Author-Topic Modeling of DESIDOC Journal of Library And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Top 10 Male Indian Singers
Top 10 Male Indian Singers 001asd Don't agree with the list? Vote for an existing item you think should be ranked higher or if you are a logged in,add a new item for others to vote on or create your own version of this list. Share on facebookShare on twitterShare on emailShare on printShare on gmailShare on stumbleupon4 The Top Ten TheTopTens List Your List 1Sonu Nigam +40Son should be at number 1 +30I feels that I have goten all types of happiness when I listen the songs of sonu nigam. He is my idol and sometimes I think that he is second rafi thumbs upthumbs down +13Die-heart fan... He's the best! Love you Sonu, your an idol. thumbs upthumbs down More comments about Sonu Nigam 2Mohamed Rafi +30Rafi the greatest singer in the whole wide world without doubt. People in the west have seen many T.V. adverts with M. Rafi songs and that is incediable and mind blowing. +21He is the greatest singer ever born in the world. He had a unique voice quality, If God once again tries to create voice like Rafi he wont be able to recreate it because God creates unique things only once and that is Rafi sahab's voice. thumbs upthumbs down +17Rafi is the best, legend of legends can sing any type of song with east, he can surf from high to low with ease. Equally melodious voice, well balanced with right base and high range. His diction is fantastic, you may feel every word. Incomparable. More comments about Mohamed Rafi 3Kumar Sanu +14He holds a Guinness World Record for recording 28 songs in a single day Awards *. -

IFLA Journal Volume 46 Number 3 October 2020
IFLA Volume 46 Number 3 October 2020 IFLA Contents Articles Designing a mentoring program for faculty librarians 197 Erla P. Heyns and Judith M. Nixon Transformational and transactional leadership and knowledge sharing in Nigerian university libraries 207 C. I. Ugwu, O. B. Onyancha and M. Fombard Knowledge management and innovation: Two explicit intentions pursued by Spanish university libraries 224 Ana R. Pacios National and international trends in library and information science research: A comparative review of the literature 234 Mallikarjun Dora and H. Anil Kumar Taxonomy design methodologies: Emergent research for knowledge management domains 250 Virginia M. Tucker The effect of information literacy instruction on lifelong learning readiness 259 Leili Seifi, Maryam Habibi and Mohsen Ayati Semantic modeling for education of library and information sciences in Iran, based on Soft Systems Methodology 271 Amir Hessam Radfar, Fatima Fahimnia, Mohammad Reza Esmaeili and Moluk al-Sadat Beheshti Abstracts 290 Aims and Scope IFLA Journal is an international journal publishing peer reviewed articles on library and information services and the social, political and economic issues that impact