Nosql Databases: Yearning for Disambiguation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Smart Methods for Retrieving Physiological Data in Physiqual
University of Groningen Bachelor thesis Smart methods for retrieving physiological data in Physiqual Marc Babtist & Sebastian Wehkamp Supervisors: Frank Blaauw & Marco Aiello July, 2016 Contents 1 Introduction 4 1.1 Physiqual . 4 1.2 Problem description . 4 1.3 Research questions . 5 1.4 Document structure . 5 2 Related work 5 2.1 IJkdijk project . 5 2.2 MUMPS . 6 3 Background 7 3.1 Scalability . 7 3.2 CAP theorem . 7 3.3 Reliability models . 7 4 Requirements 8 4.1 Scalability . 8 4.2 Reliability . 9 4.3 Performance . 9 4.4 Open source . 9 5 General database options 9 5.1 Relational or Non-relational . 9 5.2 NoSQL categories . 10 5.2.1 Key-value Stores . 10 5.2.2 Document Stores . 11 5.2.3 Column Family Stores . 11 5.2.4 Graph Stores . 12 5.3 When to use which category . 12 5.4 Conclusion . 12 5.4.1 Key-Value . 13 5.4.2 Document stores . 13 5.4.3 Column family stores . 13 5.4.4 Graph Stores . 13 6 Specific database options 13 6.1 Key-value stores: Riak . 14 6.2 Document stores: MongoDB . 14 6.3 Column Family stores: Cassandra . 14 6.4 Performance comparison . 15 6.4.1 Sensor Data Storage Performance . 16 6.4.2 Conclusion . 16 7 Data model 17 7.1 Modeling rules . 17 7.2 Data model Design . 18 2 7.3 Summary . 18 8 Architecture 20 8.1 Basic layout . 20 8.2 Sidekiq . 21 9 Design decisions 21 9.1 Keyspaces . 21 9.2 Gap determination . -
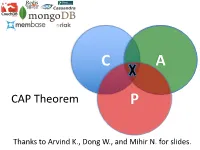
CAP Theorem P
C A CAP Theorem P Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem • “It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3): • (Sequential) Consistency • Availability • Partition-tolerance” • Conjectured by Eric Brewer in ’00 • Proved by Gilbert and Lynch in ’02 • But with definitions that do not match what you’d assume (or Brewer meant) • Influenced the NoSQL mania • Highly controversial: “the CAP theorem encourages engineers to make awful decisions.” – Stonebraker • Many misinterpretations 2 CAP Theorem • Consistency: – Sequential consistency (a data item behaves as if there is one copy) • Availability: – Node failures do not prevent survivors from continuing to operate • Partition-tolerance: – The system continues to operate despite network partitions • CAP says that “A distributed system can satisfy any two of these guarantees at the same time but not all three” 3 C in CAP != C in ACID • They are different! • CAP’s C(onsistency) = sequential consistency – Similar to ACID’s A(tomicity) = Visibility to all future operations • ACID’s C(onsistency) = Does the data satisfy schema constraints 4 Sequential consistency • Makes it appear as if there is one copy of the object • Strict ordering on ops from same client • A single linear ordering across client ops – If client a executes operations {a1, a2, a3, ...}, client b executes operations {b1, b2, b3, ...} – Then, globally, clients observe some serialized version of the sequence • e.g., {a1, b1, b2, a2, ...} (or whatever) Notice -

IBM Cloudant: Database As a Service Fundamentals
Front cover IBM Cloudant: Database as a Service Fundamentals Understand the basics of NoSQL document data stores Access and work with the Cloudant API Work programmatically with Cloudant data Christopher Bienko Marina Greenstein Stephen E Holt Richard T Phillips ibm.com/redbooks Redpaper Contents Notices . 5 Trademarks . 6 Preface . 7 Authors. 7 Now you can become a published author, too! . 8 Comments welcome. 8 Stay connected to IBM Redbooks . 9 Chapter 1. Survey of the database landscape . 1 1.1 The fundamentals and evolution of relational databases . 2 1.1.1 The relational model . 2 1.1.2 The CAP Theorem . 4 1.2 The NoSQL paradigm . 5 1.2.1 ACID versus BASE systems . 7 1.2.2 What is NoSQL? . 8 1.2.3 NoSQL database landscape . 9 1.2.4 JSON and schema-less model . 11 Chapter 2. Build more, grow more, and sleep more with IBM Cloudant . 13 2.1 Business value . 15 2.2 Solution overview . 16 2.3 Solution architecture . 18 2.4 Usage scenarios . 20 2.5 Intuitively interact with data using Cloudant Dashboard . 21 2.5.1 Editing JSON documents using Cloudant Dashboard . 22 2.5.2 Configuring access permissions and replication jobs within Cloudant Dashboard. 24 2.6 A continuum of services working together on cloud . 25 2.6.1 Provisioning an analytics warehouse with IBM dashDB . 26 2.6.2 Data refinement services on-premises. 30 2.6.3 Data refinement services on the cloud. 30 2.6.4 Hybrid clouds: Data refinement across on/off–premises. 31 Chapter 3. -

