Assignment 3 1/21/2015
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Clones Stick Together
TVhome The Daily Home April 12 - 18, 2015 Clones Stick Together Sarah (Tatiana Maslany) is on a mission to find the 000208858R1 truth about the clones on season three of “Orphan Black,” premiering Saturday at 8 p.m. on BBC America. The Future of Banking? We’ve Got A 167 Year Head Start. You can now deposit checks directly from your smartphone by using FNB’s Mobile App for iPhones and Android devices. No more hurrying to the bank; handle your deposits from virtually anywhere with the Mobile Remote Deposit option available in our Mobile App today. (256) 362-2334 | www.fnbtalladega.com Some products or services have a fee or require enrollment and approval. Some restrictions may apply. Please visit your nearest branch for details. 000209980r1 2 THE DAILY HOME / TV HOME Sun., April 12, 2015 — Sat., April 18, 2015 DISH AT&T DIRECTV CABLE CHARTER CHARTER PELL CITY PELL ANNISTON CABLE ONE CABLE TALLADEGA SYLACAUGA BIRMINGHAM BIRMINGHAM BIRMINGHAM CONVERSION CABLE COOSA SPORTS WBRC 6 6 7 7 6 6 6 6 AUTO RACING Friday WBIQ 10 4 10 10 10 10 6 p.m. FS1 St. John’s Red Storm at Drag Racing WCIQ 7 10 4 Creighton Blue Jays (Live) WVTM 13 13 5 5 13 13 13 13 Sunday Saturday WTTO 21 8 9 9 8 21 21 21 7 p.m. ESPN2 Summitracing.com 12 p.m. ESPN2 Vanderbilt Com- WUOA 23 14 6 6 23 23 23 NHRA Nationals from The Strip at modores at South Carolina WEAC 24 24 Las Vegas Motor Speedway in Las Gamecocks (Live) WJSU 40 4 4 40 Vegas (Taped) 2 p.m. -

Sight & Sound Films of 2007
Sight & Sound Films of 2007 Each year we ask a selection of our contributors - reviewers and critics from around the world - for their five films of the year. It's a very loosely policed subjective selection, based on films the writer has seen and enjoyed that year, and we don't deny them the choice of films that haven't yet reached the UK. And we don't give them much time to ponder, either - just about a week. So below you'll find the familiar and the obscure, the new and the old. From this we put together the top ten you see here. What distinguishes this particular list is that it's been drawn up from one of the best years for all-round quality I can remember. 2007 has seen some extraordinary films. So all of the films in the ten are must-sees and so are many more. Enjoy. - Nick James, Editor. 1 4 Months, 3 Weeks and 2 Days (Cristian Mungiu) 2 Inland Empire (David Lynch) 3 Zodiac (David Fincher) = 4 I’m Not There (Todd Haynes) The Lives of Others (Florian Henckel von Donnersmarck) 6 Silent Light (Carlos Reygadas) = 7 The Assassination of Jesse James by the Coward Robert Ford (Andrew Dominik) Syndromes and a Century (Apichatpong Weerasethakul) No Country for Old Men (Ethan and Joel Coen) Eastern Promises (David Cronenberg) 1 Table of Contents – alphabetical by critic Gilbert Adair (Critic and author, UK)............................................................................................4 Kaleem Aftab (Critic, The Independent, UK)...............................................................................4 Geoff Andrew (Critic -
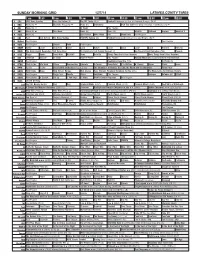
Sunday Morning Grid 12/7/14 Latimes.Com/Tv Times
SUNDAY MORNING GRID 12/7/14 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) The NFL Today (N) Å Football Pittsburgh Steelers at Cincinnati Bengals. (N) Å 4 NBC News (N) Å Meet the Press (N) Å News (N) Swimming PGA Tour Golf Hero World Challenge, Final Round. (N) Å 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) News (N) Wildlife Outback Explore World of X 9 KCAL News (N) Joel Osteen Mike Webb Paid Woodlands Paid Program 11 FOX Paid Joel Osteen Fox News Sunday FOX NFL Sunday (N) Football Indianapolis Colts at Cleveland Browns. (N) Å 13 MyNet Paid Program Paid Program 18 KSCI Paid Program Church Faith Paid Program 22 KWHY Como Local Jesucristo Local Local Gebel Local Local Local Local Transfor. Transfor. 24 KVCR The Omni Health Revolution With Tana Amen Dr. Fuhrman’s End Dieting Forever! Å Joy Bauer’s Food Remedies (TVG) Deepak 28 KCET Raggs Space Travel-Kids Biz Kid$ News Asia Biz Things That Aren’t Here Anymore More Things Aren’t Here Anymore 30 ION Jeremiah Youssef In Touch Hour Of Power Paid Program Holiday Heist (2011) Lacey Chabert, Rick Malambri. 34 KMEX Paid Program República Deportiva (TVG) Al Punto (N) 40 KTBN Walk in the Win Walk Prince Redemption Liberate In Touch PowerPoint It Is Written B. Conley Super Christ Jesse 46 KFTR Tu Dia Tu Dia Beverly Hills Chihuahua 2 (2011) (G) The Chronicles of Narnia: The Lion, the Witch and the Wardrobe Fútbol MLS 50 KOCE Wild Kratts Maya Rick Steves’ Europe Rick Steves Suze Orman’s Financial Solutions for You (TVG) The Roosevelts: An Intimate History 52 KVEA Paid Program Raggs New. -

