Computational Methods to Vocalize Arabic Texts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CYP2D6 and CYP2C19 Genotyping in Psychiatry
CYP2D6 and CYP2C19 genotyping in psychiatry Citation for published version (APA): Koopmans, A. B. (2021). CYP2D6 and CYP2C19 genotyping in psychiatry: bridging the gap between practice and lab. ProefschriftMaken. https://doi.org/10.26481/dis.20210512ak Document status and date: Published: 01/01/2021 DOI: 10.26481/dis.20210512ak Document Version: Publisher's PDF, also known as Version of record Please check the document version of this publication: • A submitted manuscript is the version of the article upon submission and before peer-review. There can be important differences between the submitted version and the official published version of record. People interested in the research are advised to contact the author for the final version of the publication, or visit the DOI to the publisher's website. • The final author version and the galley proof are versions of the publication after peer review. • The final published version features the final layout of the paper including the volume, issue and page numbers. Link to publication General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal. -

GAF Timberline Series Application Instructions
Application Instructions Timberline® HDTM, Timberline® Natural ShadowTM, Timberline® Ultra HDTM, Timberline® Cool Series, Timberline® American HarvestTM, Updated: 4/12 Quality You Can Trust… From North America’s Largest Roofing Manufacturer!™ www.gaf.com Quality You Can Trust…From North America’s Largest Roofing Manufacturer!™ ¡Calidad En La Que Usted Puede Confiar...Del Fabricante De Techos Más Grande De Norteamérica!™ Une Qualité À Laquelle Vous Pouvez Vous Fier... Du Plus Gros Fabricant De Toitures En Amérique Du Nord! MC INSTALLATION INSTRUCTIONS · INSTRUCCIONES DE INSTALACIÓN · INSTRUCTIONS D’INSTALLATION LIFETIME HIGH DEFINITION® SHINGLES LIFETIME SHINGLES TEJAS DE ALTA DEFINICIÓN® DE POR VIDA TEJAS DE POR VIDA BARDEAUX DE HAUTE DÉFINITION® À VIE BARDEAUX À VIE LIFETIME HIGH DEFINITION® SHINGLES TEJAS DE ALTA DEFINICIÓN® DE POR VIDA ENERGY-SAVING ARCHITECTURAL SHINGLES TEJAS ARQUITECTÓNICAS PARA AHORRO DE ENERGÍA BARDEAUX DE HAUTE DÉFINITION® À VIE BARDEAUX ARCHITECTURAUX ÉCONERGÉTIQUES GENERAL INSTRUCTIONS t."5&3*"-4"'&5:%"5"4)&&54 When using GAF products, e.g., shingles, underlayments, plastic cement, etc., please refer to the applicable MSDS. The most current versions are available at www.gaf.com. GAF does not provide safety data sheets or installation instructions for products not manufactured by GAF. Please consult the material manufacturer for their MSDS and installation instructions where appropriate. t300'%&$,4Use minimum 3/8" (10mm) plywood or OSB decking as recommended by APA-The Engineered Wood Assn. Wood decks must be well-seasoned and supported having a maximum 1/8" (3mm) spacing, using minimum nominal 1"(25mm) thick lumber, a maximum 6" (152mm) width, having adequate nail-holding capacity and a smooth surface. -

