Quasi-Poisson Vs. Negative Binomial Regression: How Should We Model Overdispersed Count Data?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Introduction to Poisson Regression Russ Lavery, K&L Consulting Services, King of Prussia, PA, U.S.A
NESUG 2010 Statistics and Analysis An Animated Guide: An Introduction To Poisson Regression Russ Lavery, K&L Consulting Services, King of Prussia, PA, U.S.A. ABSTRACT: This paper will be a brief introduction to Poisson regression (theory, steps to be followed, complications and interpretation) via a worked example. It is hoped that this will increase motivation towards learning this useful statistical technique. INTRODUCTION: Poisson regression is available in SAS through the GENMOD procedure (generalized modeling). It is appropriate when: 1) the process that generates the conditional Y distributions would, theoretically, be expected to be a Poisson random process and 2) when there is no evidence of overdispersion and 3) when the mean of the marginal distribution is less than ten (preferably less than five and ideally close to one). THE POISSON DISTRIBUTION: The Poison distribution is a discrete Percent of observations where the random variable X is expected distribution and is appropriate for to have the value x, given that the Poisson distribution has a mean modeling counts of observations. of λ= P(X=x, λ ) = (e - λ * λ X) / X! Counts are observed cases, like the 0.4 count of measles cases in cities. You λ can simply model counts if all data 0.35 were collected in the same measuring 0.3 unit (e.g. the same number of days or 0.3 0.5 0.8 same number of square feet). 0.25 λ 1 0.2 3 You can use the Poisson Distribution = 5 for modeling rates (rates are counts 0.15 20 per unit) if the units of collection were 8 different. -

Overdispersion, and How to Deal with It in R and JAGS (Requires R-Packages AER, Coda, Lme4, R2jags, Dharma/Devtools) Carsten F
Overdispersion, and how to deal with it in R and JAGS (requires R-packages AER, coda, lme4, R2jags, DHARMa/devtools) Carsten F. Dormann 07 December, 2016 Contents 1 Introduction: what is overdispersion? 1 2 Recognising (and testing for) overdispersion 1 3 “Fixing” overdispersion 5 3.1 Quasi-families . .5 3.2 Different distribution (here: negative binomial) . .6 3.3 Observation-level random effects (OLRE) . .8 4 Overdispersion in JAGS 12 1 Introduction: what is overdispersion? Overdispersion describes the observation that variation is higher than would be expected. Some distributions do not have a parameter to fit variability of the observation. For example, the normal distribution does that through the parameter σ (i.e. the standard deviation of the model), which is constant in a typical regression. In contrast, the Poisson distribution has no such parameter, and in fact the variance increases with the mean (i.e. the variance and the mean have the same value). In this latter case, for an expected value of E(y) = 5, we also expect that the variance of observed data points is 5. But what if it is not? What if the observed variance is much higher, i.e. if the data are overdispersed? (Note that it could also be lower, underdispersed. This is less often the case, and not all approaches below allow for modelling underdispersion, but some do.) Overdispersion arises in different ways, most commonly through “clumping”. Imagine the number of seedlings in a forest plot. Depending on the distance to the source tree, there may be many (hundreds) or none. The same goes for shooting stars: either the sky is empty, or littered with shooting stars. -

