AMD Opterontm Multicore Pprocessors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Titan X Amd 1.2 V4 Ig 20210319
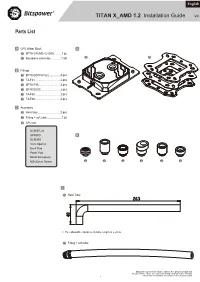
English TITAN X_AMD 1.2 Installation Guide V4 Parts List A CPU Water Block A A-1 BPTA-CPUMS-V2-SKA ..........1 pc A-1 A-2 A-2 Backplane assembly ..............1 set B Fittings B-1 BPTA-DOTFH1622 ...............4 pcs B-2 TA-F61 ...................................2 pcs B-3 BPTA-F95 ..............................2 pcs B-4 BP-RIGOS5 ...........................2 pcs B-5 TA-F60 ..................................2 pcs B-6 TA-F40 ..................................2 pcs C Accessory C-1 Hard tube ..............................2 pcs C-2 Fitting + soft tube ....................1 pc C-3 CPU set SCM3FL20 SPRING B SCM3F6 1mm Spacer Back Pad Paste Pad Metal Backplane M3x32mm Screw B-1 B-2 B-3 B-4 B-5 B-6 C C-1 Hard Tube ※ The allowable variance in tube length is ± 2mm C-2 Fitting + soft tube Bitspower reserves the right to change the product design and interpretations. These are subject to change without notice. Product colors and accessories are based on the actual product. — 1 — I. AMD Motherboard system 54 AMD SOCKET 939 / 754 / 940 IN 48 AMD SOCKET AM4 AMD SOCKET AM3 / AM3+ AMD SOCKET AM2 / AM2+ AMD SOCKET FM1 / FM2+ Bitspower Fan and DRGB RF Remote Controller Hub (Not included) are now available at microcenter.com DRGB PIN on Motherboard or other equipment. 96 90 BPTA-RFCHUB The CPU water block has a DRGB cable, which AMD SOCKET AM4 AMD SOCKET AM3 AM3+ / AMD SOCKET AM2 AM2+ / AMD SOCKET FM1 / FM2+ can be connected to the DRGB extension cable of the radiator fans. Fan and DRGB RF Remote Motherboard Controller Hub (Not included) OUT DRGB LED Do not over-tighten the thumb screws Installation (SCM3FL20). -

Workload Management and Application Placement for the Cray Linux Environment™
TMTM Workload Management and Application Placement for the Cray Linux Environment™ S–2496–4101 © 2010–2012 Cray Inc. All Rights Reserved. This document or parts thereof may not be reproduced in any form unless permitted by contract or by written permission of Cray Inc. U.S. GOVERNMENT RESTRICTED RIGHTS NOTICE The Computer Software is delivered as "Commercial Computer Software" as defined in DFARS 48 CFR 252.227-7014. All Computer Software and Computer Software Documentation acquired by or for the U.S. Government is provided with Restricted Rights. Use, duplication or disclosure by the U.S. Government is subject to the restrictions described in FAR 48 CFR 52.227-14 or DFARS 48 CFR 252.227-7014, as applicable. Technical Data acquired by or for the U.S. Government, if any, is provided with Limited Rights. Use, duplication or disclosure by the U.S. Government is subject to the restrictions described in FAR 48 CFR 52.227-14 or DFARS 48 CFR 252.227-7013, as applicable. Cray and Sonexion are federally registered trademarks and Active Manager, Cascade, Cray Apprentice2, Cray Apprentice2 Desktop, Cray C++ Compiling System, Cray CX, Cray CX1, Cray CX1-iWS, Cray CX1-LC, Cray CX1000, Cray CX1000-C, Cray CX1000-G, Cray CX1000-S, Cray CX1000-SC, Cray CX1000-SM, Cray CX1000-HN, Cray Fortran Compiler, Cray Linux Environment, Cray SHMEM, Cray X1, Cray X1E, Cray X2, Cray XD1, Cray XE, Cray XEm, Cray XE5, Cray XE5m, Cray XE6, Cray XE6m, Cray XK6, Cray XK6m, Cray XMT, Cray XR1, Cray XT, Cray XTm, Cray XT3, Cray XT4, Cray XT5, Cray XT5h, Cray XT5m, Cray XT6, Cray XT6m, CrayDoc, CrayPort, CRInform, ECOphlex, LibSci, NodeKARE, RapidArray, The Way to Better Science, Threadstorm, uRiKA, UNICOS/lc, and YarcData are trademarks of Cray Inc. -

