Dialect Levelling in Finnish: a Universal Speech Attribute Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ajan Jäljet -Kohteista Löytyy Paljon Viikko Heinäkuussa Tuo Vilskettä Rauman Kaupunkikuvaan
ELÄVÄÄ HISTORIAA KIVIKAUDELTA PURJELAIVA-AIKAAN RAUMA, EURA, EURAJOKI, SÄKYLÄ, KÖYLIÖ AJAN JÄLJET -SYMBOLIT MUSEO MUINAISJÄÄNNÖS MATKAILUNÄHTÄVYYS KAHVILA RUOKAILU NÄYTTELY MYYNTIPISTE MAJOITUS MAAILMANPERINTÖKOHDE Kivikausi (n. 4200 - 1500 eKr) Rautakausi (n. 500 eKr - 1155 jKr) 1500 - 1900 luku Euran Hinnerjoki, Honkilahti, Euran Luistari, Käräjämäki Vanha Rauma, Vuojoen Kartano Kauttua ja Kiukaisten Kulttuuri ja Kauttuan Linnavuori ja Irjanteen kirkko Eurajoella sekä Kauttuan Ruukinpuisto Eurassa ESIHISTORIA KESKIAIKA UUSI AIKA 1155 jKr 1500 500 eKr 1500 eKr Pronssikausi (n. 1500 - 500 eKr) Keskiaika (n. 1155 - 1500) Kodisjoki, Euran Panelia, Rauman Köyliön Kirkkosaari ja Kirkkokari, Vasaraisten Kylmänkorvenkallio Pyhän Henrikin tie ja Vanha Rauma ja Lapin Sammallahdenmäki Rauman seudun historia herää eloon myös monissa alueen tapahtumissa. Euran Muinaisaikaan -tapahtuma kesäkuussa tutustuttaa viikinkien elämään ja Pitsi- Ajan Jäljet -kohteista löytyy paljon viikko heinäkuussa tuo vilskettä Rauman kaupunkikuvaan. Elokuussa vietetään kiintoisaa tekemistä myös lapsille! Lapissa löylypäiviä sekä pimenevän kesäillan Suviehtoota Vuojoen kartanolla. Li- Katso lisää esitteen takasivulta. sätietoja näistä ja monista muista Rauman seudun historia- ja kulttuuritapahtu- mista löydät osoitteesta www.visitrauma.fi. terveisin: Murre ESIHISTORIALLISIA VIERAILUKOHTEITA Esihistoriaksi kutsutaan aikaa, jolta ei ole kirjallisia lähteitä. Niinpä muinaisjäännökset ja esinelöydöt ovat tutkijoiden ainoat lähteet. Esihistoria jaetaan kivi-, pronssi- ja rautakauteen. -

Pohjanlahden Rantatie Pohjanlahden Rantatie
POHJANLAHDEN RANTATIE Satakuntalaisten maaseutukylien kautta Pohjanlahden rannikkoa seuraten kulkee vanha maantie. Rantatie on jo myöhäiskeskiajalla yhdistänyt toisiinsa Varsinais-Suomen ja Pohjanmaan kulkien Pohjanlahden ympäri Ruotsin eteläosiin asti. Osittain rantatietä pitkin kulki keskiajalla Turun ja Korsholman linnojen välinen yhteydenpito ja 1600-luvulta lähtien postitalonpojat kuljettivat postia tiellä osittaista verovapautta vastaan. Rantatien varrella tai sen lähiympäristössä on useita valtakunnallisesti merkittäviä kulttuurihistoriallisia ympäristöjä, arvokkaita maisema-alueita sekä luontokohteita, joihin vanha tie ja tuleva Selkämeren kansallispuisto yhdessä muodostavat luonnollisen yhteyden. Kansi: Henri Terho Kannen kuva: Jyrki Toivanen, Lankosken museosilta, Merikarvia. 