SQL Vs. Nosql Vs. Newsql
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Smart Methods for Retrieving Physiological Data in Physiqual
University of Groningen Bachelor thesis Smart methods for retrieving physiological data in Physiqual Marc Babtist & Sebastian Wehkamp Supervisors: Frank Blaauw & Marco Aiello July, 2016 Contents 1 Introduction 4 1.1 Physiqual . 4 1.2 Problem description . 4 1.3 Research questions . 5 1.4 Document structure . 5 2 Related work 5 2.1 IJkdijk project . 5 2.2 MUMPS . 6 3 Background 7 3.1 Scalability . 7 3.2 CAP theorem . 7 3.3 Reliability models . 7 4 Requirements 8 4.1 Scalability . 8 4.2 Reliability . 9 4.3 Performance . 9 4.4 Open source . 9 5 General database options 9 5.1 Relational or Non-relational . 9 5.2 NoSQL categories . 10 5.2.1 Key-value Stores . 10 5.2.2 Document Stores . 11 5.2.3 Column Family Stores . 11 5.2.4 Graph Stores . 12 5.3 When to use which category . 12 5.4 Conclusion . 12 5.4.1 Key-Value . 13 5.4.2 Document stores . 13 5.4.3 Column family stores . 13 5.4.4 Graph Stores . 13 6 Specific database options 13 6.1 Key-value stores: Riak . 14 6.2 Document stores: MongoDB . 14 6.3 Column Family stores: Cassandra . 14 6.4 Performance comparison . 15 6.4.1 Sensor Data Storage Performance . 16 6.4.2 Conclusion . 16 7 Data model 17 7.1 Modeling rules . 17 7.2 Data model Design . 18 2 7.3 Summary . 18 8 Architecture 20 8.1 Basic layout . 20 8.2 Sidekiq . 21 9 Design decisions 21 9.1 Keyspaces . 21 9.2 Gap determination . -

Big Data Velocity in Plain English
Big Data Velocity in Plain English John Ryan Data Warehouse Solution Architect Table of Contents The Requirement . 1 What’s the Problem? . .. 2 Components Needed . 3 Data Capture . 3 Transformation . 3 Storage and Analytics . 4 The Traditional Solution . 6 The NewSQL Based Solution . 7 NewSQL Advantage . 9 Thank You. 10 About the Author . 10 ii The Requirement The assumed requirement is the ability to capture, transform and analyse data at potentially massive velocity in real time. This involves capturing data from millions of customers or electronic sensors, and transforming and storing the results for real time analysis on dashboards. The solution must minimise latency — the delay between a real world event and it’s impact upon a dashboard, to under a second. Typical applications include: • Monitoring Machine Sensors: Using embedded sensors in industrial machines or vehicles — typically referred to as The Internet of Things (IoT) . For example Progressive Insurance use real time speed and vehicle braking data to help classify accident risk and deliver appropriate discounts. Similar technology is used by logistics giant FedEx which uses SenseAware technology to provide near real-time parcel tracking. • Fraud Detection: To assess the risk of credit card fraud prior to authorising or declining the transaction. This can be based upon a simple report of a lost or stolen card, or more likely, an analysis of aggregate spending behaviour, aligned with machine learning techniques. • Clickstream Analysis: Producing real time analysis of user web site clicks to dynamically deliver pages, recommended products or services, or deliver individually targeted advertising. Big Data: Velocity in Plain English eBook 1 What’s the Problem? The primary challenge for real time systems architects is the potentially massive throughput required which could exceed a million transactions per second. -