Introducing the Cray XMT
Introducing the Cray XMT Petr Konecny Cray Inc. 411 First Avenue South Seattle, Washington 98104 [email protected] May 5th 2007 Abstract Cray recently introduced the Cray XMT system, which builds on the parallel architecture of the Cray XT3 system and the multithreaded architecture of the Cray MTA systems with a Cray-designed multithreaded processor. This paper highlights not only the details of the architecture, but also the application areas it is best suited for. 1 Introduction past two decades the processor speeds have increased several orders of magnitude while memory speeds Cray XMT is the third generation multithreaded ar- increased only slightly. Despite this disparity the chitecture built by Cray Inc. The two previous gen- performance of most applications continued to grow. erations, the MTA-1 and MTA-2 systems [2], were This has been achieved in large part by exploiting lo- fully custom systems that were expensive to man- cality in memory access patterns and by introducing ufacture and support. Developed under code name hierarchical memory systems. The benefit of these Eldorado [4], the Cray XMT uses many parts built multilevel caches is twofold: they lower average la- for other commercial system, thereby, significantly tency of memory operations and they amortize com- lowering system costs while maintaining the sim- munication overheads by transferring larger blocks ple programming model of the two previous genera- of data. tions. Reusing commodity components significantly The presence of multiple levels of caches forces improves price/performance ratio over the two pre- programmers to write code that exploits them, if vious generations. they want to achieve good performance of their ap- Cray XMT leverages the development of the Red plication. -

FCC Information and Copyright
N68S3B Setup Manual FCC Information and Copyright This equipment has been tested and found to comply with the limits of a Class B digital device, pursuant to Part 15 of the FCC Rules. These limits are designed to provide reasonable protection against harmful interference in a residential installation. This equipment generates, uses, and can radiate radio frequency energy and, if not installed and used in accordance with the instructions, may cause harmful interference to radio communications. There is no guarantee that interference will not occur in a particular installation. The vendor makes no representations or warranties with respect to the contents here and specially disclaims any implied warranties of merchantability or fitness for any purpose. Further the vendor reserves the right to revise this publication and to make changes to the contents here without obligation to notify any party beforehand. Duplication of this publication, in part or in whole, is not allowed without first obtaining the vendor’s approval in writing. The content of this user’s manual is subject to be changed without notice and we will not be responsible for any mistakes found in this user’s manual. All the brand and product names are trademarks of their respective companies. Dichiarazione di conformità Short Declaration of conformity sintetica We declare this product is complying Ai sensi dell’art. 2 comma 3 del D.M. with the laws in force and meeting all 275 del 30/10/2002 the essential requirements as specified by the directives Si dichiara che questo prodotto è conforme alle normative vigenti e 2004/108/CE, 2006/95/CE and soddisfa i requisiti essenziali richiesti 1999/05/CE dalle direttive whenever these laws may be applied 2004/108/CE, 2006/95/CE e 1999/05/CE quando ad esso applicabili Table of Contents Chapter 1: Introduction ....................................... -

Cray XT and Cray XE Y Y System Overview
Crayyy XT and Cray XE System Overview Customer Documentation and Training Overview Topics • System Overview – Cabinets, Chassis, and Blades – Compute and Service Nodes – Components of a Node Opteron Processor SeaStar ASIC • Portals API Design Gemini ASIC • System Networks • Interconnection Topologies 10/18/2010 Cray Private 2 Cray XT System 10/18/2010 Cray Private 3 System Overview Y Z GigE X 10 GigE GigE SMW Fibre Channels RAID Subsystem Compute node Login node Network node Boot /Syslog/Database nodes 10/18/2010 Cray Private I/O and Metadata nodes 4 Cabinet – The cabinet contains three chassis, a blower for cooling, a power distribution unit (PDU), a control system (CRMS), and the compute and service blades (modules) – All components of the system are air cooled A blower in the bottom of the cabinet cools the blades within the cabinet • Other rack-mounted devices within the cabinet have their own internal fans for cooling – The PDU is located behind the blower in the back of the cabinet 10/18/2010 Cray Private 5 Liquid Cooled Cabinets Heat exchanger Heat exchanger (XT5-HE LC only) (LC cabinets only) 48Vdc flexible Cage 2 buses Cage 2 Cage 1 Cage 1 Cage VRMs Cage 0 Cage 0 backplane assembly Cage ID controller Interconnect 01234567 Heat exchanger network cable Cage inlet (LC cabinets only) connection air temp sensor Airflow Heat exchanger (slot 3 rail) conditioner 48Vdc shelf 3 (XT5-HE LC only) 48Vdc shelf 2 L1 controller 48Vdc shelf 1 Blower speed controller (VFD) Blooewer PDU line filter XDP temperature XDP interface & humidity sensor -

