Alothman 2012: Najdi Arabic In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CYP2D6 and CYP2C19 Genotyping in Psychiatry
CYP2D6 and CYP2C19 genotyping in psychiatry Citation for published version (APA): Koopmans, A. B. (2021). CYP2D6 and CYP2C19 genotyping in psychiatry: bridging the gap between practice and lab. ProefschriftMaken. https://doi.org/10.26481/dis.20210512ak Document status and date: Published: 01/01/2021 DOI: 10.26481/dis.20210512ak Document Version: Publisher's PDF, also known as Version of record Please check the document version of this publication: • A submitted manuscript is the version of the article upon submission and before peer-review. There can be important differences between the submitted version and the official published version of record. People interested in the research are advised to contact the author for the final version of the publication, or visit the DOI to the publisher's website. • The final author version and the galley proof are versions of the publication after peer review. • The final published version features the final layout of the paper including the volume, issue and page numbers. Link to publication General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal. -

Different Dialects of Arabic Language
e-ISSN : 2347 - 9671, p- ISSN : 2349 - 0187 EPRA International Journal of Economic and Business Review Vol - 3, Issue- 9, September 2015 Inno Space (SJIF) Impact Factor : 4.618(Morocco) ISI Impact Factor : 1.259 (Dubai, UAE) DIFFERENT DIALECTS OF ARABIC LANGUAGE ABSTRACT ifferent dialects of Arabic language have been an Dattraction of students of linguistics. Many studies have 1 Ali Akbar.P been done in this regard. Arabic language is one of the fastest growing languages in the world. It is the mother tongue of 420 million in people 1 Research scholar, across the world. And it is the official language of 23 countries spread Department of Arabic, over Asia and Africa. Arabic has gained the status of world languages Farook College, recognized by the UN. The economic significance of the region where Calicut, Kerala, Arabic is being spoken makes the language more acceptable in the India world political and economical arena. The geopolitical significance of the region and its language cannot be ignored by the economic super powers and political stakeholders. KEY WORDS: Arabic, Dialect, Moroccan, Egyptian, Gulf, Kabael, world economy, super powers INTRODUCTION DISCUSSION The importance of Arabic language has been Within the non-Gulf Arabic varieties, the largest multiplied with the emergence of globalization process in difference is between the non-Egyptian North African the nineties of the last century thank to the oil reservoirs dialects and the others. Moroccan Arabic in particular is in the region, because petrol plays an important role in nearly incomprehensible to Arabic speakers east of Algeria. propelling world economy and politics. -

Possessive Constructions in Najdi Arabic