Operational Database Offload
Operational Database Offload Partner Brief Facing increased data growth and cost pressures, scale‐out technology has become very popular as more businesses become frustrated with their costly “Our partnership with Hortonworks is able to scale‐up RDBMSs. With Hadoop emerging as the de facto scale‐out file system, a deliver to our clients 5‐10x faster performance Hadoop RDBMS is a natural choice to replace traditional relational databases and over 75% reduction in TCO over traditional scale‐up databases. With Splice like Oracle and IBM DB2, which struggle with cost or scaling issues. Machine’s SQL‐based transactional processing Designed to meet the needs of real‐time, data‐driven businesses, Splice engine, our clients are able to migrate their legacy database applications without Machine is the only Hadoop RDBMS. Splice Machine offers an ANSI‐SQL application rewrites” database with support for ACID transactions on the distributed computing Monte Zweben infrastructure of Hadoop. Like Oracle and MySQL, it is an operational database Chief Executive Office that can handle operational (OLTP) or analytical (OLAP) workloads, while scaling Splice Machine out cost‐effectively from terabytes to petabytes on inexpensive commodity servers. Splice Machine, a technology partner with Hortonworks, chose HBase and Hadoop as its scale‐out architecture because of their proven auto‐sharding, replication, and failover technology. This partnership now allows businesses the best of all worlds: a standard SQL database, the proven scale‐out of Hadoop, and the ability to leverage current staff, operations, and applications without specialized hardware or significant application modifications. What Business Challenges are Solved? Leverage Existing SQL Tools Cost Effective Scaling Real‐Time Updates Leveraging the proven SQL processing of Splice Machine leverages the proven Splice Machine provides full ACID Apache Derby, Splice Machine is a true ANSI auto‐sharding of HBase to scale with transactions across rows and tables by using SQL database on Hadoop. -

Not ACID, Not BASE, but SALT a Transaction Processing Perspective on Blockchains
Not ACID, not BASE, but SALT A Transaction Processing Perspective on Blockchains Stefan Tai, Jacob Eberhardt and Markus Klems Information Systems Engineering, Technische Universitat¨ Berlin fst, je, [email protected] Keywords: SALT, blockchain, decentralized, ACID, BASE, transaction processing Abstract: Traditional ACID transactions, typically supported by relational database management systems, emphasize database consistency. BASE provides a model that trades some consistency for availability, and is typically favored by cloud systems and NoSQL data stores. With the increasing popularity of blockchain technology, another alternative to both ACID and BASE is introduced: SALT. In this keynote paper, we present SALT as a model to explain blockchains and their use in application architecture. We take both, a transaction and a transaction processing systems perspective on the SALT model. From a transactions perspective, SALT is about Sequential, Agreed-on, Ledgered, and Tamper-resistant transaction processing. From a systems perspec- tive, SALT is about decentralized transaction processing systems being Symmetric, Admin-free, Ledgered and Time-consensual. We discuss the importance of these dual perspectives, both, when comparing SALT with ACID and BASE, and when engineering blockchain-based applications. We expect the next-generation of decentralized transactional applications to leverage combinations of all three transaction models. 1 INTRODUCTION against. Using the admittedly contrived acronym of SALT, we characterize blockchain-based transactions There is a common belief that blockchains have the – from a transactions perspective – as Sequential, potential to fundamentally disrupt entire industries. Agreed, Ledgered, and Tamper-resistant, and – from Whether we are talking about financial services, the a systems perspective – as Symmetric, Admin-free, sharing economy, the Internet of Things, or future en- Ledgered, and Time-consensual. -

