A Big Data Roadmap for the DB2 Professional
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Management of Polyglot Persistent Environments for Low Latency Data Access in Big Data
Beheer van heterogene opslagtechnologieën voor snelle datatoegang in 'Big Data'-omgevingen Management of Polyglot Persistent Environments for Low Latency Data Access in Big Data Thomas Vanhove Promotoren: prof. dr. ir. F. De Turck, dr. G. Van Seghbroeck Proefschrift ingediend tot het behalen van de graad van Doctor in de ingenieurswetenschappen: computerwetenschappen Vakgroep Informatietechnologie Voorzitter: prof. dr. ir. B. Dhoedt Faculteit Ingenieurswetenschappen en Architectuur Academiejaar 2017 - 2018 ISBN 978-94-6355-084-0 NUR 988, 995 Wettelijk depot: D/2018/10.500/2 QoE-beheer van HTTP-gebaseerde adaptieve videodiensten QoE Management of HTTP Adaptive Streaming Services Niels Bouten Promotoren: prof. dr. ir. F. De Turck, prof. dr. S. Latré Proefschrift ingediend tot het behalen van de graden van Doctor in de ingenieurswetenschappen: computerwetenschappen (Universiteit Gent) en Doctor in de wetenschappen: informatica (Universiteit Antwerpen) Universiteit Gent Faculteit IngenieurswetenschappenVakgroep Informatietechnologie en Architectuur Voorzitter: prof. dr. ir. D. De Zutter Faculteit IngenieurswetenschappenVakgroep Informatietechnologie en Architectuur Departement Wiskunde en Informatica Voorzitter: prof. dr. C. Blondia Leden van de examencommissie: Faculteit Wetenschappen prof. dr. ir. Filip De Turck (promotor) Universiteit Gent - imec Academiejaar 2016 - 2017 dr. Gregory Van Seghbroeck (promotor) Universiteit Gent - imec prof. dr. ir. Daniel¨ De Zutter (voorzitter) Universiteit Gent prof. dr. ir. Frank Gielen Universiteit Gent prof. dr. Guy De Tre´ Universiteit Gent prof. dr. ing. Erik Mannens Universiteit Gent - imec ir. Werner Van Leekwijck Universiteit Antwerpen dr. Anthony Liekens IO Lab Proefschrift tot het behalen van de graad van Doctor in de ingenieurswetenschappen: Computerwetenschappen Academiejaar 2017-2018 Dankwoord Je zou denken dat 5,5 jaar een lange tijd is, maar nu ik hier de laatste woorden van dit boek neerschrijf, lijkt het alsof augustus 2012 toch niet zo veraf is. -

Smart Methods for Retrieving Physiological Data in Physiqual
University of Groningen Bachelor thesis Smart methods for retrieving physiological data in Physiqual Marc Babtist & Sebastian Wehkamp Supervisors: Frank Blaauw & Marco Aiello July, 2016 Contents 1 Introduction 4 1.1 Physiqual . 4 1.2 Problem description . 4 1.3 Research questions . 5 1.4 Document structure . 5 2 Related work 5 2.1 IJkdijk project . 5 2.2 MUMPS . 6 3 Background 7 3.1 Scalability . 7 3.2 CAP theorem . 7 3.3 Reliability models . 7 4 Requirements 8 4.1 Scalability . 8 4.2 Reliability . 9 4.3 Performance . 9 4.4 Open source . 9 5 General database options 9 5.1 Relational or Non-relational . 9 5.2 NoSQL categories . 10 5.2.1 Key-value Stores . 10 5.2.2 Document Stores . 11 5.2.3 Column Family Stores . 11 5.2.4 Graph Stores . 12 5.3 When to use which category . 12 5.4 Conclusion . 12 5.4.1 Key-Value . 13 5.4.2 Document stores . 13 5.4.3 Column family stores . 13 5.4.4 Graph Stores . 13 6 Specific database options 13 6.1 Key-value stores: Riak . 14 6.2 Document stores: MongoDB . 14 6.3 Column Family stores: Cassandra . 14 6.4 Performance comparison . 15 6.4.1 Sensor Data Storage Performance . 16 6.4.2 Conclusion . 16 7 Data model 17 7.1 Modeling rules . 17 7.2 Data model Design . 18 2 7.3 Summary . 18 8 Architecture 20 8.1 Basic layout . 20 8.2 Sidekiq . 21 9 Design decisions 21 9.1 Keyspaces . 21 9.2 Gap determination . -

