Polynomials Are Continuous Functions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Brief but Important Note on the Product Rule
A brief but important note on the product rule Peter Merrotsy The University of Western Australia [email protected] The product rule in the Australian Curriculum he product rule refers to the derivative of the product of two functions Texpressed in terms of the functions and their derivatives. This result first naturally appears in the subject Mathematical Methods in the senior secondary Australian Curriculum (Australian Curriculum, Assessment and Reporting Authority [ACARA], n.d.b). In the curriculum content, it is mentioned by name only (Unit 3, Topic 1, ACMMM104). Elsewhere (Glossary, p. 6), detail is given in the form: If h(x) = f(x) g(x), then h'(x) = f(x) g'(x) + f '(x) g(x) (1) or, in Leibniz notation, d dv du ()u v = u + v (2) dx dx dx presupposing, of course, that both u and v are functions of x. In the Australian Capital Territory (ACT Board of Senior Secondary Studies, 2014, pp. 28, 43), Tasmania (Tasmanian Qualifications Authority, 2014, p. 21) and Western Australia (School Curriculum and Standards Authority, 2014, WACE, Mathematical Methods Year 12, pp. 9, 22), these statements of the Australian Senior Mathematics Journal vol. 30 no. 2 product rule have been adopted without further commentary. Elsewhere, there are varying attempts at elaboration. The SACE Board of South Australia (2015, p. 29) refers simply to “differentiating functions of the form , using the product rule.” In Queensland (Queensland Studies Authority, 2008, p. 14), a slight shift in notation is suggested by referring to rules for differentiation, including: d []f (t)g(t) (product rule) (3) dt At first, the Victorian Curriculum and Assessment Authority (2015, p. -

A Quotient Rule Integration by Parts Formula Jennifer Switkes ([email protected]), California State Polytechnic Univer- Sity, Pomona, CA 91768
A Quotient Rule Integration by Parts Formula Jennifer Switkes ([email protected]), California State Polytechnic Univer- sity, Pomona, CA 91768 In a recent calculus course, I introduced the technique of Integration by Parts as an integration rule corresponding to the Product Rule for differentiation. I showed my students the standard derivation of the Integration by Parts formula as presented in [1]: By the Product Rule, if f (x) and g(x) are differentiable functions, then d f (x)g(x) = f (x)g(x) + g(x) f (x). dx Integrating on both sides of this equation, f (x)g(x) + g(x) f (x) dx = f (x)g(x), which may be rearranged to obtain f (x)g(x) dx = f (x)g(x) − g(x) f (x) dx. Letting U = f (x) and V = g(x) and observing that dU = f (x) dx and dV = g(x) dx, we obtain the familiar Integration by Parts formula UdV= UV − VdU. (1) My student Victor asked if we could do a similar thing with the Quotient Rule. While the other students thought this was a crazy idea, I was intrigued. Below, I derive a Quotient Rule Integration by Parts formula, apply the resulting integration formula to an example, and discuss reasons why this formula does not appear in calculus texts. By the Quotient Rule, if f (x) and g(x) are differentiable functions, then ( ) ( ) ( ) − ( ) ( ) d f x = g x f x f x g x . dx g(x) [g(x)]2 Integrating both sides of this equation, we get f (x) g(x) f (x) − f (x)g(x) = dx. -
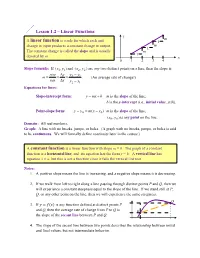
Lesson 1.2 – Linear Functions Y M a Linear Function Is a Rule for Which Each Unit 1 Change in Input Produces a Constant Change in Output
Lesson 1.2 – Linear Functions y m A linear function is a rule for which each unit 1 change in input produces a constant change in output. m 1 The constant change is called the slope and is usually m 1 denoted by m. x 0 1 2 3 4 Slope formula: If (x1, y1)and (x2 , y2 ) are any two distinct points on a line, then the slope is rise y y y m 2 1 . (An average rate of change!) run x x x 2 1 Equations for lines: Slope-intercept form: y mx b m is the slope of the line; b is the y-intercept (i.e., initial value, y(0)). Point-slope form: y y0 m(x x0 ) m is the slope of the line; (x0, y0 ) is any point on the line. Domain: All real numbers. Graph: A line with no breaks, jumps, or holes. (A graph with no breaks, jumps, or holes is said to be continuous. We will formally define continuity later in the course.) A constant function is a linear function with slope m = 0. The graph of a constant function is a horizontal line, and its equation has the form y = b. A vertical line has equation x = a, but this is not a function since it fails the vertical line test. Notes: 1. A positive slope means the line is increasing, and a negative slope means it is decreasing. 2. If we walk from left to right along a line passing through distinct points P and Q, then we will experience a constant steepness equal to the slope of the line. -