access to information through libraries. The Journal publishes research, case studies and essays that reflect the broad spectrum of the profession internationally. To submit an article to IFLA Journal please visit: journals.sagepub.com/home/ifl IFLA Journal Official Journal of the International Federation of Library Associations and Institutions ISSN 0340-0352 [print] 1745-2651 [online] Published 4 times a year in March, June, October and December Editor Steve Witt, University of Illinois at Urbana-Champaign, 321 Main Library, MC – 522 1408 W. Gregory Drive, Urbana, IL, USA. -

Qatar Ranked Safest Country in the World Qatar’S Strong Commercial
BUSINESS | Page 1 SPORT | Page 8 Ominous Serena, Djokovic QNB posts 5% surge in make Open 2018 profi t to QR13.8bn statements published in QATAR since 1978 WEDNESDAY Vol. XXXIX No. 11065 January 16, 2019 Jumada I 10, 1440 AH GULF TIMES www. gulf-times.com 2 Riyals Amir grants $50mn in aid package for displaced Syrians is Highness the Amir Sheikh Tamim bin Hamad al-Thani has given directions to allocate $50mn to QC raises QR214mn for ‘Arsal Relief’ campaign Hsupport the Syrian refugees and displaced persons who suff er tough humanitarian conditions as a result of dis- placement and the cold winter weather. atar Charity yesterday raised have decided to donate a part of their Qatar extends this grant in the form of an urgent relief aid more than QR214mn in dona- sales revenues to the QC campaign and package and a group of development programmes, through Qtions for its ‘Arsal Relief’ cam- support it by all possible means. Qatar Fund for Development, to the Syrian refugees in Turkey, paign which was aired on Qatar Media Qatar Charity has extended its sin- Lebanon and Jordan, in addition to the displaced within Syria. Corporation’s channels. cere thanks and gratitude to the sup- The grant will be distributed as follows: $20mn to support In a tweet, the charity said there porters of the “Arsal Relief” campaign. the displaced within Syria, $10mn for programmes support- has been an overwhelming response Donations towards the campaign ing refugees in each Jordan, Turkey and Lebanon, adding up for the appeal as many organisations, can be made through QC’s website to a total of $30mn in the three countries. -

Technology and Engineering International Journal of Recent
International Journal of Recent Technology and Engineering ISSN : 2277 - 3878 Website: www.ijrte.org Volume-9 Issue-2, JULY 2020 Published by: Blue Eyes Intelligence Engineering and Sciences Publication d E a n n g y i n g o e l e o r i n n h g c e T t n e c Ijrt e e E R X I N P n f L O I O t T R A o e I V N O l G N r IN n a a n r t i u o o n J a l www.ijrte.org Exploring Innovation Editor-In-Chief & CEO Dr. Shiv Kumar Ph.D. (CSE), M.Tech. (IT, Honors), B.Tech. (IT) Senior Member of IEEE, Member of the Elsevier Advisory Panel CEO, Blue Eyes Intelligence Engineering