Poisson Versus Negative Binomial Regression
Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Poisson versus Negative Binomial Regression Randall Reese Utah State University [email protected] February 29, 2016 Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Overview 1 Handling Count Data ADEM Overdispersion 2 The Negative Binomial Distribution Foundations of Negative Binomial Distribution Basic Properties of the Negative Binomial Distribution Fitting the Negative Binomial Model 3 Other Applications and Analysis in R 4 References Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Data whose values come from Z≥0, the non-negative integers. Classic example is deaths in the Prussian army per year by horse kick (Bortkiewicz) Example 2 of Notes 5. (Number of successful \attempts"). Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Poisson Distribution Support is the non-negative integers. (Count data). Described by a single parameter λ > 0. When Y ∼ Poisson(λ), then E(Y ) = Var(Y ) = λ Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Acute Disseminated Encephalomyelitis Acute Disseminated Encephalomyelitis (ADEM) is a neurological, immune disorder in which widespread inflammation of the brain and spinal cord damages tissue known as white matter. -
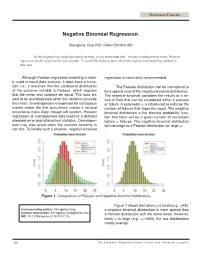
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Statistical Approaches for Highly Skewed Data 1
Running head: STATISTICAL APPROACHES FOR HIGHLY SKEWED DATA 1 (in press) Journal of Clinical Child and Adolescent Psychology Statistical Approaches for Highly Skewed Data: Evaluating Relations between Child Maltreatment and Young Adults’ Non-Suicidal Self-injury Ana Gonzalez-Blanks, PhD Jessie M. Bridgewater, MA *Tuppett M. Yates, PhD Department of Psychology University of California, Riverside Acknowledgments: We gratefully acknowledge Dr. Chandra Reynolds who provided generous instruction and consultation throughout the execution of the analyses reported herein. *Please address correspondence to: Tuppett M. Yates, Department of Psychology, University of California, Riverside CA, 92521. Email: [email protected]. STATISTICAL APPROACHES FOR HIGHLY SKEWED DATA 2 Abstract Objective: Clinical phenomena often feature skewed distributions with an overabundance of zeros. Unfortunately, empirical methods for dealing with this violation of distributional assumptions underlying regression are typically discussed in statistical journals with limited translation to applied researchers. Therefore, this investigation compared statistical approaches for addressing highly skewed data as applied to the evaluation of relations between child maltreatment and non-suicidal self-injury (NSSI). Method: College students (N = 2,651; 64.2% female; 85.2% non-White) completed the Child Abuse and Trauma Scale and the Functional Assessment of Self-Mutilation. Statistical models were applied to cross-sectional data to provide illustrative comparisons across predictions to a) raw, highly skewed NSSI outcomes, b) natural log, square-root, and inverse NSSI transformations to reduce skew, c) zero-inflated Poisson (ZIP) and negative-binomial zero- inflated (NBZI) regression models to account for both disproportionate zeros and skewness in the NSSI data, and d) the skew-t distribution to model NSSI skewness. -

Negative Binomial Regression Models and Estimation Methods
Appendix D: Negative Binomial Regression Models and Estimation Methods By Dominique Lord Texas A&M University Byung-Jung Park Korea Transport Institute This appendix presents the characteristics of Negative Binomial regression models and discusses their estimating methods. Probability Density and Likelihood Functions The properties of the negative binomial models with and without spatial intersection are described in the next two sections. Poisson-Gamma Model The Poisson-Gamma model has properties that are very similar to the Poisson model discussed in Appendix C, in which the dependent variable yi is modeled as a Poisson variable with a mean i where the model error is assumed to follow a Gamma distribution. As it names implies, the Poisson-Gamma is a mixture of two distributions and was first derived by Greenwood and Yule (1920). This mixture distribution was developed to account for over-dispersion that is commonly observed in discrete or count data (Lord et al., 2005). It became very popular because the conjugate distribution (same family of functions) has a closed form and leads to the negative binomial distribution. As discussed by Cook (2009), “the name of this distribution comes from applying the binomial theorem with a negative exponent.” There are two major parameterizations that have been proposed and they are known as the NB1 and NB2, the latter one being the most commonly known and utilized. NB2 is therefore described first. Other parameterizations exist, but are not discussed here (see Maher and Summersgill, 1996; Hilbe, 2007). NB2 Model Suppose that we have a series of random counts that follows the Poisson distribution: i e i gyii; (D-1) yi ! where yi is the observed number of counts for i 1, 2, n ; and i is the mean of the Poisson distribution. -

Generalized Linear Models
CHAPTER 6 Generalized linear models 6.1 Introduction Generalized linear modeling is a framework for statistical analysis that includes linear and logistic regression as special cases. Linear regression directly predicts continuous data y from a linear predictor Xβ = β0 + X1β1 + + Xkβk.Logistic regression predicts Pr(y =1)forbinarydatafromalinearpredictorwithaninverse-··· logit transformation. A generalized linear model involves: 1. A data vector y =(y1,...,yn) 2. Predictors X and coefficients β,formingalinearpredictorXβ 1 3. A link function g,yieldingavectoroftransformeddataˆy = g− (Xβ)thatare used to model the data 4. A data distribution, p(y yˆ) | 5. Possibly other parameters, such as variances, overdispersions, and cutpoints, involved in the predictors, link function, and data distribution. The options in a generalized linear model are the transformation g and the data distribution p. In linear regression,thetransformationistheidentity(thatis,g(u) u)and • the data distribution is normal, with standard deviation σ estimated from≡ data. 1 1 In logistic regression,thetransformationistheinverse-logit,g− (u)=logit− (u) • (see Figure 5.2a on page 80) and the data distribution is defined by the proba- bility for binary data: Pr(y =1)=y ˆ. This chapter discusses several other classes of generalized linear model, which we list here for convenience: The Poisson model (Section 6.2) is used for count data; that is, where each • data point yi can equal 0, 1, 2, ....Theusualtransformationg used here is the logarithmic, so that g(u)=exp(u)transformsacontinuouslinearpredictorXiβ to a positivey ˆi.ThedatadistributionisPoisson. It is usually a good idea to add a parameter to this model to capture overdis- persion,thatis,variationinthedatabeyondwhatwouldbepredictedfromthe Poisson distribution alone. -