Calculus Terminology
AP Calculus BC Calculus Terminology Absolute Convergence Asymptote Continued Sum Absolute Maximum Average Rate of Change Continuous Function Absolute Minimum Average Value of a Function Continuously Differentiable Function Absolutely Convergent Axis of Rotation Converge Acceleration Boundary Value Problem Converge Absolutely Alternating Series Bounded Function Converge Conditionally Alternating Series Remainder Bounded Sequence Convergence Tests Alternating Series Test Bounds of Integration Convergent Sequence Analytic Methods Calculus Convergent Series Annulus Cartesian Form Critical Number Antiderivative of a Function Cavalieri’s Principle Critical Point Approximation by Differentials Center of Mass Formula Critical Value Arc Length of a Curve Centroid Curly d Area below a Curve Chain Rule Curve Area between Curves Comparison Test Curve Sketching Area of an Ellipse Concave Cusp Area of a Parabolic Segment Concave Down Cylindrical Shell Method Area under a Curve Concave Up Decreasing Function Area Using Parametric Equations Conditional Convergence Definite Integral Area Using Polar Coordinates Constant Term Definite Integral Rules Degenerate Divergent Series Function Operations Del Operator e Fundamental Theorem of Calculus Deleted Neighborhood Ellipsoid GLB Derivative End Behavior Global Maximum Derivative of a Power Series Essential Discontinuity Global Minimum Derivative Rules Explicit Differentiation Golden Spiral Difference Quotient Explicit Function Graphic Methods Differentiable Exponential Decay Greatest Lower Bound Differential -

Matrix Calculus
Appendix D Matrix Calculus From too much study, and from extreme passion, cometh madnesse. Isaac Newton [205, §5] − D.1 Gradient, Directional derivative, Taylor series D.1.1 Gradients Gradient of a differentiable real function f(x) : RK R with respect to its vector argument is defined uniquely in terms of partial derivatives→ ∂f(x) ∂x1 ∂f(x) , ∂x2 RK f(x) . (2053) ∇ . ∈ . ∂f(x) ∂xK while the second-order gradient of the twice differentiable real function with respect to its vector argument is traditionally called the Hessian; 2 2 2 ∂ f(x) ∂ f(x) ∂ f(x) 2 ∂x1 ∂x1∂x2 ··· ∂x1∂xK 2 2 2 ∂ f(x) ∂ f(x) ∂ f(x) 2 2 K f(x) , ∂x2∂x1 ∂x2 ··· ∂x2∂xK S (2054) ∇ . ∈ . .. 2 2 2 ∂ f(x) ∂ f(x) ∂ f(x) 2 ∂xK ∂x1 ∂xK ∂x2 ∂x ··· K interpreted ∂f(x) ∂f(x) 2 ∂ ∂ 2 ∂ f(x) ∂x1 ∂x2 ∂ f(x) = = = (2055) ∂x1∂x2 ³∂x2 ´ ³∂x1 ´ ∂x2∂x1 Dattorro, Convex Optimization Euclidean Distance Geometry, Mεβoo, 2005, v2020.02.29. 599 600 APPENDIX D. MATRIX CALCULUS The gradient of vector-valued function v(x) : R RN on real domain is a row vector → v(x) , ∂v1(x) ∂v2(x) ∂vN (x) RN (2056) ∇ ∂x ∂x ··· ∂x ∈ h i while the second-order gradient is 2 2 2 2 , ∂ v1(x) ∂ v2(x) ∂ vN (x) RN v(x) 2 2 2 (2057) ∇ ∂x ∂x ··· ∂x ∈ h i Gradient of vector-valued function h(x) : RK RN on vector domain is → ∂h1(x) ∂h2(x) ∂hN (x) ∂x1 ∂x1 ··· ∂x1 ∂h1(x) ∂h2(x) ∂hN (x) h(x) , ∂x2 ∂x2 ··· ∂x2 ∇ . -