and Sciences Publication, Bhopal (MP), India Associate Editor-In-Chief Prof. Dr. Takialddin Al Smadi PhD. (ECE) M.Sc. (ECE), B.Sc (EME), Member of the Elsevier Professor, Department of Communication and Electronics, Jerash Universtiy, Jerash, Jordan. Dr. Vo Quang Minh PhD. (Agronomy), MSc. (Agronomy), BSc. (Agronomy) Senior Lecturer and Head, Department of Land Resources, College of Environment and Natural Resources (CENRes), Can Tho City, Vietnam. Dr. Stamatis Papadakis PhD. (Philosophy), M.Sc. (Preschool Education), BSc. (Informatics) Member of IEEE, ACM, Elsevier, Springer, PubMed Lecturer, Department of Preschool Education, University of Crete, Greece Dr. Ali OTHMAN Al Janaby Ph.D. (LTE), MSc. (ECE), BSc (EE) Lecturer, Department of Communications Engineering, College of Electronics Engineering University of Ninevah, Iraq. Dr. Hakimjon Zaynidinov PhD. -
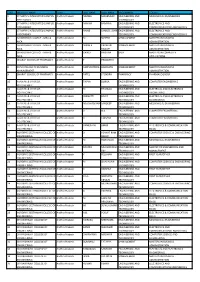
S.No Institute Name State Last Name First Name
S.NO INSTITUTE NAME STATE LAST NAME FIRST NAME PROGRAMME COURSE 1 ST MARY S INTEGRATED CAMPUS Andhra Pradesh NIMMA MAHENDAR ENGINEERING AND MECHANICAL ENGINEERING HYDERABAD TECHNOLOGY 2 ST MARY S INTEGRATED CAMPUS Andhra Pradesh ANNAM RAMANA ENGINEERING AND ELECTRONICS AND HYDERABAD TECHNOLOGY COMMUNICATIONS ENGINEERING 3 ST MARY S INTEGRATED CAMPUS Andhra Pradesh NAINE SAMUEL JOHN ENGINEERING AND ELECTRONICS AND HYDERABAD TECHNOLOGY COMMUNICATIONS ENGINEERING 4 SAI KRISHNA COLLEGE - MBA & Andhra Pradesh M SURESH MANAGEMENT MASTERS IN BUSINESS MCA ADMINISTRATION 5 SAI KRISHNA COLLEGE - MBA & Andhra Pradesh NUKALA YADAGIRI MANAGEMENT MASTERS IN BUSINESS MCA SWAMY ADMINISTRATION 6 SAI KRISHNA COLLEGE - MBA & Andhra Pradesh GANGI KRISHNA MCA MASTERS IN COMPUTER MCA APPLICATIONS 7 BHARAT SCHOOL OF PHARMACY Andhra Pradesh T PRASANTHI 8 DVM COLLEGE OF BUSINESS Andhra Pradesh KARIMIKONDA HARINATH MANAGEMENT MASTERS IN BUSINESS MANAGEMENT ADMINISTRATION 9 BHARAT SCHOOL OF PHARMACY Andhra Pradesh PATEL JITENDRA PHARMACY PHARMACOGNOSY 10 A.A.N.M. & V.V.R.S.R. Andhra Pradesh TAVVA DURGA ENGINEERING AND COMPUTER ENGINEERING POLYTECHNIC TECHNOLOGY 11 A.A.N.M. & V.V.R.S.R. Andhra Pradesh M THANUJA ENGINEERING AND ELECTRICAL AND ELECTRONICS POLYTECHNIC TECHNOLOGY ENGINEERING 12 A.A.N.M. & V.V.R.S.R. Andhra Pradesh PERISETTI DIVYA ENGINEERING AND ELECTRICAL AND ELECTRONICS POLYTECHNIC TECHNOLOGY ENGINEERING 13 A.A.N.M. & V.V.R.S.R. Andhra Pradesh NAGANABOINA SANDEEP ENGINEERING AND MECHANICAL ENGINEERING POLYTECHNIC TECHNOLOGY 14 A.A.N.M. & V.V.R.S.R. Andhra Pradesh V N.K. ENGINEERING AND COMPUTER ENGINEERING POLYTECHNIC TECHNOLOGY 15 A.A.N.M. & V.V.R.S.R. -

Qatar to Host LNG2025 Undertaken by Hotels
