From the Editor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

YELLOW FEVER SITUATION REPORT Report of Yellow Fever Cases in 14 States Serial Number 010: Epi-Week 4 (As at 29 January 2021)
YELLOW FEVER SITUATION REPORT Report of Yellow fever Cases in 14 States Serial Number 010: Epi-Week 4 (as at 29 January 2021) HIGHLIGHTS ▪ The Nigeria Centre for Disease Control (NCDC) is currently responding to reports of yellow fever cases in 14 states - Akwa Ibom, Bauchi, Benue, Borno, Delta, Ebonyi, Enugu, Gombe, Imo, Kogi, Osun, Oyo, Plateau and Taraba States From the 14 States ▪ In the last week (weeks 4, 2021) ‒ Four new confirmed cases were reported from National Reference Laboratory (NRL) from 2 Local Government Areas (LGAs) in Benue - [Okpokwu (3), Ado (1) ‒ Thirteen presumptive positive cases were reported from NRL [Benue (6)] and Central Public Health Laboratory (CPHL) from [Enugu (6), Oyo (1)] ‒ One new LGA reported a confirmed case from Ado (1) in Benue State, ‒ No new death was recorded among confirmed cases ▪ Cumulatively from epi-week 24, 2020 – epi-week 4, 2021 ‒ A total of 1,502 suspected cases with 179 presumptive positive cases have been reported from 34 LGAs across 14 States from the Nigeria Laboratories ‒ Out of the 1,502 suspected, 161 confirmed cases [Delta-63 Ika North-East (48), Aniocha-South(6), Ika South (4), Oshimili South (2), Oshimili North(1), Ukwuani(1), Ndokwa West (1)], [Enugu-53 Enugu East (4), Enugu North (1), Igbo-Etiti (6), Igbo-Eze North(13), Isi-Uzo (15), Nkanu West (3) Nsukka(8), Udenu (3)], [Benue-17 (Ogbadibo (12), Okpokwu (4), Ado (1)], [Bauchi-9 Ganjuwa (8), Darazo (1)], [Borno-6 Gwoza(1), Hawul (1), Jere (2), Shani (1), Maiduguri (1)], [Ebonyi-3 Ohaukwu (3)], [Oyo-3), Ibarapa North East (1), Ibarapa North (2)], [Gombe-1 Akko (1)], [Imo-1 Owerri North(1)], [Kogi-1 Lokoja (1)], [Plateau- 1 Langtang North (1)], [Taraba-1 Jalingo (1)], [Akwa Ibom-1 Uyo(1)] and [Osun-1 Ilesha East (1)]. -

