Package 'Cnum'
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Dictionary of Chinese Characters: Accessed by Phonetics
A dictionary of Chinese characters ‘The whole thrust of the work is that it is more helpful to learners of Chinese characters to see them in terms of sound, than in visual terms. It is a radical, provocative and constructive idea.’ Dr Valerie Pellatt, University of Newcastle. By arranging frequently used characters under the phonetic element they have in common, rather than only under their radical, the Dictionary encourages the student to link characters according to their phonetic. The system of cross refer- encing then allows the student to find easily all the characters in the Dictionary which have the same phonetic element, thus helping to fix in the memory the link between a character and its sound and meaning. More controversially, the book aims to alleviate the confusion that similar looking characters can cause by printing them alongside each other. All characters are given in both their traditional and simplified forms. Appendix A clarifies the choice of characters listed while Appendix B provides a list of the radicals with detailed comments on usage. The Dictionary has a full pinyin and radical index. This innovative resource will be an excellent study-aid for students with a basic grasp of Chinese, whether they are studying with a teacher or learning on their own. Dr Stewart Paton was Head of the Department of Languages at Heriot-Watt University, Edinburgh, from 1976 to 1981. A dictionary of Chinese characters Accessed by phonetics Stewart Paton First published 2008 by Routledge 2 Park Square, Milton Park, Abingdon, OX14 4RN Simultaneously published in the USA and Canada by Routledge 270 Madison Ave, New York, NY 10016 Routledge is an imprint of the Taylor & Francis Group, an informa business This edition published in the Taylor & Francis e-Library, 2008. -

Old Scripts, New Actors: European Encounters with Chinese Writing, 1550-1700 *
EASTM 26 (2007): 68-116 Old Scripts, New Actors: European Encounters with Chinese Writing, 1550-1700 * Bruce Rusk [Bruce Rusk is Assistant Professor of Chinese Literature in the Department of Asian Studies at Cornell University. From 2004 to 2006 he was Mellon Humani- ties Fellow in the Asian Languages Department at Stanford University. His dis- sertation was entitled “The Rogue Classicist: Feng Fang and his Forgeries” (UCLA, 2004) and his article “Not Written in Stone: Ming Readers of the Great Learning and the Impact of Forgery” appeared in The Harvard Journal of Asi- atic Studies 66.1 (June 2006).] * * * But if a savage or a moon-man came And found a page, a furrowed runic field, And curiously studied line and frame: How strange would be the world that they revealed. A magic gallery of oddities. He would see A and B as man and beast, As moving tongues or arms or legs or eyes, Now slow, now rushing, all constraint released, Like prints of ravens’ feet upon the snow. — Herman Hesse 1 Visitors to the Far East from early modern Europe reported many marvels, among them a writing system unlike any familiar alphabetic script. That the in- habitants of Cathay “in a single character make several letters that comprise one * My thanks to all those who provided feedback on previous versions of this paper, especially the workshop commentator, Anthony Grafton, and Liam Brockey, Benjamin Elman, and Martin Heijdra as well as to the Humanities Fellows at Stanford. I thank the two anonymous readers, whose thoughtful comments were invaluable in the revision of this essay. -
The Totality of Chinese Characters – a Digital Perspective
Journal of Chinese Language and Computing 17 (2): 107-125 107 The Totality of Chinese Characters – A Digital Perspective Shouhui Zhao CRPP, NIE of Nanyang Technological University, Singapore 647616 [email protected] Dongbo Zhang Department of Modern Language, Carnegie Mellon University, PA 15231, USA [email protected] Abstract That the Chinese IT industry has been recurrently plagued by the deficiencies of the Chinese writing system has been well known. In this paper, we provided an examination of the complex factors involved in the process of streamlining the total number (TN) of Chinese characters (hanzi), and critically reviewed the existing and emerging theoretical frameworks advocated by language policy (LP) practitioners over the years in addressing the issue of fixing the TN. We first identified three referencing points when people from different fields talk about the TN of hanzi. Based on this review of the concept of TN, we discussed how the ever-expanding, indefinable and unpredictable TN poses problems to Chinese information processing. From a sociolinguistic perspective, we then pointed out the main external causes that lead to the dilemma of TN restriction. Various proposals, articulated since the early 20th century, were then reviewed and their failures were briefly discussed. Lastly, the most recent visionary model to deal with hanzi’s TN was introduced and how it informs the planning of TN of Chinese characters was also discussed. It is hoped, this study will shed some light on the in-depth understanding towards one difficult aspect of Chinese script modernization and computerization. Keywords Chinese characters, total number, variant forms (VF), rarely used characters (RC), encoding set 1. -
What Do Teachers of Chinese As a Foreign Language Believe About Teaching Chinese Literacy to English Speakers?
What do Teachers of Chinese as a Foreign Language Believe about Teaching Chinese Literacy to English Speakers? By © 2018 Sheree A. W. Willis DPhil, University of Kansas, 2018 M.A., University of Kansas, 2000 B.A., University of Kansas, 1979 Submitted to the graduate degree program in Curriculum and Instruction and the Graduate Faculty of the University of Kansas in partial fulfillment of the requirements for the degree of Doctor of Philosophy. Chair: Lizette Peter Steven White Heidi Hallman Dennis Karney J. Megan Greene Date Defended: 24 July 2018 The dissertation committee for Sheree A. W. Willis certifies that this is the approved version of the following dissertation: What do Teachers of Chinese as a Foreign Language Believe about Teaching Chinese Literacy to English Speakers? Chair: Lizette Peter Date Approved: 24 July 2018 ii Abstract This study was motivated by a recognition of the difficulties of teaching literacy in Chinese as a foreign language (CFL). CFL teachers deliberate over pedagogy, content sequencing, goals for literacy learning, and the use of authentic materials. These issues are complicated by the long history of Chinese literacy practices and the cultural significance of the writing system. The teachers bring rich personal histories and expertise, shaped by this cultural background, to their teaching. The study aims to gain a better understanding of teacher cognition on teaching Chinese literacy, to inform the discussion on improving CFL literacy instruction. The participants are five teachers raised and educated in China who are currently teaching in U.S. K-12 schools. This qualitative study employs semi-structured interviews, triangulated with lesson plans and classroom observations. -

