Graduate Institute of Applied Linguistics Thesis Approval Sheet
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Grammatical Gender in Hindukush Languages
Grammatical gender in Hindukush languages An areal-typological study Julia Lautin Department of Linguistics Independent Project for the Degree of Bachelor 15 HEC General linguistics Bachelor's programme in Linguistics Spring term 2016 Supervisor: Henrik Liljegren Examinator: Bernhard Wälchli Expert reviewer: Emil Perder Project affiliation: “Language contact and relatedness in the Hindukush Region,” a research project supported by the Swedish Research Council (421-2014-631) Grammatical gender in Hindukush languages An areal-typological study Julia Lautin Abstract In the mountainous area of the Greater Hindukush in northern Pakistan, north-western Afghanistan and Kashmir, some fifty languages from six different genera are spoken. The languages are at the same time innovative and archaic, and are of great interest for areal-typological research. This study investigates grammatical gender in a 12-language sample in the area from an areal-typological perspective. The results show some intriguing features, including unexpected loss of gender, languages that have developed a gender system based on the semantic category of animacy, and languages where this animacy distinction is present parallel to the inherited gender system based on a masculine/feminine distinction found in many Indo-Aryan languages. Keywords Grammatical gender, areal-typology, Hindukush, animacy, nominal categories Grammatiskt genus i Hindukush-språk En areal-typologisk studie Julia Lautin Sammanfattning I den här studien undersöks grammatiskt genus i ett antal språk som talas i ett bergsområde beläget i norra Pakistan, nordvästra Afghanistan och Kashmir. I området, här kallat Greater Hindukush, talas omkring 50 olika språk från sex olika språkfamiljer. Det stora antalet språk tillsammans med den otillgängliga terrängen har gjort att språken är arkaiska i vissa hänseenden och innovativa i andra, vilket gör det till ett intressant område för arealtypologisk forskning. -

(And Potential) Language and Linguistic Resources on South Asian Languages
CoRSAL Symposium, University of North Texas, November 17, 2017 Existing (and Potential) Language and Linguistic Resources on South Asian Languages Elena Bashir, The University of Chicago Resources or published lists outside of South Asia Digital Dictionaries of South Asia in Digital South Asia Library (dsal), at the University of Chicago. http://dsal.uchicago.edu/dictionaries/ . Some, mostly older, not under copyright dictionaries. No corpora. Digital Media Archive at University of Chicago https://dma.uchicago.edu/about/about-digital-media-archive Hock & Bashir (eds.) 2016 appendix. Lists 9 electronic corpora, 6 of which are on Sanskrit. The 3 non-Sanskrit entries are: (1) the EMILLE corpus, (2) the Nepali national corpus, and (3) the LDC-IL — Linguistic Data Consortium for Indian Languages Focus on Pakistan Urdu Most work has been done on Urdu, prioritized at government institutions like the Center for Language Engineering at the University of Engineering and Technology in Lahore (CLE). Text corpora: http://cle.org.pk/clestore/index.htm (largest is a 1 million word Urdu corpus from the Urdu Digest. Work on Essential Urdu Linguistic Resources: http://www.cle.org.pk/eulr/ Tagset for Urdu corpus: http://cle.org.pk/Publication/papers/2014/The%20CLE%20Urdu%20POS%20Tagset.pdf Urdu OCR: http://cle.org.pk/clestore/urduocr.htm Sindhi Sindhi is the medium of education in some schools in Sindh Has more institutional backing and consequent research than other languages, especially Panjabi. Sindhi-English dictionary developed jointly by Jennifer Cole at the University of Illinois Urbana- Champaign and Sarmad Hussain at CLE (http://182.180.102.251:8081/sed1/homepage.aspx). -