2008 Kulttuurituotannon ja maisemantutkimuksen laitoksen julkaisuja XV ISBN 978-951-29-3950-3 POHJANLAHDENPOHJANLAHDEN RANTATIERANTATIE RatsupolustaRatsupolusta rannikonrannikon matkailutieksmatkailutieksii POHJANLAHDEN RANTATIE Ratsupolusta rannikon matkailutieksi Kulttuurituotannon ja maisemantutkimuksen laitoksen julkaisuja XV Pori 2009 © 2009 Kirjoittajat Turun yliopisto Kulttuurituotannon ja maisemantutkimuksen laitoksen julkaisuja XV http://www.hum.utu.fi/satakunta/ Toimittajat Maunu Häyrynen ja Mikael Lähteenmäki Ohjausryhmä Pentti Ala-Luopa, Merikarvian kunta Elisa Bruk, Turun yliopisto Pirjo Ihamäki, Turun yliopisto Pirjo Jaakkola, Eurajoen kunta Tomi Kuusimäki, SAMK Mikael Lähteenmäki, Turun yliopisto Ilmo Marttila, Noormarkun kunta Kari Ojalahti, -

Tilastokeskus 1.1.1984 Kuntanumerointi 1984
Tilastoarkisto Statistikarkivefc TILASTOKESKUS # 1.1.1984 KUNTANUMEROINTI 1984 Lukijalle .............................................................. 1 Taulu 1. Läänit, seutukaava-alueet, kuntamuoto ... 2 ■ 2. Kunnat aakkosjärjestyksessä ............. 3 * 3. Kunnat lääneittäin ....................... 12 * 4. Kunnat seutukaava-alueittaln ............ 23 * 5. Kunnat tilastoalueittain ................. 34 Liite 1. Lakkautetut kunnat vuodesta 1959 lähtien. 40 Liite 2. Kuntamuodossa tapahtuneet muutokset sekä kuntien nimenmuutokset (suomenkiel. nimi) vuodesta 1960 lähtien .................... 43 KUNTANUMEROINTI 1984 LUKIJALLE Tilastokeskus ylläpitää kuntaluokitusrekisterlä, joka sisältää tietoja julkisessa hallinnossa eniten käytetyistä aluejaoista. Tästä kuntaluokitusrekisteristä tuotetaan vuosit tain tämä KUNTANUMEROINTI-vihkonen, joka sisältää nykyisellään luettelot kunnista aakkosjärjestyksessä (taulu 2) lääneittäin (taulu 3) seutukaava-aluelttain (taulu 4) tilastoalueittain (taulu 5) Liitteinä ovat luettelot lakkautetuista kunnista sekä kuntamuo dossa tapahtuneista muutoksista ja nimenmuutoksista (suomenkielinen nimi). Kuntatunnuksena käytetään aikaisemmin Kansaneläkelaitoksen, nykyisin Väestörekisterikeskuksen antamaa kolminumeroista kuntatunnusta. Niin kutsuttu "TP:n kuntakoodi", joka myös esiintyy julkaisussa, tarkoittaa vanhaa Tilastollisen Päätoimi ston kuntakoodia. Tilastotoimessa sen käytöstä on luo vuttu ja siirrytty Valtion tilastotoimen kehittämisohjelman mukaisesti käyttämään alueluokituksina tilastoaluejaon sijasta pääasiassa -

Pests of Cultivated Plants in Finland
ANNALES AGRICULTURAE FE,NNIAE Maatalouden tutkimuskeskuksen aikakauskirja Vol. 1 1962 Supplementum 1 (English edition) Seria ANIMALIA NOCENTIA N. 5 — Sarja TUHOELÄIMET n:o 5 Reprinted from Acta Entomologica Fennica 19 PESTS OF CULTIVATED PLANTS IN FINLAND NIILO A.VAPPULA Agricultural Research Centre, Department of Pest Investigation, Tikkurila, Finland HELSINKI 1965 ANNALES AGRICULTURAE FENNIAE Maatalouden tutkimuskeskuksen aikakauskirja journal of the Agricultural Researeh Centre TOIMITUSNEUVOSTO JA TOIMITUS EDITORIAL BOARD AND STAFF E. A. jamalainen V. Kanervo K. Multamäki 0. Ring M. Salonen M. Sillanpää J. Säkö V.Vainikainen 0. Valle V. U. Mustonen Päätoimittaja Toimitussihteeri Editor-in-chief Managing editor Ilmestyy 4-6 numeroa vuodessa; ajoittain lisänidoksia