Analysis and Optimisation of Communication Links for Signal Processing Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

End-To-End Performance of 10-Gigabit Ethernet on Commodity Systems
END-TO-END PERFORMANCE OF 10-GIGABIT ETHERNET ON COMMODITY SYSTEMS INTEL’SNETWORK INTERFACE CARD FOR 10-GIGABIT ETHERNET (10GBE) ALLOWS INDIVIDUAL COMPUTER SYSTEMS TO CONNECT DIRECTLY TO 10GBE ETHERNET INFRASTRUCTURES. RESULTS FROM VARIOUS EVALUATIONS SUGGEST THAT 10GBE COULD SERVE IN NETWORKS FROM LANSTOWANS. From its humble beginnings as such performance to bandwidth-hungry host shared Ethernet to its current success as applications via Intel’s new 10GbE network switched Ethernet in local-area networks interface card (or adapter). We implemented (LANs) and system-area networks and its optimizations to Linux, the Transmission anticipated success in metropolitan and wide Control Protocol (TCP), and the 10GbE area networks (MANs and WANs), Ethernet adapter configurations and performed sever- continues to evolve to meet the increasing al evaluations. Results showed extraordinari- demands of packet-switched networks. It does ly higher throughput with low latency, so at low implementation cost while main- indicating that 10GbE is a viable intercon- taining high reliability and relatively simple nect for all network environments. (plug and play) installation, administration, Justin (Gus) Hurwitz and maintenance. Architecture of a 10GbE adapter Although the recently ratified 10-Gigabit The world’s first host-based 10GbE adapter, Wu-chun Feng Ethernet standard differs from earlier Ether- officially known as the Intel PRO/10GbE LR net standards, primarily in that 10GbE oper- server adapter, introduces the benefits of Los Alamos National ates only over fiber and only in full-duplex 10GbE connectivity into LAN and system- mode, the differences are largely superficial. area network environments, thereby accom- Laboratory More importantly, 10GbE does not make modating the growing number of large-scale obsolete current investments in network infra- cluster systems and bandwidth-intensive structure. -

Design of a High Speed XAUI Based on Dynamic Reconfigurable
International Journal of Soft Computing And Software Engineering (JSCSE) e-ISSN: 2251-7545 Vol.2,o.9, 2012 DOI: 10.7321/jscse.v2.n9.4 Published online: Sep 25, 2012 Design of a High Speed XAUI Based on Dynamic Reconfigurable Transceiver IP Core * 1Haipeng Zhang, 1Lingjun Kong, 2Xiuju Huang, 3Mengmeng Cao 1 .School of Electronics & Information, Hangzhou Dianzi University, Hangzhou, China, 310018 2. UTSTARCOM Co. Ltd. Hangzhou, China, 310052 3. North China Electric Power University, Department of electronics and Communication Engineering, Baoding, China, 071003 Email:1 [email protected],2 [email protected],3 [email protected] Abstract. By using the dynamic reconfigurable transceiver in high speed interface design, designer can solve critical technology problems such as ensuring signal integrity conveniently, with lower error binary rate. In this paper, we designed a high speed XAUI (10Gbps Ethernet Attachment Unit Interface) to transparently extend the physical reach of the XGMII. The following points are focused: (1) IP (Intellectual Property) core usage. Altera Co. offers two transceiver IP cores in Quartus II MegaWizard Plug-In Manager for XAUI design which is featured of dynamic reconfiguration performance, that is, ALTGX_RECOFIG instance and ALTGX instance, we can get various groups by changing settings of the devices without power off. These two blocks can accomplish function of PCS (Physical Coding Sub-layer) and PMA (Physical Medium Attachment), however, with higher efficiency and reliability. (2) 1+1 protection. In our design, two ALTGX IP cores are used to work in parallel, which named XAUI0 and XAUI1. The former works as the main channel while the latter redundant channel. -