INDEX QATAR 2-10, 20 COMMENT 18, 19 BUSINESS | Page 1 QATAR | Page 10 ARAB WORLD 11 BUSINESS 1-12 Ooredoo INTERNATIONAL 11-17 SPORTS 1-8 Group posts H1 profi t of DOW JONES QE NYMEX QR818mn on QR14bn 26,379.28 9,371.75 41.10 QF awards innovation grants to eight -265.49 +20.39 +0.06 revenue -0.77% +0.22% +0.15% startups to tackle Covid-19 challenges Latest Figures published in QATAR since 1978 WEDNESDAY Vol. XXXXI No. 11624 July 29, 2020 Dhul-Hijjah 8, 1441 AH GULF TIMES www. gulf-times.com 2 Riyals Time for operas and tourism again In brief ‘Qatar Clean’ plan Amir, Sultan of Oman exchange Eid greetings launched in hotels His Highness the Amir Sheikh Tamim bin Hamad al-Thani held yesterday a telephone zQNTC-MoPH programme aimed conversation with Sultan Haitham bin Tariq of Oman. The Amir and at preparing the tourism sector Sultan Haitham exchanged Eid al-Adha greetings. They reviewed to welcome visitors again the strong brotherly relations between the two countries, as well QNA as the prospects for strengthening Doha and developing them to serve the common interests of the two brotherly people, in addition to atar National Tourism Council discussing the most prominent (QNTC), in partnership with regional and international Qthe Ministry of Public Health is one of many initiatives by QNTC, in developments. (MoPH), has launched the fi rst phase collaboration with our partners, to help of the ‘Qatar Clean’ programme in all the sector welcome back visitors; fi rst hotels across the country. -

Annexure 1B 18416
Annexure 1 B List of taxpayers allotted to State having turnover of more than or equal to 1.5 Crore Sl.No Taxpayers Name GSTIN 1 BROTHERS OF ST.GABRIEL EDUCATION SOCIETY 36AAAAB0175C1ZE 2 BALAJI BEEDI PRODUCERS PRODUCTIVE INDUSTRIAL COOPERATIVE SOCIETY LIMITED 36AAAAB7475M1ZC 3 CENTRAL POWER RESEARCH INSTITUTE 36AAAAC0268P1ZK 4 CO OPERATIVE ELECTRIC SUPPLY SOCIETY LTD 36AAAAC0346G1Z8 5 CENTRE FOR MATERIALS FOR ELECTRONIC TECHNOLOGY 36AAAAC0801E1ZK 6 CYBER SPAZIO OWNERS WELFARE ASSOCIATION 36AAAAC5706G1Z2 7 DHANALAXMI DHANYA VITHANA RAITHU PARASPARA SAHAKARA PARIMITHA SANGHAM 36AAAAD2220N1ZZ 8 DSRB ASSOCIATES 36AAAAD7272Q1Z7 9 D S R EDUCATIONAL SOCIETY 36AAAAD7497D1ZN 10 DIRECTOR SAINIK WELFARE 36AAAAD9115E1Z2 11 GIRIJAN PRIMARY COOPE MARKETING SOCIETY LIMITED ADILABAD 36AAAAG4299E1ZO 12 GIRIJAN PRIMARY CO OP MARKETING SOCIETY LTD UTNOOR 36AAAAG4426D1Z5 13 GIRIJANA PRIMARY CO-OPERATIVE MARKETING SOCIETY LIMITED VENKATAPURAM 36AAAAG5461E1ZY 14 GANGA HITECH CITY 2 SOCIETY 36AAAAG6290R1Z2 15 GSK - VISHWA (JV) 36AAAAG8669E1ZI 16 HASSAN CO OPERATIVE MILK PRODUCERS SOCIETIES UNION LTD 36AAAAH0229B1ZF 17 HCC SEW MEIL JOINT VENTURE 36AAAAH3286Q1Z5 18 INDIAN FARMERS FERTILISER COOPERATIVE LIMITED 36AAAAI0050M1ZW 19 INDU FORTUNE FIELDS GARDENIA APARTMENT OWNERS ASSOCIATION 36AAAAI4338L1ZJ 20 INDUR INTIDEEPAM MUTUAL AIDED CO-OP THRIFT/CREDIT SOC FEDERATION LIMITED 36AAAAI5080P1ZA 21 INSURANCE INFORMATION BUREAU OF INDIA 36AAAAI6771M1Z8 22 INSTITUTE OF DEFENCE SCIENTISTS AND TECHNOLOGISTS 36AAAAI7233A1Z6 23 KARNATAKA CO-OPERATIVE MILK PRODUCER\S FEDERATION -

Annexure Government of India Ministry of Science & Technology