Drop Radio Wants Its Audiences to Dance by DEBBIE WILLIS Beyond Salt Spring
SECTION WEDNESDAY, AUGUST 27, 2003 Page 81 Drop Radio wants its audiences to dance By DEBBIE WILLIS beyond Salt Spring. pie's reactions to Canadian Staff Writer "We really want to start and Peruvian-born musi Drop Radio has what branching out and tapping cians playing reggae, seems like a simple goal: back into the Vancouver fan Meaghar said they have met when the band plays, they base," said Meaghar. "We're nothing but open minds. want people to dance. open to playing anything." "I haven't encountered According to guitar play Part of Drop Radio's any objections to us playing er Dave Campbell, when an appeal could be due to the reggae music. You've just audience gets down, there's fact that each show is differ got to play the music that a real connection between ent. comes from your soul. If it the band and the listeners. "We never play the same comes from your heart, you "It's a giving and receiv way twice," said Campbell, can do no wrong." ing: we spit music out and who mentioned the Eventually the band they give it right back when impromptu country version wants to record, and they they dance," he said. of Redemption Song they hope to produce a full "Everybody' s participat once performed. "There's a length album by next ing." high level of spontaneity." spring. Their only stipula When everyone in the The three members of the tions are that the recording _ room is grooving to the band bring varied back be "high quality" and pro same beat, lead singer and grounds to the creative pro duced on-island. -

CHAPTER I INTRODUCTION A. Background of the Study People
CHAPTER I INTRODUCTION A. Background of the Study People live in the world in various cultures. They live in different co mmunity and background. They are different, and they often have problems in their live. Life becomes more complex as more problems appear. They are having the same opportunity to get their property, prosperity and happiness. They must work hard and struggle to get such things. According to Meizeir (http: // www. self growth. com/ article/ Meizeir. html) “Struggle is any personal goal achievement accompanied by discomfort and resistance. Struggle may still certainly involve overcoming resistance and discomfort”. Struggle is identical wit h hero and it is a symbol of freedom of a nation to fight against the colonialism. It has a general meaning as a way to get the best result and something worth. People will do everything to get it. This occurs in many kinds of field, one of them in literary works. Literature is an artwork while has idea of struggle elements such as novel, poetry, and film. Film has the same position in textual studies. It is true that film has become part of daily life, which is more complicated than the other works. Making a film is not like writing a novel. It needs a teamwork, which involves many people as crew. Film has many elements, such as director, script, writer, editor, music composer, artistic , costume, designer, etc. 2 Beside that, it also needs some technique including cinematography, editing, and sound. There are many aspects of literature that describe our daily life and our surrounding such as struggle, effort, etc. -