Possessive Constructions in Najdi Arabic Eisa Sneitan Alrasheedi A thesis submitted to the Faculty of Humanities, Arts and Social Sciences in partial fulfilment of the requirements for the degree of Doctor of Philosophy in Theoretical Linguistics School of English Literature, Language and Linguistics Newcastle University July, 2019 ii Abstract This thesis investigates the syntax of possession and agreement in Najdi Arabic (NA, henceforth) with a particular focus on the possession expressed at the level of the DP (Determiner Phrase). Using the main assumptions of the Minimalist Program (Chomsky 1995, and subsequent work) and adopting Abney’s (1987) DP-hypothesis, this thesis shows that the various agreement patterns within the NA DP can be accounted for with the use of a probe/goal agreement operation (Chomsky 2000, 2001). Chapter two discusses the syntax of ‘synthetic’ possession in NA. Possession in NA, like other Arabic varieties, can be expressed synthetically using a Construct State (CS), e.g. kitaab al- walad (book the-boy) ‘the boy’s book’. Drawing on the (extensive) literature on the CS, I summarise its main characteristics and the different proposals for its derivation. However, the main focus of this chapter is on a lesser-investigated aspect of synthetic possession – that is, possessive suffixes, the so-called pronominal possessors, as in kitaab-ah (book-his) ‘his book’. Building on a previous analysis put forward by Shlonsky (1997), this study argues (contra Fassi Fehri 1993), that possessive suffixes should not be analysed as bound pronouns but rather as an agreement inflectional suffix (à la Shlonsky 1997), where the latter is derived by Agree between the Poss(essive) head and the null pronoun within NP. -

GAF Timberline Series Application Instructions
Application Instructions Timberline® HDTM, Timberline® Natural ShadowTM, Timberline® Ultra HDTM, Timberline® Cool Series, Timberline® American HarvestTM, Updated: 4/12 Quality You Can Trust… From North America’s Largest Roofing Manufacturer!™ www.gaf.com Quality You Can Trust…From North America’s Largest Roofing Manufacturer!™ ¡Calidad En La Que Usted Puede Confiar...Del Fabricante De Techos Más Grande De Norteamérica!™ Une Qualité À Laquelle Vous Pouvez Vous Fier... Du Plus Gros Fabricant De Toitures En Amérique Du Nord! MC INSTALLATION INSTRUCTIONS · INSTRUCCIONES DE INSTALACIÓN · INSTRUCTIONS D’INSTALLATION LIFETIME HIGH DEFINITION® SHINGLES LIFETIME SHINGLES TEJAS DE ALTA DEFINICIÓN® DE POR VIDA TEJAS DE POR VIDA BARDEAUX DE HAUTE DÉFINITION® À VIE BARDEAUX À VIE LIFETIME HIGH DEFINITION® SHINGLES TEJAS DE ALTA DEFINICIÓN® DE POR VIDA ENERGY-SAVING ARCHITECTURAL SHINGLES TEJAS ARQUITECTÓNICAS PARA AHORRO DE ENERGÍA BARDEAUX DE HAUTE DÉFINITION® À VIE BARDEAUX ARCHITECTURAUX ÉCONERGÉTIQUES GENERAL INSTRUCTIONS t."5&3*"-4"'&5:%"5"4)&&54 When using GAF products, e.g., shingles, underlayments, plastic cement, etc., please refer to the applicable MSDS. The most current versions are available at www.gaf.com. GAF does not provide safety data sheets or installation instructions for products not manufactured by GAF. Please consult the material manufacturer for their MSDS and installation instructions where appropriate. t300'%&$,4Use minimum 3/8" (10mm) plywood or OSB decking as recommended by APA-The Engineered Wood Assn. Wood decks must be well-seasoned and supported having a maximum 1/8" (3mm) spacing, using minimum nominal 1"(25mm) thick lumber, a maximum 6" (152mm) width, having adequate nail-holding capacity and a smooth surface. -

Persian Ugs Kobo Audiobook.Pdf