Nigeria's Constitution of 1999
PDF generated: 26 Aug 2021, 16:42 constituteproject.org Nigeria's Constitution of 1999 This complete constitution has been generated from excerpts of texts from the repository of the Comparative Constitutions Project, and distributed on constituteproject.org. constituteproject.org PDF generated: 26 Aug 2021, 16:42 Table of contents Preamble . 5 Chapter I: General Provisions . 5 Part I: Federal Republic of Nigeria . 5 Part II: Powers of the Federal Republic of Nigeria . 6 Chapter II: Fundamental Objectives and Directive Principles of State Policy . 13 Chapter III: Citizenship . 17 Chapter IV: Fundamental Rights . 20 Chapter V: The Legislature . 28 Part I: National Assembly . 28 A. Composition and Staff of National Assembly . 28 B. Procedure for Summoning and Dissolution of National Assembly . 29 C. Qualifications for Membership of National Assembly and Right of Attendance . 32 D. Elections to National Assembly . 35 E. Powers and Control over Public Funds . 36 Part II: House of Assembly of a State . 40 A. Composition and Staff of House of Assembly . 40 B. Procedure for Summoning and Dissolution of House of Assembly . 41 C. Qualification for Membership of House of Assembly and Right of Attendance . 43 D. Elections to a House of Assembly . 45 E. Powers and Control over Public Funds . 47 Chapter VI: The Executive . 50 Part I: Federal Executive . 50 A. The President of the Federation . 50 B. Establishment of Certain Federal Executive Bodies . 58 C. Public Revenue . 61 D. The Public Service of the Federation . 63 Part II: State Executive . 65 A. Governor of a State . 65 B. Establishment of Certain State Executive Bodies . -
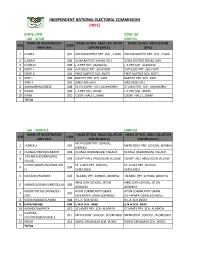
State: Oyo Code: 30 Lga : Afijio Code: 01 Name of Registration Name of Reg
INDEPENDENT NATIONAL ELECTORAL COMMISSION (INEC) STATE: OYO CODE: 30 LGA : AFIJIO CODE: 01 NAME OF REGISTRATION NAME OF REG. AREA COLLATION NAME OF REG. AREA CENTRE S/N CODE AREA (RA) CENTRE (RACC) (RAC) 1 ILORA I 001 OKEDIJI BAPTIST PRY. SCH., ILORA OKEDIJI BAPTIST PRY. SCH., ILORA 2 ILORA II 002 ILORA BAPTIST GRAM. SCH. ILORA BAPTIST GRAM. SCH. 3 ILORA III 003 L.A PRY SCH. ALAWUSA. L.A PRY SCH. ALAWUSA. 4 FIDITI I 004 CATHOLIC PRY. SCH FIDITI CATHOLIC PRY. SCH FIDITI 5 FIDITI II 005 FIRST BAPTIST SCH. FIDITI FIRST BAPTIST SCH. FIDITI 6 AWE I 006 BAPTIST PRY. SCH. AWE BAPTIST PRY. SCH. AWE 7 AWE II 007 AWE HIGH SCH. AWE HIGH SCH. 8 AKINMORIN/JOBELE 008 ST.JOHN PRY. SCH. AKINMORIN ST.JOHN PRY. SCH. AKINMORIN 9 IWARE 009 L.A PRY SCH. IWARE. L.A PRY SCH. IWARE. 10 IMINI 010 COURT HALL 1, IMINI COURT HALL 1, IMINI TOTAL LGA : AKINYELE CODE: 02 NAME OF REGISTRATION NAME OF REG. AREA COLLATION NAME OF REG. AREA COLLATION S/N CODE AREA (RA) CENTRE (RACC) CENTRE (RACC) METHODIST PRY. SCHOOL, 1 IKEREKU 001 METHODIST PRY. SCHOOL, IKEREKU IKEREKU 2 OLANLA/OBODA/LABODE 002 OLANLA (OGBANGAN) VILLAGE OLANLA (OGBANGAN) VILLAGE EOLANLA (OGBANGAN) 3 003 COURT HALL ARULOGUN VILLAGE COURT HALL ARULOGUN VILLAGE VILLAG OLODE/AMOSUN/ONIDUND ST. LUKES PRY. SCHOOL, ST. LUKES PRY. SCHOOL, 4 004 U ONIDUNDU ONIDUNDU 5 OJO-EMO/MONIYA 005 ISLAMIC PRY. SCHOOL, MONIYA ISLAMIC PRY. SCHOOL, MONIYA ANGLICAN SCHOOL, OTUN ANGLICAN SCHOOL, OTUN 6 AKINYELE/ISABIYI/IREPODUN 006 AGBAKIN AGBAKIN IWOKOTO/TALONTAN/IDI- AYUN COMMUNITY GRAM. -