Nosql Distilled: a Brief Guide to the Emerging World of Polyglot Persistence
NoSQL Distilled This page intentionally left blank NoSQL Distilled A Brief Guide to the Emerging World of Polyglot Persistence Pramod J. Sadalage Martin Fowler Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trademark claim, the designations have been printed with initial capital letters or in all capitals. The authors and publisher have taken care in the preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The publisher offers excellent discounts on this book when ordered in quantity for bulk purchases or special sales, which may include electronic versions and/or custom covers and content particular to your business, training goals, marketing focus, and branding interests. For more information, please contact: U.S. Corporate and Government Sales (800) 382–3419 [email protected] For sales outside the United States please contact: International Sales [email protected] Visit us on the Web: informit.com/aw Library of Congress Cataloging-in-Publication Data: Sadalage, Pramod J. NoSQL distilled : a brief guide to the emerging world of polyglot persistence / Pramod J Sadalage, Martin Fowler. p. cm. Includes bibliographical references and index. -

Not ACID, Not BASE, but SALT a Transaction Processing Perspective on Blockchains
Not ACID, not BASE, but SALT A Transaction Processing Perspective on Blockchains Stefan Tai, Jacob Eberhardt and Markus Klems Information Systems Engineering, Technische Universitat¨ Berlin fst, je, [email protected] Keywords: SALT, blockchain, decentralized, ACID, BASE, transaction processing Abstract: Traditional ACID transactions, typically supported by relational database management systems, emphasize database consistency. BASE provides a model that trades some consistency for availability, and is typically favored by cloud systems and NoSQL data stores. With the increasing popularity of blockchain technology, another alternative to both ACID and BASE is introduced: SALT. In this keynote paper, we present SALT as a model to explain blockchains and their use in application architecture. We take both, a transaction and a transaction processing systems perspective on the SALT model. From a transactions perspective, SALT is about Sequential, Agreed-on, Ledgered, and Tamper-resistant transaction processing. From a systems perspec- tive, SALT is about decentralized transaction processing systems being Symmetric, Admin-free, Ledgered and Time-consensual. We discuss the importance of these dual perspectives, both, when comparing SALT with ACID and BASE, and when engineering blockchain-based applications. We expect the next-generation of decentralized transactional applications to leverage combinations of all three transaction models. 1 INTRODUCTION against. Using the admittedly contrived acronym of SALT, we characterize blockchain-based transactions There is a common belief that blockchains have the – from a transactions perspective – as Sequential, potential to fundamentally disrupt entire industries. Agreed, Ledgered, and Tamper-resistant, and – from Whether we are talking about financial services, the a systems perspective – as Symmetric, Admin-free, sharing economy, the Internet of Things, or future en- Ledgered, and Time-consensual. -