LESSON NOTES Basic Bootcamp #1 Self Introductions - Basic Greetings in Persian CONTENTS 2 Persian 2 English 2 Romanization 2 Vocabulary 3 Sample Sentences 4 Vocabulary Phrase Usage 6 Grammar # 1 COPYRIGHT © 2013 INNOVATIVE LANGUAGE LEARNING. ALL RIGHTS RESERVED. PERSIAN . : .1 . : .2 . : .3 . : .4 ENGLISH 1. BEHZAD: Hello. I'm Behzad. What's your name? 2. MARY: Hello Behzad. My name is Mary. 3. BEHZAD: Nice to meet you. 4. MARY: You too. ROMANIZATION 1. BEHZAD: Salam, man Behzad am. Esme shoma chi e? 2. MARY: Salam Behzad, Esme man Mary e. 3. BEHZAD: Az ashnayi ba shoma khoshvaght am. 4. MARY: Man ham hamintor. VOCABULARY PERSIANPOD101.COM BASIC BOOTCAMP #1 - SELF INTRODUCTIONS - BASIC GREETINGS IN PERSIAN 2 Persian Romanization English Class Man ham hamintor. me too phrase Az ashnayi ba shoma khoshvaght Nice to meet you sentence am. ... Esme man (...) e. My name is (...). sentence Esme shoma chi e? What’s your name? sentence salaam hello interjection man I, me pronoun hastam (I) am verb esm name noun SAMPLE SENTENCES : . : . . . ali: man gorosne hastam. zahraa: man ham man faateme hastam. az aashnaayi baa shomaa hamin tor. khoshvaghtam. Ali: I'm hungry. Zahra: Me too. My name is Fateme. Nice to meet you. . esm-e man zeinabe. esm-e man naaser e. esm-e shomaa chie? My name is Zeinab. My name is Naser. What is your name? . . Oo hich vaght be man salaam nemikonad. Az man aks nagir. He never says hello to me. "Don't take photos of me." . Man ta hala chenin chizi nadidam. Kheili khaste hastam I have never seen such a thing. -
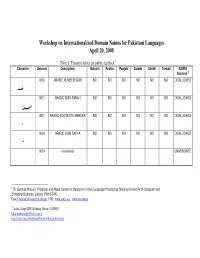
Workshop on Internationalized Domain Names for Pakistani Languages April 20, 2008
Workshop on Internationalized Domain Names for Pakistani Languages April 20, 2008 Table 1: Tentative tables for public feedback 1 Character Unicode Description Balochi Pashto Punjabi Saraiki Sindhi Torwali ASIWG Decision 2 0600 ARABIC NUMBER SIGN NO NO NO NO NO NO DISALLOWED 0601 ARABIC SIGN SANAH NO NO NO NO NO NO DISALLOWED 0601 ARABIC FOOTNOTE MARKER NO NO NO NO NO NO DISALLOWED 0603 ARABIC SIGN SAFHA NO NO NO NO NO NO DISALLOWED 0604 <reserved> UNASSIGNED 1 Dr. Sarmad Hussain, Professor and Head, Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, Lahore, PAKISTAN. Email: [email protected] , URL: www.crulp.org , www.nu.edu.pk 2 Arabic Script IDN Working Group (ASIWG) [email protected] http://lists.irnic.ir/mailman/listinfo/idna-arabicscript 0605 <reserved> UNASSIGNED 0606 ARABIC-INDIC CUBE ROOT NO NO NO NO NO NO DISALLOWED 0607 ARABIC-INDIC FOURTH NO NO NO NO NO NO DISALLOWED ROOT 0608 ARABIC RAY NO NO NO NO NO NO DISALLOWED 0609 ARABIC-INDIC PER MILLE NO NO NO NO NO NO DISALLOWED SIGN 060A ARABIC-INDIC PER TEN NO NO NO NO NO NO DISALLOWED THOUSAND SIGN 060B AFGHANI SIGN NO NO NO NO NO NO DISALLOWED 060C ARABIC COMMA NO NO NO NO NO NO DISALLOWED 060D ARABIC DATE SEPARATOR NO NO NO NO NO NO DISALLOWED ؍ 060E ARABIC POETIC VERSE SIGN NO NO NO NO NO NO DISALLOWED ؎ 060F ARABIC SIGN MISRA NO NO NO NO NO NO DISALLOWED ؏ 0610 ARABIC SIGN SALLALLAHOU PENDING PENDING PENDING PENDING PENDING PENDING PVALID ALAYHE WASSALLAM 0611 ARABIC SIGN ALAYHE PENDING PENDING -

00. the Realization of Negation in the Syrian Arabic Clause, Phrase, And
