IBM Cloudant: Database As a Service Fundamentals
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Smart Methods for Retrieving Physiological Data in Physiqual
University of Groningen Bachelor thesis Smart methods for retrieving physiological data in Physiqual Marc Babtist & Sebastian Wehkamp Supervisors: Frank Blaauw & Marco Aiello July, 2016 Contents 1 Introduction 4 1.1 Physiqual . 4 1.2 Problem description . 4 1.3 Research questions . 5 1.4 Document structure . 5 2 Related work 5 2.1 IJkdijk project . 5 2.2 MUMPS . 6 3 Background 7 3.1 Scalability . 7 3.2 CAP theorem . 7 3.3 Reliability models . 7 4 Requirements 8 4.1 Scalability . 8 4.2 Reliability . 9 4.3 Performance . 9 4.4 Open source . 9 5 General database options 9 5.1 Relational or Non-relational . 9 5.2 NoSQL categories . 10 5.2.1 Key-value Stores . 10 5.2.2 Document Stores . 11 5.2.3 Column Family Stores . 11 5.2.4 Graph Stores . 12 5.3 When to use which category . 12 5.4 Conclusion . 12 5.4.1 Key-Value . 13 5.4.2 Document stores . 13 5.4.3 Column family stores . 13 5.4.4 Graph Stores . 13 6 Specific database options 13 6.1 Key-value stores: Riak . 14 6.2 Document stores: MongoDB . 14 6.3 Column Family stores: Cassandra . 14 6.4 Performance comparison . 15 6.4.1 Sensor Data Storage Performance . 16 6.4.2 Conclusion . 16 7 Data model 17 7.1 Modeling rules . 17 7.2 Data model Design . 18 2 7.3 Summary . 18 8 Architecture 20 8.1 Basic layout . 20 8.2 Sidekiq . 21 9 Design decisions 21 9.1 Keyspaces . 21 9.2 Gap determination . -

Evolution of Database Technology
Introduction and Database Technology By EM Bakker September 11, 2012 Databases and Data Mining 1 DBDM Introduction Databases and Data Mining Projects at LIACS Biological and Medical Databases and Data Mining CMSB (Phenotype Genotype), DIAL CGH DB Cyttron: Visualization of the Cell GRID Computing VLe: Virtual Lab e-Science environments DAS3/DAS4 super computer Research on Fundamentals of Databases and Data Mining Database integration Data Mining algorithms Content Based Retrieval September 11, 2012 Databases and Data Mining 2 DBDM Databases (Chapters 1-7): The Evolution of Database Technology Data Preprocessing Data Warehouse (OLAP) & Data Cubes Data Cubes Computation Grand Challenges and State of the Art September 11, 2012 Databases and Data Mining 3 DBDM Data Mining (Chapters 8-11): Introduction and Overview of Data Mining Data Mining Basic Algorithms Mining data streams Mining Sequence Patterns Graph Mining September 11, 2012 Databases and Data Mining 4 DBDM Further Topics Mining object, spatial, multimedia, text and Web data Mining complex data objects Spatial and spatiotemporal data mining Multimedia data mining Text mining Web mining Applications and trends of data mining Mining business & biological data Visual data mining Data mining and society: Privacy-preserving data mining September 11, 2012 Databases and Data Mining 5 [R] Evolution of Database Technology September 11, 2012 Databases and Data Mining 6 Evolution of Database Technology 1960s: (Electronic) Data collection, database creation, IMS -

Lucene in Action Second Edition
Covers Apache Lucene 3.0 IN ACTION SECOND EDITION Michael McCandless Erik Hatcher , Otis Gospodnetic FOREWORD BY DOUG CUTTING MANNING www.it-ebooks.info Praise for the First Edition This is definitely the book to have if you’re planning on using Lucene in your application, or are interested in what Lucene can do for you. —JavaLobby Search powers the information age. This book is a gateway to this invaluable resource...It suc- ceeds admirably in elucidating the application programming interface (API), with many code examples and cogent explanations, opening the door to a fine tool. —Computing Reviews A must-read for anyone who wants to learn about Lucene or is even considering embedding search into their applications or just wants to learn about information retrieval in general. Highly recommended! —TheServerSide.com Well thought-out...thoroughly edited...stands out clearly from the crowd....I enjoyed reading this book. If you have any text-searching needs, this book will be more than sufficient equipment to guide you to successful completion. Even, if you are just looking to download a pre-written search engine, then this book will provide a good background to the nature of information retrieval in general and text indexing and searching specifically. —Slashdot.org The book is more like a crystal ball than ink on pape--I run into solutions to my most pressing problems as I read through it. —Arman Anwar, Arman@Web Provides a detailed blueprint for using and customizing Lucene...a thorough introduction to the inner workings of what’s arguably the most popular open source search engine...loaded with code examples and emphasizes a hands-on approach to learning. -

