A High-Throughput in Silico Pipeline for Revealing Novel Protein-Protein Interactions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Phylogenetic Analysis of the Haemagglutinin Gene of Canine
Guo et al. Virology Journal 2013, 10:109 http://www.virologyj.com/content/10/1/109 RESEARCH Open Access Phylogenetic analysis of the haemagglutinin gene of canine distemper virus strains detected from giant panda and raccoon dogs in China Ling Guo1, Shao-lin Yang1, Cheng-dong Wang2, Rong Hou3, Shi-jie Chen4, Xiao-nong Yang5, Jie Liu1, Hai-bo Pan1, Zhong-xiang Hao1, Man-li Zhang1, San-jie Cao1 and Qi-gui Yan1,6* Abstract Background: Canine distemper virus (CDV) infects a variety of carnivores, including wild and domestic Canidae. In this study, we sequenced and phylogenetic analyses of the hemagglutinin (H) genes from eight canine distemper virus (CDV) isolates obtained from seven raccoon dogs (Nyctereutes procyonoides) and a giant panda (Ailuropoda melanoleuca) in China. Results: Phylogenetic analysis of the partial hemagglutinin gene sequences showed close clustering for geographic lineages, clearly distinct from vaccine strains and other wild-type foreign CDV strains, all the CDV strains were characterized as Asia-1 genotype and were highly similar to each other (91.5-99.8% nt and 94.4-99.8% aa). The giant panda and raccoon dogs all were 549Y on the HA protein in this study, irrespective of the host species. Conclusions: These findings enhance our knowledge of the genetic characteristics of Chinese CDV isolates, and may facilitate the development of effective strategies for monitoring and controlling CDV for wild canids and non-cainds in China. Keywords: Canine distemper virus, Haemagglutinin (H) gene, Genotype, Phylogenetic analysis Background of specialist traits and increased expression of generalist CD is caused by the canine distemper virus (CDV) which traits, thereby confirming its functional importance [10]. -

CDV3 (NM 001134422) Human Tagged ORF Clone Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RG225254 CDV3 (NM_001134422) Human Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: CDV3 (NM_001134422) Human Tagged ORF Clone Tag: TurboGFP Symbol: CDV3 Synonyms: H41 Vector: pCMV6-AC-GFP (PS100010) E. coli Selection: Ampicillin (100 ug/mL) Cell Selection: Neomycin ORF Nucleotide >RG225254 representing NM_001134422 Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGCTGAGACGGAGGAGCGGAGCCTGGACAACTTCTTTGCCAAGAGGGACAAGAAGAAGAAGAAGGAGC GGAGCAACCGGGCGGCGAGTGCCGCGGGCGCAGCGGGCAGCGCCGGCGGAAGCAGTGGAGCCGCGGGTGC GGCGGGCGGCGGGGCGGGCGCGGGGACCCGGCCGGGTGACGGCGGGACCGCCAGCGCGGGGGCTGCGGGC CCAGGGGCCGCCACCAAGGCTGTGACGAAGGACGAAGATGAATGGAAAGAATTGGAGCAAAAAGAGGTTG ATTACAGCGGCCTCAGGGTTCAGGCAATGCAAATAAGCAGTGAAAAGGAAGAAGACGATAATGAAAAGAG ACAAGATCCAGGTGATAACTGGGAAGAAGGTGGAGGTGGTGGTGGAGGTATGGAAAAATCTTCAGGTCCC TGGAATAAAACAGCTCCAGTACAAGCACCTCCTGCTCCAGTAATTGTTACAGAAACCCCAGAACCAGCGA TGACTAGTGGTGTGTATAGGCCTCCTGGGGCCAGGTTAACCACAACAAGGAAAACACCACAAGGACCACC AGAAATCTACAGTGATACACAGTTCCCATCCCTGCAGTCAACTGCCAAGCATGTAGAAAGCCGGAACAGG TACTTAAAA ACGCGTACGCGGCCGCTCGAG - GFP Tag - GTTTAA Protein Sequence: >RG225254 representing NM_001134422 Red=Cloning site Green=Tags(s) MAETEERSLDNFFAKRDKKKKKERSNRAASAAGAAGSAGGSSGAAGAAGGGAGAGTRPGDGGTASAGAAG PGAATKAVTKDEDEWKELEQKEVDYSGLRVQAMQISSEKEEDDNEKRQDPGDNWEEGGGGGGGMEKSSGP -