The realization of negation in the Syrian Arabic clause, phrase, and word Isa Wayne Murphy M.Phil in Applied Linguistics Trinity College Dublin 2014 Supervisor: Dr. Brian Nolan Declaration I declare that this dissertation has not been submitted as an exercise for a degree at this or any other university and that it is entirely my own work. I agree that the Library may lend or copy this dissertation on request. Signed: Date: 2 Abstract The realization of negation in the Syrian Arabic clause, phrase, and word Isa Wayne Murphy Syrian Arabic realizes negation in broadly the same way as other dialects of Arabic, but it does so utilizing varied and at times unique means. This dissertation provides a Role and Reference Grammar account of the full spectrum of lexical, morphological, and analytical means employed by Syrian Arabic to encode negation on the layered structures of the verb, the clause, the noun, and the noun phrase. The scope negation takes within the LSC and the LSNP is identified and illustrated. The study found that Syrian Arabic employs separate negative particles to encode wide-scope negation on clauses and narrow-scope negation on constituents, and utilizes varied and interesting means to express emphatic negation. It also found that while Syrian Arabic belongs in most respects to the broader Levantine family of Arabic dialects, its negation strategy is more closely aligned with the Arabic dialects of Iraq and the Arab Gulf states. 3 Table of Contents DECLARATION......................................................................................................................... -

20 May 2021 4° 5° 6° 7° 8° 9° 10° 11° 12° 13° 14° 15° 16° 17° 18° 19° 20° 21° 22° 23° 24°
ERC-03/L 20 May 2021 4° 5° 6° 7° 8° 9° 10° 11° 12° 13° 14° 15° 16° 17° 18° 19° 20° 21° 22° 23° 24° LFD54 M < A1 < M 0 G2 DIKEL VALMA LIP233 Z LIR22 LIP329 LIR50 A482 OKDI N14 T216 N141> T ANA > <Y < 6 8 YE L 1> 2 R 4 3 VE LFD < 4 LIP99 CRA TI < 4 E ED R1 9 R 5 > 5 A 1 K < 4 M L G U SO A2 T 5 L L TORLI 8 06 7 MA 7 L 4 2 A LIR3 7 M M P 4 ERIK 2 U ISIP ) W1 1 6 8 0 DIVK P AAL > 8 U 0 LF 1 2 1 M 0 LA ASB D 3 1 > > 3 L 1 5 7 L LIRL LIR N V 4A 4 8 3 9 3 7 7 LIR309A A 95 7 N K > LF 1 2 L 7 LIRRAET ERAV --------- 1 1 R19 LG 2 9 K P - 5 F 3 --- A N 2 9 7 A --- 3 G LIRRUS1 300 305 8 --- R 4 L AP 9 5 2 LIR LIR --- LA AR < 8 M 6 RUR M AM 4 < LID 9B B A D2 DOB M 13 H P 2 67 0 8 R30 T A L 1 Q LI L 9 F E A 2 D S 9 4 54C1 L J L IR300B L 2> 0 SK L A < 1 7 L 4 L 4 E TMA R3C F P 5 G 5 > 9 Z IP328 BCN1 6 A AAA LA K 2 3 1 L LIB 7 A O L M L L 1 1 L < 9 3 B > FM 5 9 9 G N 6 LFD54 LFD MAJ E L H IKO C2 1 9 580 LVIN 5 1 2 2 G O OD < 5 8 6 L W < 5 2 < L ) 1 1 7 > 0 6 0 10 1 R LS ( LGGG GR 1 LAT LIP2 5 6 3 LYBA FIR ( 8 N L LF Z LIP323 2A A T I 2 D 8 0 54C3 2 LIR3 L SA01 1 A 6 6 T 2 T N 1 <U 1 5 D 2 LW LW < HI 1 GR 7 M 9 302B 5 R S LWSS N 6 1 L 6 3 LIR T Z 2 UR 3 6 F I > 01 NIVD GOPA M 4 M 80 EKM K N 1 1 8 3 A T P 3 2 M POULP 2 LIP8A LIP163 3 I A > 17 T AG 7 7 R O 4 3 R O T 1 5 OSN P COR INTO 9 LIP173 B F > 1 < 3 LG U SI Z 7 T2 W ( 2 B P 3 L 6 T 7 T < M CR R L AR3 7 3 AS L 0 41° M LIBA 1 L L 2 4 I Y 9 J > 6 N 4 TA 3 N 8 M M N A 5 M < MAR 6 Q 9 < CHEL < UREN LFM T SEILLE FIR (L 7 9 D B P E 1 < 3 8 6 Y 6 F 5 MD MM Z LIBF KA A N L Y < L ) O 6 9 6 V 1 2 LIP8B SIPRO 8 -

Topic Particles in the North Hail Dialect of Najdi Arabic