Issued as 4-6 numbers yearly and occasional supplements SARJAT— SERIES Agrogeologia, -chimica et -physica — Maaperä, lannoitus ja muokkaus Agricultura — Kasvinviljely Horticultura — Puutarhanviljely Phytopathologia — Kasvitaudit Animalia domestica — Kotieläimet Animalia nocentia — Tuhoeläimet JAKELU JA VAIHTOTI LAUKS ET DISTRIBUTION AND EXCHANGE Maatalouden tutkimuskeskus, kirjasto, Tikkurila Agricultural Research Centre, Library, Tikkurila, Finland ANNALES AGRICULTURAE FENNIAE Maatalouden tutkimuskeskuksen aikakauskirja 1962 Supplementum 1 (English edition) Vol. 1 Seria ANIMALIA NOCENTIA N. 5 — Sarja TUHOELÄIMET n:o 5 Reprinted from Acta Entomologica Fennica 19 PESTS OF CULTIVATED PLANTS IN FINLAND NIILO A. VAPPULA Agricultural Research Centre, Department of Pest Investigation, -
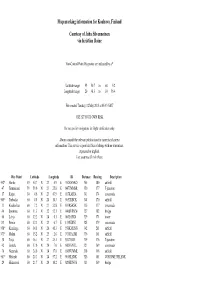
Map Marking Information for Kauhava, Finland Courtesy of Juha
Map marking information for Kauhava,Finland Courtesy of Juha Silvennoinen via Kristian Roine Non-Control Point Waypoints are indicated by a * Latitude range: 59 50.7 to 68 5.2 Longitude range: 20 48.3 to 30 56.4 File created Tuesday,12May 2015 at 05:35 GMT USE ATYOUR OWN RISK Do not use for navigation, for flight verification only. Always consult the relevant publications for current and correct information. This service is provided free of charge with no warrantees, expressed or implied. User assumes all risk of use. WayPoint Latitude Longitude ID Distance Bearing Description 952* Hanko5950.7 N 23 4.9 E952HANKO365 180 airfield 47 Tammisaari 59 59.0 N 23 25.8 E 047TMMSR 350 177 T-junction 17 Karjaa 60 4.6 N2343.9 E 017KARJA341 174 crossroads 965* Torbacka 60 4.8 N 24 10.3 E 965TRBCK 344 170 airfield 33 Kisakeskus 60 7.2 N 23 22.8 E 033KSKSK 335 177 crossroads 46 Stromma 60 11.3 N 22 52.1 E 046STRMM 327 182 bridge 60 Lohja 60 12.2 N 24 0.1 E060LOHJA329 171 tower 133 Pernio 60 12.3 N 23 6.7 E133PERNI 325 179 crossroads 958* Kumlinge 60 14.8 N 20 48.3 E 958KMLNG 342 201 airfield 973* Malmi 60 15.2 N 25 2.6 E973MALMI 336 161 airfield 34 Toija 60 16.1 N 23 25.1 E 034TOIJA319 176 T-junction 42 Ventela 60 17.0 N 24 7.0 E042VENTL 321 169 crossroads 30 Nummela 60 20.0 N 24 17.8 E 030NUMML 318 168 airfield 901* Helsinki 60 20.3 N 24 57.2 E 901HLSNK 326 161 VOR/DME HELSNK 29 Hiidenvesi 60 21.7 N 24 10.2 E 029HDNVS 313 169 bridge Map marking information for Kauhava, Finland, page 2 WayPoint Latitude Longitude ID Distance Bearing Description 69 Saukkola -

TABELL 7 – TABLE 7 Lakkautetut Kunnat Lakkauttamisjärjestyksessä Upplösta Kommuner I Den Ordning De Upplösts Abolished Municipalities in Order of Abolition