Annexure 12011/67/2014 INSPIRE (Telangana) Dated: 18 Nov 2019 Government of India Ministry of Science & Technology, Department of Science & Technology List of Selected Students under the INSPIRE Award Scheme for the Year 2019-20 Name of the State :Telangana No. of Sanctioned :3472 Sr. Name of Name of Name of Sub Name of the School Name of the selected Class Sex Category Name of Father UID No Ref Code No. Revenue Education District Student or Mother District District (Block/Tehsil/Zone etc.) 1 Adilabad Adilabad Adilabad SRI SATYA SAI VANKADE 8 M OBC V SANDEEP 19TE1812092 VIDYANIKETAN HIGH PREETHAM SCHOOL 2 Adilabad Adilabad Adilabad SRI SATYA SAI KHADSE ANIKETH 8 M OBC K ZEEBLAJI 19TE1812093 VIDYANIKETAN HIGH SCHOOL 3 Adilabad Adilabad Adilabad SRI SATYA SAI MESRAM SHEKAR 10 M OBC M LAXMAN 19TE1812094 VIDYANIKETAN HIGH SCHOOL 4 Adilabad ADILABAD Adilabad LITTLE FLOWER ENUGULA SAI TEJA 8 M OBC ENUGULA KIRAN 19TE1812095 ENGLISH HIGH KUMAR SCHOOL 5 Adilabad Adilabad Adilabad Zpss kura APAS RAHUL 8 M OBC APAS SANTHOSH 19TE1812096 6 Adilabad Adilabad Adilabad Zpss kura NERALLA AKHILA 9 F SC RAVI 19TE1812097 7 Adilabad Adilabad Adilabad Zpss mannur VAGMARE MARUTHI 8 M SC SHAMBU 19TE1812098 Page 1 of 241 Sr. Name of Name of Name of Sub Name of the School Name of the selected Class Sex Category Name of Father UID No Ref Code No. Revenue Education District Student or Mother District District (Block/Tehsil/Zone etc.) 8 Adilabad ADILABAD Adilabad ZPSS VIDYA SAGAR 8 M ST GANGANNA 19TE1812099 RANADIVENAGAR 9 Adilabad Adilabad Adilabad ZPSS PONNARI -

Alphabetical List of Recommendations Received for Padma Awards - 2014
Alphabetical List of recommendations received for Padma Awards - 2014 Sl. No. Name Recommending Authority 1. Shri Manoj Tibrewal Aakash Shri Sriprakash Jaiswal, Minister of Coal, Govt. of India. 2. Dr. (Smt.) Durga Pathak Aarti 1.Dr. Raman Singh, Chief Minister, Govt. of Chhattisgarh. 2.Shri Madhusudan Yadav, MP, Lok Sabha. 3.Shri Motilal Vora, MP, Rajya Sabha. 4.Shri Nand Kumar Saay, MP, Rajya Sabha. 5.Shri Nirmal Kumar Richhariya, Raipur, Chhattisgarh. 6.Shri N.K. Richarya, Chhattisgarh. 3. Dr. Naheed Abidi Dr. Karan Singh, MP, Rajya Sabha & Padma Vibhushan awardee. 4. Dr. Thomas Abraham Shri Inder Singh, Chairman, Global Organization of People Indian Origin, USA. 5. Dr. Yash Pal Abrol Prof. M.S. Swaminathan, Padma Vibhushan awardee. 6. Shri S.K. Acharigi Self 7. Dr. Subrat Kumar Acharya Padma Award Committee. 8. Shri Achintya Kumar Acharya Self 9. Dr. Hariram Acharya Government of Rajasthan. 10. Guru Shashadhar Acharya Ministry of Culture, Govt. of India. 11. Shri Somnath Adhikary Self 12. Dr. Sunkara Venkata Adinarayana Rao Shri Ganta Srinivasa Rao, Minister for Infrastructure & Investments, Ports, Airporst & Natural Gas, Govt. of Andhra Pradesh. 13. Prof. S.H. Advani Dr. S.K. Rana, Consultant Cardiologist & Physician, Kolkata. 