Not ACID, Not BASE, but SALT a Transaction Processing Perspective on Blockchains
Not ACID, not BASE, but SALT A Transaction Processing Perspective on Blockchains Stefan Tai, Jacob Eberhardt and Markus Klems Information Systems Engineering, Technische Universitat¨ Berlin fst, je, [email protected] Keywords: SALT, blockchain, decentralized, ACID, BASE, transaction processing Abstract: Traditional ACID transactions, typically supported by relational database management systems, emphasize database consistency. BASE provides a model that trades some consistency for availability, and is typically favored by cloud systems and NoSQL data stores. With the increasing popularity of blockchain technology, another alternative to both ACID and BASE is introduced: SALT. In this keynote paper, we present SALT as a model to explain blockchains and their use in application architecture. We take both, a transaction and a transaction processing systems perspective on the SALT model. From a transactions perspective, SALT is about Sequential, Agreed-on, Ledgered, and Tamper-resistant transaction processing. From a systems perspec- tive, SALT is about decentralized transaction processing systems being Symmetric, Admin-free, Ledgered and Time-consensual. We discuss the importance of these dual perspectives, both, when comparing SALT with ACID and BASE, and when engineering blockchain-based applications. We expect the next-generation of decentralized transactional applications to leverage combinations of all three transaction models. 1 INTRODUCTION against. Using the admittedly contrived acronym of SALT, we characterize blockchain-based transactions There is a common belief that blockchains have the – from a transactions perspective – as Sequential, potential to fundamentally disrupt entire industries. Agreed, Ledgered, and Tamper-resistant, and – from Whether we are talking about financial services, the a systems perspective – as Symmetric, Admin-free, sharing economy, the Internet of Things, or future en- Ledgered, and Time-consensual. -
CAP Theorem P
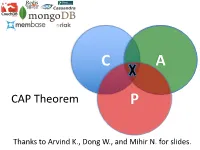
C A CAP Theorem P Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem • “It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3): • (Sequential) Consistency • Availability • Partition-tolerance” • Conjectured by Eric Brewer in ’00 • Proved by Gilbert and Lynch in ’02 • But with definitions that do not match what you’d assume (or Brewer meant) • Influenced the NoSQL mania • Highly controversial: “the CAP theorem encourages engineers to make awful decisions.” – Stonebraker • Many misinterpretations 2 CAP Theorem • Consistency: – Sequential consistency (a data item behaves as if there is one copy) • Availability: – Node failures do not prevent survivors from continuing to operate • Partition-tolerance: – The system continues to operate despite network partitions • CAP says that “A distributed system can satisfy any two of these guarantees at the same time but not all three” 3 C in CAP != C in ACID • They are different! • CAP’s C(onsistency) = sequential consistency – Similar to ACID’s A(tomicity) = Visibility to all future operations • ACID’s C(onsistency) = Does the data satisfy schema constraints 4 Sequential consistency • Makes it appear as if there is one copy of the object • Strict ordering on ops from same client • A single linear ordering across client ops – If client a executes operations {a1, a2, a3, ...}, client b executes operations {b1, b2, b3, ...} – Then, globally, clients observe some serialized version of the sequence • e.g., {a1, b1, b2, a2, ...} (or whatever) Notice -

MDA Process to Extract the Data Model from a Document-Oriented Nosql Database Amal Ait Brahim, Rabah Tighilt Ferhat, Gilles Zurfluh
MDA process to extract the data model from a document-oriented NoSQL database Amal Ait Brahim, Rabah Tighilt Ferhat, Gilles Zurfluh To cite this version: Amal Ait Brahim, Rabah Tighilt Ferhat, Gilles Zurfluh. MDA process to extract the data model from a document-oriented NoSQL database. ICEIS 2019: 21st International Conference on Enterprise Information Systems, May 2019, Heraklion, Greece. pp.141-148, 10.5220/0007676201410148. hal- 02886696 HAL Id: hal-02886696 https://hal.archives-ouvertes.fr/hal-02886696 Submitted on 1 Jul 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Open Archive Toulouse Archive Ouverte OATAO is an open access repository that collects the work of Toulouse researchers and makes it freely available over the web where possible This is an author’s version published in: https://oatao.univ-toulouse.fr/26232 Official URL : https://doi.org/10.5220/0007676201410148 To cite this version: Ait Brahim, Amal and Tighilt Ferhat, Rabah and Zurfluh, Gilles MDA process to extract the data model from a document-oriented NoSQL database. (2019) In: ICEIS 2019: 21st International Conference on Enterprise Information Systems, 3 May 2019 - 5 May 2019 (Heraklion, Greece). -