Oyo State Ubec Fts Shortlist
UNIVERSAL BASIC EDUCATION COMMISSION (UBEC) FEDERAL TEACHERS’ SCHEME (FTS) SHORTLISTED CANDIDATES OYO STATE EXAM S/NO NAME STATE LGA SEX COURSE OF STUDY STATUS NO AMINAT ODEDELE 1 001YY OYO AFIJIO F PHYSICS/MATHEMATICS SHORTLISTED OMOLOLA ABOSEDE 2 002YY AKINRINOLA OYO AFIJIO F BIOLOGY EDUCATION SHORTLISTED DEBORAH ESTHER 3 003YY FEYISETAN OYO AFIJIO F EDUCATION/ENGLISH SHORTLISTED OLUWAFERANMI OLUWATOYIN INTEGRATED 4 004YY OLAGBAMI OYO AFIJIO F SHORTLISTED SCIENCE/BIOLOGY IFEOLUWA SUNDAY 5 005YY ADEKANBI OYO AFIJIO M MATHEMATICS SHORTLISTED OLANREWAJU OLUWATOSIN 6 006YY OYO AFIJIO M EDUCATION/MATHEMATICS SHORTLISTED AKANO JOHN BLESSING 7 007YY ADEBOWALE OYO AFIJIO F BIOLOGY /CHEMISTRY SHORTLISTED OPEYEMI ADEBUNMI OJO 8 008YY OYO AFIJIO F HOME ECONOMICS SHORTLISTED NIKE IFETAYO DAIRO 9 009YY OYO AFIJIO M HUMAN KINETICS SHORTLISTED ELIJAH ADEOLU ADELEYE 10 010YY OYO AFIJIO M SPECIAL EDUCATION/MATHE SHORTLISTED AKINTUNDE REUBEN 11 011YY FUNMILAYO OYO AFIJIO M YORUBA SHORTLISTED ADEGOKE TOHEEB AJAO SPECIAL 12 012YY OYO AFIJIO M SHORTLISTED OPEYEMI EDUCATION/MATHEM ABOSEDE 13 013YY OGUNTUNJI OYO AFIJIO F BIOLOGY SHORTLISTED REBECCA OMOLOLA 14 014YY OGUNKUNLE OYO AFIJIO F BIOLOGY EDUCATION SHORTLISTED ABOSEDE FAITH OLAJIRE 15 015YY OYO AKINYELE F MATHEMATICS/GEOGRAPHY SHORTLISTED OMOWUMI TITILOPE AREMU 16 016YY OYO AKINYELE F FINE ART SHORTLISTED ADEBISI RAFIAT COMPUTER 17 017YY SALAWUDEEN OYO AKINYELE F SHORTLISTED SCIENCE/MATHEMA ADENIKE GAFAR KOLAPO ENGLISH LANGUAGE AND 18 018YY OYO AKINYELE M SHORTLISTED ABIODUN YORUBA TEJUMADE 19 019YY -

0514001001 Federal Ministry of Women Affairs - Hqtrs
Federal Government of Nigeria SUMMARY BY MDAs 2014 FGN BUDGET PROPOSAL NO CODE MDA TOTAL PERSONNEL TOTAL OVERHEAD TOTAL RECURRENT TOTAL CAPITAL TOTAL ALLOCATION 1 0514 FEDERAL MINISTRY OF 926,000,948 612,262,602 1,538,263,550 2,992,311,641 4,530,575,191 WOMEN AFFAIRS 926,000,948 612,262,602 1,538,263,550 2,992,311,641 4,530,575,191 SUMMARY BY FUNDS 2014 FGN BUDGET PROPOSAL NO CODE FUND TOTAL ALLOCATION 1 021 MAIN ENVELOP - PERSONNEL 926,000,948 2 022 MAIN ENVELOP - OVERHEAD 612,262,602 3 031 CAPITAL DEVELOPMENT FUND MAIN 2,992,311,641 4,530,575,191 FEDERAL MINISTRY OF WOMEN AFFAIRS 2014 FGN BUDGET PROPOSAL NO CODE MDA TOTAL PERSONNEL TOTAL OVERHEAD TOTAL RECURRENT TOTAL CAPITAL TOTAL ALLOCATION 1 0514001001 FEDERAL MINISTRY OF 742,858,577 491,002,277 1,233,860,855 2,549,804,533 3,783,665,388 WOMEN AFFAIRS - HQTRS 2 0514002001 NATIONAL CENTRE FOR 183,142,371 121,260,325 304,402,696 442,507,108 746,909,804 WOMEN DEVELOPMENT 926,000,948 612,262,602 1,538,263,550 2,992,311,641 4,530,575,191 0514001001 FEDERAL MINISTRY OF WOMEN AFFAIRS - HQTRS CODE LINE ITEM AMOUNT 2 EXPENDITURE 3,783,665,388 21 PERSONNEL COST 742,858,577 2101 SALARY 660,318,735 210101 SALARIES AND WAGES 660,318,735 21010101 SALARY 660,318,735 2102 ALLOWANCES AND SOCIAL CONTRIBUTION 82,539,842 210202 SOCIAL CONTRIBUTIONS 82,539,842 21020201 NHIS 33,015,937 21020202 CONTRIBUTORY PENSION 49,523,905 22 OTHER RECURRENT COSTS 491,002,277 2202 OVERHEAD COST 488,297,920 220201 TRAVEL& TRANSPORT - GENERAL 80,307,092 22020101 LOCAL TRAVEL & TRANSPORT: TRAINING 20,182,514 22020102 LOCAL -