Parallel Computing at DESY Peter Wegner Outline •Types of Parallel
Parallel Computing at DESY Peter Wegner Outline •Types of parallel computing •The APE massive parallel computer •PC Clusters at DESY •Symbolic Computing on the Tablet PC Parallel Computing at DESY, CAPP2005 1 Parallel Computing at DESY Peter Wegner Types of parallel computing : •Massive parallel computing tightly coupled large number of special purpose CPUs and special purpose interconnects in n-Dimensions (n=2,3,4,5,6) Software model – special purpose tools and compilers •Event parallelism trivial parallel processing characterized by communication independent programs which are running on large PC farms Software model – Only scheduling via a Batch System Parallel Computing at DESY, CAPP2005 2 Parallel Computing at DESY Peter Wegner Types of parallel computing cont.: •“Commodity ” parallel computing on clusters one parallel program running on a distributed PC Cluster, the cluster nodes are connected via special high speed, low latency interconnects (GBit Ethernet, Myrinet, Infiniband) Software model – MPI (Message Passing Interface) •SMP (Symmetric MultiProcessing) parallelism many CPUs are sharing a global memory, one program is running on different CPUs in parallel Software model – OpenPM and MPI Parallel Computing at DESY, CAPP2005 3 Parallel computing at DESY: Zeuthen Computer Center Massive parallel PC Farms PC Clusters computer Parallel Computing Parallel Computing at DESY, CAPP2005 4 Parallel Computing at DESY Massive parallel APE (Array Processor Experiment) - since 1994 at DESY, exclusively used for Lattice Simulations for simulations of Quantum Chromodynamics in the framework of the John von Neumann Institute of Computing (NIC, FZ Jülich, DESY) http://www-zeuthen.desy.de/ape PC Cluster with fast interconnect (Myrinet, Infiniband) – since 2001, Applications: LQCD, Parform ? Parallel Computing at DESY, CAPP2005 5 Parallel computing at DESY: APEmille Parallel Computing at DESY, CAPP2005 6 Parallel computing at DESY: apeNEXT Parallel computing at DESY: apeNEXT Parallel Computing at DESY, CAPP2005 7 Parallel computing at DESY: Motivation for PC Clusters 1. -

Ipug68 01.3 Lattice Semiconductor XAUI IP Core User’S Guide
ispLever TM CORECORE XAUI IP Core User’s Guide November 2009 ipug68_01.3 Lattice Semiconductor XAUI IP Core User’s Guide Introduction The 10Gb Ethernet Attachment Unit Interface (XAUI) IP Core User’s Guide for the LatticeECP2M™ and LatticeECP3™ FPGAs provides a solution for bridging between XAUI and 10-Gigabit Media Independent Interface (XGMII) devices. This user’s guide implements 10Gb Ethernet Extended Sublayer (XGXS) capabilities in soft logic that together with PCS and SERDES functions implemented in the FGPA provides a complete XAUI-to-XGMII solu- tion. The XAUI IP core package comes with the following documentation and files: • Protected netlist/database • Behavioral RTL simulation model • Source files for instantiating and evaluating the core The XAUI IP core supports Lattice’s IP hardware evaluation capability, which makes it possible to create versions of the IP core that operate in hardware for a limited period of time (approximately four hours) without requiring the pur- chase on an IP license. It may also be used to evaluate the core in hardware in user-defined designs. Details for using the hardware evaluation capability are described in the Hardware Evaluation section of this document. Features • XAUI compliant functionality supported by embedded SERDES PCS functionality implemented in the LatticeECP2M and LatticeECP3, including four channels of 3.125 Gbps serializer/deserializer with 8b10b encod- ing/decoding. • Complete 10Gb Ethernet Extended Sublayer (XGXS) solution based on LatticeECP2M and LatticeECP3 FPGA. • Soft IP targeted to the FPGA implements XGXS functionality conforming to IEEE 802.3ae-2002, including: – 10 GbE Media Independent Interface (XGMII). – Optional Slip buffers for clock domain transfer to/from the XGMII interface. -