Of the Cloudtracker®
DIGITAL BANKS AND THE POWER OF THE CLOUD TRACKER® AUGUST 2020 How Holvi is Australian online-only Xinja Why the pandemic is pushing leveraging Kubernetes Bank turns to Kubernetes banks to go cloud-native for seamless service to enhance its mobile Page 8 banking features Page 19 FEATURE STORY Page 13 DEEP DIVE NEWS AND TRENDS TABLE OF CONTENTS 03 WHAT’S INSIDE Recent cloud and digital banking developments, such as why banks need to examine their container orchestration and Kubernetes investments as well as why the Royal Bank of Canada is employing AI and private cloud technology to accelerate its software innovation 08 FEATURE STORY An interview with Andrew Smith, director of technical operations for Finnish banking service Holvi, on why Kubernetes’ speed and scalability are essential to helping FIs swiftly deploy services for customers NEWS AND TRENDS 13 The latest cloud banking headlines, including why Australian business banking FinTech Tyro is using the cloud to upgrade its infrastructure and why Singapore’s Asia Digital Bank Corporation is leveraging the cloud to better contend for one of the region’s digital banking licenses DEEP DIVE 19 ACKNOWLEDGMENT An in-depth look at how the ongoing The Digital Banks And The Power Of The pandemic is pushing banks onto cloud-native ® Cloud Tracker was done in collaboration digital infrastructure and how systems like with NuoDB, and PYMNTS is grateful for the company’s support and insight. PYMNTS.com Kubernetes will prove essential for this move retains full editorial control over the following findings, methodology and data analysis. 23 ABOUT Information on PYMNTS.com and NuoDB WHAT’S INSIDE pproximately half a year has passed since the COVID-19 pandemic was declared and banks have largely determined how to continue their oper- ations as the industry faces significant challenges. -

Failures in DBMS
Chapter 11 Database Recovery 1 Failures in DBMS Two common kinds of failures StSystem filfailure (t)(e.g. power outage) ‒ affects all transactions currently in progress but does not physically damage the data (soft crash) Media failures (e.g. Head crash on the disk) ‒ damagg()e to the database (hard crash) ‒ need backup data Recoveryyp scheme responsible for handling failures and restoring database to consistent state 2 Recovery Recovering the database itself Recovery algorithm has two parts ‒ Actions taken during normal operation to ensure system can recover from failure (e.g., backup, log file) ‒ Actions taken after a failure to restore database to consistent state We will discuss (briefly) ‒ Transactions/Transaction recovery ‒ System Recovery 3 Transactions A database is updated by processing transactions that result in changes to one or more records. A user’s program may carry out many operations on the data retrieved from the database, but the DBMS is only concerned with data read/written from/to the database. The DBMS’s abstract view of a user program is a sequence of transactions (reads and writes). To understand database recovery, we must first understand the concept of transaction integrity. 4 Transactions A transaction is considered a logical unit of work ‒ START Statement: BEGIN TRANSACTION ‒ END Statement: COMMIT ‒ Execution errors: ROLLBACK Assume we want to transfer $100 from one bank (A) account to another (B): UPDATE Account_A SET Balance= Balance -100; UPDATE Account_B SET Balance= Balance +100; We want these two operations to appear as a single atomic action 5 Transactions We want these two operations to appear as a single atomic action ‒ To avoid inconsistent states of the database in-between the two updates ‒ And obviously we cannot allow the first UPDATE to be executed and the second not or vice versa. -