Persian Ugs Kobo Audiobook.Pdf
LESSON NOTES Basic Bootcamp #1 Self Introductions - Basic Greetings in Persian CONTENTS 2 Persian 2 English 2 Romanization 2 Vocabulary 3 Sample Sentences 4 Vocabulary Phrase Usage 6 Grammar # 1 COPYRIGHT © 2013 INNOVATIVE LANGUAGE LEARNING. ALL RIGHTS RESERVED. PERSIAN . : .1 . : .2 . : .3 . : .4 ENGLISH 1. BEHZAD: Hello. I'm Behzad. What's your name? 2. MARY: Hello Behzad. My name is Mary. 3. BEHZAD: Nice to meet you. 4. MARY: You too. ROMANIZATION 1. BEHZAD: Salam, man Behzad am. Esme shoma chi e? 2. MARY: Salam Behzad, Esme man Mary e. 3. BEHZAD: Az ashnayi ba shoma khoshvaght am. 4. MARY: Man ham hamintor. VOCABULARY PERSIANPOD101.COM BASIC BOOTCAMP #1 - SELF INTRODUCTIONS - BASIC GREETINGS IN PERSIAN 2 Persian Romanization English Class Man ham hamintor. me too phrase Az ashnayi ba shoma khoshvaght Nice to meet you sentence am. ... Esme man (...) e. My name is (...). sentence Esme shoma chi e? What’s your name? sentence salaam hello interjection man I, me pronoun hastam (I) am verb esm name noun SAMPLE SENTENCES : . : . . . ali: man gorosne hastam. zahraa: man ham man faateme hastam. az aashnaayi baa shomaa hamin tor. khoshvaghtam. Ali: I'm hungry. Zahra: Me too. My name is Fateme. Nice to meet you. . esm-e man zeinabe. esm-e man naaser e. esm-e shomaa chie? My name is Zeinab. My name is Naser. What is your name? . . Oo hich vaght be man salaam nemikonad. Az man aks nagir. He never says hello to me. "Don't take photos of me." . Man ta hala chenin chizi nadidam. Kheili khaste hastam I have never seen such a thing. -
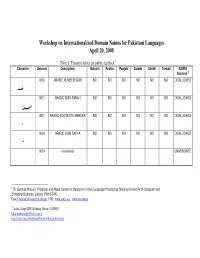
Workshop on Internationalized Domain Names for Pakistani Languages April 20, 2008
Workshop on Internationalized Domain Names for Pakistani Languages April 20, 2008 Table 1: Tentative tables for public feedback 1 Character Unicode Description Balochi Pashto Punjabi Saraiki Sindhi Torwali ASIWG Decision 2 0600 ARABIC NUMBER SIGN NO NO NO NO NO NO DISALLOWED 0601 ARABIC SIGN SANAH NO NO NO NO NO NO DISALLOWED 0601 ARABIC FOOTNOTE MARKER NO NO NO NO NO NO DISALLOWED 0603 ARABIC SIGN SAFHA NO NO NO NO NO NO DISALLOWED 0604 <reserved> UNASSIGNED 1 Dr. Sarmad Hussain, Professor and Head, Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, Lahore, PAKISTAN. Email: [email protected] , URL: www.crulp.org , www.nu.edu.pk 2 Arabic Script IDN Working Group (ASIWG) [email protected] http://lists.irnic.ir/mailman/listinfo/idna-arabicscript 0605 <reserved> UNASSIGNED 0606 ARABIC-INDIC CUBE ROOT NO NO NO NO NO NO DISALLOWED 0607 ARABIC-INDIC FOURTH NO NO NO NO NO NO DISALLOWED ROOT 0608 ARABIC RAY NO NO NO NO NO NO DISALLOWED 0609 ARABIC-INDIC PER MILLE NO NO NO NO NO NO DISALLOWED SIGN 060A ARABIC-INDIC PER TEN NO NO NO NO NO NO DISALLOWED THOUSAND SIGN 060B AFGHANI SIGN NO NO NO NO NO NO DISALLOWED 060C ARABIC COMMA NO NO NO NO NO NO DISALLOWED 060D ARABIC DATE SEPARATOR NO NO NO NO NO NO DISALLOWED ؍ 060E ARABIC POETIC VERSE SIGN NO NO NO NO NO NO DISALLOWED ؎ 060F ARABIC SIGN MISRA NO NO NO NO NO NO DISALLOWED ؏ 0610 ARABIC SIGN SALLALLAHOU PENDING PENDING PENDING PENDING PENDING PENDING PVALID ALAYHE WASSALLAM 0611 ARABIC SIGN ALAYHE PENDING PENDING -