IEEE Std 802.3™-2012 New York, NY 10016-5997 (Revision of USA IEEE Std 802.3-2008)
IEEE Standard for Ethernet IEEE Computer Society Sponsored by the LAN/MAN Standards Committee IEEE 3 Park Avenue IEEE Std 802.3™-2012 New York, NY 10016-5997 (Revision of USA IEEE Std 802.3-2008) 28 December 2012 IEEE Std 802.3™-2012 (Revision of IEEE Std 802.3-2008) IEEE Standard for Ethernet Sponsor LAN/MAN Standards Committee of the IEEE Computer Society Approved 30 August 2012 IEEE-SA Standard Board Abstract: Ethernet local area network operation is specified for selected speeds of operation from 1 Mb/s to 100 Gb/s using a common media access control (MAC) specification and management information base (MIB). The Carrier Sense Multiple Access with Collision Detection (CSMA/CD) MAC protocol specifies shared medium (half duplex) operation, as well as full duplex operation. Speed specific Media Independent Interfaces (MIIs) allow use of selected Physical Layer devices (PHY) for operation over coaxial, twisted-pair or fiber optic cables. System considerations for multisegment shared access networks describe the use of Repeaters that are defined for operational speeds up to 1000 Mb/s. Local Area Network (LAN) operation is supported at all speeds. Other specified capabilities include various PHY types for access networks, PHYs suitable for metropolitan area network applications, and the provision of power over selected twisted-pair PHY types. Keywords: 10BASE; 100BASE; 1000BASE; 10GBASE; 40GBASE; 100GBASE; 10 Gigabit Ethernet; 40 Gigabit Ethernet; 100 Gigabit Ethernet; attachment unit interface; AUI; Auto Negotiation; Backplane Ethernet; data processing; DTE Power via the MDI; EPON; Ethernet; Ethernet in the First Mile; Ethernet passive optical network; Fast Ethernet; Gigabit Ethernet; GMII; information exchange; IEEE 802.3; local area network; management; medium dependent interface; media independent interface; MDI; MIB; MII; PHY; physical coding sublayer; Physical Layer; physical medium attachment; PMA; Power over Ethernet; repeater; type field; VLAN TAG; XGMII The Institute of Electrical and Electronics Engineers, Inc. -
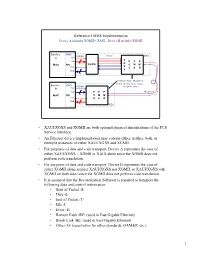
1 Reference 10Gbe Implementation • XAUI/XGXS and XGMII Are Both
Reference 10GbE Implementation Device A includes XGMII + XAUI , Device B includes XGMII Device PHY XGMII XAUI MDI A TXC X TXD P P P G MAC RS 36 XGXS C M M X RXC S A D S RXD 36 Transceiver Modules Initial 10 GbE Form Factor: Device PHY XGMII Daughter Card B TXC TXD P P P Medium MAC RS 36 C M M RXC S A D RXD 36 MDI • XAUI/XGXS and XGMII are both optional physical instantiations of the PCS Service Interface. • An Ethernet device implementation may contain either, neither, both, or multiple instances of either XAUI/XGXS and XGMII. • For purposes of data and code transport, Device A represents the case of either XAUI/XGXS + XGMII or XAUI alone since the XGMII does not perform code translation. • For purposes of data and code transport, Device B represents the case of either XGMII alone, neither XAUI/XGXS nor XGMII, or XAUI/XGXS with XGMII on both sides since the XGMII does not perform code translation. • It is assumed that the Reconciliation Sublayer is required to transport the following data and control information: • Start of Packet /S/ • Data /d/ • End of Packet /T/ • Idle /I/ • Error /E/ • Remote Fault /RF/ (used in Fast/Gigabit Ethernet) • Break Link /BL/ (used in Fast/Gigabit Ethernet) • Other /O/ (reserved or for other standards, OAM&P, etc.) 1 Serial PHY, 64B/66B PCS, XGXS never forwards /A/K/R/ /S/d/T/I/E/ /S/d/T/E/ /S/d/T/E/ /RF/BL/O/ /S/d/T/I/E/ /A/K/R/ /A/K/R/ /S/d/T/I/E/ /S/d/T/I/E/ /RF/BL/O/ /RF/BL/O/ /RF/BL/O/ /RF/BL/O/ /RF/BL/O/ Device PHY XGMII XAUI MDI A TXC X TXD P P P G MAC RS 36 XGXS C M M X RXC S A D S RXD 36 Device PHY XGMII B TXC TXD P P P Medium MAC RS 36 C M M RXC S A D RXD 36 MDI /S/d/T/I/E/ /S/d/T/I/E/ /S/d/T/I/E/ /RF/BL/O/ /RF/BL/O/ /RF/BL/O/ Device A to Device B data and control transport • XGXS adjacent to Device A XGMII translates Idle /I/ to XAUI Idle /A/K/R/. -