Modeling Overdispersion with the Normalized Tempered Stable Distribution
Modeling overdispersion with the normalized tempered stable distribution M. Kolossiatisa, J.E. Griffinb, M. F. J. Steel∗,c aDepartment of Hotel and Tourism Management, Cyprus University of Technology, P.O. Box 50329, 3603 Limassol, Cyprus. bInstitute of Mathematics, Statistics and Actuarial Science, University of Kent, Canterbury, CT2 7NF, U.K. cDepartment of Statistics, University of Warwick, Coventry, CV4 7AL, U.K. Abstract A multivariate distribution which generalizes the Dirichlet distribution is intro- duced and its use for modeling overdispersion in count data is discussed. The distribution is constructed by normalizing a vector of independent tempered sta- ble random variables. General formulae for all moments and cross-moments of the distribution are derived and they are found to have similar forms to those for the Dirichlet distribution. The univariate version of the distribution can be used as a mixing distribution for the success probability of a binomial distribution to define an alternative to the well-studied beta-binomial distribution. Examples of fitting this model to simulated and real data are presented. Keywords: Distribution on the unit simplex; Mice fetal mortality; Mixed bino- mial; Normalized random measure; Overdispersion 1. Introduction In many experiments we observe data as the number of observations in a sam- ple with some property. The binomial distribution is a natural model for this type of data. However, the data are often found to be overdispersed relative to that ∗Corresponding author. Tel.: +44-2476-523369; fax: +44-2476-524532 Email addresses: [email protected] (M. Kolossiatis), [email protected] (J.E. Griffin), [email protected] (M. -

Measures of Fit for Logistic Regression Paul D
Paper 1485-2014 SAS Global Forum Measures of Fit for Logistic Regression Paul D. Allison, Statistical Horizons LLC and the University of Pennsylvania ABSTRACT One of the most common questions about logistic regression is “How do I know if my model fits the data?” There are many approaches to answering this question, but they generally fall into two categories: measures of predictive power (like R-square) and goodness of fit tests (like the Pearson chi-square). This presentation looks first at R-square measures, arguing that the optional R-squares reported by PROC LOGISTIC might not be optimal. Measures proposed by McFadden and Tjur appear to be more attractive. As for goodness of fit, the popular Hosmer and Lemeshow test is shown to have some serious problems. Several alternatives are considered. INTRODUCTION One of the most frequent questions I get about logistic regression is “How can I tell if my model fits the data?” Often the questioner is expressing a genuine interest in knowing whether a model is a good model or a not-so-good model. But a more common motivation is to convince someone else--a boss, an editor, or a regulator--that the model is OK. There are two very different approaches to answering this question. One is to get a statistic that measures how well you can predict the dependent variable based on the independent variables. I’ll refer to these kinds of statistics as measures of predictive power. Typically, they vary between 0 and 1, with 0 meaning no predictive power whatsoever and 1 meaning perfect predictions. -