PURE Crossfirex 790GX
PC-AM3RS790G - PURE CrossFireX 790GX The Sapphire PURE CrossFireX 790GX AM3 is designed for AMD Phenom II™ AM3 true quad-core processors and next generation graphics with high speed DDR3 DRAM module. Performance, scalability, and personalization are coupled with an innovative and efficient design incorporating new ATI CrossFireX and Hybrid CrossFire technologies. The Sapphire PURE CrossFireX 790GX AM3 is designed for PC enthusiasts, high-performance gamers and professional overclockers**. Cut to the chase and open up the system BIOS to mad tweaking for the hardcore overclocker, via real-time control and then using the AMD OverDrive utility. Get the power of multi GPU graphics behind you to experience the ultimate in high definition gaming . Loaded with next generation technologies like PCI Express® 2.0 and HyperTransport™ 3.0 technology, get the ammo you need in gaming, HD editing, and high resolution video to lead the pack, not follow it. Build your dream PC. Start with a Sapphire PURE CrossFireX 790GX AM3 motherboard. Overview Features Features and Benefits AMD Phenom&tarade; Quad-Core Processors with True Quad-Core Technology Realize new possibilities for connecting with friends, family, and digital entertainment with the phenomenal performance of the AMD Phenom™ II AM3 series quad-core processor. Built from the ground up for true quad-core performance, AMD Phenom™ processors speed through advanced multitasking, critical business productivity, advanced visual design and modeling, serious gaming, and visually stunning digital media -

2018 Annual Report on Form 10-K
2018 ANNUAL REPORT ON FORM 10-K MARCH 2019 DEAR SHAREHOLDERS: From the industry’s first 1GHz CPU to the world’s first GPU delivering a teraflop of computing power, AMD has always stood for pushing the boundaries of what is possible. A few years ago, we made several big bets to accelerate our pace of innovation, strengthen our execution, and enable AMD to deliver a leadership portfolio of computing and graphics processors capable of increasing our share of the $75 billion high-performance computing market. In 2018, we saw those bets begin to pay off as we delivered our second straight year of greater than 20% annual revenue growth and significantly improved our gross margin and profitability from the previous year. REVENUE GROSS MARGIN % R&D INVESTMENT EXPENSE/REVENUE % $ Billions $ Billions $6.5B 38% $1.43B 34% $5.3B 34% 33% $4.3B $1.20B 23% $1.01B 31% 2016 2017 2018 2016 2017 2018 2016 2017 2018 2016 2017 2018 Added $2.2B in revenue Significantly improved gross Increased R&D by more than Significant improvement over the last 2 years margin over last 2 years based 40% over the last 2 years in OPEX leverage on new product portfolio Our newest Ryzen™, EPYC™ and datacenter GPU products contributed more than $1.2 billion of revenue in 2018 and helped us gain share across our priority markets. In 2018, we added 3.9% points of desktop processor unit share, 5.3% points of notebook processor unit share and met our goal of exiting the year with mid-single digit server processor market share. -

