Safety-Critical Software in Machinery Applications • Vtt Research Notes 2601
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Building Functional Safety Into Industrial Robotics
BUILDING FUNCTIONAL SAFETY INTO INDUSTRIAL ROBOTICS Rian Whitton Principal Analyst EXECUTIVE SUMMARY TABLE OF CONTENTS Functional safety is critical to many modern robotic applications and will become more so. In the near future, many robots will run in areas where they interact directly Executive Summary ................................1 and indirectly with workers, and the tasks they perform will disproportionately relate The Market for Industrial Robotics ...........2 The Potential of the Robotics Industry .....................2 to production logistics and moving goods for the general public. If a robot malfunctions, New Robots, New Demands ...................................4 there is a risk to the surrounding workers, to product safety, and to public safety. This Functional Safety Is Crucial for the Industry to Meet risk amplifies as robots are increasingly required to handle multiple tasks and navigate Its Potential ............................................................5 Regulations .............................................................6 crowded environments. So, mitigating safety risks under these conditions will become Embedded Systems for Robotics ..............7 a fundamental requirement that cannot be addressed without considering security as RTOS and the Benefits of Microkernel an integral part of robot design. Architecture ............................................................8 Hypervisors-as-a-Solution .......................................9 This is where functional safety of the underlying software and -

Relevant Norms and Standards
Appendix A Relevant norms and standards A.1 A Short Overview of the Most Relevant Process Standards There is a huge number of different process standards, and Fig. A.1 contains an overview of the most relevant such standards as covered in this book, showing the topics covered. A more extensive list of the relevant standards will be provided in the following section below. ISO/IEC 15504, ISO 19011 ISO/IEC 330xx Auditing man- agement systems Process Process assessment ISO/IEC 20000-1 ISO 9001 ISO/IEC 15504-6 ISO/IEC 15504-5 Service management QM system re- System life cycle PAM Software life cycle PAM Assessments, audits Criteria system requirements quirements ISO/IEC/IEEE 15288 ISO/IEC/IEEE 12207 ITIL System life cy- Software life cy- IT Infrastruc- cle processes cle processes ture Library COBIT Life cycle processes SWEBoK Software engineering Funda- Body of Knowledge mentals ISO/IEC/IEEE 24765 ISO 9000 Systems and SW Engineering Vocabulary QM fundamentals (SEVOCAB) and vocabulary Vocabulary Systems Software Organzational IT Quality Management Engineering Engineering Fig. A.1 Overview of the most important standards for software processes © Springer Nature Switzerland AG 2018 327 R. Kneuper, Software Processes and Life Cycle Models, https://doi.org/10.1007/978-3-319-98845-0 328 A Relevant norms and standards A.2 ISO and IEC Standards The International Organization for Standardization (ISO) is the main international standard-setting organisation, working with representatives from many national standard-setting organisations. Standards referring to electrical, electronic and re- lated technologies, including software, are often published jointly with its sister organisation, the International Electrotechnical Commission (IEC), but IEC also publishes a number of standards on their own. -

Standards Action Layout SAV3438.Fp5
PUBLISHED WEEKLY BY THE AMERICAN NATIONAL STANDARDS INSTITUTE 25 West 43rd Street, NY, NY 10036 VOL. 34, #38 September 19, 2003 Contents American National Standards Call for Comment on Standards Proposals................................................. 2 Call for Comment Contact Information........................................................ 5 Initiation of Canvasses.................................................................................. 7 Final Actions .................................................................................................. 8 Project Initiation Notification System (PINS) .............................................. 10 International Standards ISO Draft Standards ...................................................................................... 13 ISO Newly Published Standards .................................................................. 15 Registration of Organization Names in the U.S. ........................................... 18 Proposed Foreign Government Regulations ................................................ 18 Information Concerning.................................................................................. 19 Standards Action is now available via the World Wide Web For your convenience Standards Action can now be down- loaded from the following web address: http://www.ansi.org/news_publications/periodicals/standard s_action/standards_action.aspx?menuid=7 American National Standards Call for comment on proposals listed This section solicits your comments on proposed -