Speed Kills / Hannibal Production in Association with Saban Films, the Pimienta Film Company and Blue Rider Pictures
HANNIBAL CLASSICS PRESENTS A SPEED KILLS / HANNIBAL PRODUCTION IN ASSOCIATION WITH SABAN FILMS, THE PIMIENTA FILM COMPANY AND BLUE RIDER PICTURES JOHN TRAVOLTA SPEED KILLS KATHERYN WINNICK JENNIFER ESPOSITO MICHAEL WESTON JORDI MOLLA AMAURY NOLASCO MATTHEW MODINE With James Remar And Kellan Lutz Directed by Jodi Scurfield Story by Paul Castro and David Aaron Cohen & John Luessenhop Screenplay by David Aaron Cohen & John Luessenhop Based upon the book “Speed Kills” by Arthur J. Harris Produced by RICHARD RIONDA DEL CASTRO, pga LUILLO RUIZ OSCAR GENERALE Executive Producers PATRICIA EBERLE RENE BESSON CAM CANNON MOSHE DIAMANT LUIS A. REIFKOHL WALTER JOSTEN ALASTAIR BURLINGHAM CHARLIE DOMBECK WAYNE MARC GODFREY ROBERT JONES ANSON DOWNES LINDA FAVILA LINDSEY ROTH FAROUK HADEF JOE LEMMON MARTIN J. BARAB WILLIAM V. BROMILEY JR NESS SABAN SHANAN BECKER JAMAL SANNAN VLADIMIRE FERNANDES CLAITON FERNANDES EUZEBIO MUNHOZ JR. BALAN MELARKODE RANDALL EMMETT GEORGE FURLA GRACE COLLINS GUY GRIFFITHE ROBERT A. FERRETTI SILVIO SARDI “SPEED KILLS” SYNOPSIS When he is forced to suddenly retire from the construction business in the early 1960s, Ben Aronoff immediately leaves the harsh winters of New Jersey behind and settles his family in sunny Miami Beach, Florida. Once there, he falls in love with the intense sport of off-shore powerboat racing. He not only races boats and wins multiple championship, he builds the boats and sells them to high-powered clientele. But his long-established mob ties catch up with him when Meyer Lansky forces him to build boats for his drug-running operations. Ben lives a double life, rubbing shoulders with kings and politicians while at the same time laundering money for the mob through his legitimate business. -

A-Z-Movies-November-2020.Pdf
NOVEMBER 2020 A-Z MOVIES 1% (MA 15+ a) missing father and unravel Mel Gibson, Robert Downey Jr MOVIES THRILLER 2006 Drama their high school reunion. Having MOVIES PREMIERE 2017 November 9, 15, 21 a mystery that threatens the A young pilot is unwittingly recruited (MA 15+ dlsv) decided to spend the weekend Drama (MA 15+ alsv) James Franco, Kate Mara. survival of our planet. into a covert and corrupt CIA November 2, 3, 15, 26 together reconnecting, they try to November 11 Trapped under a boulder, a mountain organisation transporting illicit goods Justin Timberlake, Emile Hirsch. recapture the glories of their youth. Matt Nable, Ryan Corr. climber faces the elements, death and ADAPTATION in and out of Southeast Asia during the When an arrogant young drug dealer The heir to the throne of a notorious his own demons before making the DRAMA MOVIES 2002 Vietnam war. kidnaps the brother of a client the AMERICAN SNIPER outlaw motorcycle club must betray grisliest decision of his life. Comedy (MA 15+ ad) situation quickly spirals out of control. DRAMA MOVIES 2014 his president to save his brother’s life. November 25 AIR BUD: Action/Adventure (MA 15+ av) 1941 Nicolas Cage, Meryl Streep. GOLDEN RECEIVER AMANDa KNOX: November 4, 11, 23, 26 8 MILE MOVIES GREATS 1979 Comedy (M s) The real and fictional intertwine in an MOVIES KIDS 1998 Family Murder ON TRIAL IN ITALY Bradley Cooper, Sienna Miller. DRAMA MOVIES 2002 Drama (M alsv) November 3, 12, 19, 30 explosive bid for survival between November 1, 6 LIFETIME MOVIES 2011 A Navy SEAL’s pinpoint accuracy saves November 2, 9, 12, 24 Dan Aykroyd, John Belushi. -