Oracle Vs. Nosql Vs. Newsql Comparing Database Technology
Oracle vs. NoSQL vs. NewSQL Comparing Database Technology John Ryan Senior Solution Architect, Snowflake Computing Table of Contents The World has Changed . 1 What’s Changed? . 2 What’s the Problem? . .. 3 Performance vs. Availability and Durability . 3 Consistecy vs. Availability . 4 Flexibility vs . Scalability . 5 ACID vs. Eventual Consistency . 6 The OLTP Database Reimagined . 7 Achieving the Impossible! . .. 8 NewSQL Database Technology . 9 VoltDB . 10 MemSQL . 11 Which Applications Need NewSQL Technology? . 12 Conclusion . 13 About the Author . 13 ii The World has Changed The world has changed massively in the past 20 years. Back in the year 2000, a few million users connected to the web using a 56k modem attached to a PC, and Amazon only sold books. Now billions of people are using to their smartphone or tablet 24x7 to buy just about everything, and they’re interacting with Facebook, Twitter and Instagram. The pace has been unstoppable . Expectations have also changed. If a web page doesn’t refresh within seconds we’re quickly frustrated, and go elsewhere. If a web site is down, we fear it’s the end of civilisation as we know it. If a major site is down, it makes global headlines. Instant gratification takes too long! — Ladawn Clare-Panton Aside: If you’re not a seasoned Database Architect, you may want to start with my previous articles on Scalability and Database Architecture. Oracle vs. NoSQL vs. NewSQL eBook 1 What’s Changed? The above leads to a few observations: • Scalability — With potentially explosive traffic growth, IT systems need to quickly grow to meet exponential numbers of transactions • High Availability — IT systems must run 24x7, and be resilient to failure. -
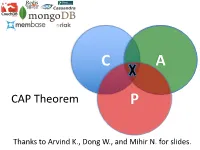
CAP Theorem P
C A CAP Theorem P Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem • “It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3): • (Sequential) Consistency • Availability • Partition-tolerance” • Conjectured by Eric Brewer in ’00 • Proved by Gilbert and Lynch in ’02 • But with definitions that do not match what you’d assume (or Brewer meant) • Influenced the NoSQL mania • Highly controversial: “the CAP theorem encourages engineers to make awful decisions.” – Stonebraker • Many misinterpretations 2 CAP Theorem • Consistency: – Sequential consistency (a data item behaves as if there is one copy) • Availability: – Node failures do not prevent survivors from continuing to operate • Partition-tolerance: – The system continues to operate despite network partitions • CAP says that “A distributed system can satisfy any two of these guarantees at the same time but not all three” 3 C in CAP != C in ACID • They are different! • CAP’s C(onsistency) = sequential consistency – Similar to ACID’s A(tomicity) = Visibility to all future operations • ACID’s C(onsistency) = Does the data satisfy schema constraints 4 Sequential consistency • Makes it appear as if there is one copy of the object • Strict ordering on ops from same client • A single linear ordering across client ops – If client a executes operations {a1, a2, a3, ...}, client b executes operations {b1, b2, b3, ...} – Then, globally, clients observe some serialized version of the sequence • e.g., {a1, b1, b2, a2, ...} (or whatever) Notice -

MDA Process to Extract the Data Model from a Document-Oriented Nosql Database Amal Ait Brahim, Rabah Tighilt Ferhat, Gilles Zurfluh
MDA process to extract the data model from a document-oriented NoSQL database Amal Ait Brahim, Rabah Tighilt Ferhat, Gilles Zurfluh To cite this version: Amal Ait Brahim, Rabah Tighilt Ferhat, Gilles Zurfluh. MDA process to extract the data model from a document-oriented NoSQL database. ICEIS 2019: 21st International Conference on Enterprise Information Systems, May 2019, Heraklion, Greece. pp.141-148, 10.5220/0007676201410148. hal- 02886696 HAL Id: hal-02886696 https://hal.archives-ouvertes.fr/hal-02886696 Submitted on 1 Jul 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Open Archive Toulouse Archive Ouverte OATAO is an open access repository that collects the work of Toulouse researchers and makes it freely available over the web where possible This is an author’s version published in: https://oatao.univ-toulouse.fr/26232 Official URL : https://doi.org/10.5220/0007676201410148 To cite this version: Ait Brahim, Amal and Tighilt Ferhat, Rabah and Zurfluh, Gilles MDA process to extract the data model from a document-oriented NoSQL database. (2019) In: ICEIS 2019: 21st International Conference on Enterprise Information Systems, 3 May 2019 - 5 May 2019 (Heraklion, Greece). -