Guideline for Applying Functional Safety to Autonomous Systems in Mining
20200709_Guideline_for_Applying_Functional_Safety_to_Autonomous_Systems- GMG-AM-FS-v01-r01 GUIDELINE FOR APPLYING FUNCTIONAL SAFETY TO AUTONOMOUS SYSTEMS IN MINING SUBMITTED BY Functional Safety for Autonomous Equipment Sub-committee VERSION DATE 09 Jul 2020 APPROVED BY Autonomous Mining Working Group 31 Jul 2020 and GMG Executive Council 12 Aug 2020 PUBLISHED 18 Aug 2020 DATE DOCUMENT TO BE REVIEWED 18 Aug 2022 PREPARED BY THE FUNCTIONAL SAFETY FOR AUTONOMOUS EQUIPMENT SUB-COMMITTEE OF THE AUTONOMOUS MINING WORKING GROUP Global Mining Guidelines Group (GMG) ii | GUIDELINE FOR APPLYING FUNCTIONAL SAFETY TO AUTONOMOUS SYSTEMS IN MINING DISCLAIMER Although the Global Mining Guidelines Group (GMG) believes that the information on https://gmggroup.org, which includes guidelines, is reliable, GMG and the organizations involved in the preparation of the guidelines do not guarantee that it is accu- rate or complete. While the guidelines are developed by participants across the mining industry, they do not necessarily rep- resent the views of all of the participating organizations. This information does not replace or alter requirements of any national, state, or local governmental statutes, laws, regulations, ordinances, or other requirements. Your use of GMG guide- lines is entirely voluntary. CREDITS Organizations Involved in the Preparation of these Guidelines ABB, Abbott Risk Consulting, Agnico Eagle, Airobiotics, Alex Atkins & Associates, Ambuja Cements, AMOG Consulting, Antofa- gasta Minerals, Australian Droid + Robot, Autonomous Solutions, -
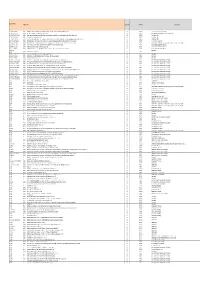
STANDARDS LIST Neu.Xlsx
Document‐Number Published Title Organization Committee Committee Title IEC 100/2536/CD * IEC 63002 2015‐07 IEC 63002, Ed. 1.0: Idenficaon and CommunicaonInteroperability Method for External Power Supplies Used WithPortable Compung Devices (TA 14) IEC IEC/TC 100 Audio, video and multimedia systems and equipment IEC 115/105/CD *IEC/TR 62978 2015‐01 IEC/TR 62978, Ed. 1: Guidelines on Asset Management forHVDC Installaons IEC IEC/TC 115 High Voltage Direct Current (HVDC) transmission for DC voltages above 100 kV IEC 118/29/DPAS* IEC/PAS 62746‐199 2013‐09 System interfaces and communication protocol profiles relevant for systems connected to the smart grid ‐ Open Automated Demand Response (OpenADR 2.0 Profile Specification) IEC IEC/PC 118 Smart grid user interface IEC 118/46/CD *IEC 62746‐10‐2 2014‐12 OASIS Energy Interoperation Version 1.0 Specification IEC IEC/PC 118 Smart grid user interface IEC 118/47/CD * IEC 62746‐10‐1 2015‐01 IEC 62746‐10‐1: Systems interface between customer energymanagement system and the power management system ‐ Part10 ‐1: Open Automated Demand Response (OpenADR 2.0bPro file Specificaon) IEC IEC/PC 118 Smart grid user interface IEC 22H/192/CD * IEC/TS 62040‐4‐1 2015‐04 IEC/TS 62040‐4‐1: Uninterrupble power systems (UPS) ‐ Part 4‐1: Environmental aspects ‐ Product Category Rules (PCR) for life Cycle Assessment and environmental declaraons IEC IEC/SC 22H Uninterruptible power systems (UPS) IEC 3/1224A/CD * IEC 81346‐2 2015‐05 Industrial systems, installaons and equipment and industrialproducts ‐ Structuring principles and reference designaons ‐ Part 2: Classificaon of objects and codes for classes IEC IEC/TC 3 Information structures and elements, identification and marking principles, documentation and graphical symbols IEC 3D/225A/CD * IEC 62656‐5 2014‐03 IEC 62656‐5, Ed. -

Standards for Enabling Trade— Mapping and Gap Analysis Study
Standards for Enabling Trade— Mapping and Gap Analysis Study An IA-CEPA Early Outcomes Initiative November 2017 Standards For Enabling Trade—Mapping and Gap Analysis Study 2 An IA-CEPA Early Outcomes Initiative – November 2017 Contents ListofFigures..............................................................................................................3 Abbreviations...............................................................................................................4 Terms..........................................................................................................................6 Acknowledgements......................................................................................................8 ExplanatoryNotes........................................................................................................8 Foreword.....................................................................................................................9 Recommendations.....................................................................................................10 ExecutiveSummary....................................................................................................11 Introduction................................................................................................................13 ProjectPurpose.........................................................................................................13 Objectives..................................................................................................................13 -

