Bayesian and Conditional Frequentist Hypothesis Testing and Model Selection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam
Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam Roger Barlow The University of Huddersfield August 2018 Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 1 / 34 Lecture 1: The Basics 1 Probability What is it? Frequentist Probability Conditional Probability and Bayes' Theorem Bayesian Probability 2 Probability distributions and their properties Expectation Values Binomial, Poisson and Gaussian 3 Hypothesis testing Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 2 / 34 Question: What is Probability? Typical exam question Q1 Explain what is meant by the Probability PA of an event A [1] Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 3 / 34 Four possible answers PA is number obeying certain mathematical rules. PA is a property of A that determines how often A happens For N trials in which A occurs NA times, PA is the limit of NA=N for large N PA is my belief that A will happen, measurable by seeing what odds I will accept in a bet. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 4 / 34 Mathematical Kolmogorov Axioms: For all A ⊂ S PA ≥ 0 PS = 1 P(A[B) = PA + PB if A \ B = ϕ and A; B ⊂ S From these simple axioms a complete and complicated structure can be − ≤ erected. E.g. show PA = 1 PA, and show PA 1.... But!!! This says nothing about what PA actually means. Kolmogorov had frequentist probability in mind, but these axioms apply to any definition. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 5 / 34 Classical or Real probability Evolved during the 18th-19th century Developed (Pascal, Laplace and others) to serve the gambling industry. -
![Arxiv:1803.00360V2 [Stat.CO] 2 Mar 2018 Prone to Misinterpretation [2, 3]](https://docslib.b-cdn.net/cover/7623/arxiv-1803-00360v2-stat-co-2-mar-2018-prone-to-misinterpretation-2-3-297623.webp)
Arxiv:1803.00360V2 [Stat.CO] 2 Mar 2018 Prone to Misinterpretation [2, 3]
Computing Bayes factors to measure evidence from experiments: An extension of the BIC approximation Thomas J. Faulkenberry∗ Tarleton State University Bayesian inference affords scientists with powerful tools for testing hypotheses. One of these tools is the Bayes factor, which indexes the extent to which support for one hypothesis over another is updated after seeing the data. Part of the hesitance to adopt this approach may stem from an unfamiliarity with the computational tools necessary for computing Bayes factors. Previous work has shown that closed form approximations of Bayes factors are relatively easy to obtain for between-groups methods, such as an analysis of variance or t-test. In this paper, I extend this approximation to develop a formula for the Bayes factor that directly uses infor- mation that is typically reported for ANOVAs (e.g., the F ratio and degrees of freedom). After giving two examples of its use, I report the results of simulations which show that even with minimal input, this approximate Bayes factor produces similar results to existing software solutions. Note: to appear in Biometrical Letters. I. INTRODUCTION A. The Bayes factor Bayesian inference is a method of measurement that is Hypothesis testing is the primary tool for statistical based on the computation of P (H j D), which is called inference across much of the biological and behavioral the posterior probability of a hypothesis H, given data D. sciences. As such, most scientists are trained in classical Bayes' theorem casts this probability as null hypothesis significance testing (NHST). The scenario for testing a hypothesis is likely familiar to most readers of this journal. -
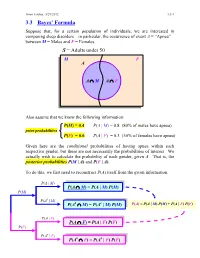
3.3 Bayes' Formula
Ismor Fischer, 5/29/2012 3.3-1 3.3 Bayes’ Formula Suppose that, for a certain population of individuals, we are interested in comparing sleep disorders – in particular, the occurrence of event A = “Apnea” – between M = Males and F = Females. S = Adults under 50 M F A A ∩ M A ∩ F Also assume that we know the following information: P(M) = 0.4 P(A | M) = 0.8 (80% of males have apnea) prior probabilities P(F) = 0.6 P(A | F) = 0.3 (30% of females have apnea) Given here are the conditional probabilities of having apnea within each respective gender, but these are not necessarily the probabilities of interest. We actually wish to calculate the probability of each gender, given A. That is, the posterior probabilities P(M | A) and P(F | A). To do this, we first need to reconstruct P(A) itself from the given information. P(A | M) P(A ∩ M) = P(A | M) P(M) P(M) P(Ac | M) c c P(A ∩ M) = P(A | M) P(M) P(A) = P(A | M) P(M) + P(A | F) P(F) P(A | F) P(A ∩ F) = P(A | F) P(F) P(F) P(Ac | F) c c P(A ∩ F) = P(A | F) P(F) Ismor Fischer, 5/29/2012 3.3-2 So, given A… P(M ∩ A) P(A | M) P(M) P(M | A) = P(A) = P(A | M) P(M) + P(A | F) P(F) (0.8)(0.4) 0.32 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.64 and posterior P(F ∩ A) P(A | F) P(F) P(F | A) = = probabilities P(A) P(A | M) P(M) + P(A | F) P(F) (0.3)(0.6) 0.18 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.36 S Thus, the additional information that a M F randomly selected individual has apnea (an A event with probability 50% – why?) increases the likelihood of being male from a prior probability of 40% to a posterior probability 0.32 0.18 of 64%, and likewise, decreases the likelihood of being female from a prior probability of 60% to a posterior probability of 36%. -