20 May 2021 4° 5° 6° 7° 8° 9° 10° 11° 12° 13° 14° 15° 16° 17° 18° 19° 20° 21° 22° 23° 24°
ERC-03/L 20 May 2021 4° 5° 6° 7° 8° 9° 10° 11° 12° 13° 14° 15° 16° 17° 18° 19° 20° 21° 22° 23° 24° LFD54 M < A1 < M 0 G2 DIKEL VALMA LIP233 Z LIR22 LIP329 LIR50 A482 OKDI N14 T216 N141> T ANA > <Y < 6 8 YE L 1> 2 R 4 3 VE LFD < 4 LIP99 CRA TI < 4 E ED R1 9 R 5 > 5 A 1 K < 4 M L G U SO A2 T 5 L L TORLI 8 06 7 MA 7 L 4 2 A LIR3 7 M M P 4 ERIK 2 U ISIP ) W1 1 6 8 0 DIVK P AAL > 8 U 0 LF 1 2 1 M 0 LA ASB D 3 1 > > 3 L 1 5 7 L LIRL LIR N V 4A 4 8 3 9 3 7 7 LIR309A A 95 7 N K > LF 1 2 L 7 LIRRAET ERAV --------- 1 1 R19 LG 2 9 K P - 5 F 3 --- A N 2 9 7 A --- 3 G LIRRUS1 300 305 8 --- R 4 L AP 9 5 2 LIR LIR --- LA AR < 8 M 6 RUR M AM 4 < LID 9B B A D2 DOB M 13 H P 2 67 0 8 R30 T A L 1 Q LI L 9 F E A 2 D S 9 4 54C1 L J L IR300B L 2> 0 SK L A < 1 7 L 4 L 4 E TMA R3C F P 5 G 5 > 9 Z IP328 BCN1 6 A AAA LA K 2 3 1 L LIB 7 A O L M L L 1 1 L < 9 3 B > FM 5 9 9 G N 6 LFD54 LFD MAJ E L H IKO C2 1 9 580 LVIN 5 1 2 2 G O OD < 5 8 6 L W < 5 2 < L ) 1 1 7 > 0 6 0 10 1 R LS ( LGGG GR 1 LAT LIP2 5 6 3 LYBA FIR ( 8 N L LF Z LIP323 2A A T I 2 D 8 0 54C3 2 LIR3 L SA01 1 A 6 6 T 2 T N 1 <U 1 5 D 2 LW LW < HI 1 GR 7 M 9 302B 5 R S LWSS N 6 1 L 6 3 LIR T Z 2 UR 3 6 F I > 01 NIVD GOPA M 4 M 80 EKM K N 1 1 8 3 A T P 3 2 M POULP 2 LIP8A LIP163 3 I A > 17 T AG 7 7 R O 4 3 R O T 1 5 OSN P COR INTO 9 LIP173 B F > 1 < 3 LG U SI Z 7 T2 W ( 2 B P 3 L 6 T 7 T < M CR R L AR3 7 3 AS L 0 41° M LIBA 1 L L 2 4 I Y 9 J > 6 N 4 TA 3 N 8 M M N A 5 M < MAR 6 Q 9 < CHEL < UREN LFM T SEILLE FIR (L 7 9 D B P E 1 < 3 8 6 Y 6 F 5 MD MM Z LIBF KA A N L Y < L ) O 6 9 6 V 1 2 LIP8B SIPRO 8 -

(PIMS) Technical Manual Patient Registration, Admission, Discharge, Transfer, and Appointment Scheduling
Patient Information Management System (PIMS) Technical Manual Patient Registration, Admission, Discharge, Transfer, and Appointment Scheduling Software Version 5.3 Revised Software Release: December 2020 Department of Veterans Affairs Office of Information and Technology (OIT) Enterprise Management Program Office (EPMO) Revision History Date Revision Description Author 10/2020 0.49 Updates for VS GUI R1.7.2.1 with associated Liberty ITS VistA patch SD*5.3*756 09/2020 0.48 Approved by HSP for VS GUI R1.7.1. Added Liberty ITS updates made in August 2020 (0.44 below) to the correct document version. 09/2020 0.47 DG*5.3*1015 – Added modified routines DGENA2, Liberty ITS DGENACL2, and DGENDD to Section 3.5.18 (p. 25). 08/2020 0.46 DG*5.3*993: Added new routine Section 3.5.17 to Liberty ITS Section 3.5 New and Modified Routines (p. 24 – 25); modified ZEN – VA Specific Enrollment Segment Table 62 to include SEQ 11 – 19 (p. 205-206). 