Arxiv:1804.07781V3 [Cs.CL] 28 Aug 2018 Regular Examples
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nomadic Incursion MMW 13, Lecture 3
MMW 13, Lecture 3 Nomadic Incursion HOW and Why? The largest Empire before the British Empire What we talked about in last lecture 1) No pure originals 2) History is interrelated 3) Before Westernization (16th century) was southernization 4) Global integration happened because of human interaction: commerce, religion and war. Known by many names “Ruthless” “Bloodthirsty” “madman” “brilliant politician” “destroyer of civilizations” “The great conqueror” “Genghis Khan” Ruling through the saddle Helped the Eurasian Integration Euroasia in Fragments Afro-Eurasia Afro-Eurasian complex as interrelational societies Cultures circulated and accumulated in complex ways, but always interconnected. Contact Zones 1. Eurasia: (Hemispheric integration) a) Mediterranean-Mesopotamia b) Subcontinent 2) Euro-Africa a) Africa-Mesopotamia 3) By the late 15th century Transatlantic (Globalization) Africa-Americas 12th century Song and Jin dynasties Abbasids: fragmented: Fatimads in Egypt are overtaken by the Ayyubid dynasty (Saladin) Africa: North Africa and Sub-Saharan Africa Europe: in the periphery; Roman catholic is highly bureaucratic and society feudal How did these zones become connected? Nomadic incursions Xiongunu Huns (Romans) White Huns (Gupta state in India) Avars Slavs Bulgars Alans Uighur Turks ------------------------------------------------------- In Antiquity, nomads were known for: 1. War 2. Migration Who are the Nomads? Tribal clan-based people--at times formed into confederate forces-- organized based on pastoral or agricultural economies. 1) Migrate so to adapt to the ecological and changing climate conditions. 2) Highly competitive on a tribal basis. 3) Religion: Shamanistic & spirit-possession Two Types of Nomadic peoples 1. Pastoral: lifestyle revolves around living off the meat, milk and hides of animals that are domesticated as they travel through arid lands. -

Mongolian Interest in Architecture and Construction in China (7Th C
REVIEW OF INTERNATIONAL GEOGRAPHICAL EDUCATION ISSN: 2146-0353 ● © RIGEO ● 11(4), WINTER, 2021 www.rigeo.org Research Article Mongolian Interest in Architecture and Construction in China (7th C. AH/ 13th C. AD) Prof. Dr. Suaad Hadi Hassan Al-Taai Department of History, College of Education ibn Rushd for Humanities, University of Baghdad, Baghdad, Iraq [email protected] Abstract The Mongols were interested in architecture and construction, whether in Mongolia or China, especially after they mixed with civilized peoples. They merged with them and were affected by their civilization and their arts, and they borrowed a lot from them, especially in the field of construction and architecture. After establishing his rule in China, Kublai (658-693 A.H., 1260-1294 A.D.) was keen on building a new capital for him, which he called Dadu, to replace his previous capital, Khanbaliq. After consulting with the wise men of his palace and astrologers, Kublai was interested in building luxurious palaces for himself and his family, and he used a large number of engineers and craftsmen to build them to be a model for contemporary cities and compete with them in architecture and luxury. Kublai gave several priorities to build his capital by providing it with large funds to provide all service institutions its residents need. He split rivers, built canals, reclaimed and cultivated lands, built roads, Keywords Kublai, Engineers, Walls, Rivers, The Capital, Princesses. To cite this article: Al-Taai, Prof.Dr, S, H, H.; (2021) Mongolian Interest in Architecture and Construction in China (7th C. AH/ 13th C. -

From Kashgar to Xanadu in the Travels of Marco Polo Amelia Carolina Sparavigna