Participants Bios
AMY LEMISCH Executive Director California Film Commission As Executive Director of the California Film Commission, Amy Lemisch oversees all of the state's efforts to facilitate motion picture, television and commercial production. She was appointed by Governor Arnold Schwarzenegger in May 2004, and continues to serve for Governor Edmund G. Brown Jr. Under her leadership, the Commission coordinates with all levels of state and local government to promote California as a production locale. Such efforts in-turn create jobs, increase production spending and generate tax revenues. In addition to overseeing the Commission's wide range of support services, Ms. Lemisch also serves as the state's leading advocate for educating legislators, production industry decision makers and the public at large about the value of filming in California. Among her many accomplishments, Ms. Lemisch was instrumental in the creation, passage and implementation of the California Film & Television Tax Credit Program, which was enacted in 2009 to help curb runaway production. The Commission is charged with administering the $500 million program that targets the types of productions most likely to leave California due to incentives offered in other states and countries. Prior to her appointment at the Commission, Ms. Lemisch served for more than 15 years as a producer for Penny Marshall’s company - Parkway Productions. While based at Universal Studios and Sony Pictures, she was responsible for overseeing physical production on all Parkway projects, as well as selecting new projects for the company to produce. Her credits include: producer on the independent feature film WITH FRIENDS LIKE THESE; co-producer on RIDING IN CARS WITH BOYS (starring Drew Barrymore), THE PREACHER’S WIFE (starring Denzel Washington and Whitney Houston) and RENAISSANCE MAN (starring Danny DeVito); associate producer on AWAKENINGS, A LEAGUE OF THEIR OWN, and CALENDAR GIRL. -

John Doyle Insurancedoyle Insurance AGENCY
FINAL-2 Sat, Jun 30, 2018 8:14:39 PM Your Weekly Guide to TV Entertainment for the week of July 7 - 13, 2018 OLD FASHIONED SERVICE FREE REGISTRY SERVICE John Doyle INSURANCEDoyle Insurance AGENCY Voted #1 1 x 3 Insurance Agency When a big city crime reporter (Amy Adams, “Arrival,” 2016) returns to her hometown Home sweet home to cover a string of gruesome killings, not all is what it seems. Jean-Marc Vallée (“Dal- las Buyers Club,” 2013) reunites with HBO to helm another beloved novel adaptation Auto • Homeowners in Gillian Flynn’s “Sharp Objects,” premiering Sunday, July 8, on HBO. The ensemble Business • Life Insurance cast also includes Patricia Clarkson (“House of Cards”) and Chris Messina (“The Mindy Patricia Clarkson stars in “Sharp Objects” 978-777-6344 Project”). www.doyleinsurance.com FINAL-2 Sat, Jun 30, 2018 8:14:41 PM 2•SalemNews•July 7 - 13, 2018 Into the fire: A crime reporter is drawn home in ‘Sharp Objects’ By Francis Babin by Patricia Clarkson (“House of ten than not, alone. The boozy try to replicate its success by fol- discussed this at the ATX Television TV Media Cards”). nights help with her ever-growing lowing the same formula: a trendy, Festival in Austin, Texas, explaining Video Three preteen victims and a po- sense of paranoia but trigger pain- well-known novel, big name talent that “Camille needed to be ex- releases n recent years, we’ve seen a real tential serial killer on the loose is a ful recollections of her sister Mari- and a celebrated auteur/director in plored over eight episodes. -