Pashto, Waneci, Ormuri. Sociolinguistic Survey of Northern
SOCIOLINGUISTIC SURVEY OF NORTHERN PAKISTAN VOLUME 4 PASHTO, WANECI, ORMURI Sociolinguistic Survey of Northern Pakistan Volume 1 Languages of Kohistan Volume 2 Languages of Northern Areas Volume 3 Hindko and Gujari Volume 4 Pashto, Waneci, Ormuri Volume 5 Languages of Chitral Series Editor Clare F. O’Leary, Ph.D. Sociolinguistic Survey of Northern Pakistan Volume 4 Pashto Waneci Ormuri Daniel G. Hallberg National Institute of Summer Institute Pakistani Studies of Quaid-i-Azam University Linguistics Copyright © 1992 NIPS and SIL Published by National Institute of Pakistan Studies, Quaid-i-Azam University, Islamabad, Pakistan and Summer Institute of Linguistics, West Eurasia Office Horsleys Green, High Wycombe, BUCKS HP14 3XL United Kingdom First published 1992 Reprinted 2004 ISBN 969-8023-14-3 Price, this volume: Rs.300/- Price, 5-volume set: Rs.1500/- To obtain copies of these volumes within Pakistan, contact: National Institute of Pakistan Studies Quaid-i-Azam University, Islamabad, Pakistan Phone: 92-51-2230791 Fax: 92-51-2230960 To obtain copies of these volumes outside of Pakistan, contact: International Academic Bookstore 7500 West Camp Wisdom Road Dallas, TX 75236, USA Phone: 1-972-708-7404 Fax: 1-972-708-7433 Internet: http://www.sil.org Email: [email protected] REFORMATTING FOR REPRINT BY R. CANDLIN. CONTENTS Preface.............................................................................................................vii Maps................................................................................................................ -

ARTICLE Development of a Gold-Standard Pashto Dataset and a Segmentation App Yan Han and Marek Rychlik
ARTICLE Development of a Gold-standard Pashto Dataset and a Segmentation App Yan Han and Marek Rychlik ABSTRACT The article aims to introduce a gold-standard Pashto dataset and a segmentation app. The Pashto dataset consists of 300 line images and corresponding Pashto text from three selected books. A line image is simply an image consisting of one text line from a scanned page. To our knowledge, this is one of the first open access datasets which directly maps line images to their corresponding text in the Pashto language. We also introduce the development of a segmentation app using textbox expanding algorithms, a different approach to OCR segmentation. The authors discuss the steps to build a Pashto dataset and develop our unique approach to segmentation. The article starts with the nature of the Pashto alphabet and its unique diacritics which require special considerations for segmentation. Needs for datasets and a few available Pashto datasets are reviewed. Criteria of selection of data sources are discussed and three books were selected by our language specialist from the Afghan Digital Repository. The authors review previous segmentation methods and introduce a new approach to segmentation for Pashto content. The segmentation app and results are discussed to show readers how to adjust variables for different books. Our unique segmentation approach uses an expanding textbox method which performs very well given the nature of the Pashto scripts. The app can also be used for Persian and other languages using the Arabic writing system. The dataset can be used for OCR training, OCR testing, and machine learning applications related to content in Pashto. -

Language Documentation and Description
Language Documentation and Description ISSN 1740-6234 ___________________________________________ This article appears in: Language Documentation and Description, vol 17. Editor: Peter K. Austin Countering the challenges of globalization faced by endangered languages of North Pakistan ZUBAIR TORWALI Cite this article: Torwali, Zubair. 2020. Countering the challenges of globalization faced by endangered languages of North Pakistan. In Peter K. Austin (ed.) Language Documentation and Description 17, 44- 65. London: EL Publishing. Link to this article: http://www.elpublishing.org/PID/181 This electronic version first published: July 2020 __________________________________________________ This article is published under a Creative Commons License CC-BY-NC (Attribution-NonCommercial). The licence permits users to use, reproduce, disseminate or display the article provided that the author is attributed as the original creator and that the reuse is restricted to non-commercial purposes i.e. research or educational use. See http://creativecommons.org/licenses/by-nc/4.0/ ______________________________________________________ EL Publishing For more EL Publishing articles and services: Website: http://www.elpublishing.org Submissions: http://www.elpublishing.org/submissions Countering the challenges of globalization faced by endangered languages of North Pakistan Zubair Torwali Independent Researcher Summary Indigenous communities living in the mountainous terrain and valleys of the region of Gilgit-Baltistan and upper Khyber Pakhtunkhwa, northern -