Internet of Things Risk Analysis and Assessment
Deliverable 3: Internet of Things Risk Analysis and Assessment PROJECT RISIOT: MARKET ANALYSIS AND RISK ASSESSMENT TO ACCELERATE THE ADOPTION OF THE INTERNET OF THINGS IN AUSTRIAN ENTERPRISES Sandra König, Stefan Schiebeck, Stefan Schauer, Martin Latzenhofer, Peter Mayer, Geraldine Fitzpatrick MAY, 2017 IoT Risks The project RISIoT - MARKET ANALYSIS AND RISK ASSESSMENT TO ACCELERATE THE ADOPTION OF THE INTERNET OF THINGS IN AUSTRIAN ENTERPRISES – is conducted between September 2016 and August 2017 by the following consortium: IDC Central Europe GmbH Austrian Institute of Technology GmbH Technical University of Vienna Austrian Computer Society The RISIoT project is co-funded under the „ICT of the Future“ programme by the Austrian Ministry for Transport, Innovation and Technology and the Austrian Research Promotion Agency (FFG). Project number: 855450 1 IoT Risks TABLE OF CONTENTS Table of Contents .......................................................................................................................................................2 List of Figures ..............................................................................................................................................................3 List of Tables ...............................................................................................................................................................3 1. Introduction ........................................................................................................................................................0 -

BGIA Report 2/2008E
BGIA Report 2/2008e Functional safety of machine controls − Application of EN ISO 13849 − Care has been taken in the translation of this report from German. In case of any doubt consider the German version: Funktionale Sicherheit von Maschinensteue- rungen – Anwendung der DIN EN ISO 13849 – (BGIA-Report 2/2008, 2nd ed. Dec. 2008, and Erratum as of June 2009) Authors: Michael Hauke, Michael Schaefer, Ralf Apfeld, Thomas Boemer, Michael Huelke, Torsten Borowski, Karl-Heinz Büllesbach, Michael Dorra, Hans-Georg Foermer-Schaefer, Wolfgang Grigulewitsch, Klaus-Dieter Heimann, Burkhard Köhler, Michael Krauß, Werner Kühlem, Oliver Lohmaier, Karlheinz Meffert, Jan Pilger, Günter Reuß, Udo Schuster, Thomas Seifen, Helmut Zilligen BGIA – Institute for Occupational Safety and Health of the German Social Accident Insurance, Sankt Augustin Editorial office: Central Division of the BGIA – Institute for Occupational Safety and Health of the German Social Accident Insurance Published by: German Social Accident Insurance (DGUV) Mittelstr. 51 10117 Berlin Germany Tel.: +49 30 288763-800 Fax: +49 30 288763-808 Internet www.dguv.de − June 2009 − ISBN: 978-3-88383-793-2 ISSN: 1869-3491 Functional safety of machine controls – Application of EN ISO 13849 – Abstract The EN ISO 13849 standard, “Safety of machinery – Safety-related parts of control systems”, contains provisions governing the design of such parts. This report de- scribes the essential subject-matter of the standard in its heavily revised 2006 edi- tion, and explains its application with reference to numerous examples from the fields of electromechanics, fluidics, electronics and programmable electronics, including control systems employing mixed technologies. The standard is placed in its context of the essential safety requirements of the Machinery Directive, and possible methods for risk assessment are presented. -

Transforming the Future 2019
AUTOMATION & DIGITISATION AUTOMATION VOL 12 APR-MAY 2019 ` 100 www.industr.com/en AUTOMATION & DIGITISATION INDUSTRIAL ROBOTS Transforming the future Apr-May Apr-May 2019 I VOLUME 12 Also available in China, Taiwan, Singapore, Malaysia, Thailand & Hong Kong Malaysia, Singapore, Taiwan, Also available in China, A&D - Interview www.industr.com/en Bipin K Chirmure, CEO & Managing Director, Stauff India (p. 17) FOCUS Chemical & Process P. 36 In association with Additive Manufacturing P. 40 Advt Solutions for the Chemical Industry Planning and construction of system solutions ■ Comprehensive fieldbus technology know- Interface and power supply modules how for chemical applications with fieldbus solutions for plants and control cabinet Cabinet guard ■ Modules to isolate, convert, process and ■ Tailor made system solutions with interface condition analog and digital signals devices ■ Monitoring of the door as well as ex- ceedance of temperature and interior humidity ■ Applicable up to zone 1 Distributed signal processing ■ The modular I/O systems excom® and BL20 support application-optimized Identification of mobile signal processing containers and tube stations ■ Use in the non-Ex and Ex areas in zones 1 and 2, as well as 21 and 22 ■ The RFID system BL ident® ensures in- creased plant efficiency and traceability of the production processes through the reliable detection of mobile containers Namur stainless steel sensors ■ The inductive sensors with removable terminal chambers are easily commis- sioned and maintained. ■ High density and chemical -