Numerical Physics with Probabilities: the Monte Carlo Method and Bayesian Statistics Part I for Assignment 2
Numerical Physics with Probabilities: The Monte Carlo Method and Bayesian Statistics Part I for Assignment 2 Department of Physics, University of Surrey module: Energy, Entropy and Numerical Physics (PHY2063) 1 Numerical Physics part of Energy, Entropy and Numerical Physics This numerical physics course is part of the second-year Energy, Entropy and Numerical Physics mod- ule. It is online at the EENP module on SurreyLearn. See there for assignments, deadlines etc. The course is about numerically solving ODEs (ordinary differential equations) and PDEs (partial differential equations), and introducing the (large) part of numerical physics where probabilities are used. This assignment is on numerical physics of probabilities, and looks at the Monte Carlo (MC) method, and at the Bayesian statistics approach to data analysis. It covers MC and Bayesian statistics, in that order. MC is a widely used numerical technique, it is used, amongst other things, for modelling many random processes. MC is used in fields from statistical physics, to nuclear and particle physics. Bayesian statistics is a powerful data analysis method, and is used everywhere from particle physics to spam-email filters. Data analysis is fundamental to science. For example, analysis of the data from the Large Hadron Collider was required to extract a most probable value for the mass of the Higgs boson, together with an estimate of the region of masses where the scientists think the mass is. This region is typically expressed as a range of mass values where the they think the true mass lies with high (e.g., 95%) probability. Many of you will be analysing data (physics data, commercial data, etc) for your PTY or RY, or future careers1 . -

The Bayesian Approach to Statistics
THE BAYESIAN APPROACH TO STATISTICS ANTHONY O’HAGAN INTRODUCTION the true nature of scientific reasoning. The fi- nal section addresses various features of modern By far the most widely taught and used statisti- Bayesian methods that provide some explanation for the rapid increase in their adoption since the cal methods in practice are those of the frequen- 1980s. tist school. The ideas of frequentist inference, as set out in Chapter 5 of this book, rest on the frequency definition of probability (Chapter 2), BAYESIAN INFERENCE and were developed in the first half of the 20th century. This chapter concerns a radically differ- We first present the basic procedures of Bayesian ent approach to statistics, the Bayesian approach, inference. which depends instead on the subjective defini- tion of probability (Chapter 3). In some respects, Bayesian methods are older than frequentist ones, Bayes’s Theorem and the Nature of Learning having been the basis of very early statistical rea- Bayesian inference is a process of learning soning as far back as the 18th century. Bayesian from data. To give substance to this statement, statistics as it is now understood, however, dates we need to identify who is doing the learning and back to the 1950s, with subsequent development what they are learning about. in the second half of the 20th century. Over that time, the Bayesian approach has steadily gained Terms and Notation ground, and is now recognized as a legitimate al- ternative to the frequentist approach. The person doing the learning is an individual This chapter is organized into three sections. -

