis of three of the more widely used interconnects technologies in high performance computing (HPC) scene today: Myrinet, Quadrics and Infiniband. The most important properties of each interconnect technology are described and the role of each of those in the efficiency of a clustered system is analysed. Then a comparison of the performance of each interconnect at MPI level and at application level is presented using results obtain on tests performed by different teams in several research institutes in United States. Finally the future trends of high performance network interconnect technologies are analyzed based on the results of the comparisons made and on the actual behaviour of the business markets with respect to the development of products and support of the major manufacturers in the industry. 1 Introduction During the past few years the rapid fall in prices of individual computers and the fast increase of its computing capabilities has let to the idea of grouping individual servers together in clusters as an alternative for high performance computing (HPC) applications which is cheaper and thus more accessible than the traditional concept of custom-made supercomputers. The great problem with using individual servers interconnected through some sort of network is the existence of several bottlenecks that decrease the overall performance of this sort of systems. That is the main reason for developing special network interconnects designed to meet the requirements for high performance computing, which are mainly, low internodes communication latency, a high bandwidth for transmitting messages between nodes, scalability, programmability and reliability. -

Presentation
Linux Clusters Institute: HPC Networking Ben Matthews, Software Engineer, NCAR Types of Networks • Highspeed Interconnect • External (Internet access) • Management/Boot May 2017 2 High Speed Interconnect • Significant percentage of the cost of a cluster (1/3 or more) • High bandwidth, low latency • Exact requirements depend on cluster workload • Typically, want some hardware offload capability • RDMA • Needs to present a software interface compatible with your desired middleware (MPI?) • Reliability desirable (may carry filesystem and other important traffic) • Typically short range (single room, or at least single building) • Proprietary and open solutions available May 2017 3 Hardware Offload - RDMA • “Remote Direct Memory Access” – The CPU designates a memory region, which the network cards then transfer • CPU can (and should!) continue doing computation during the transfer • Exposed to user software through various special purpose APIs • Most commonly: Verbs • LibFabric is an up-and-coming alternative • One API for a variety of hardware (at least in theory) • Some Vendors have their own – PSM, Portals, etc • Software often wrapped with a higher level middleware layer, almost always MPI for HPC use cases • The Open Fabric Alliance conference/mailing lists are a good source of information about RDMA May 2017 4 Hardware Offload – RDMA – High level workflow • Create a TCP/IP connection to the nodes of interest and exchange their high-speed interconnect addresses (IB and similar generally don’t have a DNS like thing) • Pin a memory region for transfer on both nodes (so the kernel won’t move the data before the network card is done) • Open a context to the network card and create a queue pair • Exchange metadata about the transfer over TCP • Put a work request in the queue specifying the region to transfer • Wait for a completion message (or better, do something else with the CPU).