Data Center Architecture and Topology
CENTRAL TRAINING INSTITUTE JABALPUR Data Center Architecture and Topology Data Center Architecture Overview The data center is home to the computational power, storage, and applications necessary to support an enterprise business. The data center infrastructure is central to the IT architecture, from which all content is sourced or passes through. Proper planning of the data center infrastructure design is critical, and performance, resiliency, and scalability need to be carefully considered. Another important aspect of the data center design is flexibility in quickly deploying and supporting new services. Designing a flexible architecture that has the ability to support new applications in a short time frame can result in a significant competitive advantage. Such a design requires solid initial planning and thoughtful consideration in the areas of port density, access layer uplink bandwidth, true server capacity, and oversubscription, to name just a few. The data center network design is based on a proven layered approach, which has been tested and improved over the past several years in some of the largest data center implementations in the world. The layered approach is the basic foundation of the data center design that seeks to improve scalability, performance, flexibility, resiliency, and maintenance. Figure 1-1 shows the basic layered design. 1 CENTRAL TRAINING INSTITUTE MPPKVVCL JABALPUR Figure 1-1 Basic Layered Design Campus Core Core Aggregation 10 Gigabit Ethernet Gigabit Ethernet or Etherchannel Backup Access The layers of the data center design are the core, aggregation, and access layers. These layers are referred to extensively throughout this guide and are briefly described as follows: • Core layer—Provides the high-speed packet switching backplane for all flows going in and out of the data center. -

(12) United States Patent (10) Patent No.: US 7,676,600 B2 Davies Et Al
USOO7676600B2 (12) United States Patent (10) Patent No.: US 7,676,600 B2 Davies et al. (45) Date of Patent: Mar. 9, 2010 (54) NETWORK, STORAGE APPLIANCE, AND 4,245,344 A 1/1981 Richter METHOD FOR EXTERNALIZING AN INTERNAL AO LINK BETWEEN A SERVER AND A STORAGE CONTROLLER (Continued) INTEGRATED WITHIN THE STORAGE APPLIANCE CHASSIS FOREIGN PATENT DOCUMENTS (75) Inventors: Ian Robert Davies, Longmont, CO WO WOO21 O1573 12/2002 (US); George Alexander Kalwitz, Mead, CO (US); Victor Key Pecone, Lyons, CO (US) (Continued) (73) Assignee: Dot Hill Systems Corporation, OTHER PUBLICATIONS Longmont, CO (US) Williams, Al. “Programmable Logic & Hardware.” Dr. Dobb's Jour nal. Published May 1, 2003, downloaded from http://www.dd.com/ (*) Notice: Subject to any disclaimer, the term of this architect 184405342. pp. 1-7. patent is extended or adjusted under 35 U.S.C. 154(b) by 1546 days. (Continued) Primary Examiner Hassan Phillips (21) Appl. No.: 10/830,876 Assistant Examiner—Adam Cooney (22) Filed: Apr. 23, 2004 (74) Attorney, Agent, or Firm—Thomas J. Lavan: E. Alan pr. A5, Davis (65) Prior Publication Data (57) ABSTRACT US 2005/0027751A1 Feb. 3, 2005 Related U.S. Application Data A network Storage appliance is disclosed. The storage appli (60) Provisional application No. 60/473,355, filed on Apr. ance includes a port combiner that provides data COU1 23, 2003, provisional application No. 60/554,052, cation between at least first, second, and third I/O ports; a filed on Mar. 17, 2004. storage controller that controls storage devices and includes s the first I/O port; a server having the second I/O port; and an (51) Int. -