From Kashgar to Xanadu in the Travels of Marco Polo Amelia Carolina Sparavigna To cite this version: Amelia Carolina Sparavigna. From Kashgar to Xanadu in the Travels of Marco Polo. 2020. hal- 02563026 HAL Id: hal-02563026 https://hal.archives-ouvertes.fr/hal-02563026 Preprint submitted on 5 May 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. From Kashgar to Xanadu in the Travels of Marco Polo Amelia Carolina Sparavigna Politecnico di Torino Uploaded 21 April 2020 on Zenodo DOI: 10.5281/zenodo.3759380 Abstract: In two previous papers (Philica, 2017, Articles 1097 and 1100), we investigated the travels of Marco Polo, using Google Earth and Wikimapia. We reconstructed the Polo’s travel from Beijing to Xanadu and from Sheberghan to Kashgar. Here we continue the analysis of this travel from today Kashgar to Xanadu. Keywords: Satellite Images, Google Earth, Wikimapia, Marco Polo, Taklamakan, Southwest Xinjiang, Lop Desert, Xanadu, Marco Polo, China. The Travels of Marco Polo is a 13th-century book writen by Rustchello da Pisa, reportng the stories told by Marco to Rustchello while they were in prison together in Genoa. This book is describing the several travels through Asia of Polo and the period that he spent at the court of Kublai Khan [1]. -
Chapter 4: China in the Middle Ages
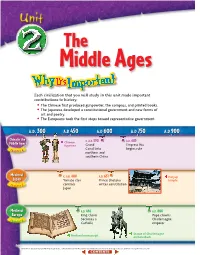
The Middle Ages Each civilization that you will study in this unit made important contributions to history. • The Chinese first produced gunpowder, the compass, and printed books. • The Japanese developed a constitutional government and new forms of art and poetry. • The Europeans took the first steps toward representative government. A..D.. 300300 A..D 450 A..D 600 A..D 750 A..DD 900 China in the c. A.D. 590 A.D.683 Middle Ages Chinese Middle Ages figurines Grand Empress Wu Canal links begins rule Ch 4 apter northern and southern China Medieval c. A.D. 400 A.D.631 Horyuji JapanJapan Yamato clan Prince Shotoku temple Chapter 5 controls writes constitution Japan Medieval A.D. 496 A.D. 800 Europe King Clovis Pope crowns becomes a Charlemagne Ch 6 apter Catholic emperor Statue of Charlemagne Medieval manuscript on horseback 244 (tl)The British Museum/Topham-HIP/The Image Works, (c)Angelo Hornak/CORBIS, (bl)Ronald Sheridan/Ancient Art & Architecture Collection, (br)Erich Lessing/Art Resource, NY 0 60E 120E 180E tecture Collection, (bl)Ron tecture Chapter Chapter 6 Chapter 60N 6 4 5 0 1,000 mi. 0 1,000 km Mercator projection EUROPE Caspian Sea ASIA Black Sea e H T g N i an g Hu JAPAN r i Eu s Ind p R Persian u h . s CHINA r R WE a t Gulf . e PACIFIC s ng R ha Jiang . C OCEAN S le i South N Arabian Bay of China Red Sea Bengal Sea Sea EQUATOR 0 Chapter 4 ATLANTIC Chapter 5 OCEAN INDIAN Chapter 6 OCEAN Dahlquist/SuperStock, (br)akg-images (tl)Aldona Sabalis/Photo Researchers, (tc)National Museum of Taipei, (tr)Werner Forman/Art Resource, NY, (c)Ancient Art & Archi NY, Forman/Art Resource, (tr)Werner (tc)National Museum of Taipei, (tl)Aldona Sabalis/Photo Researchers, A..D 1050 A..D 1200 A..D 1350 A..D 1500 c. -

Cultural Industries in China and Their Importance in Asian Communities Prof. Qingben LI
Cultural Industries in China and Their Importance in Asian Communities Prof. Qingben LI April 3, 2017 Madrid Contents Part I: The China Model from the perspective of Cross- Cultural Studies Part II: Beijing’s Policies in Support of Cultural and Creative Industries Development Part III: Beijing as site of Cross-Cultural Exchanges between East and West Part I The China Model from the perspective of Cross-Cultural Studies The China Model from the perspective of Cross- Cultural Studies In recent years, many scholars are talking about the so- called “China Model” in order to understand the rapid development of Chinese economy and its economic and political reasons. One key concept is that of “meritocracy”, forged by American professor working in Tsinghua University Daniel A. Bell, to describe the ideas and the reality of how the Chinese