Polyglot Persistency an Adaptive Data Layer for Digital Systems Table of Contents
polyglot persistency an adaptive data layer for digital systems table of contents 03 Executive summary 04 Why NoSQL databases? 05 Persistence store families 06 Assessing NoSQL technologies 10 Polyglot persistency in amdocs digital 14 About Amdocs To properly serve such demand, the underlying data layer executive must adapt from what has been used for the past three decades into a new adaptive data infrastructure capable summary of handling the multiple types of data models that exist in the modern application design, and providing an optimal persistence method – also called polyglot persistence. The digital era has changed the way users consume software. They want to access it from everywhere, at any A polyglot is “someone who speaks or writes several time, get all the capabilities they need in one place, and languages”. Neal Ford first introduced the term ’polyglot complete transactions with a single click of a button. persistence’ in 2006 to express the idea that NoSQL applications would, by their nature, require differing To meet these high standards, enterprises embrace persistence stores based on the type of data and access cloud principles and tools that will allow them to be needs. geographically distributed, intensely transactional, and continuously available. This paper introduces the concept of polyglot persistence along with the guidelines that can be utilized to map Furthermore, they understand that their software must various application use-cases to the appropriate be architected to be agile, distributed and broken up persistence family. The document also provides examples into independent, loosely coupled services, also known as of how Amdocs Digital is leveraging different persistence microservices. -

Oracle Vs. Nosql Vs. Newsql Comparing Database Technology
Oracle vs. NoSQL vs. NewSQL Comparing Database Technology John Ryan Senior Solution Architect, Snowflake Computing Table of Contents The World has Changed . 1 What’s Changed? . 2 What’s the Problem? . .. 3 Performance vs. Availability and Durability . 3 Consistecy vs. Availability . 4 Flexibility vs . Scalability . 5 ACID vs. Eventual Consistency . 6 The OLTP Database Reimagined . 7 Achieving the Impossible! . .. 8 NewSQL Database Technology . 9 VoltDB . 10 MemSQL . 11 Which Applications Need NewSQL Technology? . 12 Conclusion . 13 About the Author . 13 ii The World has Changed The world has changed massively in the past 20 years. Back in the year 2000, a few million users connected to the web using a 56k modem attached to a PC, and Amazon only sold books. Now billions of people are using to their smartphone or tablet 24x7 to buy just about everything, and they’re interacting with Facebook, Twitter and Instagram. The pace has been unstoppable . Expectations have also changed. If a web page doesn’t refresh within seconds we’re quickly frustrated, and go elsewhere. If a web site is down, we fear it’s the end of civilisation as we know it. If a major site is down, it makes global headlines. Instant gratification takes too long! — Ladawn Clare-Panton Aside: If you’re not a seasoned Database Architect, you may want to start with my previous articles on Scalability and Database Architecture. Oracle vs. NoSQL vs. NewSQL eBook 1 What’s Changed? The above leads to a few observations: • Scalability — With potentially explosive traffic growth, IT systems need to quickly grow to meet exponential numbers of transactions • High Availability — IT systems must run 24x7, and be resilient to failure. -
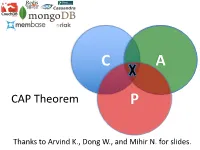
CAP Theorem P
C A CAP Theorem P Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem • “It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3): • (Sequential) Consistency • Availability • Partition-tolerance” • Conjectured by Eric Brewer in ’00 • Proved by Gilbert and Lynch in ’02 • But with definitions that do not match what you’d assume (or Brewer meant) • Influenced the NoSQL mania • Highly controversial: “the CAP theorem encourages engineers to make awful decisions.” – Stonebraker • Many misinterpretations 2 CAP Theorem • Consistency: – Sequential consistency (a data item behaves as if there is one copy) • Availability: – Node failures do not prevent survivors from continuing to operate • Partition-tolerance: – The system continues to operate despite network partitions • CAP says that “A distributed system can satisfy any two of these guarantees at the same time but not all three” 3 C in CAP != C in ACID • They are different! • CAP’s C(onsistency) = sequential consistency – Similar to ACID’s A(tomicity) = Visibility to all future operations • ACID’s C(onsistency) = Does the data satisfy schema constraints 4 Sequential consistency • Makes it appear as if there is one copy of the object • Strict ordering on ops from same client • A single linear ordering across client ops – If client a executes operations {a1, a2, a3, ...}, client b executes operations {b1, b2, b3, ...} – Then, globally, clients observe some serialized version of the sequence • e.g., {a1, b1, b2, a2, ...} (or whatever) Notice -