Variance Partitioning in Multilevel Logistic Models That Exhibit Overdispersion
J. R. Statist. Soc. A (2005) 168, Part 3, pp. 599–613 Variance partitioning in multilevel logistic models that exhibit overdispersion W. J. Browne, University of Nottingham, UK S. V. Subramanian, Harvard School of Public Health, Boston, USA K. Jones University of Bristol, UK and H. Goldstein Institute of Education, London, UK [Received July 2002. Final revision September 2004] Summary. A common application of multilevel models is to apportion the variance in the response according to the different levels of the data.Whereas partitioning variances is straight- forward in models with a continuous response variable with a normal error distribution at each level, the extension of this partitioning to models with binary responses or to proportions or counts is less obvious. We describe methodology due to Goldstein and co-workers for appor- tioning variance that is attributable to higher levels in multilevel binomial logistic models. This partitioning they referred to as the variance partition coefficient. We consider extending the vari- ance partition coefficient concept to data sets when the response is a proportion and where the binomial assumption may not be appropriate owing to overdispersion in the response variable. Using the literacy data from the 1991 Indian census we estimate simple and complex variance partition coefficients at multiple levels of geography in models with significant overdispersion and thereby establish the relative importance of different geographic levels that influence edu- cational disparities in India. Keywords: Contextual variation; Illiteracy; India; Multilevel modelling; Multiple spatial levels; Overdispersion; Variance partition coefficient 1. Introduction Multilevel regression models (Goldstein, 2003; Bryk and Raudenbush, 1992) are increasingly being applied in many areas of quantitative research. -
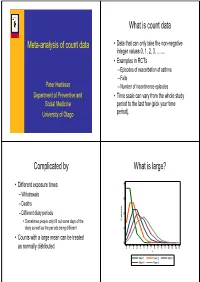
Meta-Analysis of Count Data What Is Count Data Complicated by What Is
What is count data Meta-analysis of count data • Data that can only take the non-negative integer values 0, 1, 2, 3, ……. • Examples in RCTs – Episodes of exacerbation of asthma – Falls Peter Herbison – Number of incontinence episodes Department of Preventive and • Time scale can vary from the whole study Social Medicine period to the last few (pick your time University of Otago period). Complicated by What is large? • Different exposure times .4 – Withdrawals .3 – Deaths – Different diary periods .2 • Sometimes people only fill out some days of the Probability diary as well as the periods being different .1 • Counts with a large mean can be treated 0 as normally distributed 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 n Mean 1 Mean 2 Mean 3 Mean 4 Mean 5 Analysis as rates Meta-analysis of rate ratios • Count number of events in each arm • Formula for calculation in Handbook • Calculate person years at risk in each arm • Straightforward using generic inverse • Calculate rates in each arm variance • Divide to get a rate ratio • In addition to the one reference in the • Can also be done by poisson regression Handbook: family – Guevara et al. Meta-analytic methods for – Poisson, negative binomial, zero inflated pooling rates when follow up duration varies: poisson a case study. BMC Medical Research – Assumes constant underlying risk Methodology 2004;4:17 Dichotimizing Treat as continuous • Change data so that it is those who have • May not be too bad one or more events versus those who • Handbook says beware of skewness have none • Get a 2x2 table • Good if the purpose of the treatment is to prevent events rather than reduce the number of them • Meta-analyse as usual Time to event Not so helpful • Usually time to first event but repeated • Many people look at the distribution and events can be used think that the only distribution that exists is • Analyse by survival analysis (e.g. -

Multiple Binomial Regression Models of Learning Style Preferences of Students of Sidhu School, Wilkes University
International Journal of Statistics and Probability; Vol. 7, No. 3; May 2018 ISSN 1927-7032 E-ISSN 1927-7040 Published by Canadian Center of Science and Education Multiple Binomial Regression Models of Learning Style Preferences of Students of Sidhu School, Wilkes University Adekanmbi, D. B1 1 Department of Statistics, Ladoke Akintola University of Technology, Nigeria Correspondence: Adekanmbi, D.B, Department of Statistics, Ladoke Akintola University of Technology, Ogbomoso, Nigeria. Received: November 6, 2017 Accepted: November 27, 2017 Online Published: March 13, 2018 doi:10.5539/ijsp.v7n3p9 URL: https://doi.org/10.5539/ijsp.v7n3p9 Abstract The interest of this study is to explore the relationship between a dichotomous response, learning style preferences by university students of Sidhu School, Wilkes University, as a function of the following predictors: Gender, Age, employment status, cumulative grade point assessment (GPA) and level of study, as in usual generalized linear model. The response variable is the students’ preference for either Behaviorist or Humanist learning style. Four different binomial regression models were fitted to the data. Model A is a logit regression model that fits all the predictors, Model B is a probit model that fits all the predictors, Model C is a logit model with an effect modifier, while Model D is a probit model also with an effect modifier. Models A and B appeared to have performed poorly in fitting the data. Models C and D fit the data well as confirmed by the non-significant chi-square lack of fit with p-values 0.1409 and 0.1408 respectively. Among the four models considered for fitting the data, Model D, the probit model with effect modifier fit best.