Latticesc/M Broadcom XAUI/Higig 10 Gbps Lattice Semiconductor Physical Layer Interoperability Over CX-4
LatticeSC/M Broadcom® XAUI/HiGig™ 10 Gbps Physical Layer Interoperability Over CX-4 August 2007 Technical Note TN1155 Introduction This technical note describes a physical layer 10-Gigabit Ethernet and HiGig (10 Gbps) interoperability test between a LatticeSC/M device and the Broadcom BCM56800 network switch. The test was limited to the physical layer (up to XGMII) of the 10-Gigabit Ethernet protocol stack. Specifically, the document discusses the following topics: • Overview of LatticeSC™ and LatticeSCM™ devices and Broadcom BCM56800 network switch • Physical layer interoperability setup and results Two significant aspects of the interoperability test need to be highlighted: • The BCM56800 uses a CX-4 HiGig port, whereas the LatticeSC Communications Platform Evaluation Board provides an SMA connector. A CX-4 to SMA conversion board was used as a physical medium interface to cre- ate a physical link between both boards. The SMA side of the CX-4 to SMA conversion board has four differential TX/RX channels (10 Gbps bandwidth total). All four SMA channels (Quad 360) were connected to the LatticeSC side. • The physical layer interoperability ran at a 10-Gbps data rate (12.5-Gbps aggregated rate). XAUI Interoperability XAUI is a high-speed interconnect that offers reduced pin count and the ability to drive up to 20” of PCB trace on standard FR-4 material. In order to connect a 10-Gigabit Ethernet MAC to an off-chip PHY device, an XGMII inter- face is used. The XGMII is a low-speed parallel interface for short range (approximately 2”) interconnects. XAUI interoperability is based on the 10-Gigabit Ethernet standard (IEEE Standard 802.3ae-2002). -

Making the Switch to Rapidio
QNX Software Systems Ltd. 175 Terence Matthews Crescent Ottawa, Ontario, Canada, K2M 1W8 Voice: +1 613 591-0931 1 800 676-0566 Fax: +1 613 591-3579 Email: [email protected] Web: www.qnx.com Making the Switch to RapidIO Using a Message-passing Microkernel OS to Realize the Full Potential of the RapidIO Interconnect Paul N. Leroux Technology Analyst QNX Software Systems Ltd. [email protected] Introduction Manufacturers of networking equipment have hit a bottleneck. On the one hand, they can now move traffic from one network element to another at phenomenal speeds, using line cards that transmit data at 10 Gigabits per second or higher. But, once inside the box, data moves between boards, processors, and peripherals at a much slower clip: typically a few hundred megabits per second. To break this bottleneck, equipment manufacturers are seeking a new, high-speed — and broadly supported — interconnect. In fact, many have already set their sights on RapidIO, an open-standard interconnect developed by the RapidIO Trade Association and designed for both chip-to-chip and board-to-board communications. Why RapidIO? Because it offers low latency and extremely high bandwidth, as well as a low pin count and a small silicon footprint — a RapidIO interface can easily fit Making the Switch to RapidIO into the corner of a processor, FPGA, or ASIC. Locked Out by Default: The RapidIO is also transparent to software, allowing Problem with Conventional any type of data protocol to run over the intercon- Software Architectures nect. And, last but not least, RapidIO addresses the demand for reliability by offering built-in While RapidIO provides a hardware bus that is error recovery mechanisms and a point-to-point both fast and reliable, system designers must find or architecture that helps eliminate single points develop software that can fully realize the benefits of failure. -