WO 2012/174282 A2 20 December 2012 (20.12.2012) P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2012/174282 A2 20 December 2012 (20.12.2012) P O P C T (51) International Patent Classification: David [US/US]; 13539 N . 95th Way, Scottsdale, AZ C12Q 1/68 (2006.01) 85260 (US). (21) International Application Number: (74) Agent: AKHAVAN, Ramin; Caris Science, Inc., 6655 N . PCT/US20 12/0425 19 Macarthur Blvd., Irving, TX 75039 (US). (22) International Filing Date: (81) Designated States (unless otherwise indicated, for every 14 June 2012 (14.06.2012) kind of national protection available): AE, AG, AL, AM, AO, AT, AU, AZ, BA, BB, BG, BH, BR, BW, BY, BZ, English (25) Filing Language: CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, DO, Publication Language: English DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KM, KN, KP, KR, (30) Priority Data: KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, ME, 61/497,895 16 June 201 1 (16.06.201 1) US MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, 61/499,138 20 June 201 1 (20.06.201 1) US OM, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SC, SD, 61/501,680 27 June 201 1 (27.06.201 1) u s SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, TR, 61/506,019 8 July 201 1(08.07.201 1) u s TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. -

Gene Expression Analysis of Mevalonate Kinase Deficiency
International Journal of Environmental Research and Public Health Article Gene Expression Analysis of Mevalonate Kinase Deficiency Affected Children Identifies Molecular Signatures Related to Hematopoiesis Simona Pisanti * , Marianna Citro , Mario Abate , Mariella Caputo and Rosanna Martinelli * Department of Medicine, Surgery and Dentistry ‘Scuola Medica Salernitana’, University of Salerno, Via Salvatore Allende, 84081 Baronissi (SA), Italy; [email protected] (M.C.); [email protected] (M.A.); [email protected] (M.C.) * Correspondence: [email protected] (S.P.); [email protected] (R.M.) Abstract: Mevalonate kinase deficiency (MKD) is a rare autoinflammatory genetic disorder charac- terized by recurrent fever attacks and systemic inflammation with potentially severe complications. Although it is recognized that the lack of protein prenylation consequent to mevalonate pathway blockade drives IL1β hypersecretion, and hence autoinflammation, MKD pathogenesis and the molecular mechanisms underlaying most of its clinical manifestations are still largely unknown. In this study, we performed a comprehensive bioinformatic analysis of a microarray dataset of MKD patients, using gene ontology and Ingenuity Pathway Analysis (IPA) tools, in order to identify the most significant differentially expressed genes and infer their predicted relationships into biological processes, pathways, and networks. We found that hematopoiesis linked biological functions and pathways are predominant in the gene ontology of differentially expressed genes in MKD, in line with the observed clinical feature of anemia. We also provided novel information about the molecular Citation: Pisanti, S.; Citro, M.; Abate, M.; Caputo, M.; Martinelli, R. mechanisms at the basis of the hematological abnormalities observed, that are linked to the chronic Gene Expression Analysis of inflammation and to defective prenylation. -

Homologous Recombination Is a Force in the Evolution of Canine Distemper Virus
RESEARCH ARTICLE Homologous recombination is a force in the evolution of canine distemper virus Chaowen Yuan1, Wenxin Liu2, Yingbo Wang1, Jinlong Hou1, Liguo Zhang3, Guoqing Wang1* 1 College of life and health sciences, Northeastern University, Shenyang, Liaoning, China, 2 Laboratory of Hematology, Affiliated hospital of Guangdong Medical College, Zhanjiang, Guangzhou, China, 3 Center for Animal Disease Emergency of Liaoning province, Shenyang, Liaoning, China * [email protected] a1111111111 a1111111111 Abstract a1111111111 a1111111111 Canine distemper virus (CDV) is the causative agent of canine distemper (CD) that is a a1111111111 highly contagious, lethal, multisystemic viral disease of receptive carnivores. The preva- lence of CDV is a major concern in susceptible animals. Presently, it is unclear whether intragenic recombination can contribute to gene mutations and segment reassortment in the virus. In this study, 25 full-length CDV genome sequences were subjected to phylogenetic OPEN ACCESS and recombinational analyses. The results of phylogenetic analysis, intragenic recombina- Citation: Yuan C, Liu W, Wang Y, Hou J, Zhang L, tion, and nucleotide selection pressure indicated that mutation and recombination occurred Wang G (2017) Homologous recombination is a in the six individual genes segment (H, F, P, N, L, M) of the CDV genome. The analysis also force in the evolution of canine distemper virus. revealed pronounced genetic diversity in the CDV genome according to the geographically PLoS ONE 12(4): e0175416. https://doi.org/ 10.1371/journal.pone.0175416 distinct lineages (genotypes), namely Asia-1, Asia-2, Asia-3, Europe, America-1, and Amer- ica-2. The six recombination events were detected using SimPlot and RDP programs. -