7.Results of Geophysical Survey
7.Results of Geophysical Survey 1. General 1-1 Purpose of Geophysical Survey The purpose of the geophysical survey is to find the promising communities with high potential ground water development. 1-2 Contents of geophysical survey -1st Stage (BD1) The geophysical survey was conducted in 100 communities of high priority selected among 220 communities -2nd stage(BD2) 56 communities among 100 communities were analyzed as low potential water development in 1st stage. The geophysical re-survey conducted at these 56 communities and in the new 17 additional communities. Total of geophysical survey including re-survey is 117communities (173 sites). ① Electromagnetic Survey ・Method :Loop-Loop (Srigram) ・Line :more than200 m(5 m interval) ・Equipment :GEONICS EM34 ・Analysis :Horizontal Electric Conductivity Profiling ② Resistivity Survey ・Method :Schlumberger method ・Survey depth:a=100m ・Equipment :ABEM SAS300B ・Analysis :1dimention inversion 2. Result of survey 2-1 Potential of Ground Water Basement of survey area is composed with crystal formation (Granite, Gneiss) in Precambrian Period. Upper stratum is weathered. According to the situation of weathered zone, crack and fault in crystal rock (Granite, Gneiss), the formation of aquifer is not constant due to thickness of weathered zone and scale of crack etc. Formation of aquifer are as follow: ・ It is difficult to find aquifer in fissure zone ・ Main aquifer from the test boreholes are located in the boundary between weathered zone and basement. ・ The thickness of weathered zone needs to be more than 20m for high potential of water development ・ Based on the electric conductivity and existing data, the resistivity of weathered zone needs to be less than 130 ohm-m. -

Report on Epidemiological Mapping of Schistosomiasis and Soil Transmitted Helminthiasis in 19 States and the FCT, Nigeria
Report on Epidemiological Mapping of Schistosomiasis and Soil Transmitted Helminthiasis in 19 States and the FCT, Nigeria. May, 2015 i Table of Contents Acronyms ......................................................................................................................................................................v Foreword ......................................................................................................................................................................vi Acknowledgements ...............................................................................................................................................vii Executive Summary ..............................................................................................................................................viii 1.0 Background ............................................................................................................................................1 1.1 Introduction .................................................................................................................................................1 1.2 Objectives of the Mapping Project ..................................................................................................2 1.3 Justification for the Survey ..................................................................................................................2 2.0. Mapping Methodology ......................................................................................................................3 -

Survey of Processed Fish Products Sold in Oyo State, South West Nigeria
Research & Reviews: Journal of Agriculture and Allied Sciences e-ISSN:2347-226X p-ISSN:2319-9857 Survey of Processed Fish Products Sold in Oyo State, South West Nigeria Ayeloja AA1*, George FOA2, Adebisi GL3 and Jimoh WA1 1Department of Aquaculture and Fisheries, University of Ilorin, PMB 1515 Ilorin, Kwara State, Nigeria 2Department of Aquaculture and Fisheries Management, Federal University of Agriculture, Abeokuta (FUNAAB) PO Box 2240 Abeokuta, Nigeria 3Department of Agriculture Extension and Management, Federal College of Animal Health and Production Technology Moor Plantation, PMB 5029 Ibadan, Nigeria Research Article Received date: 22/11/2016 ABSTRACT Accepted date: 15/11/2018 The study reveals the survey of processed fish products, in Oyo Published date: 26/11/2018 state south west Nigeria. A multistage sampling technique was used to select 150 respondents from 9 wards within Oyo state and information *For Correspondence on socio-economic characteristics of the respondents, the types of processed fish products available in Oyo State, the marketing channels Ayeloja AA, Department of Aquaculture and of processed fish in Oyo State and marketing efficiency of fish products Fisheries, University of Ilorin, PMB 1515 Ilorin, were obtained using semi-structured questionnaire. Data were analyzed Kwara State, Nigeria. using descriptive statistics and budgetary technique. This study revealed that 74% of the respondents fall within the age group of 50 years or less, all the respondents in the study area were female. Also, whole smoked E-mail: [email protected] fish was the most available processed fish product (78.7%) while canned fish and fish cracker were least available (2% and 0.7% respectively) fish Keywords: Survey, Processed, Fish products, Sold products in the study area. -