Apache Lucene Searching the Web and Everything Else
Apache Lucene Searching the Web and Everything Else Daniel Naber Mindquarry GmbH ID 380 2 AGENDA > What's a search engine > Lucene Java – Features – Code example > Solr – Features – Integration > Nutch – Features – Usage example > Conclusion and alternative solutions 3 About the Speaker > Studied computational linguistics > Java developer > Worked 3.5 years for an Enterprise Search company (using Lucene Java) > Now at Mindquarry, creators on an Open Source Collaboration Software (Mindquarry uses Solr) 4 Question: What is a Search Engine? > Answer: A software that – builds an index on text – answers queries using that index “But we have a database already“ – A search engine offers Scalability Relevance Ranking Integrates different data sources (email, web pages, files, database, ...) 5 What is a search engine? (cont.) > Works on words, not on substrings auto != automatic, automobile > Indexing process: – Convert document – Extract text and meta data – Normalize text – Write (inverted) index – Example: Document 1: “Apache Lucene at Jazoon“ Document 2: “Jazoon conference“ Index: apache -> 1 conference -> 2 jazoon -> 1, 2 lucene -> 1 6 Apache Lucene Overview > Lucene Java 2.2 – Java library > Solr 1.2 – http-based index and search server > Nutch 0.9 – Internet search engine software > http://lucene.apache.org 7 Lucene Java > Java library for indexing and searching > No dependencies (not even a logging framework) > Works with Java 1.4 or later > Input for indexing: Document objects – Each document: set of Fields, field name: field content (plain text) > Input for searching: query strings or Query objects > Stores its index as files on disk > No document converters > No web crawler 8 Lucene Java Users > IBM OmniFind Yahoo! Edition > technorati.com > Eclipse > Furl > Nuxeo ECM > Monster.com > .. -

MDA Process to Extract the Data Model from Document-Oriented Nosql Database
MDA Process to Extract the Data Model from Document-oriented NoSQL Database Amal Ait Brahim, Rabah Tighilt Ferhat and Gilles Zurfluh Toulouse Institute of Computer Science Research (IRIT), Toulouse Capitole University, Toulouse, France Keywords: Big Data, NoSQL, Model Extraction, Schema Less, MDA, QVT. Abstract: In recent years, the need to use NoSQL systems to store and exploit big data has been steadily increasing. Most of these systems are characterized by the property "schema less" which means absence of the data model when creating a database. This property brings an undeniable flexibility by allowing the evolution of the model during the exploitation of the base. However, query expression requires a precise knowledge of the data model. In this article, we propose a process to automatically extract the physical model from a document- oriented NoSQL database. To do this, we use the Model Driven Architecture (MDA) that provides a formal framework for automatic model transformation. From a NoSQL database, we propose formal transformation rules with QVT to generate the physical model. An experimentation of the extraction process was performed on the case of a medical application. 1 INTRODUCTION however that it is absent in some systems such as Cassandra and Riak TS. The "schema less" property Recently, there has been an explosion of data offers undeniable flexibility by allowing the model to generated and accumulated by more and more evolve easily. For example, the addition of new numerous and diversified computing devices. attributes in an existing line is done without Databases thus constituted are designated by the modifying the other lines of the same type previously expression "Big Data" and are characterized by the stored; something that is not possible with relational so-called "3V" rule (Chen, 2014). -

What Is Nosql? the Only Thing That All Nosql Solutions Providers Generally Agree on Is That the Term “Nosql” Isn’T Perfect, but It Is Catchy
NoSQL GREG SYSADMINBURD Greg Burd is a Developer Choosing between databases used to boil down to examining the differences Advocate for Basho between the available commercial and open source relational databases . The term Technologies, makers of Riak. “database” had become synonymous with SQL, and for a while not much else came Before Basho, Greg spent close to being a viable solution for data storage . But recently there has been a shift nearly ten years as the product manager for in the database landscape . When considering options for data storage, there is a Berkeley DB at Sleepycat Software and then new game in town: NoSQL databases . In this article I’ll introduce this new cat- at Oracle. Previously, Greg worked for NeXT egory of databases, examine where they came from and what they are good for, and Computer, Sun Microsystems, and KnowNow. help you understand whether you, too, should be considering a NoSQL solution in Greg has long been an avid supporter of open place of, or in addition to, your RDBMS database . source software. [email protected] What Is NoSQL? The only thing that all NoSQL solutions providers generally agree on is that the term “NoSQL” isn’t perfect, but it is catchy . Most agree that the “no” stands for “not only”—an admission that the goal is not to reject SQL but, rather, to compensate for the technical limitations shared by the majority of relational database implemen- tations . In fact, NoSQL is more a rejection of a particular software and hardware architecture for databases than of any single technology, language, or product . -