Duke University Dissertation Template
Gene-Environment Interactions in Cardiovascular Disease by Cavin Keith Ward-Caviness Graduate Program in Computational Biology and Bioinformatics Duke University Date:_______________________ Approved: ___________________________ Elizabeth R. Hauser, Supervisor ___________________________ William E. Kraus ___________________________ Sayan Mukherjee ___________________________ H. Frederik Nijhout Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate Program in Computational Biology and Bioinformatics in the Graduate School of Duke University 2014 i v ABSTRACT Gene-Environment Interactions in Cardiovascular Disease by Cavin Keith Ward-Caviness Graduate Program in Computational Biology and Bioinformatics Duke University Date:_______________________ Approved: ___________________________ Elizabeth R. Hauser, Supervisor ___________________________ William E. Kraus ___________________________ Sayan Mukherjee ___________________________ H. Frederik Nijhout An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate Program in Computational Biology and Bioinformatics in the Graduate School of Duke University 2014 Copyright by Cavin Keith Ward-Caviness 2014 Abstract In this manuscript I seek to demonstrate the importance of gene-environment interactions in cardiovascular disease. This manuscript contains five studies each of which contributes to our understanding of the joint impact of genetic variation -

UC San Diego Electronic Theses and Dissertations
UC San Diego UC San Diego Electronic Theses and Dissertations Title Cardiac Stretch-Induced Transcriptomic Changes are Axis-Dependent Permalink https://escholarship.org/uc/item/7m04f0b0 Author Buchholz, Kyle Stephen Publication Date 2016 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, SAN DIEGO Cardiac Stretch-Induced Transcriptomic Changes are Axis-Dependent A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Bioengineering by Kyle Stephen Buchholz Committee in Charge: Professor Jeffrey Omens, Chair Professor Andrew McCulloch, Co-Chair Professor Ju Chen Professor Karen Christman Professor Robert Ross Professor Alexander Zambon 2016 Copyright Kyle Stephen Buchholz, 2016 All rights reserved Signature Page The Dissertation of Kyle Stephen Buchholz is approved and it is acceptable in quality and form for publication on microfilm and electronically: Co-Chair Chair University of California, San Diego 2016 iii Dedication To my beautiful wife, Rhia. iv Table of Contents Signature Page ................................................................................................................... iii Dedication .......................................................................................................................... iv Table of Contents ................................................................................................................ v List of Figures ................................................................................................................... -