08/2020 0.45 DG*5.3*997 – Added new routines DGRP11A and Liberty ITS DGRP11B and modified routines DGRPE, DGRPH, DGRPP, DGRPP1, DGRPU, DGRPV, VAFHLFNC and VAFHLZCT to Section 3.5.16 (p. 23 - 24). 08/2020 0.44 Updates for numerous VS GUI releases with their AbleVets associated VistA patches, as requested by HSP. 05/2020 0.43 DG*5.3*996 – Added modified routine VADPT to Liberty ITS Section 3.5 New and Modified Routines (p. 23); Added PREFERRED NAME field to Table 32 Supported References (p. 87); Removed VADM(14) The PREFERRED NAME of the patient (e.g., "PREFERRED NAME") from Section 12.2.1 DEM^VADPT (p. -
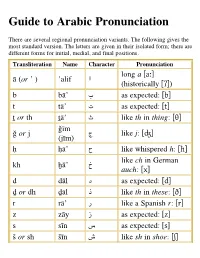
Guide to Arabic Pronunciation
Guide to Arabic Pronunciation There are several regional pronunciation variants. The following gives the most standard version. The letters are given in their isolated form; there are different forms for initial, medial, and final positions. Transliteration Name Character Pronunciation long a [aː] ﺍ ā (or ʼ ) ʼalif (historically [ʔ]) [as expected: [b ﺏ b bāʼ [as expected: [t ﺕ t tāʼ [like th in thing: [θ ﺙ ṯ or th ṯāʼ ǧīm [like j: [ʤ ﺝ ǧ or j (jīm) [like whispered h: [ħ ﺡ ḥ ḥāʼ like ch in German ﺥ kh ḫāʼ auch: [x] [as expected: [d ﺩ d dāl [like th in these: [ð ﺫ ḏ or dh ḏāl [like a Spanish r: [r ﺭ r rāʼ [as expected: [z ﺯ z zāy [as expected: [s ﺱ s sīn [like sh in shoe: [ʃ ﺵ š or sh šīn [emphatic s: [sˁ ﺹ ṣ ṣād [emphatic d: [dˁ ﺽ ḍ ḍād [emphatic t: [tˁ ﻁ ṭ ṭāʼ emphatic dh or z: ﻅ ẓ or ḍh ẓāʼ [ðˁ] / [zˁ] not found in ﻉ ʻ ʻayn English: [ʕ] not found in ﻍ ġ or gh ġayn English: [ɣ] [as expected: [f ﻑ f fāʼ not found in ﻕ q qāf English: [q] [as expected: [k ﻙ k kāf [as expected: [l ﻝ l lām [as expected: [m ﻡ m mīm [as expected: [n ﻥ n nūn [as expected: [h ﻩ h hāʼ like w or long u: [w] ﻭ w, ū wāw , [uː] like y or long i: [j] , ﻱ y , ī yāʼ [iː] Standard Arabic only has three vowels (a, i, u) and short vowels are not written. -

Middle East-I 9 Modern and Liturgical Scripts
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

Alothman 2012: Najdi Arabic In
Digital Vernaculars: An Investigation of Najdi Arabic in Multilingual Synchronous Computer-Mediated Communication A Thesis submitted to the University of Manchester for the degree of Doctor of Philosophy in the Faculty of Humanities 2012 Ebtesam S Alothman School of Languages, Linguistics and Cultures Linguistics and English Language TABLE OF CONTENTS LIST OF FIGURES…………………………………………………………………..... 10 LIST OF TABLES…………………………………………………………………….. 12 TRANSLITERATION SYSTEMS……………………………………………………. 14 LIST OF ABBREVIATIONS I……………………………………………………….. 15 LIST OF ABBREVIATIONS II……………………………………………………….. 16 ABSTRACT…………………………………………………………………………… 17 DECLARATION……….……………………………………………………………… 18 COPYRIGHT STATEMENT…………………………………………………………. 19 ACKNOWLEDGMENT……………………………………………………………… 20 DEDICATION………………………………….………………...