CHAPTER 1 VECTOR ANALYSIS ̂ ̂ Distribution Rule Vector Components
8/29/2016 CHAPTER 1 1. VECTOR ALGEBRA VECTOR ANALYSIS Addition of two vectors 8/24/16 Communicative Chap. 1 Vector Analysis 1 Vector Chap. Associative Definition Multiplication by a scalar Distribution Dot product of two vectors Lee Chow · , & Department of Physics · ·· University of Central Florida ·· 2 Orlando, FL 32816 • Cross-product of two vectors Cross-product follows distributive rule but not the commutative rule. 8/24/16 8/24/16 where , Chap. 1 Vector Analysis 1 Vector Chap. Analysis 1 Vector Chap. In a strict sense, if and are vectors, the cross product of two vectors is a pseudo-vector. Distribution rule A vector is defined as a mathematical quantity But which transform like a position vector: so ̂ ̂ 3 4 Vector components Even though vector operations is independent of the choice of coordinate system, it is often easier 8/24/16 8/24/16 · to set up Cartesian coordinates and work with Analysis 1 Vector Chap. Analysis 1 Vector Chap. the components of a vector. where , , and are unit vectors which are perpendicular to each other. , , and are components of in the x-, y- and z- direction. 5 6 1 8/29/2016 Vector triple products · · · · · 8/24/16 8/24/16 · ( · Chap. 1 Vector Analysis 1 Vector Chap. Analysis 1 Vector Chap. · · · All these vector products can be verified using the vector component method. It is usually a tedious process, but not a difficult process. = - 7 8 Position, displacement, and separation vectors Infinitesimal displacement vector is given by The location of a point (x, y, z) in Cartesian coordinate ℓ as shown below can be defined as a vector from (0,0,0) 8/24/16 In general, when a charge is not at the origin, say at 8/24/16 to (x, y, z) is given by (x’, y’, z’), to find the field produced by this Chap. -

9 Power and Polynomial Functions
Arkansas Tech University MATH 2243: Business Calculus Dr. Marcel B. Finan 9 Power and Polynomial Functions A function f(x) is a power function of x if there is a constant k such that f(x) = kxn If n > 0, then we say that f(x) is proportional to the nth power of x: If n < 0 then f(x) is said to be inversely proportional to the nth power of x. We call k the constant of proportionality. Example 9.1 (a) The strength, S, of a beam is proportional to the square of its thickness, h: Write a formula for S in terms of h: (b) The gravitational force, F; between two bodies is inversely proportional to the square of the distance d between them. Write a formula for F in terms of d: Solution. 2 k (a) S = kh ; where k > 0: (b) F = d2 ; k > 0: A power function f(x) = kxn , with n a positive integer, is called a mono- mial function. A polynomial function is a sum of several monomial func- tions. Typically, a polynomial function is a function of the form n n−1 f(x) = anx + an−1x + ··· + a1x + a0; an 6= 0 where an; an−1; ··· ; a1; a0 are all real numbers, called the coefficients of f(x): The number n is a non-negative integer. It is called the degree of the polynomial. A polynomial of degree zero is just a constant function. A polynomial of degree one is a linear function, of degree two a quadratic function, etc. The number an is called the leading coefficient and a0 is called the constant term. -