Genome-Wide Profiling of P53-Regulated Enhancer Rnas
ARTICLE Received 29 Aug 2014 | Accepted 4 Feb 2015 | Published 27 Mar 2015 DOI: 10.1038/ncomms7520 OPEN Genome-wide profiling of p53-regulated enhancer RNAs uncovers a subset of enhancers controlled by a lncRNA Nicolas Le´veille´1,*, Carlos A. Melo1,2,*, Koos Rooijers1,*, Angel Dı´az-Lagares3, Sonia A. Melo4, Gozde Korkmaz1, Rui Lopes1, Farhad Akbari Moqadam5, Ana R. Maia6, Patrick J. Wijchers7, Geert Geeven7, Monique L. den Boer5, Raghu Kalluri4, Wouter de Laat7, Manel Esteller3,8,9 & Reuven Agami1,10 p53 binds enhancers to regulate key target genes. Here, we globally mapped p53-regulated enhancers by looking at enhancer RNA (eRNA) production. Intriguingly, while many p53- induced enhancers contained p53-binding sites, most did not. As long non-coding RNAs (lncRNAs) are prominent regulators of chromatin dynamics, we hypothesized that p53- induced lncRNAs contribute to the activation of enhancers by p53. Among p53-induced lncRNAs, we identified LED and demonstrate that its suppression attenuates p53 function. Chromatin-binding and eRNA expression analyses show that LED associates with and acti- vates strong enhancers. One prominent target of LED was located at an enhancer region within CDKN1A gene, a potent p53-responsive cell cycle inhibitor. LED knockdown reduces CDKN1A enhancer induction and activity, and cell cycle arrest following p53 activation. Finally, promoter-associated hypermethylation analysis shows silencing of LED in human tumours. Thus, our study identifies a new layer of complexity in the p53 pathway and suggests its dysregulation in cancer. 1 Division of Biological Stress Response, The Netherlands Cancer Institute, Plesmanlaan 121, 1066 CX Amsterdam, The Netherlands. 2 Doctoral Programme in Biomedicine and Experimental Biology, Centre for Neuroscience and Cell Biology, Coimbra University, 3004-504 Coimbra, Portugal. -
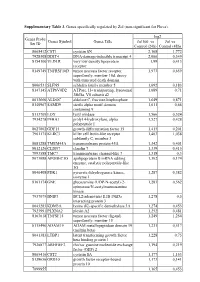
Supplementary Table 3. Genes Specifically Regulated by Zol (Non-Significant for Fluva)
Supplementary Table 3. Genes specifically regulated by Zol (non-significant for Fluva). log2 Genes Probe Genes Symbol Genes Title Zol100 vs Zol vs Set ID Control (24h) Control (48h) 8065412 CST1 cystatin SN 2,168 1,772 7928308 DDIT4 DNA-damage-inducible transcript 4 2,066 0,349 8154100 VLDLR very low density lipoprotein 1,99 0,413 receptor 8149749 TNFRSF10D tumor necrosis factor receptor 1,973 0,659 superfamily, member 10d, decoy with truncated death domain 8006531 SLFN5 schlafen family member 5 1,692 0,183 8147145 ATP6V0D2 ATPase, H+ transporting, lysosomal 1,689 0,71 38kDa, V0 subunit d2 8013660 ALDOC aldolase C, fructose-bisphosphate 1,649 0,871 8140967 SAMD9 sterile alpha motif domain 1,611 0,66 containing 9 8113709 LOX lysyl oxidase 1,566 0,524 7934278 P4HA1 prolyl 4-hydroxylase, alpha 1,527 0,428 polypeptide I 8027002 GDF15 growth differentiation factor 15 1,415 0,201 7961175 KLRC3 killer cell lectin-like receptor 1,403 1,038 subfamily C, member 3 8081288 TMEM45A transmembrane protein 45A 1,342 0,401 8012126 CLDN7 claudin 7 1,339 0,415 7993588 TMC7 transmembrane channel-like 7 1,318 0,3 8073088 APOBEC3G apolipoprotein B mRNA editing 1,302 0,174 enzyme, catalytic polypeptide-like 3G 8046408 PDK1 pyruvate dehydrogenase kinase, 1,287 0,382 isozyme 1 8161174 GNE glucosamine (UDP-N-acetyl)-2- 1,283 0,562 epimerase/N-acetylmannosamine kinase 7937079 BNIP3 BCL2/adenovirus E1B 19kDa 1,278 0,5 interacting protein 3 8043283 KDM3A lysine (K)-specific demethylase 3A 1,274 0,453 7923991 PLXNA2 plexin A2 1,252 0,481 8163618 TNFSF15 tumor necrosis -

Structural Determinants and Their Role in Cyanobacterial Morphogenesis
life Review Structural Determinants and Their Role in Cyanobacterial Morphogenesis Benjamin L. Springstein 1,* , Dennis J. Nürnberg 2 , Gregor L. Weiss 3 , Martin Pilhofer 3 and Karina Stucken 4 1 Department of Microbiology, Blavatnik Institute, Harvard Medical School, Boston, MA 02115, USA 2 Department of Physics, Biophysics and Biochemistry of Photosynthetic Organisms, Freie Universität Berlin, 14195 Berlin, Germany; [email protected] 3 Department of Biology, Institute of Molecular Biology & Biophysics, ETH Zürich, 8092 Zürich, Switzerland; [email protected] (G.L.W.); [email protected] (M.P.) 4 Department of Food Engineering, Universidad de La Serena, La Serena 1720010, Chile; [email protected] * Correspondence: [email protected] Received: 2 November 2020; Accepted: 9 December 2020; Published: 17 December 2020 Abstract: Cells have to erect and sustain an organized and dynamically adaptable structure for an efficient mode of operation that allows drastic morphological changes during cell growth and cell division. These manifold tasks are complied by the so-called cytoskeleton and its associated proteins. In bacteria, FtsZ and MreB, the bacterial homologs to tubulin and actin, respectively, as well as coiled-coil-rich proteins of intermediate filament (IF)-like function to fulfil these tasks. Despite generally being characterized as Gram-negative, cyanobacteria have a remarkably thick peptidoglycan layer and possess Gram-positive-specific cell division proteins such as SepF and DivIVA-like proteins, besides Gram-negative and cyanobacterial-specific cell division proteins like MinE, SepI, ZipN (Ftn2) and ZipS (Ftn6). The diversity of cellular morphologies and cell growth strategies in cyanobacteria could therefore be the result of additional unidentified structural determinants such as cytoskeletal proteins. -