The Gemini Network
The Gemini Network Rev 1.1 Cray Inc. © 2010 Cray Inc. All Rights Reserved. Unpublished Proprietary Information. This unpublished work is protected by trade secret, copyright and other laws. Except as permitted by contract or express written permission of Cray Inc., no part of this work or its content may be used, reproduced or disclosed in any form. Technical Data acquired by or for the U.S. Government, if any, is provided with Limited Rights. Use, duplication or disclosure by the U.S. Government is subject to the restrictions described in FAR 48 CFR 52.227-14 or DFARS 48 CFR 252.227-7013, as applicable. Autotasking, Cray, Cray Channels, Cray Y-MP, UNICOS and UNICOS/mk are federally registered trademarks and Active Manager, CCI, CCMT, CF77, CF90, CFT, CFT2, CFT77, ConCurrent Maintenance Tools, COS, Cray Ada, Cray Animation Theater, Cray APP, Cray Apprentice2, Cray C90, Cray C90D, Cray C++ Compiling System, Cray CF90, Cray EL, Cray Fortran Compiler, Cray J90, Cray J90se, Cray J916, Cray J932, Cray MTA, Cray MTA-2, Cray MTX, Cray NQS, Cray Research, Cray SeaStar, Cray SeaStar2, Cray SeaStar2+, Cray SHMEM, Cray S-MP, Cray SSD-T90, Cray SuperCluster, Cray SV1, Cray SV1ex, Cray SX-5, Cray SX-6, Cray T90, Cray T916, Cray T932, Cray T3D, Cray T3D MC, Cray T3D MCA, Cray T3D SC, Cray T3E, Cray Threadstorm, Cray UNICOS, Cray X1, Cray X1E, Cray X2, Cray XD1, Cray X-MP, Cray XMS, Cray XMT, Cray XR1, Cray XT, Cray XT3, Cray XT4, Cray XT5, Cray XT5h, Cray Y-MP EL, Cray-1, Cray-2, Cray-3, CrayDoc, CrayLink, Cray-MP, CrayPacs, CrayPat, CrayPort, Cray/REELlibrarian, CraySoft, CrayTutor, CRInform, CRI/TurboKiva, CSIM, CVT, Delivering the power…, Dgauss, Docview, EMDS, GigaRing, HEXAR, HSX, IOS, ISP/Superlink, LibSci, MPP Apprentice, ND Series Network Disk Array, Network Queuing Environment, Network Queuing Tools, OLNET, RapidArray, RQS, SEGLDR, SMARTE, SSD, SUPERLINK, System Maintenance and Remote Testing Environment, Trusted UNICOS, TurboKiva, UNICOS MAX, UNICOS/lc, and UNICOS/mp are trademarks of Cray Inc. -

Socket AM3 Processor Functional Data Sheet
AMD Confidential – Advance Information Socket AM3 Processor Functional Data Sheet Publication # 40778 Revision: 1.13 Issue Date: January 2009 Advanced Micro Devices AMD Confidential – Advance Information © 2007 – 2009 Advanced Micro Devices, Inc. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. The information contained herein may be of a preliminary or advance nature and is subject to change without notice. No license, whether express, implied, arising by estoppel or otherwise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other application in which the failure of AMD’s product could create a situation where personal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD Arrow logo, and combinations thereof are trademarks of Advanced Micro Devices, Inc. -

Overview of the Next Generation Cray XMT
Overview of the Next Generation Cray XMT Andrew Kopser and Dennis Vollrath, Cray Inc. ABSTRACT: The next generation of Cray’s multithreaded supercomputer is architecturally very similar to the Cray XMT, but the memory system has been improved significantly and other features have been added to improve reliability, productivity, and performance. This paper begins with a review of the Cray XMT followed by an overview of the next generation Cray XMT implementation. Finally, the new features of the next generation XMT are described in more detail and preliminary performance results are given. KEYWORDS: Cray, XMT, multithreaded, multithreading, architecture 1. Introduction The primary objective when designing the next Cray XMT generation Cray XMT was to increase the DIMM The Cray XMT is a scalable multithreaded computer bandwidth and capacity. It is built using the Cray XT5 built with the Cray Threadstorm processor. This custom infrastructure with DDR2 technology. This change processor is designed to exploit parallelism that is only increases each node’s memory capacity by a factor of available through its unique ability to rapidly context- eight and DIMM bandwidth by a factor of three. switch among many independent hardware execution streams. The Cray XMT excels at large graph problems Reliability and productivity were important goals for that are poorly served by conventional cache-based the next generation Cray XMT as well. A source of microprocessors. frustration, especially for new users of the current Cray XMT, is the issue of hot spots. Since all memory is The Cray XMT is a shared memory machine. The programming model assumes a flat, globally accessible, globally accessible and the application has access to shared address space. -