Topic Particles in the North Hail Dialect of Najdi Arabic Murdhy Radad D Alshamari A thesis submitted to the Faculty of Humanities, Arts and Social Sciences in partial fulfilment of the requirements for the degree of Doctor of Philosophy In Theoretical Linguistics School of English Literature, Language and Linguistics At Newcastle University, UK September 2017 i ii ABSTRACT This thesis investigates a set of clause-initial discourse particles in North Hail Arabic (NHA), a dialect spoken in Saudi Arabia. The particles are shown to be heads in the C-domain with topic-marking function. It is shown that the topics typology put forward by Frascarelli and Hinterhölzl (2007) for German and Italian extends to NHA. The Shifting Topic (S-Topic) is situated above the Focus Phrase, followed by Contrastive Topic (C-Topic), which is in turn followed by Familiar Topic (F-Topic). S-Topic can be marked by either C-particles mar or ʕad. The particles tara and ʔaktɪn mark an entity expressing C-Topic, while the particle ʁedɪ, tsin, ʔeʃwa and tigil mark an entity expressing F-Topic. All particles are argued to carry a valued [TOP] feature. However, they are different with respect to whether they have φ-content. This difference motivates the distinction between agreeing particles (having φ-content) and non- agreeing particles (not having φ-content). The study shows that the agreeing particles are probes, being with unvalued φ-features, establishing an Agree relation (Chomsky 2000, 2001) with the element that carries a matching unvalued [TOP] feature and valued φ-features. This results in the valuation of the unvalued φ-features of the agreeing particle, and the valuation of the matching unvalued [TOP] feature of the goal. -

(PIMS) Technical Manual Patient Registration, Admission, Discharge, Transfer, and Appointment Scheduling
Patient Information Management System (PIMS) Technical Manual Patient Registration, Admission, Discharge, Transfer, and Appointment Scheduling Software Version 5.3 Revised Software Release: December 2020 Department of Veterans Affairs Office of Information and Technology (OIT) Enterprise Management Program Office (EPMO) Revision History Date Revision Description Author 10/2020 0.49 Updates for VS GUI R1.7.2.1 with associated Liberty ITS VistA patch SD*5.3*756 09/2020 0.48 Approved by HSP for VS GUI R1.7.1. Added Liberty ITS updates made in August 2020 (0.44 below) to the correct document version. 09/2020 0.47 DG*5.3*1015 – Added modified routines DGENA2, Liberty ITS DGENACL2, and DGENDD to Section 3.5.18 (p. 25). 08/2020 0.46 DG*5.3*993: Added new routine Section 3.5.17 to Liberty ITS Section 3.5 New and Modified Routines (p. 24 – 25); modified ZEN – VA Specific Enrollment Segment Table 62 to include SEQ 11 – 19 (p. 205-206). 08/2020 0.45 DG*5.3*997 – Added new routines DGRP11A and Liberty ITS DGRP11B and modified routines DGRPE, DGRPH, DGRPP, DGRPP1, DGRPU, DGRPV, VAFHLFNC and VAFHLZCT to Section 3.5.16 (p. 23 - 24). 08/2020 0.44 Updates for numerous VS GUI releases with their AbleVets associated VistA patches, as requested by HSP. 05/2020 0.43 DG*5.3*996 – Added modified routine VADPT to Liberty ITS Section 3.5 New and Modified Routines (p. 23); Added PREFERRED NAME field to Table 32 Supported References (p. 87); Removed VADM(14) The PREFERRED NAME of the patient (e.g., "PREFERRED NAME") from Section 12.2.1 DEM^VADPT (p. -

Rhode Island College