TAULUKKO 7 – TABELL 7 – TABLE 7 Lakkautetut kunnat lakkauttamisjärjestyksessä Upplösta kommuner i den ordning de upplösts Abolished municipalities in order of abolition Lakkautettu kunta Liitoskunta / Liitoskunnat Upplöst kommun Inkorporerad i kommun / kommuner Abolished municipality Ajankohta Annexed municipality / municipalities 994 Pirkkala 01.01.1922 536 994 Pirkkala 01.01.1922 604 321 Kyyrölä 01.01.1934 497 013 Antrea 19.09.1944 - 080 Harlu 19.09.1944 - 087 Heinjoki 19.09.1944 - 093 Hiitola 19.09.1944 - 147 Impilahti 19.09.1944 - 162 Jaakkima 19.09.1944 - 168 Johannes 19.09.1944 - 215 Kanneljärvi 19.09.1944 - 234 Kaukola 19.09.1944 - 258 Kirvu 19.09.1944 - 264 Kivennapa 19.09.1944 - 268 Koivisto 19.09.1944 - 269 Koiviston mlk – Koivisto lk 19.09.1944 - 296 Kuolemajärvi 19.09.1944 - 302 Kurkijoki 19.09.1944 - 313 Käkisalmi – Kexholm 19.09.1944 - 314 Käkisalmi mlk – Kexholms lk 19.09.1944 - 397 Lahdenpohja 19.09.1944 - 412 Lavansaari 19.09.1944 - 437 Lumivaara 19.09.1944 - 488 Metsäpirtti 19.09.1944 - 497 Muolaa 19.09.1944 - 591 Petsamo 19.09.1944 - 628 Pyhäjärvi Vi – Pyhäjärvi Vib l 19.09.1944 - 690 Rautu 19.09.1944 - 703 Ruskeala 19.09.1944 - 706 Räisälä 19.09.1944 - 731 Sakkola 19.09.1944 - 733 Salmi 19.09.1944 - 745 Seiskari 19.09.1944 - 757 Soanlahti 19.09.1944 - 763 Sortavala 19.09.1944 - 764 Sortavalan mlk – Sortavala lk 19.09.1944 - 767 Suistamo 19.09.1944 - 773 Suojärvi 19.09.1944 - 780 Suursaari 19.09.1944 - 843 Terijoki 19.09.1944 - 862 Tytärsaari 19.09.1944 - 897 Uusikirkko 19.09.1944 - 910 Valkjärvi 19.09.1944 - 929 Viipuri -

Arkisto TILASTOLLINEN PÄÄTOIMISTO 23.8.1967
Arkisto TILASTOLLINEN PÄÄTOIMISTO 23.8.1967 Kuntanumerolnti lääneittäin Kuntanumero Lääni UUDENMAAN LÄÄNI 0 11 00 0 HELSINKI 0 11 10 7 HANKO 0 11 14 4 HYVINKÄÄ 0 11 15 0 j ä rvenpää 0 11 11 2 LOVI ISA 0 11 12 1 PORVOO 0 11 13 7 TAMMISAARI 0 11 27 0 ESPOO 0 11 22 7 KARJAA 0 11 23 5 KARKKILA 0 11 24 0 KAUNIAINEN 0 11 25 0 KERAVA 0 11 26 6 LOHJA 0 15 30 1 ARTJÄRVI 0 11 30 3 ASKOLA 0 11 31 7 BROMARV 0 11 33 0 HELSINGIN MLK 0 11 34 4 HYVINKÄÄN MLK 0 11 35 7 INKOO 0 11 36 7 k a r j a a n MLK 0 11 37 6 KARJALOHJA 0 11 38 7 kirkkonummi 0 11 39 2 LAPINJÄRVI 0 11 40 2 LILJENDAL 0 11 41 6 LOHJAN MLK 0 11 42 2 MYRSKYLÄ 0 11 43 3 Mäntsälä 0 11 44 6 NUMMI 0 11 45 0 NURMIJÄRVI 0 15 49 1 ORIMATTILA 0 11 46 2 PERNAJA 0 11 47 7 POHJA 0 11 48 3 PORNAINEN 0 11 49 1 PORVOON MLK 0 11 50 3 PUKKILA 0 11 51 5 PUSULA 0 11 52 5 PYHÄJÄRVI UL 0 11 53 2 RUOTSINPYHTÄÄ 0 11 54 6 SAMMATTI 0 11 55 1 SIPOO 0 11 56 7 SIUNTIO 0 11 57 7 SNAPPERTUNA - 2 - o 11 58 7 TAMMISAAREN MLK o 11 59 7 TENHOLA o 11 60 0 TUUSULA o 11 61 0 VIHTI TURUN JA PORIN LÄÄNI 1 12 00 0 TURKU 1 12 10 0 NAANTALI 1 14 10 0 PORI 1 14 11 1 RAUMA 1 12 12 1 SALO 1 12 11 3 UUSIKAUPUNKI 1 16 11 5 VAMMALA 1 16 20 6 IKAALINEN 1 14 20 2 KANKAANPÄÄ 1 12 20 2 LOIMAA 1 12 21 4 PARAINEN 1 12 22 0 RAISIO 1 14 30 0 AHLAINEN 1 12 30 2 ALASTARO 1 12 32 0 ASKAINEN 1 12 33 O AURA 1 12 34 4 DRAGSFJÄRD 1 14 31 1 EURA 1 14 32 1 EURAJOKI 1 12 35 1 HALIKKO 1 14 33 O HARJAVALTA 1 12 36 6 HIITTINEN 1 14 34 1 HINNERJOKI 1 14 35 2 HONKAJOKI 1 14 36 1 HONKILAHTI 1 12 37 6 HOUTSKARI 1 14 37 1 HUITTINEN 1 16 33 0 HÄMEENKYRÖ 1 16 -