Polynomials.Pdf
POLYNOMIALS James T. Smith San Francisco State University For any real coefficients a0,a1,...,an with n $ 0 and an =' 0, the function p defined by setting n p(x) = a0 + a1 x + AAA + an x for all real x is called a real polynomial of degree n. Often, we write n = degree p and call an its leading coefficient. The constant function with value zero is regarded as a real polynomial of degree –1. For each n the set of all polynomials with degree # n is closed under addition, subtraction, and multiplication by scalars. The algebra of polynomials of degree # 0 —the constant functions—is the same as that of real num- bers, and you need not distinguish between those concepts. Polynomials of degrees 1 and 2 are called linear and quadratic. Polynomial multiplication Suppose f and g are nonzero polynomials of degrees m and n: m f (x) = a0 + a1 x + AAA + am x & am =' 0, n g(x) = b0 + b1 x + AAA + bn x & bn =' 0. Their product fg is a nonzero polynomial of degree m + n: m+n f (x) g(x) = a 0 b 0 + AAA + a m bn x & a m bn =' 0. From this you can deduce the cancellation law: if f, g, and h are polynomials, f =' 0, and fg = f h, then g = h. For then you have 0 = fg – f h = f ( g – h), hence g – h = 0. Note the analogy between this wording of the cancellation law and the corresponding fact about multiplication of numbers. One of the most useful results about integer multiplication is the unique factoriza- tion theorem: for every integer f > 1 there exist primes p1 ,..., pm and integers e1 em e1 ,...,em > 0 such that f = pp1 " m ; the set consisting of all pairs <pk , ek > is unique. -
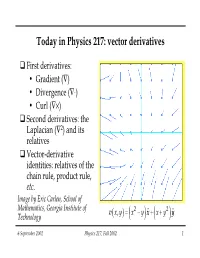
Today in Physics 217: Vector Derivatives
Today in Physics 217: vector derivatives First derivatives: • Gradient (—) • Divergence (—◊) •Curl (—¥) Second derivatives: the Laplacian (—2) and its relatives Vector-derivative identities: relatives of the chain rule, product rule, etc. Image by Eric Carlen, School of Mathematics, Georgia Institute of 22 vxyxy, =−++ x yˆˆ x y Technology ()()() 6 September 2002 Physics 217, Fall 2002 1 Differential vector calculus df/dx provides us with information on how quickly a function of one variable, f(x), changes. For instance, when the argument changes by an infinitesimal amount, from x to x+dx, f changes by df, given by df df= dx dx In three dimensions, the function f will in general be a function of x, y, and z: f(x, y, z). The change in f is equal to ∂∂∂fff df=++ dx dy dz ∂∂∂xyz ∂∂∂fff =++⋅++ˆˆˆˆˆˆ xyzxyz ()()dx() dy() dz ∂∂∂xyz ≡⋅∇fdl 6 September 2002 Physics 217, Fall 2002 2 Differential vector calculus (continued) The vector derivative operator — (“del”) ∂∂∂ ∇ =++xyzˆˆˆ ∂∂∂xyz produces a vector when it operates on scalar function f(x,y,z). — is a vector, as we can see from its behavior under coordinate rotations: I ′ ()∇∇ff=⋅R but its magnitude is not a number: it is an operator. 6 September 2002 Physics 217, Fall 2002 3 Differential vector calculus (continued) There are three kinds of vector derivatives, corresponding to the three kinds of multiplication possible with vectors: Gradient, the analogue of multiplication by a scalar. ∇f Divergence, like the scalar (dot) product. ∇⋅v Curl, which corresponds to the vector (cross) product. ∇×v 6 September 2002 Physics 217, Fall 2002 4 Gradient The result of applying the vector derivative operator on a scalar function f is called the gradient of f: ∂∂∂fff ∇f =++xyzˆˆˆ ∂∂∂xyz The direction of the gradient points in the direction of maximum increase of f (i.e. -

The Calculus of Newton and Leibniz CURRENT READING: Katz §16 (Pp
Worksheet 13 TITLE The Calculus of Newton and Leibniz CURRENT READING: Katz §16 (pp. 543-575) Boyer & Merzbach (pp 358-372, 382-389) SUMMARY We will consider the life and work of the co-inventors of the Calculus: Isaac Newton and Gottfried Leibniz. NEXT: Who Invented Calculus? Newton v. Leibniz: Math’s Most Famous Prioritätsstreit Isaac Newton (1642-1727) was born on Christmas Day, 1642 some 100 miles north of London in the town of Woolsthorpe. In 1661 he started to attend Trinity College, Cambridge and assisted Isaac Barrow in the editing of the latter’s Geometrical Lectures. For parts of 1665 and 1666, the college was closed due to The Plague and Newton went home and studied by himself, leading to what some observers have called “the most productive period of mathematical discover ever reported” (Boyer, A History of Mathematics, 430). During this period Newton made four monumental discoveries 1. the binomial theorem 2. the calculus 3. the law of gravitation 4. the nature of colors Newton is widely regarded as the most influential scientist of all-time even ahead of Albert Einstein, who demonstrated the flaws in Newtonian mechanics two centuries later. Newton’s epic work Philosophiæ Naturalis Principia Mathematica (Mathematical Principles of Natural Philosophy) more often known as the Principia was first published in 1687 and revolutionalized science itself. Infinite Series One of the key tools Newton used for many of his mathematical discoveries were power series. He was able to show that he could expand the expression (a bx) n for any n He was able to check his intuition that this result must be true by showing that the power series for (1+x)-1 could be used to compute a power series for log(1+x) which he then used to calculate the logarithms of several numbers close to 1 to over 50 decimal paces. -