Role of English in Afghan Language Policy Planning with Its Impact on National Integration (2001-2010)
ROLE OF ENGLISH IN AFGHAN LANGUAGE POLICY PLANNING WITH ITS IMPACT ON NATIONAL INTEGRATION (2001-2010) By AYAZ AHMAD Area Study Centre (Russia, China & Central Asia) UNIVERSITY OF PESHAWAR (DECEMBER 2016) ROLE OF ENGLISH IN AFGHAN LANGUAGE POLICY PLANNING WITH ITS IMPACT ON NATIONAL INTEGRATION (2001-2010) By AYAZ AHMAD A dissertation submitted to the University of Peshawar in partial fulfilment of the requirements for the degree of Doctor of Philosophy (DECEMBER 2016) i AUTHOR’S DECLARATION I, Mr. Ayaz Ahmad hereby state that my PhD thesis titled “Role of English in Afghan Language Policy Planning with its Impact on National Integration (2001-2010)” is my own work and has not been submitted previously by me for taking any degree from this University of Peshawar or anywhere else in the country/world. At any time if my statement is found to be incorrect even after my graduation the University has the right to withdraw my PhD degree. AYAZ AHMAD Date: December 2016 ii PLAGIARISM UNDERTAKING I solemnly declare that research work presented in the thesis titled “Role of English in Afghan Language Policy Planning with its Impact on National Integration (2001-2010)” is solely my research work with no significant contribution from any other person. Small contribution/help wherever taken has been duly acknowledged and that complete thesis has been written by me. I understand the zero tolerance policy of the Higher Education Commission (HEC) and University of Peshawar towards plagiarism. Therefore I as an Author of the above-titled thesis declare that no portion of my thesis has been plagiarized and any material used as a reference is properly referred/cited. -

The Socio Linguistic Situation and Language Policy of the Autonomous Region of Mountainous Badakhshan: the Case of the Tajik Language*
THE SOCIO LINGUISTIC SITUATION AND LANGUAGE POLICY OF THE AUTONOMOUS REGION OF MOUNTAINOUS BADAKHSHAN: THE CASE OF THE TAJIK LANGUAGE* Leila Dodykhudoeva Institute Of Linguistics, Russian Academy Of Sciences The paper deals with the problem of closely related languages of the Eastern and Western Iranian origin that coexist in a close neighbourhood in a rather compact area of one region of Republic Tajikistan. These are a group of "minor" Pamir languages and state language of Tajikistan - Tajik. The population of the Autonomous Region of Mountainous Badakhshan speaks different Pamir languages. They are: Shughni, Rushani, Khufi, Bartangi, Roshorvi, Sariqoli; Yazghulami; Wakhi; Ishkashimi. These languages have no script and written tradition and are used only as spoken languages in the region. The status of these languages and many other local linguemes is still discussed in Iranology. Nearly all Pamir languages to a certain extent can be called "endangered". Some of these languages, like Yazghulami, Roshorvi, Ishkashimi are included into "The Red Book " (UNESCO 1995) as "endangered". Some of them are extinct. Information on other idioms up to now is not available. These languages live in close cooperation and interaction with the state language of Tajikistan - Tajik. Almost all population of Badakhshan is multilingual or bilingual. The second language is official language of the state - Tajik. This language is used in Badakhshan as the language of education, press, media, and culture. This is the reason why this paper is focused on the status of Tajik language in Republic Tajikistan and particularly in Badakhshan. The Tajik literary language (its oral and written forms) has a long history and rich written traditions. -

TRANSFORMATIONS of HIGH MOUNTAIN PASTORAL STRATEGIES in the PAMIRIAN KNOT Hermann Kreutzmann
TRANSFORMATIONS OF HIGH MOUNTAIN PASTORAL STRATEGIES IN THE PAMIRIAN KNOT Hermann Kreutzmann Abstract Mountain pastoralism in the Pamirian Knot has been significantly transformed from the nineteenth to the twentieth century. The development path has depended on spheres of influence of dominating powers and affiliation to mighty neighbours and, subsequently, to parties in the Cold War. Significant interventions that led to structural changes can be societal transformations, such as those that happened in the Emirate of Bokhara– Tsarist Russia–Soviet Union–Tajikistan sequence, as well as in the framework of establishing Afghan dominance in Badakhshan, in post- revolutionary interventions in Chinese Xinjiang or in the integration of Karakoram communities in the newly created nation-state of Pakistan. Keywords: Central Asia, Pamirs, transformation, mountain pastoralism, combined mountain agriculture As we have seen, the mountains resist the march of history, with its blessings and its burdens, or they accept it only with reluctance. And yet life sees to it that there is constant contact between hill population and lowlands. None of the Mediterranean ranges resembles the impenetrable mountains to be found in the Far East, in China, Japan, Indochina, India, and as far as the Malacca peninsula. Since they have no communication with sea-level civilization, the communities found there are autonomous (Braudel 1972: 41). Introduction Phenomena observed in high mountain regions are regularly interpreted as the result of natural frame conditions rather than as the visible effects of human action and environmental construction. This perception is particularly encountered when mountain regions outside the industrialized world are in focus, as the above quotation from Fernand Braudel proves. -
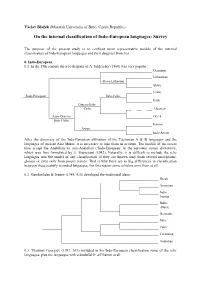
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