Bebyggelsehistorisk Tidskrift
Bebyggelsehistorisk tidskrift Nordic Journal of Settlement History and Built Heritage ! ! ! ! ! ! "#$%&'!! ()*$&+!,#-./0!1)'2&!3)+&! 4)$*.! 56.**)+78!9+:!'.*9$.:!8$'#;$#'.8!)+!<'.%)8$&');!=9)+*9+:! >)+*9+:! ?88#.! @@! A.9'!&B!1#C*);9$)&+! DEEF! 197.8! D@@GDHI! ?JJ,!K@LEMIN@L! ?JJ,!&+*)+.!IKKIM@NDI!! 666OC.CP77.*8.%)8$&')9O&'7! ! ! Dwellings and related struetures in prehistoric mainland Finland By Milton Nunez and Pirjo Uino Despite an early interest in the subject', organized farmers. The location of most sites mentioned here efforts to learn about prehistoric building structu¬ can be seen in the map of Figure 1. res in mainland Finland did not begin to materiali¬ ze until 20-25 years ago. Apparently excavating tbe obvious grave mounds was more rewarding than searching for indiscernible building remains, which generally were investigated only after acci¬ dental discovery. In contrast Finnish archaeologists sought the more conspicuous Metal Age founda¬ tions on the Åland Islands^ and the Stone Age dwelling depressions in the mainland after their discovery in 1950. The 1970s marked a turning point with C.F. Meinander’s project on Finnish Iron Age society, which included the investigation of building foundations and demonstrated that there was much to gain from the systematic inve- 4 stigation of prehistoric building remains. This paper attempts to summarize what we have learned from this incipient branch of archaeological re¬ search in Finland. For the sake of presentation the known prehistoric building forms have been somewhat arbitrarily grouped into two major cate¬ gories according to lifeways and chronology: Stone Age and Metal Age forms. The first would be mainly related to hunter-gatberers, the latter to Figure 1. -

Onomasticon of Levänluhta and Käldamäki Region
SUSA/JSFOu 96, 2017 Pauli Rahkonen (Helsinki) Onomasticon of Levänluhta and Käldamäki region The water burials in the Levänluhta (the Isokyrö parish) and Käldamäki (the former Vöyri parish) sites in Ostrobothnia have been a great mystery for the scholars because of their unique character. The dating of the burials is 5th–8th centuries AD. Similar buri- als are not known elsewhere in Finland or in its neighbouring areas. The results of an onomastic study show that the earliest Finnish maritime toponyms appeared in the 9th century and the earliest Swedish toponyms in the late 13th century. This means that the burials most probably were not conducted by Finnish or Swedish speaking populations. In Vöyri, no obvious Saami toponyms are found, but in Isokyrö, a few Saami names can be recognized. Baltic toponyms are completely unknown. The words behind the names of the largest local rivers could possibly be derived from Proto-Finno-Permian, but alternatively it is possible that they represent obscure names of Paleo-European origin. Thus, the most probable linguistic groups behind the water burials might be speakers of the West Uralic x-language or Paleo-European. 