Scalable and Robust Bayesian Inference Via the Median Posterior
Scalable and Robust Bayesian Inference via the Median Posterior CS 584: Big Data Analytics Material adapted from David Dunson’s talk (http://bayesian.org/sites/default/files/Dunson.pdf) & Lizhen Lin’s ICML talk (http://techtalks.tv/talks/scalable-and-robust-bayesian-inference-via-the-median-posterior/61140/) Big Data Analytics • Large (big N) and complex (big P with interactions) data are collected routinely • Both speed & generality of data analysis methods are important • Bayesian approaches offer an attractive general approach for modeling the complexity of big data • Computational intractability of posterior sampling is a major impediment to application of flexible Bayesian methods CS 584 [Spring 2016] - Ho Existing Frequentist Approaches: The Positives • Optimization-based approaches, such as ADMM or glmnet, are currently most popular for analyzing big data • General and computationally efficient • Used orders of magnitude more than Bayes methods • Can exploit distributed & cloud computing platforms • Can borrow some advantages of Bayes methods through penalties and regularization CS 584 [Spring 2016] - Ho Existing Frequentist Approaches: The Drawbacks • Such optimization-based methods do not provide measure of uncertainty • Uncertainty quantification is crucial for most applications • Scalable penalization methods focus primarily on convex optimization — greatly limits scope and puts ceiling on performance • For non-convex problems and data with complex structure, existing optimization algorithms can fail badly CS 584 [Spring 2016] - -

Paradoxes and Priors in Bayesian Regression
Paradoxes and Priors in Bayesian Regression Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Agniva Som, B. Stat., M. Stat. Graduate Program in Statistics The Ohio State University 2014 Dissertation Committee: Dr. Christopher M. Hans, Advisor Dr. Steven N. MacEachern, Co-advisor Dr. Mario Peruggia c Copyright by Agniva Som 2014 Abstract The linear model has been by far the most popular and most attractive choice of a statistical model over the past century, ubiquitous in both frequentist and Bayesian literature. The basic model has been gradually improved over the years to deal with stronger features in the data like multicollinearity, non-linear or functional data pat- terns, violation of underlying model assumptions etc. One valuable direction pursued in the enrichment of the linear model is the use of Bayesian methods, which blend information from the data likelihood and suitable prior distributions placed on the unknown model parameters to carry out inference. This dissertation studies the modeling implications of many common prior distri- butions in linear regression, including the popular g prior and its recent ameliorations. Formalization of desirable characteristics for model comparison and parameter esti- mation has led to the growth of appropriate mixtures of g priors that conform to the seven standard model selection criteria laid out by Bayarri et al. (2012). The existence of some of these properties (or lack thereof) is demonstrated by examining the behavior of the prior under suitable limits on the likelihood or on the prior itself. -