The Chinese Names of the Four Directions Laurent Sagart
The Chinese names of the four directions Laurent Sagart To cite this version: Laurent Sagart. The Chinese names of the four directions. Journal of the American Oriental Society, 2004, 124 (1), pp.69-76. halshs-00087314 HAL Id: halshs-00087314 https://halshs.archives-ouvertes.fr/halshs-00087314 Submitted on 22 Jul 2006 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. The Chinese names of the four directions1 Laurent SAGART CNRS, Paris Abstract : It is shown that the Old Chinese terms for the four directions: 東 'east', 西 'west', 南 'south' and 北 'north', form two etymological pairs, one of which (north- south) relates to the notions of front and back (of the house: houses faced south in early China ) and the other (east-west) to notions of beginning vs. ceasing movement, applied to the sun. The relevant word families are adumbrated, the morphology explained and Sino-Tibetan cognates established. This printout:21/07/2006 1:03 PM Sagart 1. Introduction The Chinese characters for the four directions: 東 'east', 西 'west', 南 'south' and 北 'north' are attested in the epigrapy from the Shang inscriptions (ca. -

APPENDIX: the 36 Oaths of China's Triad Societies
APPENDIX: The 36 Oaths of China's Triad Societies 1. Mter having entered the Hong Gates I must treat the parents and relatives of my sworn brothers as mine own kin. I shall suffer death by five thunderbolts if I do not keep this oath. 2. I shall assist my sworn brothers to bury their parents and brothers by offering financial or physical assistance. I shall be killed by five thunderbolts if I pretend to have no knowledge of their troubles. 3. When Hong brothers visit my house I shall provide them with board and lodging. I shall be killed by a myriad of swords if I treat them as strangers. 4. I will always acknowledge my Hong brothers when they identify themselves. If I ignore them I shall be killed by a myriad of swords. 5. I shall not disclose the secrets of the Hong family, not even to my parents, brothers or wife. I shall never disclose the secrets for money. I shall be killed by a myriad of swords if I do so. 6. I shall never betray my sworn brothers. If, through a misunder standing, I have caused the arrest of one of my brothers, I must release him immediately. If I break this oath I will be killed by five thunderbolts. 7. I will offer assistance to my sworn brothers who are in trouble, in order that they may pay their passage fee. If I break this oath, may I be killed by five thunderbolts. 8. I must not cause harm or bring trouble to my sworn brothers or Incense Master. -
Powers of Ten
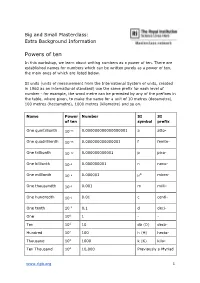
Big and Small Masterclass: Extra Background Information Powers of ten In this workshop, we learn about writing numbers as a power of ten. There are established names for numbers which can be written purely as a power of ten, the main ones of which are listed below. SI units (units of measurement from the International System of units, created in 1960 as an international standard) use the same prefix for each level of number - for example, the word metre can be preceded by any of the prefixes in the table, where given, to make the name for a unit of 10 metres (decametre), 100 metres (hectometre), 1000 metres (kilometre) and so on. Name Power Number SI SI of ten symbol prefix One quintillionth 10−18 0.000000000000000001 a atto- One quadrillionth 10−15 0.000000000000001 f femto- One trillionth 10−12 0.000000000001 p pico- One billionth 10−9 0.000000001 n nano- One millionth 10−6 0.000001 µ* micro- One thousandth 10−3 0.001 m milli- One hundredth 10−2 0.01 c centi- One tenth 10-1 0.1 d deci- One 100 1 - - Ten 101 10 da (D) deca- Hundred 102 100 h (H) hecto- Thousand 103 1000 k (K) kilo- Ten Thousand 104 10,000 Previously a Myriad www.rigb.org 1 100 Thousand 105 100,000 Previously a Lakh Million 106 1,000,000 M mega- Ten Million 107 10,000,000 Previously a Crore Billion 109 1,000,000,000 G giga- Trillion 1012 1,000,000,000,000 T tera- Quadrillion 1015 1,000,000,000,000,000 P peta- Quintillion 1018 1,000,000,000,000,000,000 E exa- Sextillion 2021 1,000,000,000,000,000,000,000 Z zetta- Septillion 1024 1,000,000,000,000,000,000,000,000 Y yotta- Octillion 1027 1,000,000,000,000,000,000,000,000,000 B bronta- * This is the Greek letter mu, used to denote ‘micro’, as ‘m’ was already taken. -