The Declarative Imperative Experiences and Conjectures in Distributed Logic
The Declarative Imperative Experiences and Conjectures in Distributed Logic Joseph M. Hellerstein University of California, Berkeley [email protected] ABSTRACT The juxtaposition of these trends presents stark alternatives. The rise of multicore processors and cloud computing is putting Will the forecasts of doom and gloom materialize in a storm enormous pressure on the software community to find solu- that drowns out progress in computing? Or is this the long- tions to the difficulty of parallel and distributed programming. delayed catharsis that will wash away today’s thicket of im- At the same time, there is more—and more varied—interest in perative languages, preparing the ground for a more fertile data-centric programming languages than at any time in com- declarative future? And what role might the database com- puting history, in part because these languages parallelize nat- munity play in shaping this future, having sowed the seeds of urally. This juxtaposition raises the possibility that the theory Datalog over the last quarter century? of declarative database query languages can provide a foun- Before addressing these issues directly, a few more words dation for the next generation of parallel and distributed pro- about both crisis and opportunity are in order. gramming languages. 1.1 Urgency: Parallelism In this paper I reflect on my group’s experience over seven years using Datalog extensions to build networking protocols I would be panicked if I were in industry. and distributed systems. Based on that experience, I present — John Hennessy, President, Stanford University [35] a number of theoretical conjectures that may both interest the database community, and clarify important practical issues in The need for parallelism is visible at micro and macro scales. -

Product 360: Retail and Consumer Industries
PRODUCT 360: RETAIL AND CONSUMER INDUSTRIES MARKLOGIC WHITE PAPER • NOVEMBER 2015 PRODUCT INFORMATION IS COMPLEX A major challenge for Retail and Consumer companies today is product proliferation and product complexity. An electronics retailer for example may have over 70,000 products in its catalog, while it is not uncommon for an industrial distributor to have over a million products and represent over 1,000 suppliers. Products HD typically have short shelf lives. In electronics for example it’s not uncommon for a new model to be released every year. And, a “Product” is not just a physical SKU (stock keeping unit) but a complex combination of structured HD and unstructured data that helps consumers search for, evaluate, compare, and choose their desired purchase. Product information includes a variety of data elements Product information includes a wide variety of data elements which are generated and stored in multiple locations, for example: WHY IS “PRODUCT 360” • Product descriptive information (e.g. size, color, IMPORTANT? material, nutritional information, usage, and other Creating, maintaining, and managing a 360 degree view elements that define it) of products is at the core of competitive differentiation • Digital images and videos – and in fact even survival – for retail and consumer • Customer ratings and reviews companies. • Dynamic pricing and promotions • Availability in-stock Key benefits of a Product 360 include: • Consumer loyalty information (who’s most likely to buy it) REVENUE GROWTH • Related products and accessories Today just 3% of on-line e-commerce transactions actually result in a sale. E-Commerce is the fastest These data elements often sit in different databases and growing channel for retailers, and sales via e-commerce legacy systems, making accessing them a challenge. -

MDA Process to Extract the Data Model from Document-Oriented Nosql Database
MDA Process to Extract the Data Model from Document-oriented NoSQL Database Amal Ait Brahim, Rabah Tighilt Ferhat and Gilles Zurfluh Toulouse Institute of Computer Science Research (IRIT), Toulouse Capitole University, Toulouse, France Keywords: Big Data, NoSQL, Model Extraction, Schema Less, MDA, QVT. Abstract: In recent years, the need to use NoSQL systems to store and exploit big data has been steadily increasing. Most of these systems are characterized by the property "schema less" which means absence of the data model when creating a database. This property brings an undeniable flexibility by allowing the evolution of the model during the exploitation of the base. However, query expression requires a precise knowledge of the data model. In this article, we propose a process to automatically extract the physical model from a document- oriented NoSQL database. To do this, we use the Model Driven Architecture (MDA) that provides a formal framework for automatic model transformation. From a NoSQL database, we propose formal transformation rules with QVT to generate the physical model. An experimentation of the extraction process was performed on the case of a medical application. 1 INTRODUCTION however that it is absent in some systems such as Cassandra and Riak TS. The "schema less" property Recently, there has been an explosion of data offers undeniable flexibility by allowing the model to generated and accumulated by more and more evolve easily. For example, the addition of new numerous and diversified computing devices. attributes in an existing line is done without Databases thus constituted are designated by the modifying the other lines of the same type previously expression "Big Data" and are characterized by the stored; something that is not possible with relational so-called "3V" rule (Chen, 2014).