Object Migration in a Distributed, Heterogeneous SQL Database Network
Linköping University | Department of Computer and Information Science Master’s thesis, 30 ECTS | Computer Engineering (Datateknik) 2018 | LIU-IDA/LITH-EX-A--18/008--SE Object Migration in a Distributed, Heterogeneous SQL Database Network Datamigrering i ett heterogent nätverk av SQL-databaser Joakim Ericsson Supervisor : Tomas Szabo Examiner : Olaf Hartig Linköpings universitet SE–581 83 Linköping +46 13 28 10 00 , www.liu.se Upphovsrätt Detta dokument hålls tillgängligt på Internet – eller dess framtida ersättare – under 25 år från publiceringsdatum under förutsättning att inga extraordinära omständigheter uppstår. Tillgång till dokumentet innebär tillstånd för var och en att läsa, ladda ner, skriva ut enstaka kopior för enskilt bruk och att använda det oförändrat för ickekommersiell forskning och för undervisning. Överföring av upphovsrätten vid en senare tidpunkt kan inte upphäva detta tillstånd. All annan användning av dokumentet kräver upphovsmannens medgivande. För att garantera äktheten, säkerheten och tillgängligheten finns lösningar av teknisk och administrativ art. Upphovsmannens ideella rätt innefattar rätt att bli nämnd som upphovsman i den omfattning som god sed kräver vid användning av dokumentet på ovan beskrivna sätt samt skydd mot att dokumentet ändras eller presenteras i sådan form eller i sådant sammanhang som är kränkande för upphovsmannens litterära eller konstnärliga anseende eller egenart. För ytterligare information om Linköping University Electronic Press se förlagets hemsida http://www.ep.liu.se/. Copyright The publishers will keep this document online on the Internet – or its possible replacement – for a period of 25 years starting from the date of publication barring exceptional circumstances. The online availability of the document implies permanent permission for anyone to read, to download, or to print out single copies for his/hers own use and to use it unchanged for non-commercial research and educational purpose. -

Database Software Market: Billy Fitzsimmons +1 312 364 5112
Equity Research Technology, Media, & Communications | Enterprise and Cloud Infrastructure March 22, 2019 Industry Report Jason Ader +1 617 235 7519 [email protected] Database Software Market: Billy Fitzsimmons +1 312 364 5112 The Long-Awaited Shake-up [email protected] Naji +1 212 245 6508 [email protected] Please refer to important disclosures on pages 70 and 71. Analyst certification is on page 70. William Blair or an affiliate does and seeks to do business with companies covered in its research reports. As a result, investors should be aware that the firm may have a conflict of interest that could affect the objectivity of this report. This report is not intended to provide personal investment advice. The opinions and recommendations here- in do not take into account individual client circumstances, objectives, or needs and are not intended as recommen- dations of particular securities, financial instruments, or strategies to particular clients. The recipient of this report must make its own independent decisions regarding any securities or financial instruments mentioned herein. William Blair Contents Key Findings ......................................................................................................................3 Introduction .......................................................................................................................5 Database Market History ...................................................................................................7 Market Definitions -

A Big Data Roadmap for the DB2 Professional
A Big Data Roadmap For the DB2 Professional Sponsored by: align http://www.datavail.com Craig S. Mullins Mullins Consulting, Inc. http://www.MullinsConsulting.com © 2014 Mullins Consulting, Inc. Author This presentation was prepared by: Craig S. Mullins President & Principal Consultant Mullins Consulting, Inc. 15 Coventry Ct Sugar Land, TX 77479 Tel: 281-494-6153 Fax: 281.491.0637 Skype: cs.mullins E-mail: [email protected] http://www.mullinsconsultinginc.com This document is protected under the copyright laws of the United States and other countries as an unpublished work. This document contains information that is proprietary and confidential to Mullins Consulting, Inc., which shall not be disclosed outside or duplicated, used, or disclosed in whole or in part for any purpose other than as approved by Mullins Consulting, Inc. Any use or disclosure in whole or in part of this information without the express written permission of Mullins Consulting, Inc. is prohibited. © 2014 Craig S. Mullins and Mullins Consulting, Inc. (Unpublished). All rights reserved. © 2014 Mullins Consulting, Inc. 2 Agenda Uncover the roadmap to Big Data… the terminology and technology used, use cases, and trends. • Gain a working knowledge and definition of Big Data (beyond the simple three V's definition) • Break down and understand the often confusing terminology within the realm of Big Data (e.g. polyglot persistence) • Examine the four predominant NoSQL database systems used in Big Data implementations (graph, key/value, column, and document) • Learn some of the major differences between Big Data/NoSQL implementations vis-a-vis traditional transaction processing • Discover the primary use cases for Big Data and NoSQL versus relational databases © 2014 Mullins Consulting, Inc. -