…………………… 21 THE AUTHOR………………………………………………………………………… 22 CHAPTER ONE ……………………………………………………………………… 23 INTRODUCTION ……………………………………………………………………. 23 1.1 Preliminaries…………………………………..…………………………………… 23 1.2 Multilingual CMC: A selective history……………………………………………. 24 1.3 Statement of the problem…………………………………………………………... 30 1.4 Aims of the study….……………………………………………………………….. 32 1.5 Research questions………………………………………………………………… 33 1.6 Overview of methodology…………………………………………………………. 34 1.7 Significance of the study…………………………………………………………. 35 1.8 Limitations………………………………………………………………………... 36 1.8 Organization of the thesis…………………………………………………………. 37 CHAPTER TWO……………………………………………………………………... 41 COMPUTER-MEDIATED COMMUNICATION …............................................... -

In Vitro Activity of Quinolones Against S
.lr...o_,:11 J.,,-!J �I U$.:I ..::.,L..,.�I !""l..Li:l fr-' -,I°J ,;yWI �I tJLJ.J..... _,:!.I J_r!J �)'I �I erJ.;..,.; Ji �)I �I �I 1,1° ..!,Ll.) _r),J -!.i�)il �l::iJ 4:,1\..i_,ll ..::.,\J.,J.IJ �l.il.lJ .-l}i/1 J�\;:JJ ,t.. �JjUIJ �I ..::.,l.,�I ij oJ.t..l..:1,.1 ..::.,IJ�W.IJ �I ..::.il.JSJIJ ,�I .:,t--11 .,1..,;a&.i JS'J! 4f>.'Y' -,/°J .J....._,:).1 Jr-�� lf.... � L., ,_1,:.J ,..::.it..._.,L.ll .;r �I �l_,J)'IJ ;_JWI L-.,.:Ji � C;' ..;Jl.dl _pl)IJ ,�I yp1 .r), ..::.,L..,li.;l\ i.1$'J ,�I .u.WI J\....J ,-1>.-Jb:-J �)'I ij �4 EASTERN MEDITERRANEAN HEALTH JOURNAL IS the official health journal published by the Eastern Mediterranean Regional Office of the World Health Organization. It is a forum for the presentation and promotion of new policies and initiatives in health services; and for the exchange of ideas, concepts, epidemiological data, research findings and other information, with special reference to the Eastern Mediterranean Region. It addresses all members of the health profession, medical and other health educational institutes, interested NGOs, WHO Collaborating Centres and individuals within and outside the Region. LARE VUE DE SANTE DE LA MEDITERRANEE ORIENTALE EST une revue de sante officiellepubliee par le Bureau regional de \'Organisation mondiale de la Sante pour la Mediterranee orientale. Elle offre une tribune pour la presentation et la promotion de nouvelles politiques et initiatives dans le domaine des services de sante ainsi qu'a l'echange d'idees, de concepts, de donnees epidemiologiques, de resultats de recherches et d'autres informations, se rapportant plus particulierement a la Region de la Mediterranee orientale. -

Written Direct Statement of Settling Devotional Claimants, in the Matter of Phase II Distribution of the 1998 and 1999 Cable Royalty Funds