1. Introduction The ethno-linguistic background of the population who practised water burials in Levänluhta in the Isokyrö parish and in Käldamäki in the former Vöyri parish during the 5th–8th centuries AD (Wessman 2009: 81; Formisto 1993: 42) has been a mys- tery for researchers for several decades. This type of burial is unknown elsewhere in Finland and the surrounding countries. The most similar burial type, so called bog-burials, is found in Denmark, but even these are not comparable with the burials in Levänluhta and Käldamäki (Wessman 2009: 91 and attached literature). -

Ala - S a T a K U N N a N K I H L a K U N T A
171 0 ALA - S A T A K U N N A N K I H L A K U N T A E U R A N H A L L I N T O P I T Ä J Ä Ylinen kolmannes Lellaisten yökunta Yläneen kirkonkylän jakokunta LELLAINEN Lellasby mk 1540-52, Lellasby nebb 1547, kym 1548, Lellais mk 1543, nebb 1552-54, Lellaijs mk 1554 Kylä maksoi kymmenykset ruotsalaisen vero-oikeuden mukaan. Laamanni Hartvik Jaakonpoika on 10.3.1461 Euran, Köyliön ja Säkylän käräjillä antanut tuomion Mynämäen Laajoen ja Euran Lellaisten välisessä rajariidassa. Rajapaikoiksi siinä hyväksyttiin Pereierwe och Kaijanåija. Häviäjiä olivat Lellaisten neljä isäntää, jotka saivat kukin kolmen markan sakon vahingonteosta Laajoen kalavesillä (nimeltä mainitut isännät on alla sijoitettu taloihinsa nimiyhtäläisyyksien perusteella). Tämä tuomio on ollut muistiinpantuna Hartvik Jaakonpojan tuomiokirjassa, jota 1500- luvulla säilytettiin Flemingien rälssisäterissä Sundholmassa. (Uuttakaupunkia). Se haettiin sieltä esiin, kun sama rajariita oli virinnyt uudelleen (ks. alla talo III). Jutussa mentiin kuninkaisiin, ja suoritetun katselmuksen mukaan vuoden 1461 tuomio vahvistettiin Tukholmassa 7.111567. Silloin laadittuun kirjeeseen jäljennettiin myös Hartvikin tuomiomuistiinpano. Samalla hylättiin Lellaisten vaatima Purokosken rajapaikka. RA Tidö samlingen, BFH IV 356. Vuoden 1461 muistiinpanossa ei ole kuitenkaan ensimmäisen kerran tietoja saman tienoon rajoista. Valtaneuvos ja laamanni Eerik Flemingin leski Hebba Sparre on vuosien 1548-60 välillä jäljennyttänyt miehensä maakirjaan Klaus Lydekenpojan tuomiokirjassa olleen merkinnän Yläneen ympärysrajoista, jotka on vahvistettu käräjillä 3.9.1432. Pyhäjärveltä raja lähtee sen mukaan Haukkavuoresta kohti lounasta Peräjärvenvuoreen ja sieltä Purokosken kautta Haganristiin (så till Hauckauar öffver tresketh, så till Perenierffuienwori, så till Purokoski, så till Hagaristi jne). VA Eerik Flemingin maakirja, pain. -

Webinaari 210121 Kaalin Ja Porkkanan Tuholaistarkkailu Ja