1. Antiderivatives for Exponential Functions Recall That for F(X) = Ec⋅X, F ′(X) = C ⋅ Ec⋅X (For Any Constant C)
1. Antiderivatives for exponential functions Recall that for f(x) = ec⋅x, f ′(x) = c ⋅ ec⋅x (for any constant c). That is, ex is its own derivative. So it makes sense that it is its own antiderivative as well! Theorem 1.1 (Antiderivatives of exponential functions). Let f(x) = ec⋅x for some 1 constant c. Then F x ec⋅c D, for any constant D, is an antiderivative of ( ) = c + f(x). 1 c⋅x ′ 1 c⋅x c⋅x Proof. Consider F (x) = c e +D. Then by the chain rule, F (x) = c⋅ c e +0 = e . So F (x) is an antiderivative of f(x). Of course, the theorem does not work for c = 0, but then we would have that f(x) = e0 = 1, which is constant. By the power rule, an antiderivative would be F (x) = x + C for some constant C. 1 2. Antiderivative for f(x) = x We have the power rule for antiderivatives, but it does not work for f(x) = x−1. 1 However, we know that the derivative of ln(x) is x . So it makes sense that the 1 antiderivative of x should be ln(x). Unfortunately, it is not. But it is close. 1 1 Theorem 2.1 (Antiderivative of f(x) = x ). Let f(x) = x . Then the antiderivatives of f(x) are of the form F (x) = ln(SxS) + C. Proof. Notice that ln(x) for x > 0 F (x) = ln(SxS) = . ln(−x) for x < 0 ′ 1 For x > 0, we have [ln(x)] = x . -

Real Zeros of Polynomial Functions
333353_0200.qxp 1/11/07 2:00 PM Page 91 Polynomial and Chapter 2 Rational Functions y y y 2.1 Quadratic Functions 2 2 2 2.2 Polynomial Functions of Higher Degree x x x −44−2 −44−2 −44−2 2.3 Real Zeros of Polynomial Functions 2.4 Complex Numbers 2.5 The Fundamental Theorem of Algebra Polynomial and rational functions are two of the most common types of functions 2.6 Rational Functions and used in algebra and calculus. In Chapter 2, you will learn how to graph these types Asymptotes of functions and how to find the zeros of these functions. 2.7 Graphs of Rational Functions 2.8 Quadratic Models David Madison/Getty Images Selected Applications Polynomial and rational functions have many real-life applications. The applications listed below represent a small sample of the applications in this chapter. ■ Automobile Aerodynamics, Exercise 58, page 101 ■ Revenue, Exercise 93, page 114 ■ U.S. Population, Exercise 91, page 129 ■ Impedance, Exercises 79 and 80, page 138 ■ Profit, Exercise 64, page 145 ■ Data Analysis, Exercises 41 and 42, page 154 ■ Wildlife, Exercise 43, page 155 ■ Comparing Models, Exercise 85, page 164 ■ Media, Aerodynamics is crucial in creating racecars.Two types of racecars designed and built Exercise 18, page 170 by NASCAR teams are short track cars, as shown in the photo, and super-speedway (long track) cars. Both types of racecars are designed either to allow for as much downforce as possible or to reduce the amount of drag on the racecar. 91 333353_0201.qxp 1/11/07 2:02 PM Page 92 92 Chapter 2 Polynomial and Rational Functions 2.1 Quadratic Functions The Graph of a Quadratic Function What you should learn Analyze graphs of quadratic functions.