Report on Epidemiological Mapping of Schistosomiasis and Soil Transmitted Helminthiasis in 19 States and the FCT, Nigeria
Report on Epidemiological Mapping of Schistosomiasis and Soil Transmitted Helminthiasis in 19 States and the FCT, Nigeria. May, 2015 Report on Epidemiological Mapping of Schistosomiasis and Soil Transmitted Helminthiasis in 19 States and the FCT, Nigeria. ii TABLE OF CONTENTS LIST OF FIGURES ...................................................................................................................................... v LIST OF PLATES ...................................................................................................................................... vii FOREWORD .............................................................................................................................................. x EXECUTIVE SUMMARY ........................................................................................................................... xii 1.0 BACKGROUND ................................................................................................................................... 1 1.1 Introduction ................................................................................................................................... 1 1.2 Objectives of the Mapping Project ................................................................................................ 2 1.3 Justification for the Survey ............................................................................................................ 2 2.0. MAPPING METHODOLOGY .............................................................................................................. -

Khalil Samihah a Case Study of Service Delivery by Local
CIEA7 #38: DILEMMAS OF AFRICAN MODERNITY AND THEIR THEORETICAL CHALLENGES. Khalil Samihah [email protected] Salihu Abdulwaheed Adelabu [email protected] A Case study of Service Delivery by Local Government Councils in Oyo state in relation to Fund and Constitutional Issues Purpose - The purpose of the paper is to review the performance of Local government councils in Oyo state of Nigeria from two major view lens viz-a-viz Constitutional and Fund/Statutory allocation perspectives in relation to service delivery. Design/methodology/approach – The research adopts quantitative and qualitative approach. Correlation between service delivery and fund/statutory allocation is established in order to assess the solvency of fund flow in the Local Government Councils. Findings – Contrary to the findings of previous studies that fund is always insufficient, the result shows that fund flow in Nigerian Local government councils is regular and sufficient to provide basic essential services. Research limitations/implications – This paper covers only 33 out of 774 Local government councils in Nigeria. Originality/value –The policy-makers can use the findings of this study to help inform future decisions with respect to service delivery in Nigeria. Service Delivery, Constitution, Fund/ Resource Allocation. Universiti Utara Malaysia. Universiti Utara Malaysia. 7.º CONGRESSO IBÉRICO DE ESTUDOS AFRICANOS | 7.º CONGRESO DE ESTUDIOS AFRICANOS | 7TH CONGRESS OF AFRICAN STUDIES LISBOA 2010 Khalil Samihah & Salihu Abdulwaheed Adelabu 2 INTRODUCTION Development is synonymous to freedom in any society. If a society is developed, the people in that society is always said to be free from diseases, hunger, poverty, illness, illiteracy, ignorance, and insecurity. -

New Projects Inserted by Nass
NEW PROJECTS INSERTED BY NASS CODE MDA/PROJECT 2018 Proposed Budget 2018 Approved Budget FEDERAL MINISTRY OF AGRICULTURE AND RURAL SUPPLYFEDERAL AND MINISTRY INSTALLATION OF AGRICULTURE OF LIGHT AND UP COMMUNITYRURAL DEVELOPMENT (ALL-IN- ONE) HQTRS SOLAR 1 ERGP4145301 STREET LIGHTS WITH LITHIUM BATTERY 3000/5000 LUMENS WITH PIR FOR 0 100,000,000 2 ERGP4145302 PROVISIONCONSTRUCTION OF SOLAR AND INSTALLATION POWERED BOREHOLES OF SOLAR IN BORHEOLEOYO EAST HOSPITALFOR KOGI STATEROAD, 0 100,000,000 3 ERGP4145303 OYOCONSTRUCTION STATE OF 1.3KM ROAD, TOYIN SURVEYO B/SHOP, GBONGUDU, AKOBO 0 50,000,000 4 ERGP4145304 IBADAN,CONSTRUCTION OYO STATE OF BAGUDU WAZIRI ROAD (1.5KM) AND EFU MADAMI ROAD 0 50,000,000 5 ERGP4145305 CONSTRUCTION(1.7KM), NIGER STATEAND PROVISION OF BOREHOLES IN IDEATO NORTH/SOUTH 0 100,000,000 6 ERGP445000690 SUPPLYFEDERAL AND CONSTITUENCY, INSTALLATION IMO OF STATE SOLAR STREET LIGHTS IN NNEWI SOUTH LGA 0 30,000,000 7 ERGP445000691 TOPROVISION THE FOLLOWING OF SOLAR LOCATIONS: STREET LIGHTS ODIKPI IN GARKUWARI,(100M), AMAKOM SABON (100M), GARIN OKOFIAKANURI 0 400,000,000 8 ERGP21500101 SUPPLYNGURU, YOBEAND INSTALLATION STATE (UNDER OF RURAL SOLAR ACCESS STREET MOBILITY LIGHTS INPROJECT NNEWI (RAMP)SOUTH LGA 0 30,000,000 9 ERGP445000692 TOSUPPLY THE FOLLOWINGAND INSTALLATION LOCATIONS: OF SOLAR AKABO STREET (100M), LIGHTS UHUEBE IN AKOWAVILLAGE, (100M) UTUH 0 500,000,000 10 ERGP445000693 ANDEROSION ARONDIZUOGU CONTROL IN(100M), AMOSO IDEATO - NCHARA NORTH ROAD, LGA, ETITI IMO EDDA, STATE AKIPO SOUTH LGA 0 200,000,000 11 ERGP445000694 -