1 Estimation and Beyond in the Bayes Universe
ISyE8843A, Brani Vidakovic Handout 7 1 Estimation and Beyond in the Bayes Universe. 1.1 Estimation No Bayes estimate can be unbiased but Bayesians are not upset! No Bayes estimate with respect to the squared error loss can be unbiased, except in a trivial case when its Bayes’ risk is 0. Suppose that for a proper prior ¼ the Bayes estimator ±¼(X) is unbiased, Xjθ (8θ)E ±¼(X) = θ: This implies that the Bayes risk is 0. The Bayes risk of ±¼(X) can be calculated as repeated expectation in two ways, θ Xjθ 2 X θjX 2 r(¼; ±¼) = E E (θ ¡ ±¼(X)) = E E (θ ¡ ±¼(X)) : Thus, conveniently choosing either EθEXjθ or EX EθjX and using the properties of conditional expectation we have, θ Xjθ 2 θ Xjθ X θjX X θjX 2 r(¼; ±¼) = E E θ ¡ E E θ±¼(X) ¡ E E θ±¼(X) + E E ±¼(X) θ Xjθ 2 θ Xjθ X θjX X θjX 2 = E E θ ¡ E θ[E ±¼(X)] ¡ E ±¼(X)E θ + E E ±¼(X) θ Xjθ 2 θ X X θjX 2 = E E θ ¡ E θ ¢ θ ¡ E ±¼(X)±¼(X) + E E ±¼(X) = 0: Bayesians are not upset. To check for its unbiasedness, the Bayes estimator is averaged with respect to the model measure (Xjθ), and one of the Bayesian commandments is: Thou shall not average with respect to sample space, unless you have Bayesian design in mind. Even frequentist agree that insisting on unbiasedness can lead to bad estimators, and that in their quest to minimize the risk by trading off between variance and bias-squared a small dosage of bias can help. -

Introduction to Bayesian Inference and Modeling Edps 590BAY
Introduction to Bayesian Inference and Modeling Edps 590BAY Carolyn J. Anderson Department of Educational Psychology c Board of Trustees, University of Illinois Fall 2019 Introduction What Why Probability Steps Example History Practice Overview ◮ What is Bayes theorem ◮ Why Bayesian analysis ◮ What is probability? ◮ Basic Steps ◮ An little example ◮ History (not all of the 705+ people that influenced development of Bayesian approach) ◮ In class work with probabilities Depending on the book that you select for this course, read either Gelman et al. Chapter 1 or Kruschke Chapters 1 & 2. C.J. Anderson (Illinois) Introduction Fall 2019 2.2/ 29 Introduction What Why Probability Steps Example History Practice Main References for Course Throughout the coures, I will take material from ◮ Gelman, A., Carlin, J.B., Stern, H.S., Dunson, D.B., Vehtari, A., & Rubin, D.B. (20114). Bayesian Data Analysis, 3rd Edition. Boco Raton, FL, CRC/Taylor & Francis.** ◮ Hoff, P.D., (2009). A First Course in Bayesian Statistical Methods. NY: Sringer.** ◮ McElreath, R.M. (2016). Statistical Rethinking: A Bayesian Course with Examples in R and Stan. Boco Raton, FL, CRC/Taylor & Francis. ◮ Kruschke, J.K. (2015). Doing Bayesian Data Analysis: A Tutorial with JAGS and Stan. NY: Academic Press.** ** There are e-versions these of from the UofI library. There is a verson of McElreath, but I couldn’t get if from UofI e-collection. C.J. Anderson (Illinois) Introduction Fall 2019 3.3/ 29 Introduction What Why Probability Steps Example History Practice Bayes Theorem A whole semester on this? p(y|θ)p(θ) p(θ|y)= p(y) where ◮ y is data, sample from some population. -

A Widely Applicable Bayesian Information Criterion
JournalofMachineLearningResearch14(2013)867-897 Submitted 8/12; Revised 2/13; Published 3/13 A Widely Applicable Bayesian Information Criterion Sumio Watanabe [email protected] Department of Computational Intelligence and Systems Science Tokyo Institute of Technology Mailbox G5-19, 4259 Nagatsuta, Midori-ku Yokohama, Japan 226-8502 Editor: Manfred Opper Abstract A statistical model or a learning machine is called regular if the map taking a parameter to a prob- ability distribution is one-to-one and if its Fisher information matrix is always positive definite. If otherwise, it is called singular. In regular statistical models, the Bayes free energy, which is defined by the minus logarithm of Bayes marginal likelihood, can be asymptotically approximated by the Schwarz Bayes information criterion (BIC), whereas in singular models such approximation does not hold. Recently, it was proved that the Bayes free energy of a singular model is asymptotically given by a generalized formula using a birational invariant, the real log canonical threshold (RLCT), instead of half the number of parameters in BIC. Theoretical values of RLCTs in several statistical models are now being discovered based on algebraic geometrical methodology. However, it has been difficult to estimate the Bayes free energy using only training samples, because an RLCT depends on an unknown true distribution. In the present paper, we define a widely applicable Bayesian information criterion (WBIC) by the average log likelihood function over the posterior distribution with the inverse temperature 1/logn, where n is the number of training samples. We mathematically prove that WBIC has the same asymptotic expansion as the Bayes free energy, even if a statistical model is singular for or unrealizable by a statistical model. -