political system has evolved over the past three decades. In his opinion, political meritocracy is referred to the idea that “political power should be distributed in accordance with ability and virtue.” This model differs from those election models on the basis of “one person, one vote,” used in the West. Different from the political perspective, I would like to talk about“China Model” from the comparative cultural studies today. The China Model from the perspective of Cross- Cultural Studies According to the Canadian cultural economists Harry Hillman Chartrand and Claire McCaughey, there are four models of cultural policy operative in the West after World War II. They are: ▲ the Facilitator Model ▲ the -

The Rise of Steppe Agriculture
The Rise of Steppe Agriculture The Social and Natural Environment Changes in Hetao (1840s-1940s) Inaugural-Dissertation zur Erlangung der Doktorwürde der Philosophischen Fakultät der Albert-Ludwigs-Universität Freiburg i. Br. vorgelegt von Yifu Wang aus Taiyuan, V. R. China WS 2017/18 Erstgutachterin: Prof. Dr. Sabine Dabringhaus Zweitgutachter: Prof. Dr. Dr. Franz-Josef Brüggemeier Vorsitzender des Promotionsausschusses der Gemeinsamen Kommission der Philologischen und der Philosophischen Fakultät: Prof. Dr. Joachim Grage Datum der Disputation: 01. 08. 2018 Table of Contents List of Figures 5 Acknowledgments 1 1. Prologue 3 1.1 Hetao and its modern environmental crisis 3 1.1.1 Geographical and historical context 4 1.1.2 Natural characteristics 6 1.1.3 Beacons of nature: Recent natural disasters in Hetao 11 1.2 Aims and current state of research 18 1.3 Sources and secondary materials 27 2. From Mongol to Manchu: the initial development of steppe agriculture (1300s-1700s) 32 2.1 The Mongolian steppe during the post-Mongol empire era (1300s-1500s) 33 2.1.1 Tuntian and steppe cities in the fourteenth century 33 2.1.2 The political impact on the steppe environment during the North-South confrontation 41 2.2 Manchu-Mongolia relations in the early seventeenth century 48 2.2.1 From a military alliance to an unequal relationship 48 2.2.2 A new management system for Mongolia 51 2.2.3 Divide in order to rule: religion and the Mongolian Policy 59 2.3 The natural environmental impact of the Qing Dynasty's Mongolian policy 65 2.3.1 Agricultural production 67 2.3.2 Wild animals 68 2.3.3 Wild plants of economic value 70 1 2.3.4 Mining 72 2.4 Summary 74 3. -
Mapping the Chinese and Islamic Worlds: Cross-Cultural Exchange in Pre-Modern Asia Hyunhee Park Index More Information
Cambridge University Press 978-1-107-01868-6 - Mapping the Chinese and Islamic Worlds: Cross-Cultural Exchange in Pre-modern Asia Hyunhee Park Index More information Index ʿAbbasids, ʿAbbasid caliphate, 7 archeological excavations breakup of, 90 in Aden, 30 conflicts with the Tang army in Central in Arikamedu, 30 Asia, 11, 24–25 in Banbhore, 30 Du You’s section about, 26 in Sıraf, 30, 66 fall of, 17, 96 in Suhar, 30 in Jia Dan’s Route, 32 of Zheng He shipyards in Nanjing, 171 updating their geographic knowledge, 12 Arigh Böke, 97 ʿAbd al-Razzaq al-Samarqandı, 183 atabeg, 95 Abū al-Fidaʾ, 147 ʿAtaMalik. See History of the World Abu-Lughod, Janet, 197 Conqueror Abū Zayd al-Sırafı, 52, 65–74, 77, 84, 86, Ayyubids, 52 87, 89 Abyssinian Sea. See Indian Ocean Baghdad, 21 Account of Foreign Countries in the Chinese craftsmen in, 68 Western Regions (Xiyu fanguo zhi). commercial connection of, to China, See Chen Cheng 57, 64 Account of the Palace Library (Mishujian fall of, 94, 126 zhi), 99, 103, 107 as the new ʿAbbasid capital, 27, 32 Accounts of China and India (Akhbar al-Balkhı, 73, 75 al-Sın wa-l-Hind), 63–72, 86, Balkhı School, 73, 75, 76, 77, 78, 80, 84, 155, 157 90, 129, 148 Achaemenids, 128 Ban Gu, legendary first emperor of China, Ahmad, Yuan minister, 99, 138 138 Alexander the Great Basra, 32, 61 wall of, 134 Battle of ʿAyn Jalūt, 19, 127 Alexandria, 53 Battle of Talas, 21, 25 Lighthouse of, 53, 106 Bayt al-Hikmah (House of Wisdom), 59 Allsen, Thomas, 98 Beijing. -