States and Lcdas Codes.Cdr
PFA CODES 28 UKANEFUN KPK AK 6 CHIBOK CBK BO 8 ETSAKO-EAST AGD ED 20 ONUIMO KWE IM 32 RIMIN-GADO RMG KN KWARA 9 IJEBU-NORTH JGB OG 30 OYO-EAST YYY OY YOBE 1 Stanbic IBTC Pension Managers Limited 0021 29 URU OFFONG ORUKO UFG AK 7 DAMBOA DAM BO 9 ETSAKO-WEST AUC ED 21 ORLU RLU IM 33 ROGO RGG KN S/N LGA NAME LGA STATE 10 IJEBU-NORTH-EAST JNE OG 31 SAKI-EAST GMD OY S/N LGA NAME LGA STATE 2 Premium Pension Limited 0022 30 URUAN DUU AK 8 DIKWA DKW BO 10 IGUEBEN GUE ED 22 ORSU AWT IM 34 SHANONO SNN KN CODE CODE 11 IJEBU-ODE JBD OG 32 SAKI-WEST SHK OY CODE CODE 3 Leadway Pensure PFA Limited 0023 31 UYO UYY AK 9 GUBIO GUB BO 11 IKPOBA-OKHA DGE ED 23 ORU-EAST MMA IM 35 SUMAILA SML KN 1 ASA AFN KW 12 IKENNE KNN OG 33 SURULERE RSD OY 1 BADE GSH YB 4 Sigma Pensions Limited 0024 10 GUZAMALA GZM BO 12 OREDO BEN ED 24 ORU-WEST NGB IM 36 TAKAI TAK KN 2 BARUTEN KSB KW 13 IMEKO-AFON MEK OG 2 BOSARI DPH YB 5 Pensions Alliance Limited 0025 ANAMBRA 11 GWOZA GZA BO 13 ORHIONMWON ABD ED 25 OWERRI-MUNICIPAL WER IM 37 TARAUNI TRN KN 3 EDU LAF KW 14 IPOKIA PKA OG PLATEAU 3 DAMATURU DTR YB 6 ARM Pension Managers Limited 0026 S/N LGA NAME LGA STATE 12 HAWUL HWL BO 14 OVIA-NORTH-EAST AKA ED 26 26 OWERRI-NORTH RRT IM 38 TOFA TEA KN 4 EKITI ARP KW 15 OBAFEMI OWODE WDE OG S/N LGA NAME LGA STATE 4 FIKA FKA YB 7 Trustfund Pensions Plc 0028 CODE CODE 13 JERE JRE BO 15 OVIA-SOUTH-WEST GBZ ED 27 27 OWERRI-WEST UMG IM 39 TSANYAWA TYW KN 5 IFELODUN SHA KW 16 ODEDAH DED OG CODE CODE 5 FUNE FUN YB 8 First Guarantee Pension Limited 0029 1 AGUATA AGU AN 14 KAGA KGG BO 16 OWAN-EAST