MDA Process to Extract the Data Model from a Document-Oriented Nosql Database Amal Ait Brahim, Rabah Tighilt Ferhat, Gilles Zurfluh
MDA process to extract the data model from a document-oriented NoSQL database Amal Ait Brahim, Rabah Tighilt Ferhat, Gilles Zurfluh To cite this version: Amal Ait Brahim, Rabah Tighilt Ferhat, Gilles Zurfluh. MDA process to extract the data model from a document-oriented NoSQL database. ICEIS 2019: 21st International Conference on Enterprise Information Systems, May 2019, Heraklion, Greece. pp.141-148, 10.5220/0007676201410148. hal- 02886696 HAL Id: hal-02886696 https://hal.archives-ouvertes.fr/hal-02886696 Submitted on 1 Jul 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Open Archive Toulouse Archive Ouverte OATAO is an open access repository that collects the work of Toulouse researchers and makes it freely available over the web where possible This is an author’s version published in: https://oatao.univ-toulouse.fr/26232 Official URL : https://doi.org/10.5220/0007676201410148 To cite this version: Ait Brahim, Amal and Tighilt Ferhat, Rabah and Zurfluh, Gilles MDA process to extract the data model from a document-oriented NoSQL database. (2019) In: ICEIS 2019: 21st International Conference on Enterprise Information Systems, 3 May 2019 - 5 May 2019 (Heraklion, Greece). -

MDA Process to Extract the Data Model from Document-Oriented Nosql Database
MDA Process to Extract the Data Model from Document-oriented NoSQL Database Amal Ait Brahim, Rabah Tighilt Ferhat and Gilles Zurfluh Toulouse Institute of Computer Science Research (IRIT), Toulouse Capitole University, Toulouse, France Keywords: Big Data, NoSQL, Model Extraction, Schema Less, MDA, QVT. Abstract: In recent years, the need to use NoSQL systems to store and exploit big data has been steadily increasing. Most of these systems are characterized by the property "schema less" which means absence of the data model when creating a database. This property brings an undeniable flexibility by allowing the evolution of the model during the exploitation of the base. However, query expression requires a precise knowledge of the data model. In this article, we propose a process to automatically extract the physical model from a document- oriented NoSQL database. To do this, we use the Model Driven Architecture (MDA) that provides a formal framework for automatic model transformation. From a NoSQL database, we propose formal transformation rules with QVT to generate the physical model. An experimentation of the extraction process was performed on the case of a medical application. 1 INTRODUCTION however that it is absent in some systems such as Cassandra and Riak TS. The "schema less" property Recently, there has been an explosion of data offers undeniable flexibility by allowing the model to generated and accumulated by more and more evolve easily. For example, the addition of new numerous and diversified computing devices. attributes in an existing line is done without Databases thus constituted are designated by the modifying the other lines of the same type previously expression "Big Data" and are characterized by the stored; something that is not possible with relational so-called "3V" rule (Chen, 2014). -

What Is Nosql? the Only Thing That All Nosql Solutions Providers Generally Agree on Is That the Term “Nosql” Isn’T Perfect, but It Is Catchy
NoSQL GREG SYSADMINBURD Greg Burd is a Developer Choosing between databases used to boil down to examining the differences Advocate for Basho between the available commercial and open source relational databases . The term Technologies, makers of Riak. “database” had become synonymous with SQL, and for a while not much else came Before Basho, Greg spent close to being a viable solution for data storage . But recently there has been a shift nearly ten years as the product manager for in the database landscape . When considering options for data storage, there is a Berkeley DB at Sleepycat Software and then new game in town: NoSQL databases . In this article I’ll introduce this new cat- at Oracle. Previously, Greg worked for NeXT egory of databases, examine where they came from and what they are good for, and Computer, Sun Microsystems, and KnowNow. help you understand whether you, too, should be considering a NoSQL solution in Greg has long been an avid supporter of open place of, or in addition to, your RDBMS database . source software. [email protected] What Is NoSQL? The only thing that all NoSQL solutions providers generally agree on is that the term “NoSQL” isn’t perfect, but it is catchy . Most agree that the “no” stands for “not only”—an admission that the goal is not to reject SQL but, rather, to compensate for the technical limitations shared by the majority of relational database implemen- tations . In fact, NoSQL is more a rejection of a particular software and hardware architecture for databases than of any single technology, language, or product . -