The Cantonese Made Easy Vocabulary
THE CANTONESE MADE EASY VOCABULARY A Small Dictionary in English and Cantonese, containing Words and Phrases used in the Spoken Language, with the Classifiers indicated for each Noun, and Definitions of the Different Shades of Meaning, as well as Notes on the Different uses of some of the Words where Ambiguity might otherwise arise THIRD EDITION Revised and Enlarged BY J. DYER BALL, I.S.O., M.R.A.S., ETC., OF HIS MAJESTY'S CIVIL SERVICE, HONGKONG Author of "Cantonese Made Easy," "How to Speak Cantonese," "How to Write Chinese," " Hakka Made Easy," "Things Chinese," "The Celestial and His Religions," &c., &c., &c.. HONGKONG: • KELLY & WALSH, LD. SHANGHAI, SINGAPORE, AND YOKOHAMA 1908 [,'7/ Rights Reserved^ (QatttcU Uttioerattg SItbrarg Itijata, Ntm ^oxk BOUGHT WITH THE INCOME OF THE WASON ENDOWMENT FUND THE GIFT OF CHARLES W. WASON CORNELL 76 1916 The date shows when this .volume was taken. HOME USE RULES llbooks subject to recall All borrowers must regis- 'ter In the library to borrow )oks for home use. All books must be re- turned at end of college year for inspection and repairs. Limited books must be returned within the four week limit and not renewed. Students must return all books before leaving town. Officers should arrange for the return of books wanted during their absence from town. Volumes of periodicals and of pamphlets are held in the library as much as possible. For special pur- poses they are given out for a limited time. Borrowers should not use their library privileges for the benefit of other persons. Books of special value / and gift books, when the giver wishes it, are not allowed to circulate. -

UC Riverside UC Riverside Electronic Theses and Dissertations
UC Riverside UC Riverside Electronic Theses and Dissertations Title Hong Kong Dreams and Disney Fantasies: How Hong Kong Disneyland (Controversially) Indigenizes Space, Labor, and Consumption Permalink https://escholarship.org/uc/item/5g5601ft Author Banh, Jenny Publication Date 2013 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA RIVERSIDE Hong Kong Dreams and Disney Fantasies: How Hong Kong Disneyland (Controversially) Indigenizes Space, Labor, and Consumption A Dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Anthropology by Jenny Banh March 2014 Dissertation Committee: Dr. Yolanda T. Moses, Chairperson Dr. Christina Schwenkel Dr. Lynda S. Bell Dr. Thomas C. Patterson Copyright by Jenny Banh 2014 The Dissertation of Jenny Banh is approved: Committee Chairperson University of California, Riverside ACKNOWLEDGEMENTS I would like to thank those Hong Kong residents who took time out of their busy schedules to be interviewed. They were truly kind and often further recommended more people to interview. During my time in the field I taught literature, journalism, and SATs to HK students and their kindness was a hug whenever I needed it. They taught me as a lot about the liminality of Hong Kong culture. My dissertation committee of Yolanda Moses, Christine Schwenkel, Tracy Fisher, Michael Kearney, Thomas Patterson, and Lynda Bell guided me steadfastly. I would also like to acknowledge Dr. Michael Kearney who was a wonderful kind advisor and I miss him often. Lynda Bell reined me in and gave me a lot of structure, information, and guidance that I am very grateful for. -