Part IV: Monte Carlo and Nonparametric Bayes Outline
Part IV: Monte Carlo and nonparametric Bayes Outline Monte Carlo methods Nonparametric Bayesian models Outline Monte Carlo methods Nonparametric Bayesian models The Monte Carlo principle • The expectation of f with respect to P can be approximated by 1 n E P(x)[ f (x)] " # f (xi ) n i=1 where the xi are sampled from P(x) • Example: the average # of spots on a die roll ! The Monte Carlo principle The law of large numbers n E P(x)[ f (x)] " # f (xi ) i=1 Average number of spots ! Number of rolls Two uses of Monte Carlo methods 1. For solving problems of probabilistic inference involved in developing computational models 2. As a source of hypotheses about how the mind might solve problems of probabilistic inference Making Bayesian inference easier P(d | h)P(h) P(h | d) = $P(d | h ") P(h ") h " # H Evaluating the posterior probability of a hypothesis requires considering all hypotheses ! Modern Monte Carlo methods let us avoid this Modern Monte Carlo methods • Sampling schemes for distributions with large state spaces known up to a multiplicative constant • Two approaches: – importance sampling (and particle filters) – Markov chain Monte Carlo Importance sampling Basic idea: generate from the wrong distribution, assign weights to samples to correct for this E p(x)[ f (x)] = " f (x)p(x)dx p(x) = f (x) q(x)dx " q(x) n ! 1 p(xi ) " # f (xi ) for xi ~ q(x) n i=1 q(xi ) ! ! Importance sampling works when sampling from proposal is easy, target is hard An alternative scheme… n 1 p(xi ) E p(x)[ f (x)] " # f (xi ) for xi ~ q(x) n i=1 q(xi ) n p(xi -

Statistical Inference: Paradigms and Controversies in Historic Perspective
Jostein Lillestøl, NHH 2014 Statistical inference: Paradigms and controversies in historic perspective 1. Five paradigms We will cover the following five lines of thought: 1. Early Bayesian inference and its revival Inverse probability – Non-informative priors – “Objective” Bayes (1763), Laplace (1774), Jeffreys (1931), Bernardo (1975) 2. Fisherian inference Evidence oriented – Likelihood – Fisher information - Necessity Fisher (1921 and later) 3. Neyman- Pearson inference Action oriented – Frequentist/Sample space – Objective Neyman (1933, 1937), Pearson (1933), Wald (1939), Lehmann (1950 and later) 4. Neo - Bayesian inference Coherent decisions - Subjective/personal De Finetti (1937), Savage (1951), Lindley (1953) 5. Likelihood inference Evidence based – likelihood profiles – likelihood ratios Barnard (1949), Birnbaum (1962), Edwards (1972) Classical inference as it has been practiced since the 1950’s is really none of these in its pure form. It is more like a pragmatic mix of 2 and 3, in particular with respect to testing of significance, pretending to be both action and evidence oriented, which is hard to fulfill in a consistent manner. To keep our minds on track we do not single out this as a separate paradigm, but will discuss this at the end. A main concern through the history of statistical inference has been to establish a sound scientific framework for the analysis of sampled data. Concepts were initially often vague and disputed, but even after their clarification, various schools of thought have at times been in strong opposition to each other. When we try to describe the approaches here, we will use the notions of today. All five paradigms of statistical inference are based on modeling the observed data x given some parameter or “state of the world” , which essentially corresponds to stating the conditional distribution f(x|(or making some assumptions about it).