EDSA-401 ISA Security Compliance Institute – Embedded Device Security Assurance – Testing the Robustness of Implementations of Two Common “Ethernet” Protocols
EDSA-401 ISA Security Compliance Institute – Embedded Device Security Assurance – Testing the robustness of implementations of two common “Ethernet” protocols Version 2.01 September 2010 Copyright © 2009-2010 ASCI – Automation Standards Compliance Institute, All rights reserved EDSA-401-2.01 A. DISCLAIMER ASCI and all related entities, including the International Society of Automation (collectively, “ASCI”)provide all materials, work products and, information (‘SPECIFICATION’) AS IS, WITHOUT WARRANTY AND WITH ALL FAULTS, and hereby disclaim all warranties and conditions, whether express, implied or statutory, including, but not limited to, any (if any) implied warranties, duties or conditions of merchantability, of fitness for a particular purpose, of reliability or availability, of accuracy or completeness of responses, of results, of workmanlike effort, of lack of viruses, and of lack of negligence, all with regard to the SPECIFICATION, and the provision of or failure to provide support or other services, information, software, and related content through the SPECIFICATION or otherwise arising out of the use of the SPECIFICATION. ALSO, THERE IS NO WARRANTY OR CONDITION OF TITLE, QUIET ENJOYMENT, QUIET POSSESSION, CORRESPONDENCE TO DESCRIPTION, OR NON- INFRINGEMENT WITH REGARD TO THE SPECIFICATION. WITHOUT LIMITING THE FOREGOING, ASCI DISCLAIMS ALL LIABILITY FOR HARM TO PERSONS OR PROPERTY, AND USERS OF THIS SPECIFICATION ASSUME ALL RISKS OF SUCH HARM. IN ISSUING AND MAKING THE SPECIFICATION AVAILABLE, ASCI IS NOT UNDERTAKING TO RENDER PROFESSIONAL OR OTHER SERVICES FOR OR ON BEHALF OF ANY PERSON OR ENTITY, NOR IS ASCI UNDERTAKING TO PERFORM ANY DUTY OWED BY ANY PERSON OR ENTITY TO SOMEONE ELSE. ANYONE USING THIS SPECIFICATION SHOULD RELY ON HIS OR HER OWN INDEPENDENT JUDGMENT OR, AS APPROPRIATE, SEEK THE ADVICE OF A COMPETENT PROFESSIONAL IN DETERMINING THE EXERCISE OF REASONABLE CARE IN ANY GIVEN CIRCUMSTANCES. -

Error Behaviour in Optical Networks Laura Bryony James
Error Behaviour in Optical Networks Laura Bryony James Corpus Christi College This dissertation is submitted for the degree of Doctor of Philosophy 30th September 2005 Department of Engineering, University of Cambridge This dissertation is my own work and contains nothing which is the outcome of work done in collaboration with others, except as speci¯ed in the text and Acknow- ledgements. Abstract Optical ¯bre communications are now widely used in many applications, including local area computer networks. I postulate that many future optical LANs will be required to operate with limited optical power budgets for a variety of reasons, including increased system complexity and link speed, low cost components and minimal increases in transmit power. Some developers will wish to run links with reduced power budget margins, and the received data in these systems will be more susceptible to errors than has been the case previously. The errors observed in optical systems are investigated using the particular case of Gigabit Ethernet on ¯bre as an example. Gigabit Ethernet is one of three popular optical local area interconnects which use 8B/10B line coding, along with Fibre Channel and In¯niband, and is widely deployed. This line encoding is also used by packet switched optical LANs currently under development. A probabilistic analysis follows the e®ects of a single channel error in a frame, through the line coding scheme and the MAC layer frame error detection mechanisms. Empirical data is used to enhance this original analysis, making it directly relevant to deployed systems. Experiments using Gigabit Ethernet on ¯bre with reduced power levels at the receiver to simulate the e®ect of limited power margins are described.