Nosql Database Technology
NoSQL Database Technology Post-relational data management for interactive software systems NOSQL DATABASE TECHNOLOGY Table of Contents Summary 3 Interactive software has changed 4 Users – 4 Applications – 5 Infrastructure – 5 Application architecture has changed 6 Database architecture has not kept pace 7 Tactics to extend the useful scope of RDBMS technology 8 Sharding – 8 Denormalizing – 9 Distributed caching – 10 “NoSQL” database technologies 11 Mobile application data synchronization 13 Open source and commercial NoSQL database technologies 14 2 © 2011 COUCHBASE ALL RIGHTS RESERVED. WWW.COUCHBASE.COM NOSQL DATABASE TECHNOLOGY Summary Interactive software (software with which a person iteratively interacts in real time) has changed in fundamental ways over the last 35 years. The “online” systems of the 1970s have, through a series of intermediate transformations, evolved into today’s web and mobile appli- cations. These systems solve new problems for potentially vastly larger user populations, and they execute atop a computing infrastructure that has changed even more radically over the years. The architecture of these software systems has likewise transformed. A modern web ap- plication can support millions of concurrent users by spreading load across a collection of application servers behind a load balancer. Changes in application behavior can be rolled out incrementally without requiring application downtime by gradually replacing the software on individual servers. Adjustments to application capacity are easily made by changing the number of application servers. But database technology has not kept pace. Relational database technology, invented in the 1970s and still in widespread use today, was optimized for the applications, users and inf- rastructure of that era. -

Multi-Model Database Management Systems - a Look Forward Zhen Hua Liu 1 , Jiaheng Lu2, Dieter Gawlick1, Heli Helskyaho2,3
Multi-Model Database Management Systems - a Look Forward Zhen Hua Liu 1 , Jiaheng Lu2, Dieter Gawlick1, Heli Helskyaho2,3 Gregory Pogossiants4, Zhe Wu1 1Oracle Corporation 2University of Helsinki 3Miracle Finland Oy 4Soulmates.ai Abstract. The existence of the variety of data models and their associated data processing technologies make data management extremely complex. In this paper, we envision a single Multi-Model DataBase Management Systems (MMDBMS) providing declarative accesses to a variety of data models. We briefly review the history of the evolution of the DBMS technology to derive requirements of MMDBMSs and then we illustrate our ideas of building MMDBMSs satisfying those requirements. Since the relational algebra is not powerful enough to provide a mathematical foundation for MMDBMSs, we promote the category theory as a new theoretical foundation, which is a generalization of the set theory. We also suggest a set of shared data infrastructure services among data models to support “Just-In-Time” multi-model data access autonomously. 1 INTRODUCTION – why MMDBMS? Here is a short history of databases: Initially, database management systems sup- ported the hierarchical and the network model (e.g., IBM’s IMS and GE’s IDS re- spectively). These databases evolved very fast and developed the core infrastructures, such as journaling, transactions, locking, 2PC (group and fast commit), recovery, restart, fault tolerance, high performance, TP-monitors, messaging, main storage da- tabases, and much, much more. We still use these concepts today. In the 80’ and 90’, these databases were widely replaced by the relational database management systems (RDBMS). The main argument is its solid theoretical foundation: set based relational data model and declarative query language (SQL) based on abstract algebra over set processing.