Before the COPYRIGHT ROYALTY JUDGES Washington, DC DR I GIMEL In the Matter of ) ) Distribution of the 2004, 2005, ) Docket No. 2012-6 CRB CD 2004-2009 2006, 2007, 2008 and 2009 ) (Phase II) Cable Royalty Funds ) In the Matter of ) ) Distribution of the 1999-2009 ) Docket No. 2012-7 CRB SD 1999-2009 Satellite Royalty Funds ) (Phase II) WRITTEN DIRECT STATEMENT OF THE SETTLING DEVOTIONAL CLAIMANTS Clifford M. Harrington (D.C. Bar No. 218107) Matthew J. MacLean (D.C. Bar No. 479257) Victoria N. Lynch (D.C. Bar No. 1001445) PILLSBURY WINTHROP SHAW PITTMAN LLP Post Office Box 57197 Washington, DC 20036-9997 Telephone: 202-663-8525 Facsimile: 202-663-8007 E-Mail:[email protected] Counselfor Settling Devotional Claimants August 22, 2016 Table of Contents I. Introductory Comments II. Supplemental Testimony of Toby Berlin, School of Toby, Inc. III. Supplemental Testimony of Erkan Erdem, Ph.D., KPMG LLP IV. Supplemental Testimony of John Sanders, Bond k, Pecaro, Inc. V. Declaration of Shirley Mahue, Coral Ridge Ministries Media, Inc. VI. Declaration of Peter T. Vay, Pillsbury Winthrop Shaw Pittman LLP VII. Oral Testimony of Toby Berlin, Dkt. Nos. 2012-6 CRB CD 2004-2009 (Phase II) & 2012-7 CRB SD 1999-2009 (Phase II), Direct and Rebuttal Hearing, Tr. Vol 2 at 60:12-145:4 (Apr. 14, 2015). VIII. Written Direct Testimony of Toby Berlin, Dkt. Nos. 2012-6 CRB CD 2004-2009 (Phase Il) A 2012-7 CRB SD 1999-2009 (Phase Ii), Amended Written Direct Statement of the Settling Devotional Claimants (Jul. 8, 2014). Before the COPYRIGHT ROYALTY JUDGES Washington, DC In the Matter of ) ) Distribution of the 2004, 2005, ) Docket No. -

Numbers Articles Available at Gordon Scanned and Edited by Ted Hildebrandt
1 NUMBERS ARTICLES Ted Hildebrandt Gordon College Sept. 2003 2 Numbers Articles available at Gordon Scanned and edited by Ted Hildebrandt Bailey, Jon N. “Vowing a way the Fifth Commandment: Matthew 15:3-6// Mark 7:9-13,” Restoration Quarterly 42 (2000) 193-209. Beck, J. A. “Geography and the Narrative Shape of Numbers 13,” Bibliotheca Sacra 157 (July-Sept. 2000) 271-80. Bosma, Carl J. and Eep Talstra, “Psalm 67: Blessing, Harvest and History: A Proposal for Exegetical Methodology,” Calvin Theological Journal 36 (2001) 290-313. Driver, Warren. “The Release of Homicides from the Cities of Refuge,” Grace Journal 1.2 (Fall, 1960) 7-22. MacRae, Allan A. “The Book Called “Numbers,” Bibliotheca Sacra 111 (441) Jan. 1954) 47-53. Mathewson, Dave. “Reading Heb 6:4-6 in Light of the Old Testament,” Westminster Theological Journal 61 (1999) 209-25. Mattingly, Keith. “The Significance of Joshua’s Reception of the Laying on of Hands in Numbers 27:12-23,” Andrews University Seminary Studies 39.2 (Autumn 2001) 191-208. Mayes, Preston. L. “Cities of Refuge,” Calvary Baptist Theological Journal14.1 (Spring 1998) 1-25. Rea, John. “New Light on the Wilderness Journey and the Conquest,” Grace Journal 2.2 (Spring, 1961) 5-13. Sailhammer, John H. “The Mosaic Law and the Theology of the Pentateuch,” Westminster Theological Journal 53 (1991) 241-61. Sawyer, Vince. “The Fall of a Great Leader as Illustrated in the Life of Moses,” Calvary Baptist Theological Journal 5.1 (Spring, 1989) 12-27. Shea, William H. “The Inscribed Tablets from Tell Deir ‘Alla: Part 1,” Andrews Uiversity Seminary Studies 27.1(Spring 1989) 191-208.