UUSIA MENETELMIÄ KASVINTUHOOJIEN TARKKAILUUN JA TULOKSIA KAALIKASVIEN JA HALLINTAAN –WEBINAARI 21.1.2021 9.30 Tilaisuuden avaus Marja Tuononen, ProAgria Länsi-Suomi PORKKANAN UUSISTA TUHOLAISTEN 9.45 Lanttusääski – tulokastuhooja, Marja Kallela, ProAgria Etelä-Suomi TARKKAILUMENETELMISTÄ 10.00 Kaalikasvien ja porkkanan tuholaisten tarkkailumenetelmät, Michaela Kontu, ProAgria Länsi-Suomi 10.30 Tuloksia kaalikasvien ja porkkanan uusista tarkkailumenetelmistä Marja Tuononen, ProAgria Länsi-Suomi Uusia menetelmiä kasvintuhoojien tarkkailuun ja hallintaan 10.50 Tauko 11.00 Olosuhteiden vaikutus porkkanakemppivioitukseen ja Webinaari 21.1.2021 Liberibakteerin esiintymiseen, Anne Nissinen, Luke 11.15 Pajunkuori perunaruton torjunnassa, Marika Rastas, Luke Marja Tuononen, ProAgria Länsi-Suomi 11.45 Keskustelua ja loppuyhteenveto, Marja Tuononen, ProAgria Länsi-Suomi 12.00 Tilaisuus päättyy Kuva: Marja Tuononen 2 Tuholaistarkkailulla on pitkät perinteet Satakunnassa, Varsinais-Suomessa ja Hämeessä LANTTUSÄÄSKI- MTT:n Hämeen tutkimusasemalla Pälkäneellä tarkkailua on alettu kokeilla vuodesta 1993 lähtien TULOKSET 2020 Satakunnassa ja Varsinais-Suomessa on aloitettu systemaattinen tarkkailu vuonna 1997 MTT:n ja ProAgria Satakunnan yhteishankkeena tarkkailussa oli lähinnä porkkana, lanttu ja kaalit Hämeessä maksullinen tarkkailu alkoi vuonna 2000 30.5.2018 Eura Osa tiloista on ollut mukana alusta lähtien 2007 – 2014 tarkkailu oli ympäristökorvauksen piirissä, joten tarkkailuun tulivat em. Lisäksi mm. sipulit, punajuuri, mansikka, vadelma, herukat, -
Kunnat Ja Kuntapohjaiset Aluejaot 2008
Tilastokeskus Käsikirjoja 28 statistikcentralen H a ndböcker Statistics Finland H andbooks Kunnat ja kuntapohjaiset aluejaot 2008 Kommuner och kommunbaserade indelningar 2008 Municipalities and Regional Divisions Based on Municipalities 2008 Tilastokeskus Käsikirjoja 28 Statistikcentralen Handböcker Statistics Finland u .. Fiandbooks Kunnat ja kuntapohjaiset aluejaot 2008 Kommuner och kommunbaserade indelningar 2008 Municipalities and Regional Divisions Based on Municipalities 2008 Helsinki - Helsingfors 2008 Tiedustelut - Förfrägningar - Inquiries: Kari Seppä Saija Ylönen (09) 17 341 sähköposti: [email protected] www.tilastokeskus.fi/luokitukset © 2008 Tilastokeskus - Statistikcentraien - Statistics Finland Tietoja lainattaessa lähteenä on mainittava Tilastokeskus. Uppgifterna fär länas med uppgivande av Statistikcentraien som källa. Quoting is encouraged provided Statistics Finland is acknowledged as the source. ISSN 0355-2063 = Käsikirjoja ISBN 978-952-467-777-6 Multiprint Oy, Flelsinki 2008 Kunnat ja kuvapohjaiset aluejaot 2008 Alkusanat Kunnat ja kuvapohjaiset aluejaot -jul 2008kitusjärjestelmä soveltuu käytettäväksi myös kaisussa esitellään yleisimmät tilastoissa käy muissa tietojärjestelmissä. tettävät kuntapohjaiset alueluokitukset. Käsi Alueluokituksia sekä tätä julkaisua koske kirja sisältää kuntajaon lisäksi seutukunnat, via tiedusteluja ja kehittämisehdotuksia otta maakunnat, suuralueet, läänit, työvoima- ja vat vastaan Kari Seppä, p. (09) 1734 3572, ja elinkeinokeskukset, tilastolliset työssäkäynti Saija Ylönen,