Introduction to Nosql
NoSQL An Introduction Amonra IT - 2019 What is NoSQL? NoSQL is a non-relational database management systems, different from traditional relational database management systems in some significant ways. It is designed for distributed data stores where very large scale of data storing needs (for example Google or Facebook which collects terabits of data every day for their users). This type of data storing may not require fixed schema, avoid join operations and typically scale horizontally. NoSQL ● Stands for Not Only SQL ● No declarative query language ● No predefined schema ● Key-Value pair storage, Column Store, Document Store, Graph databases ● Eventual consistency rather ACID property ● Unstructured and unpredictable data ● CAP Theorem ● Prioritizes high performance, high availability and scalability NoSQL Really Means… focus on non relational, next generation operational datastores and databases…. Why NoSQL? In today’s time data is becoming easier to access and capture through third parties such as Facebook, Google+ and others. Personal user information, social graphs, geo location data, user-generated content and machine logging data are just a few examples where the data has been increasing exponentially. To avail the above service properly, it is required to process huge amount of data. Which SQL databases were never designed. The evolution of NoSql databases is to handle these huge data properly. Web Applications Driving Data Growth Where to use NoSQL ● Social data ● Search ● Data processing ● Caching ● Data Warehousing ● Logging -

CAP Twelve Years Later: How the “Rules” Have Changed
COVER FEATURE CAP Twelve Years Later: How the “Rules” Have Changed Eric Brewer, University of California, Berkeley The CAP theorem asserts that any net- ances matter. CAP prohibits only a tiny part of the design worked shared-data system can have only space: perfect availability and consistency in the presence two of three desirable properties. How- of partitions, which are rare. ever, by explicitly handling partitions, Although designers still need to choose between consis- tency and availability when partitions are present, there designers can optimize consistency and is an incredible range of flexibility for handling partitions availability, thereby achieving some trade- and recovering from them. The modern CAP goal should off of all three. be to maximize combinations of consistency and avail- ability that make sense for the specific application. Such an approach incorporates plans for operation during a n the decade since its introduction, designers and partition and for recovery afterward, thus helping de- researchers have used (and sometimes abused) the signers think about CAP beyond its historically perceived CAP theorem as a reason to explore a wide variety limitations. I of novel distributed systems. The NoSQL movement also has applied it as an argument against traditional WHY “2 OF 3” IS MISLEADING databases. The easiest way to understand CAP is to think of two The CAP theorem states that any networked shared-data nodes on opposite sides of a partition. Allowing at least system can have at most two of three desirable properties: one node to update state will cause the nodes to become inconsistent, thus forfeiting C. -

Top Newsql Databases and Features Classification
International Journal of Database Management Systems ( IJDMS ) Vol.10, No.2, April 2018 TOP NEW SQL DATABASES AND FEATURES CLASSIFICATION Ahmed Almassabi 1, Omar Bawazeer and Salahadin Adam 2 1Department of Computer Science, Najran University, Najran, Saudi Arabia 2Department of Information and Computer Science, King Fahad University of Petroleum and Mineral, Dhahran, Saudi Arabia ABSTRACT Versatility of NewSQL databases is to achieve low latency constrains as well as to reduce cost commodity nodes. Out work emphasize on how big data is addressed through top NewSQL databases considering their features. This NewSQL databases paper conveys some of the top NewSQL databases [54] features collection considering high demand and usage. First part, around 11 NewSQL databases have been investigated for eliciting, comparing and examining their features so that they might assist to observe high hierarchy of NewSQL databases and to reveal their similarities and their differences. Our taxonomy involves four types categories in terms of how NewSQL databases handle, and process big data considering technologies are offered or supported. Advantages and disadvantages are conveyed in this survey for each of NewSQL databases. At second part, we register our findings based on several categories and aspects: first, by our first taxonomy which sees features characteristics are either functional or non-functional. A second taxonomy moved into another aspect regarding data integrity and data manipulation; we found data features classified based on supervised, semi-supervised, or unsupervised. Third taxonomy was about how diverse each single NewSQL database can deal with different types of databases. Surprisingly, Not only do NewSQL databases process regular (raw) data, but also they are stringent enough to afford diverse type of data such as historical and vertical distributed system, real-time, streaming, and timestamp databases. -