THE PHONOLOGY of the VERBAL PHRASE in HINDKO Submitted By
THE PHONOLOGY OF THE VERBAL PHRASE IN HINDKO submitted by ELAHI BAKHSH AKHTAR AWAN FOR THE AWARD OF A DEGREE OF Ph.D. at the UNIVERSITY OF LONDON 1974 ProQuest Number: 10672820 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a com plete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest ProQuest 10672820 Published by ProQuest LLC(2017). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States C ode Microform Edition © ProQuest LLC. ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106- 1346 acknowledgment I wish to express my profound sense of gratitude and indebtedness to my supervisor Dr. R.K. Sprigg. But for his advice, suggestions, constructive criticism and above all unfailing kind ness at all times this thesis could not have been completed. In addition, I must thank my wife Riaz Begum for her help and encouragement during the many months of preparation. CONTENTS Introduction i Chapter I Value of symbols used in this thesis 1 1 .00 Introductory 1 1.10 I.P.A. Symbols 1 1.11 Other symbols 2 Chapter II The Verbal Phrase and the Verbal Word 6 2.00 Introductory 6 2.01 The Sentence 6 2.02 The Phrase 6 2.10 The Verbal Phra.se 7 2.11 Delimiting the Verbal Phrase 7 2.12 Place of the Verbal Phrase 7 2.121 -

Persian, Farsi, Dari, Tajiki: Language Names and Language Policies
University of Pennsylvania ScholarlyCommons Department of Anthropology Papers Department of Anthropology 2012 Persian, Farsi, Dari, Tajiki: Language Names and Language Policies Brian Spooner University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/anthro_papers Part of the Anthropological Linguistics and Sociolinguistics Commons, and the Anthropology Commons Recommended Citation (OVERRIDE) Spooner, B. (2012). Persian, Farsi, Dari, Tajiki: Language Names and Language Policies. In H. Schiffman (Ed.), Language Policy and Language Conflict in Afghanistan and Its Neighbors: The Changing Politics of Language Choice (pp. 89-117). Leiden, Boston: Brill. This paper is posted at ScholarlyCommons. https://repository.upenn.edu/anthro_papers/91 For more information, please contact [email protected]. Persian, Farsi, Dari, Tajiki: Language Names and Language Policies Abstract Persian is an important language today in a number of countries of west, south and central Asia. But its status in each is different. In Iran its unique status as the only official or national language continueso t be jealously guarded, even though half—probably more—of the population use a different language (mainly Azari/Azeri Turkish) at home, and on the streets, though not in formal public situations, and not in writing. Attempts to broach this exclusive status of Persian in Iran have increased in recent decades, but are still relatively minor. Persian (called tajiki) is also the official language ofajikistan, T but here it shares that status informally with Russian, while in the west of the country Uzbek is also widely used and in the more isolated eastern part of the country other local Iranian languages are now dominant. -

Biodiversity Profile of Afghanistan
NEPA Biodiversity Profile of Afghanistan An Output of the National Capacity Needs Self-Assessment for Global Environment Management (NCSA) for Afghanistan June 2008 United Nations Environment Programme Post-Conflict and Disaster Management Branch First published in Kabul in 2008 by the United Nations Environment Programme. Copyright © 2008, United Nations Environment Programme. This publication may be reproduced in whole or in part and in any form for educational or non-profit purposes without special permission from the copyright holder, provided acknowledgement of the source is made. UNEP would appreciate receiving a copy of any publication that uses this publication as a source. No use of this publication may be made for resale or for any other commercial purpose whatsoever without prior permission in writing from the United Nations Environment Programme. United Nations Environment Programme Darulaman Kabul, Afghanistan Tel: +93 (0)799 382 571 E-mail: [email protected] Web: http://www.unep.org DISCLAIMER The contents of this volume do not necessarily reflect the views of UNEP, or contributory organizations. The designations employed and the presentations do not imply the expressions of any opinion whatsoever on the part of UNEP or contributory organizations concerning the legal status of any country, territory, city or area or its authority, or concerning the delimitation of its frontiers or boundaries. Unless otherwise credited, all the photos in this publication have been taken by the UNEP staff. Design and Layout: Rachel Dolores