CMU 15-445/645 Database Systems (Fall 2018 :: Query Optimization
Query Optimization Lecture #13 Database Systems Andy Pavlo 15-445/15-645 Computer Science Fall 2018 AP Carnegie Mellon Univ. 2 ADMINISTRIVIA Mid-term Exam is on Wednesday October 17th → See mid-term exam guide for more info. Project #2 – Checkpoint #2 is due Friday October 19th @ 11:59pm. CMU 15-445/645 (Fall 2018) 4 QUERY OPTIMIZATION Remember that SQL is declarative. → User tells the DBMS what answer they want, not how to get the answer. There can be a big difference in performance based on plan is used: → See last week: 1.3 hours vs. 0.45 seconds CMU 15-445/645 (Fall 2018) 5 IBM SYSTEM R First implementation of a query optimizer. People argued that the DBMS could never choose a query plan better than what a human could write. A lot of the concepts from System R’s optimizer are still used today. CMU 15-445/645 (Fall 2018) 6 QUERY OPTIMIZATION Heuristics / Rules → Rewrite the query to remove stupid / inefficient things. → Does not require a cost model. Cost-based Search → Use a cost model to evaluate multiple equivalent plans and pick the one with the lowest cost. CMU 15-445/645 (Fall 2018) 7 QUERY PLANNING OVERVIEW System Catalog Cost SQL Query Model Abstract Syntax Annotated Annotated Tree AST AST Parser Binder Rewriter Optimizer (Optional) Name→Internal ID Query Plan CMU 15-445/645 (Fall 2018) 8 TODAY'S AGENDA Relational Algebra Equivalences Plan Cost Estimation Plan Enumeration Nested Sub-queries Mid-Term Review CMU 15-445/645 (Fall 2018) 9 RELATIONAL ALGEBRA EQUIVALENCES Two relational algebra expressions are equivalent if they generate the same set of tuples. -

Evolution of Database Technology 1960S: (Electronic) Data Collection, Database Creation, IMS (Hierarchical Database System by IBM) and Network DBMS
Database Technology Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/DBDM/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/ [email protected] [email protected] 9/21/18 Databases and Data Mining 1 Evolution of Database Technology 1960s: (Electronic) Data collection, database creation, IMS (hierarchical database system by IBM) and network DBMS 1970s: Relational data model, relational DBMS implementation 1980s: RDBMS, advanced data models (extended-relational, OO, deductive, etc.) Application-oriented DBMS (spatial, scientific, engineering, etc.) 9/21/18 Databases and Data Mining 2 Evolution of Database Technology 1990s: Data mining, data warehousing, multimedia databases, and Web databases 2000 - Stream data management and mining Data mining and its applications Web technology Data integration, XML Social Networks (Facebook, etc.) Cloud Computing global information systems Emerging in-house solutions In Memory Databases Big Data 9/21/18 Databases and Data Mining 3 1960’s Companies began automating their back-office bookkeeping in the 1960s COBOL and its record-oriented file model were the work-horses of this effort Typical work-cycle: 1. a batch of transactions was applied to the old-tape-master 2. a new-tape-master produced 3. printout for the next business day. COmmon Business-Oriented Language (COBOL 2002 standard) 9/21/18 Databases and Data Mining 4 COBOL A quote by Prof. dr. E.W. Dijkstra (Turing Award 1972) 18 June 1975: “The use of COBOL cripples the mind; its teaching should, therefore, be regarded as a criminal offence.” September 2015: 9/21/18 Databases and Data Mining 5 COBOL Code (just an example!) 01 LOAN-WORK-AREA. -

Magnify Search Security and Administration Release 8.2 Version 04
Magnify Search Security and Administration Release 8.2 Version 04 April 08, 2019 Active Technologies, EDA, EDA/SQL, FIDEL, FOCUS, Information Builders, the Information Builders logo, iWay, iWay Software, Parlay, PC/FOCUS, RStat, Table Talk, Web390, WebFOCUS, WebFOCUS Active Technologies, and WebFOCUS Magnify are registered trademarks, and DataMigrator and Hyperstage are trademarks of Information Builders, Inc. Adobe, the Adobe logo, Acrobat, Adobe Reader, Flash, Adobe Flash Builder, Flex, and PostScript are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries. Due to the nature of this material, this document refers to numerous hardware and software products by their trademarks. In most, if not all cases, these designations are claimed as trademarks or registered trademarks by their respective companies. It is not this publisher's intent to use any of these names generically. The reader is therefore cautioned to investigate all claimed trademark rights before using any of these names other than to refer to the product described. Copyright © 2019, by Information Builders, Inc. and iWay Software. All rights reserved. Patent Pending. This manual, or parts thereof, may not be reproduced in any form without the written permission of Information Builders, Inc. Contents Preface ......................................................................... 7 Conventions ......................................................................... 7 Related Publications .................................................................