Alphabetic and Multiplicative Systems of Numeration
Section 1.2 Alphabetic and Multiplicative Systems of Numeration Alphabetic Systems The second basic type of system of numeration developed was based on the written alphabet of the culture. Writing words with an alphabet, unlike the Egyptian pictograms, involved using a symbol for each phonetic sound. This allows the culture to write down a huge number of different words with just a few dozen symbols. The earliest written alphabet was that of the Phoenicia, dating from about the fifteenth century BCE. The peoples in the area surrounding Phoenicia each adapted the Phoenician alphabet to their needs, but most of them retained the basic order of the original Phoenician letters. Since the order of the letters remained fairly constant, it was a logical step to use the alphabet as a counting tool, just like using pebbles or sticks as counting tools. Start with “A” for one, “B” for two and continue in this fashion. The disadvantage to this simple numbering system is that a person can only count to about twenty or thirty using letters. Later versions of alphabetic systems assigned numerical values to the letters by first assigning 1-9 to the first nine letters, then 10-90 in multiples of 10 to the next nine letters, then 100-900 in multiples of 100 to the last nine letters. This allows an alphabetic system to represent numbers from 1-999 easily using only 27 letters and an additive scheme for combining the values of the symbols. Alphabetic systems were developed by many peoples, including the Armenians, Hebrews and Greeks. We will illustrate this type of system by looking at the Ionic Greek system of numeration. -

Corpus-Based Chinese Studies a Historical Review from the 1920S to the Present
Corpus-based Chinese studies A historical review from the 1920s to the present Jiajin Xu Beijing Foreign Studies University This article reviews corpus‑based Chinese studies, both applied and theoretical, from the 1920s to the present. It will be shown that, while corpus‑based Chinese studies have been gaining momentum for only the last couple of decades, the roots of Chinese corpus linguistics go all the way back to the beginning of the 20th century. Today the bulk of corpus‑based Chinese studies is oriented toward applied linguistics, with the compilation of frequency character/word lists and interlanguage Chinese studies being the most popular types of research. In addi‑ tion to applied linguistic studies, this overview also highlights some innovative corpus studies on lexical and grammatical aspects of both classical and modern Chinese, as well as studies of sociolinguistic variation and discourse pragmatics. Overall, important groundwork in Chinese corpus linguistics is acknowledged and future directions are discussed. Keywords: Chinese, corpus linguistics, lexical frequency studies, interlanguage studies, syntactic/grammatical studies, discourse‑pragmatics, classical/historical Chinese studies 关键词: 汉语, 语料库语言学, 字/词频研究, 中介语研究, 句法研究, 话语语用 研究, 古汉语研究 1. Introduction The field of corpus research can be described as ‘a tale of many C’s’: corpus, corpo‑ ra, collection (of texts), collocation, colligation, concgram, concordance, context, computerised; the list of C‑initialed keywords could certainly go on. We can fur‑ ther divide these C‑words into two types: ‘corpus as data’ (i.e. corpus, corpora, col‑ lection of texts, computerised, etc.) and ‘corpus as method’ (i.e. collocation, con‑ cordance, concgram, etc.). In the current linguistics literature, ‘corpus’ is mainly Chinese Language and Discourse 6:2 (2015), 218–244. -

The Most Common Chinese Characters in Order of Frequency
The most common Chinese characters in order of frequency http://www.zein.se/patrick/3000char.html • All characters are presented in falling statistical order with the most commonly used characters first (ie from 1 to 3000). • Alternative forms of characters are specified within parentheses – in which case "F" marks full (or traditional) forms, "S" marks simplified (or modern) forms and "A" marks alternative forms (mostly special numerals). • Pronunciation is specified according to Pinyin and written within brackets "[...]". After each given pronunciation, a number of possible translations are listed. If a character corresponds closely to a somewhat longer word (usually a word that contains the character in question), the longer word is given in the list of translations marked with parentheses and a "=". • After the translation of each character, example words containing the character are often listed – these words are separated by semi commas. No guarantee is given that all the most common words are listed or that the given examples are very common. • Some of the listed pronunciations are less used than others, and in those cases translations and examples may lack. • Grammatical particles, classifiers and other special translations are marked with hooks "<...>". • Curly brackets "{...}" are mostly used when giving references to characters that are similar to the listed ones either in shape. This is to help you avoid miswriting/misreading. The same marking is also used for references to characters with similar meaning but different pronunciation. • Additional information of other sorts is sometimes given. • If the characters are not displayed correctly, verify that the encoding is set to GB2312.