The Perceptions of Horses in Thirteenth- And
Zhexin Xu THE PERCEPTIONS OF HORSES IN THIRTEENTH- AND FOURTEENTH-CENTURY CHINA MA Thesis in Comparative History, with a specialization in Interdisciplinary Medieval Studies. Central European University Budapest May 2015 CEU eTD Collection THE PERCEPTIONS OF HORSES IN THIRTEENTH- AND FOURTEENTH- CENTURY CHINA by Zhexin Xu (China) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Comparative History, with a specialization in Interdisciplinary Medieval Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ Chair, Examination Committee ____________________________________________ Thesis Supervisor ____________________________________________ Examiner ____________________________________________ Examiner CEU eTD Collection Budapest June 2015 THE PERCEPTIONS OF HORSES IN THIRTEENTH- AND FOURTEENTH- CENTURY CHINA by Zhexin Xu (China) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Comparative History, with a specialization in Interdisciplinary Medieval Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ External Reader Budapest June 2015 CEU eTD Collection THE PERCEPTIONS OF HORSES IN THIRTEENTH- AND FOURTEENTH- CENTURY CHINA by Zhexin Xu (China) Thesis submitted to the Department of Medieval Studies, -

Guided Reading, Imperial China, Lesson 3
NAME DATE CLASS Guided Reading Imperial China Lesson 3 The Mongols in China ESSENTIAL QUESTION • What are the characteristics of a leader? Mongol Expansion Listing The first column below poses questions about the Mongols. For each question, list facts you learn from reading the lesson. The Mongols Facts Who were the Mongols and where did 1. they live? 2. How did the Mongols live? 3. Copyright © McGraw-Hill Education. Permission is granted to reproduce for classroom Education. is granted for to reproduce Permission use. Copyright © McGraw-Hill 4. 5. What were the Mongols’ greatest 6. skills? 7 8. Describing Complete the time line with details about Genghis Khan and the Mongol invaders. 1206: 1211: 1227: 1260: 9. Evaluating Were the Mongols good or bad rulers of the Chinese empire? Give examples to support your answer. NAME DATE CLASS Guided Reading Cont. Imperial China Mongol Conquest of China True or False Use your textbook to determine if each statement is true or false. Write T or F in the blank next to the statement. If the statement is false, rewrite the underlined portion to make it true. Mongol Conquest of China 10. In 1264, Kublai Khan, grandson of Genghis Khan, made the city of Khanbaliq the capital of the empire. 11. The newly established Yuan dynasty would rule for centuries. 12. The Mongols and the Chinese were culturally similar. They shared language, laws, and customs. Copyright © McGraw-Hill Education. Permission is granted to reproduce for classroom Education. is granted for to reproduce Permission use. Copyright © McGraw-Hill 13. The Yuan rulers set aside the civil service examination and allowed non-Chinese to work in government jobs. -

The Reception and Management of Gifts in the Imperial Court of the Mongol Great Khan, from the Early Thirteenth Century to 1368
Ya Ning The Reception and Management of Gifts in the Imperial Court of the Mongol Great Khan, from the early thirteenth century to 1368 MA Thesis in Late Antique, Medieval and Early Modern Studies Central European University Budapest May 2020 CEU eTD Collection The Reception and Management of Gifts in the Imperial Court of the Mongol Great Khan, from the early thirteenth century to 1368 by Ya Ning (China) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Late Antique, Medieval and Early Modern Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ Chair, Examination Committee ____________________________________________ Thesis Supervisor ____________________________________________ Examiner ____________________________________________ Examiner Budapest CEU eTD Collection May 2020 The Reception and Management of Gifts in the Imperial Court of the Mongol Great Khan, from the early thirteenth century to 1368 by Ya Ning (China) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Late Antique, Medieval and Early Modern Studies. Accepted in conformance with the standards of the CEU. ____________________________________________ External Reader Budapest CEU eTD Collection May 2020 The Reception and Management of Gifts in the Imperial Court of the Mongol Great Khan, from the early thirteenth century to 1368 by Ya Ning (China) Thesis submitted to the Department of Medieval Studies, Central European University, Budapest, in partial fulfillment of the requirements of the Master of Arts degree in Late Antique, Medieval and Early Modern Studies. -
Now You May Take My Word for It That Many Roads
Now you may take my word for it that many roads lead from this city of Khanbaliq through many provinces; or, rather, one road leads to one province while another leads to another. … The fact is that between one post and the next, at intervals of three miles, there are villages consisting of as many as forty houses occupied by unmounted couriers who also play a part in the emperor’s [Kublai Khan] postal service. I will tell you how. They wear large belts covered all round with bells, so that when they are on the move they can be heard a long way off. They always run at full tilt, and never for more than three miles. And the other couriers who are waiting three miles down the road clearly hear them while they are still some way off and stand at the ready. As soon as the first courier arrives, the second takes what he is carrying, along with a little ticket given to him by the clerk, and sets off to run the second leg of three miles, at the end of which the handover is repeated. And you can take my word for it that by means of these couriers the emperor gets news from places ten days’ journey away in a day and a night. For you should know that these runners cover the distance of a ten-day journey in a day and a night, and in two days and nights they bring news from places twenty days’ journey away; and so in ten days and nights the emperor would have news from places a hundred days’ journey away. -

Temüjin's Mongolia
prelims.094 02/02/2007 5:26 PM Page i MAKERS of the MUSLIM WORLD Chinggis Khan prelims.094 02/02/2007 5:26 PM Page iv CHINGGIS KHAN A Oneworld Book Published by Oneworld Publications 2007 Copyright © Michal Biran 2007 All rights reserved Copyright under Berne Convention ACIP record for this title is available from the British Library ISBN-10: 1–85168–502–2 ISBN-13: 978–1–85168–502–8 Typeset by Jayvee, Trivandrum, India Printed and bound by XXX Oneworld Publications 185 Banbury Road Oxford OX2 7AR England www.oneworld-publications.com NL08 Learn more about Oneworld. Join our mailing list to find out about our latest titles and special offers at: www.oneworld-publications.com/newsletter.htm prelims.094 02/02/2007 5:26 PM Page v CONTENTS List of Maps,Figures and Illustrations vii Acknowledgments ix INTRODUCTION:WHY CHINGGIS? 1 1: ASIA,THE STEPPE AND THE ISLAMIC WORLD ON THE EVE OF THE MONGOLS 6 2: TEMÜJIN’S MONGOLIA 27 3: WORLD CONQUEST: HOW DID HE DO IT? 47 4: THE CHINGGISID LEGACY IN THE MUSLIM WORLD 74 5: FROM THE ACCURSED TO THE REVERED FATHER AND BACK: CHANGING IMAGES OF CHINGGIS KHAN IN THE MUSLIM WORLD 108 6: APPROPRIATING CHINGGIS: A COMPARATIVE APPROACH 137 Selected Bibliography 163 Index 174 v prelims.094 02/02/2007 5:26 PM Page vii LIST OF MAPS, FIGURES AND ILLUSTRATIONS MAPS Map 1 The Mongol Empire by the Time of the Death of Chinggis Khan and in the Height of Its Expansion 4–5 Map 2 Asia before Chinggis Khan 24 Map 3 Chinggis Khan’s Campaigns of Conquest 48 Map 4 The Four Mongol Khanates ca.