14. Shri Vikas Agarwal Self 15. Prof. Amar Agarwal Shri M. Anandan, MP, Lok Sabha. 16. Shri Apoorv Agarwal 1.Shri Praveen Singh Aron, MP, Lok Sabha. 2.Dr. Arun Kumar Saxena, MLA, Uttar Pradesh. 17. Shri Uttam Prakash Agarwal Dr. Deepak K. Tempe, Dean, Maulana Azad Medical College. 18. Dr. Shekhar Agarwal 1.Dr. Ashok Kumar Walia, Minister of Health & Family Welfare, Higher Education & TTE, Skill Mission/Labour, Irrigation & Floods Control, Govt. -

Qatar, Iraq Vow to Strengthen Ties
FRIDAY JANUARY 11, 2019 JUMADA AL-AWWAL 5, 1440 VOL.12 NO. 4511 QR 2 HAZY Fajr: 4:58 am Dhuhr: 11:42 am HIGH : 21°C Asr: 2:43 pm Maghrib: 5:03 pm LOW : 18°C Isha: 6:33 pm Business 9 Sports 12 Investors question Amazon’s Jordan tame Syria to reach future after Bezos’ divorce news Asian Cup knockout stage AMIR, IRAQI PRESIDENT DISCUSS BILATERAL RELATIONS, RECONSTRUCTION OF IRAQ Qatar, Iraq vow to strengthen ties Amir welcomes Iraqi Amir hails strong fraternal president’s invite relations between the to visit Iraq two countries QNA president and his accompa- luncheon banquet in honour DOHA nying delegation, praising the of the Iraqi President and fraternal relations between the delegation accompanying THE Amir HH Sheikh Tamim the two countries and stress- him at the Amiri Diwan. bin Hamad al Thani and ing that the Iraqi president’s After a successful visit to Iraqi President Dr Barham visit would contribute to ce- Qatar, the Iraqi president left Salih on Thursday discussed menting the relations. Doha on Thursday. bilateral relations and the The Iraqi president laud- The Iraqi president and ways to further enhance the ed the deep-rooted relations the accompanying delega- relations in economy, trade, between the two countries tion were seen off upon de- investment, infrastructure and voiced his aspiration to parture from Hamad Inter- and tourism. develop them to wider pros- national Airport by Minister During the official talks at pects. of Commerce and Industry the Amiri Diwan on Thurs- At the end of the talks, the HE Ali bin Ahmed al Kuwari, day, the Amir and the Iraqi Iraqi president extended an Acting Charge d’Affaires president also discussed the invitation to the Amir to visit of the Embassy of Qatar reconstruction of Iraq. -

Concert Brochure
Program Schedule ( Sunday, 06/13/2009 ): 12: 00 - 3: 30 PM Singing Competition on Ilaiya Raja Songs (Adults/Kids) 12: 00 PM Ticket Counter Opens 4: 30 PM Welcome Speech by Vijaya Aasuri, Event’s MC 4: 31 PM Singer Mallikharjun’s introduction & a commemorational tribute to Late. Veturi 4: 32 PM Prardhana Geetham (by Himaja Movva) 4: 35 PM Jyothi Prajwalana by Dr. Kumar Gadamasetti (Chief Guest) 4: 40 PM A Few Words by Srinivas Chimata, Event Organizer 4: 42 PM Introductory Speech on Ilaya Raja (by KiranPrabha, Koumudi.net’s editor) 4: 45 PM First Song starts 7: 00 PM Dinner Break (Food Stalls Outside the Auditorium by Peacock Restaurant) 7: 30 