Tradeoffs in Distributed Databases
1 Tradeoffs in Distributed Databases University of Oulu Department of Information Processing Science BSc Thesis Risto Juntunen 17.02.2015 2 Abstract In a distributed database data is spread throughout the network into separated nodes with different DBMS systems (Date, 2000). According to CAP – theorem three database properties - consistency, availability and partition tolerance cannot be achieved simultaneously in distributed database systems. Two of these properties can be achieved but not all three at the same time (Brewer, 2000). Since this theorem there has been some development in network infrastructure. Also new methods to achieve consistency in distributed databases has emerged. This paper discusses trade-offs in distributed databases. Keywords Distributed database, cap theorem Supervisor Title, position First name Last name 3 Contents Abstract ................................................................................................................................................ 2 Contents ............................................................................................................................................... 3 1. Introduction .................................................................................................................................. 4 2. Distributed Databases .................................................................................................................. 5 2.1 Principles of distributed databases ....................................................................................... -

Using Stored Procedures Effectively in a Distributed Postgresql Database
Using stored procedures effectively in a distributed PostgreSQL database Bryn Llewellyn Developer Advocate, Yugabyte Inc. © 2019 All rights reserved. 1 What is YugabyteDB? © 2019 All rights reserved. 2 YugaByte DB Distributed SQL PostgreSQL Compatible, 100% Open Source (Apache 2.0) Massive Scale Millions of IOPS in Throughput, TBs per Node High Performance Low Latency Queries Cloud Native Fault Tolerant, Multi-Cloud & Kubernetes Ready © 2019 All rights reserved. 3 Functional Architecture YugaByte SQL (YSQL) PostgreSQL-Compatible Distributed SQL API DOCDB Spanner-Inspired Distributed Document Store Cloud Neutral: No Specialized Hardware Needed © 2019 All rights reserved. 4 Questions? Download download.yugabyte.com Join Slack Discussions yugabyte.com/slack Star on GitHub github.com/YugaByte/yugabyte-db © 2019 All rights reserved. 5 Q: Why use stored procedures? © 2019 All rights reserved. 6 • Large software systems must be built from modules • Hide implementation detail behind API • Software engineering’s most famous principle • The RDBMS is a module • Tables and SQLs that manipulate them are the implementation details • Stored procedures express the API • Result: happiness • Developers and end-users of applications built this way are happy with their correctness, maintainability, security, and performance © 2019 All rights reserved. 7 A: Use stored procedures to encapsulate the RDBMS’s functionality behind an impenetrable hard shell © 2019 All rights reserved. 8 Hard Shell Schematic © 2019 All rights reserved. 9 Public APP DATABASE © 2019 All rights reserved. 10 Public APP DATABASE © 2019 All rights reserved. 11 APP DATABASE © 2019 All rights reserved. 12 Data APP DATABASE © 2019 All rights reserved. 13 Data Code . APP DATABASE © 2019 All rights reserved. -

Cockroachdb: the Resilient Geo-Distributed SQL Database
Industry 3: Cloud and Distributed Databases SIGMOD ’20, June 14–19, 2020, Portland, OR, USA CockroachDB: The Resilient Geo-Distributed SQL Database Rebecca Taft, Irfan Sharif, Andrei Matei, Nathan VanBenschoten, Jordan Lewis, Tobias Grieger, Kai Niemi, Andy Woods, Anne Birzin, Raphael Poss, Paul Bardea, Amruta Ranade, Ben Darnell, Bram Gruneir, Justin Jaffray, Lucy Zhang, and Peter Mattis [email protected] Cockroach Labs, Inc. ABSTRACT We live in an increasingly interconnected world, with many organizations operating across countries or even con- tinents. To serve their global user base, organizations are replacing their legacy DBMSs with cloud-based systems ca- pable of scaling OLTP workloads to millions of users. CockroachDB is a scalable SQL DBMS that was built from the ground up to support these global OLTP workloads while maintaining high availability and strong consistency. Just like its namesake, CockroachDB is resilient to disasters through replication and automatic recovery mechanisms. This paper presents the design of CockroachDB and its novel transaction model that supports consistent geo-distrib- Figure 1: A global CockroachDB cluster uted transactions on commodity hardware. We describe how CockroachDB replicates and distributes data to achieve fault ACM, New York, NY, USA, 17 pages. https://doi.org/10.1145/3318464. tolerance and high performance, as well as how its distributed 3386134 SQL layer automatically scales with the size of the database cluster while providing the standard SQL interface that users 1 INTRODUCTION expect. Finally, we present a comprehensive performance Modern transaction processing workloads are increasingly evaluation and share a couple of case studies of CockroachDB geo-distributed. This trend is fueled by the desire of global users.