AMD Opteron™ 4000 Series Platform Quick Reference Guide
AMD Opteron™ 4000 Series Platform Quick Reference Guide The AMD Opteron™ 4100 Series processor, the world’s lowest power per core processor1, sets the foundation for cloud workloads and affordability for mainstream infrastructure servers with prices starting at $992. AMD Opteron™ 4100 Series Processor END USER BENEFITS Outstanding Performance-Per-Watt > Designed from the ground up to handle demanding server workloads at the lowest available energy draw, beating the competition by as much as 40% (per/core).1 Business Value > The world’s first 1P and 2P capable processor at sub $100 pricing.2 Easy to Purchase and Operate > Scalable solutions with feature, component and platform consistency. PRODUCT FEATURES New AMD-P 2.0 Power Savings Features: > Ultra-low power platforms provide power efficiency beyond just the processor, 3 SOUNDBITE for both 1P and 2P server configurations. THE WORLD’S LOWEST POWER PER CORE SERVER PROCESSOR1 > APML (Advanced Platform Management Link)4 provides an interface for processor and systems management monitoring and controlling of system resources such as platform power Quick Features consumption via p-state limits and CPU thermals to closely monitor power and cooling. AMD-P 2.0: > Link Width PowerCap which changes all 16-bit links to 8-bit links5 can help power conscious Ultra-low power platform > customers improve performance-per-watt. > Advanced Platform Management Link (APML)4 > AMD CoolSpeed Technology reduces p-states when a temperature limit is reached to allow a > Link Width PowerCap server to operate if the processor’s thermal environment exceeds safe operational limits. > AMD CoolSpeed Technology > When C1E5,6 is enabled, the cores, southbridge and memory controller enter a sleep state that > C1E6 can equate to significant power savings in the datacenter depending on system configuration. -

Pubtex Output 2011.12.12:1229
TM Using Cray Performance Analysis Tools S–2376–53 © 2006–2011 Cray Inc. All Rights Reserved. This document or parts thereof may not be reproduced in any form unless permitted by contract or by written permission of Cray Inc. U.S. GOVERNMENT RESTRICTED RIGHTS NOTICE The Computer Software is delivered as "Commercial Computer Software" as defined in DFARS 48 CFR 252.227-7014. All Computer Software and Computer Software Documentation acquired by or for the U.S. Government is provided with Restricted Rights. Use, duplication or disclosure by the U.S. Government is subject to the restrictions described in FAR 48 CFR 52.227-14 or DFARS 48 CFR 252.227-7014, as applicable. Technical Data acquired by or for the U.S. Government, if any, is provided with Limited Rights. Use, duplication or disclosure by the U.S. Government is subject to the restrictions described in FAR 48 CFR 52.227-14 or DFARS 48 CFR 252.227-7013, as applicable. Cray, LibSci, and PathScale are federally registered trademarks and Active Manager, Cray Apprentice2, Cray Apprentice2 Desktop, Cray C++ Compiling System, Cray CX, Cray CX1, Cray CX1-iWS, Cray CX1-LC, Cray CX1000, Cray CX1000-C, Cray CX1000-G, Cray CX1000-S, Cray CX1000-SC, Cray CX1000-SM, Cray CX1000-HN, Cray Fortran Compiler, Cray Linux Environment, Cray SHMEM, Cray X1, Cray X1E, Cray X2, Cray XD1, Cray XE, Cray XEm, Cray XE5, Cray XE5m, Cray XE6, Cray XE6m, Cray XK6, Cray XMT, Cray XR1, Cray XT, Cray XTm, Cray XT3, Cray XT4, Cray XT5, Cray XT5h, Cray XT5m, Cray XT6, Cray XT6m, CrayDoc, CrayPort, CRInform, ECOphlex, Gemini, Libsci, NodeKARE, RapidArray, SeaStar, SeaStar2, SeaStar2+, Sonexion, The Way to Better Science, Threadstorm, uRiKA, and UNICOS/lc are trademarks of Cray Inc.