Table S1. 103 Ferroptosis-Related Genes Retrieved from the Genecards
Table S1. 103 ferroptosis-related genes retrieved from the GeneCards. Gene Symbol Description Category GPX4 Glutathione Peroxidase 4 Protein Coding AIFM2 Apoptosis Inducing Factor Mitochondria Associated 2 Protein Coding TP53 Tumor Protein P53 Protein Coding ACSL4 Acyl-CoA Synthetase Long Chain Family Member 4 Protein Coding SLC7A11 Solute Carrier Family 7 Member 11 Protein Coding VDAC2 Voltage Dependent Anion Channel 2 Protein Coding VDAC3 Voltage Dependent Anion Channel 3 Protein Coding ATG5 Autophagy Related 5 Protein Coding ATG7 Autophagy Related 7 Protein Coding NCOA4 Nuclear Receptor Coactivator 4 Protein Coding HMOX1 Heme Oxygenase 1 Protein Coding SLC3A2 Solute Carrier Family 3 Member 2 Protein Coding ALOX15 Arachidonate 15-Lipoxygenase Protein Coding BECN1 Beclin 1 Protein Coding PRKAA1 Protein Kinase AMP-Activated Catalytic Subunit Alpha 1 Protein Coding SAT1 Spermidine/Spermine N1-Acetyltransferase 1 Protein Coding NF2 Neurofibromin 2 Protein Coding YAP1 Yes1 Associated Transcriptional Regulator Protein Coding FTH1 Ferritin Heavy Chain 1 Protein Coding TF Transferrin Protein Coding TFRC Transferrin Receptor Protein Coding FTL Ferritin Light Chain Protein Coding CYBB Cytochrome B-245 Beta Chain Protein Coding GSS Glutathione Synthetase Protein Coding CP Ceruloplasmin Protein Coding PRNP Prion Protein Protein Coding SLC11A2 Solute Carrier Family 11 Member 2 Protein Coding SLC40A1 Solute Carrier Family 40 Member 1 Protein Coding STEAP3 STEAP3 Metalloreductase Protein Coding ACSL1 Acyl-CoA Synthetase Long Chain Family Member 1 Protein -

A Novel Neural Response Algorithm for Protein
Yalamanchili et al. BMC Systems Biology 2012, 6(Suppl 1):S19 http://www.biomedcentral.com/1752-0509/6/S1/S19 RESEARCH Open Access A novel neural response algorithm for protein function prediction Hari Krishna Yalamanchili1,2, Quan-Wu Xiao3, Junwen Wang1,2,4* From The 5th IEEE International Conference on Computational Systems Biology (ISB 2011) Zhuhai, China. 02-04 September 2011 Abstract Background: Large amounts of data are being generated by high-throughput genome sequencing methods. But the rate of the experimental functional characterization falls far behind. To fill the gap between the number of sequences and their annotations, fast and accurate automated annotation methods are required. Many methods, such as GOblet, GOFigure, and Gotcha, are designed based on the BLAST search. Unfortunately, the sequence coverage of these methods is low as they cannot detect the remote homologues. Adding to this, the lack of annotation specificity advocates the need to improve automated protein function prediction. Results: We designed a novel automated protein functional assignment method based on the neural response algorithm, which simulates the neuronal behavior of the visual cortex in the human brain. Firstly, we predict the most similar target protein for a given query protein and thereby assign its GO term to the query sequence. When assessed on test set, our method ranked the actual leaf GO term among the top 5 probable GO terms with accuracy of 86.93%. Conclusions: The proposed algorithm is the first instance of neural response algorithm being used in the biological domain. The use of HMM profiles along with the secondary structure information to define the neural response gives our method an edge over other available methods on annotation accuracy.