Documentary Movies
Libraries DOCUMENTARY MOVIES The Media and Reserve Library, located in the lower level of the west wing, has over 9,000 videotapes, DVDs and audiobooks covering a multitude of subjects. For more information on these titles, consult the Libraries' online catalog. 10 Days that Unexpectedly Changed America DVD-2043 56 Up DVD-8322 180 DVD-3999 60's DVD-0410 1-800-India: Importing a White-Collar Economy DVD-3263 7 Up/7 Plus Seven DVD-1056 1930s (Discs 1-3) DVD-5348 Discs 1 70 Acres in Chicago: Cabrini Green DVD-8778 1930s (Discs 4-5) DVD-5348 Discs 4 70 Acres in Chicago: Cabrini Green c.2 DVD-8778 c.2 1964 DVD-7724 9/11 c.2 DVD-0056 c.2 1968 with Tom Brokaw DVD-5235 9500 Liberty DVD-8572 1983 Riegelman's Closing/2008 Update DVD-7715 Abandoned: The Betrayal of America's Immigrants DVD-5835 20 Years Old in the Middle East DVD-6111 Abolitionists DVD-7362 DVD-4941 Aboriginal Architecture: Living Architecture DVD-3261 21 Up DVD-1061 Abraham and Mary Lincoln: A House Divided DVD-0001 21 Up South Africa DVD-3691 Absent from the Academy DVD-8351 24 City DVD-9072 Absolutely Positive DVD-8796 24 Hours 24 Million Meals: Feeding New York DVD-8157 Absolutely Positive c.2 DVD-8796 c.2 28 Up DVD-1066 Accidental Hero: Room 408 DVD-5980 3 Times Divorced DVD-5100 Act of Killing DVD-4434 30 Days Season 3 DVD-3708 Addicted to Plastic DVD-8168 35 Up DVD-1072 Addiction DVD-2884 4 Little Girls DVD-0051 Address DVD-8002 42 Up DVD-1079 Adonis Factor DVD-2607 49 Up DVD-1913 Adventure of English DVD-5957 500 Nations DVD-0778 Advertising and the End of the World DVD-1460 -
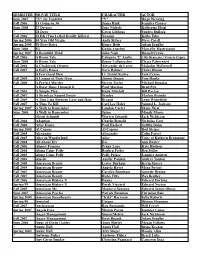
SEMESTER MOVIE TITLE CHARACTER ACTOR Sum 2007 "V
SEMESTER MOVIE TITLE CHARACTER ACTOR Sum 2007 "V" for Vendetta "V" Hugo Weaving Fall 2006 13 Going on 30 Jenna Rink Jennifer Garner Sum 2008 27 Dresses Jane Nichols Katherine Heigl ? 28 Days Gwen Gibbons Sandra Bullock Fall 2006 2LDK (Two Lethal Deadly Killers) Nozomi Koike Eiko Spring 2006 40 Year Old Virgin Andy Stitzer Steve Carell Spring 2005 50 First Dates Henry Roth Adam Sandler Sum 2008 8½ Guido Anselmi Marcello Mastroianni Spring 2007 A Beautiful Mind John Nash Russell Crowe Fall 2006 A Bronx Tale Calogero 'C' Anello Lillo Brancato / Francis Capra Sum 2008 A Bronx Tale Sonny LoSpeecchio Chazz Palmenteri Fall 2006 A Clockwork Orange Alexander de Large Malcolm McDowell Fall 2007 A Doll's House Nora Helmer Claire Bloom ? A Few Good Men Lt. Daniel Kaffee Tom Cruise Fall 2005 A League of Their Own Jimmy Dugan Tom Hanks Fall 2000 A Perfect Murder Steven Taylor Michael Douglas ? A River Runs Through It Paul Maclean Brad Pitt Fall 2005 A Simple Plan Hank Mitchell Bill Paxton Fall 2007 A Streetcar Named Desire Stanley Marlon Brando Fall 2005 A Thin Line Between Love and Hate Brandi Lynn Whitefield Fall 2007 A Time To Kill Carl Lee Haley Samuel L. Jackson Spring 2007 A Walk to Remember Landon Carter Shane West Sum 2008 A Walk to Remember Jaime Mandy Moore ? About Schmidt Warren Schmidt Jack Nickleson Fall 2004 Adaption Charlie/Donald Nicholas Cage Fall 2000 After Hours Paul Hackett Griffin Dunn Spring 2005 Al Capone Al Capone Rod Steiger Fall 2005 Alexander Alexander Colin Farrel Fall 2005 Alice in Wonderland Alice Voice of Kathryn Beaumont -

Pop Culture and Pedagogy: Taking up School Documentaries in Teacher Education
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Carolina Digital Repository POP CULTURE AND PEDAGOGY: TAKING UP SCHOOL DOCUMENTARIES IN TEACHER EDUCATION Reid L. Adams A dissertation submitted to the faculty of the University of North Carolina at Chapel Hill in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the School of Education. Chapel Hill 2011 Approved by: James Trier, Ph.D. Cheryl Mason Bolick, Ph.D. Heather Coffey, Ph.D. Deborah Eaker-Rich, Ph.D. George Noblit, Ph.D. © 2011 Reid L. Adams ALL RIGHTS RESERVED ii ABSTRACT Reid L. Adams: Pop Culture and Pedagogy: Taking Up School Documentaries in Teacher Education (Under the direction of James Trier) In the forward to Reading Television , Fiske and Hartley (2003) write that television programs ”constitute a gigantic empirical archive of human sense-making, there for the taking, twenty-four/seven” (p.xviii). In addition, this “gigantic empirical archive” also includes fiction films, video games, documentary films, commercials, news media, radio, Internet, and many other forms of mass-produced visual media found in popular culture. In this dissertation I explore a particular piece of this contemporary archive. I suggest pedagogical projects based on a cultural studies analysis of “school docs,” a particular genre of documentary films that I have defined and catalogued. This genre includes such documentary films as: Hoop Dreams (1994) , Mad Hot Ballroom (2004), OT: Our Town (2002) , Stupid in America (2006), Waiting for Superman (2010), and The War on Kids (2009). The pedagogical projects that I conceptualize are intended to explore issues and topics relevant to teacher education coursework; specifically issues and topics associated with the teaching of Social Foundations of Education.