PM Saxophone Performance by Ramesh Maraj (www.indisax.com) 7: 45 PM Second Part of the Concert starts 8: 00 PM Felicitation to the Sponsors 8: 10 PM Second Part Continues 9: 00 PM Mementoes (to Singers, Musicians, Volunteers & Singing Competition Winners) 9: 15 PM Vote of Thanks (by Vijaya Aasuri & Srinivas Chimata) Grand Sponsor Exclusive Media Partner Food Catering PannuDental.com; Fremont/San Jose/Cupertino PravasVani.com; on KLOK 1170 AM Santa Clara/Fremont/Evergreen/Mountain View Other Media Partners Padma Bhushan “Maestro” Ilaiya Raja: Ilaiya Raja is a living legend in the South Indian Film Music and he is undoubtedly the most popular music director in the 80’s in India. His original name is Daniel Ra- jayya and was born on June 3, 1943 in Vannaipuram (Madurai Dt.). His first official movie is Annakkili (1976), which was later remade by Singeetam Srinivasa Rao in Telugu as Raama Chilaka (1978), albeit he ghost-composed for some movies ear- lier. -
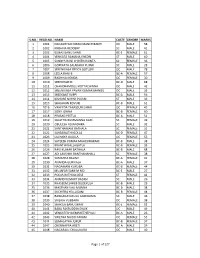
S.No. Regd.No. Name Caste Gender Marks 1 1001
S.NO. REGD.NO. NAME CASTE GENDER MARKS 1 1001 NAGASHYAM KIRAN MANCHIKANTI OC MALE 58 2 1002 KRISHNA REDDERY SC MALE 41 3 1003 ELMAS BANU SHAIK BC-E FEMALE 61 4 1004 VENKATA RAMANA KHEDRI ST MALE 60 5 1005 SANDYA RANI CHINTHAKUNTA SC FEMALE 36 6 1006 GOPINATH SALAKARU PUJARI SC MALE 28 7 1007 SREENIVASA REDDY GOTLURI OC MALE 78 8 1008 LEELA RANI B BC-A FEMALE 57 9 1009 RADHIKA KONDA OC FEMALE 30 10 1010 SREEDHAR M BC-D MALE 68 11 1011 CHANDRAMOULI KOTTACHINNA OC MALE 42 12 1012 SREENIVASA PAVAN KUMAR MANGU OC MALE 35 13 1013 SREEKANT SUPPI BC-A MALE 56 14 1014 KISHORE NAYAK PUJARI ST MALE 39 15 1015 SHAJAHAN KOVURI BC-B MALE 61 16 1016 VAHEEDA TABASSUM SHAIK OC FEMALE 45 17 1017 SONY JONNA BC-B FEMALE 60 18 1018 PRASAD PEETLA BC-A MALE 51 19 1019 SUJATHA BUMMANNA GARI SC FEMALE 49 20 1020 OBULESH ADIANDHRA SC MALE 32 21 1021 SANTHAMANI BATHALA SC FEMALE 31 22 1022 SARASWATHI GOLLA BC-D FEMALE 47 23 1023 LAVANYA GAJULA OC FEMALE 55 24 1024 SATEESH KUMAR MAHESWARAM BC-B MALE 38 25 1025 KRANTHI NALLAGATLA BC-B FEMALE 33 26 1026 RAVI KUMAR BATHALA BC-B MALE 68 27 1027 ADI LAKSHMI BANTHANAHALL SC FEMALE 38 28 1028 SAMATHA BALIMI BC-A FEMALE 41 29 1030 ANANDA GURIKALA BC-A MALE 37 30 1031 NAGAMANI KURUBA BC-B FEMALE 44 31 1032 MUJAFAR SAMI M MD BC-E MALE 27 32 1033 POOJA RATHOD DESE ST FEMALE 42 33 1034 ANAND KUMART BADIGI SC MALE 26 34 1035 KHASEEM SAHEB DUDEKULA BC-B MALE 29 35 1036 MASTHAN VALI MUNNA BC-B MALE 38 36 1037 SUCHITRA YELLUGANI BC-B FEMALE 44 37 1038 RANGANAYAKULU GUDIDAMA SC MALE 46 38 1039 SAILAJA VUBBARA OC FEMALE 38 39 1040 SHAKILA BANU SHAIK BC-E FEMALE 52 40 1041 BABA FAKRUDDIN SHAIK OC MALE 49 41 1042 VENKATESH DEMAKETHEPALLI BC-A MALE 26 42 1043 SWETHA NAIDU PAKAM OC FEMALE 55 43 1044 SUMALATHA JUKUR BC-B FEMALE 37 44 1047 CHENNAPPA ARETI BC-A MALE 29 45 1048 NAGARAJU CHALUKURU OC MALE 40 Page 1 of 127 S.NO.