Rhode Island College M.Ed. In TESL Program Language Group Specific Informational Reports Produced by Graduate Students in the M.Ed. In TESL Program In the Feinstein School of Education and Human Development Language Group: Arabic Author: Joy Thomas Program Contact Person: Nancy Cloud ([email protected]) http://cache.daylife.com/imagese http://cedarlounge.files.wordpress.com rve/0fxtg1u3mF0zB/340x.jpg /2007/12/3e55be108b958-64-1.jpg Joy http://photos.igougo.com/image Thomas s/p183870-Egypt-Souk.jpg http://www.famous-people.info/pictures/muhammad.jpg Arabic http://blog.ivanj.com/wp- http://en.wikipedia.org/wiki/File:Learning_Arabi content/uploads/2008/04/dubai-people.jpg http://www.mrdowling.com/images/607arab.jpg c_calligraphy.jpg History • Arabic is either an official language or is spoken by a major portion of the population in the following countries: Algeria, Bahrain, Chad, Comoros, Djibouti, Egypt, Eritrea, Ethiopia, Iraq, Jordan, Kuwait, Libya, Lebanon, Mauritania, Morocco, Oman, Qatar, Saudi Arabia, Somalia, Sudan, Syria, Tunisia, United Arab Emirates, Yemen • Arabic is a Semitic language, it has been around since the 4th century AD • Three different kinds of Arabic: Classical or “Qur’anical” Arabic, Formal or Modern Standard Arabic and Spoken or Colloquial Arabic • Classical Arabic only found in the Qur’an, it is not used in communication, but all Muslims are familiar to some extent with it, regardless of nationality • Arabic is diglosic in nature, as there is a major difference between Modern Standard and Colloquial Arabic • Modern -

The Damascus Psalm Fragment Oi.Uchicago.Edu
oi.uchicago.edu The Damascus Psalm Fragment oi.uchicago.edu ********** Late Antique and Medieval Islamic Near East (LAMINE) The new Oriental Institute series LAMINE aims to publish a variety of scholarly works, including monographs, edited volumes, critical text editions, translations, studies of corpora of documents—in short, any work that offers a significant contribution to understanding the Near East between roughly 200 and 1000 CE ********** oi.uchicago.edu The Damascus Psalm Fragment Middle Arabic and the Legacy of Old Ḥigāzī by Ahmad Al-Jallad with a contribution by Ronny Vollandt 2020 LAMINE 2 LATE ANTIQUE AND MEDIEVAL ISLAMIC NEAR EAST • NUMBER 2 THE ORIENTAL INSTITUTE OF THE UNIVERSITY OF CHICAGO CHICAGO, ILLINOIS oi.uchicago.edu Library of Congress Control Number: 2020937108 ISBN: 978-1-61491-052-7 © 2020 by the University of Chicago. All rights reserved. Published 2020. Printed in the United States of America. The Oriental Institute, Chicago THE UNIVERSITY OF CHICAGO LATE ANTIQUE AND MEDIEVAL ISLAMIC NEAR EAST • NUMBER 2 Series Editors Charissa Johnson and Steven Townshend with the assistance of Rebecca Cain Printed by M & G Graphics, Chicago, IL Cover design by Steven Townshend The paper used in this publication meets the minimum requirements of American National Standard for Information Services — Permanence of Paper for Printed Library Materials, ANSI Z39.48-1984. ∞ oi.uchicago.edu For Victor “Suggs” Jallad my happy thought oi.uchicago.edu oi.uchicago.edu Table of Contents Preface............................................................................... ix Abbreviations......................................................................... xi List of Tables and Figures ............................................................... xiii Bibliography.......................................................................... xv Contributions 1. The History of Arabic through Its Texts .......................................... 1 Ahmad Al-Jallad 2.