International Standards in Process CD Registered
International Standards in process An International Standard is the result of an agreement between the member bodies of ISO. A first important step towards an International Standard takes the form of a committee draft (CD) - this is circulated for study within an ISO technical committee. When consensus has been reached within the technical committee, the document is sent to the Central Secretariat for processing as a draft International Standard (DIS). The DIS requires approval by at least 75 % of the member bodies casting a vote. A confirmation vote is subsequently carried out on a final draft International Standard (FDIS), the approval criteria remaining the same. CD registered Period from 01 October to 31 October 2012 These documents are currently under consideration in the technical committee. They have been registred at the Central Secretariat. REMCO Committee on reference materials ISO/CD Guide 33 Reference Materials — Good practice in using reference materials TC 17 Steel ISO/CD 4990 Steel castings — General technical delivery requirements ISO/CD 4991 Steel castings for pressure purposes ISO/CD 4993 Steel and iron castings — Radiographic inspection ISO/CD 9477 High strength cast steels for general engineering and structural purposes ISO/CD 11970 Specification and approval of welding procedures for production welding of steel castings ISO/CD 11972 Corrosion-resistant cast steels for general applications ISO/CD 11973 Heat-resistant cast steels and alloys for general applications ISO/CD 13520 Determination of ferrite content in austenitic -
List of ISO Standards - Wikipedia, the Free Encyclopedia
List of ISO standards - Wikipedia, the free encyclopedia Log in / create account Wikipedia: Making Life Easier. [Collapse] Article Discussion Edit this page History $3,376,364 Our Goal: $6 million Donate Now » List of ISO standards Navigation From Wikipedia, the free encyclopedia ● Main page ● Contents This is a list of ISO standards that are discussed in Wikipedia articles. For a list of all the more than 16,000 ISO standards (as of ● Featured content 2007), see the ISO Catalogue. ● Current events About 300 of the standards produced by ISO and IEC's Joint Technical Committee 1 (JTC1) have been made freely/publicly ● Random article [ ] available. 1 Search Contents [hide] ● 1 ISO 1–ISO 999 Interaction ● 2 ISO 1000–ISO 9999 ● About Wikipedia ● 3 ISO 10000–ISO ● Community portal 19999 ● Recent changes ● 4 ISO 20000–ISO ● Contact Wikipedia 29999 ● Donate to Wikipedia ● 5 ISO 30000–ISO ● Help 39999 Toolbox ● 6 Other standards ● What links here ● 7 See also ● Related changes ● 8 References ● Upload file ● 9 External links http://en.wikipedia.org/wiki/List_of_ISO_standards (1 of 20)05/12/2008 10:36:09 • List of ISO standards - Wikipedia, the free encyclopedia ● Special pages ● Printable version ISO 1–ISO 999 [edit] ● Permanent link ● ISO 1 Standard reference temperature for geometrical product specification and verification ● Cite this page ● ISO 3 Preferred numbers Languages ● ISO 4 Rules for the abbreviation of title words and titles of publications ● Deutsch ● ISO 7 Pipe threads where pressure-tight joints are made on the threads ● Español ● ISO 9 Information and documentation — Transliteration of Cyrillic characters into Roman characters — Slavic and non-Slavic ● ••••• languages ● Français ● ● •••••• ISO 16:1975 Acoustics — Standard tuning frequency (Standard musical pitch) ● Íslenska ● ISO 31 Quantities and units ● Italiano ● ISO 68-1 Basic profile of metric screw threads ● Nederlands ● ISO 216 paper sizes, e.g. -

Unified SE Feasibility1.Pdf
Cross-domain systems and safety engineering: is it feasible? Composable safety: is it feasible? [email protected] Altreonic NV 17.01.2013 From Deep Space to Deep Sea 1 Content • Intro to safety and its importance • Some results from OPENCOSS project • The issue with the SIL concept • Introducing the ARRL concept • A unified process pattern • Conclusions 17.01.2013 From Deep Space to Deep Sea 2 Some data for thought • 35000 people killed in cars /yr /Europe • 500 people killed in airplanes /yr /world • Why the difference? => many reasons • The Renault Logan is the most reliable car • Why? Less electronics, proven in use design • Is it also safer? • The US is considering to make black boxes a legal requirement in cars • What does this mean? What could be the impact? 17.01.2013 From Deep Space to Deep Sea 3 Systems Engineering vs. Safety Engineering • System = holistic • Real goal is "Trustworthy Systems" • Cfr. Felix Baumgartner almost did not do it because he didn't trust his safe jumpsuit • TRUST = by the user or stakeholders • Safety • Security • Usability (UI) • Privacy • Achieving intended Functionality • Meeting non-functional objectives • Cost, energy, volume, maintainability, scalability, Manufacturability,.. • So why focus on safety? 17.01.2013 From Deep Space to Deep Sea 4 Safety • Safety is the state of being "safe" the condition of being protected against physical, social, spiritual, financial, political, emotional, occupational, psychological, educational or other types or consequences of failure, damage, error, accidents, harm or any other event which could be considered non-desirable. • Safety can also be defined to be the control of recognized hazards to achieve an acceptable level of risk.