An Introduction to Poisson Regression Russ Lavery, K&L Consulting Services, King of Prussia, PA, U.S.A
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Generalized Linear Models (Glms)
San Jos´eState University Math 261A: Regression Theory & Methods Generalized Linear Models (GLMs) Dr. Guangliang Chen This lecture is based on the following textbook sections: • Chapter 13: 13.1 – 13.3 Outline of this presentation: • What is a GLM? • Logistic regression • Poisson regression Generalized Linear Models (GLMs) What is a GLM? In ordinary linear regression, we assume that the response is a linear function of the regressors plus Gaussian noise: 0 2 y = β0 + β1x1 + ··· + βkxk + ∼ N(x β, σ ) | {z } |{z} linear form x0β N(0,σ2) noise The model can be reformulate in terms of • distribution of the response: y | x ∼ N(µ, σ2), and • dependence of the mean on the predictors: µ = E(y | x) = x0β Dr. Guangliang Chen | Mathematics & Statistics, San Jos´e State University3/24 Generalized Linear Models (GLMs) beta=(1,2) 5 4 3 β0 + β1x b y 2 y 1 0 −1 0.0 0.2 0.4 0.6 0.8 1.0 x x Dr. Guangliang Chen | Mathematics & Statistics, San Jos´e State University4/24 Generalized Linear Models (GLMs) Generalized linear models (GLM) extend linear regression by allowing the response variable to have • a general distribution (with mean µ = E(y | x)) and • a mean that depends on the predictors through a link function g: That is, g(µ) = β0x or equivalently, µ = g−1(β0x) Dr. Guangliang Chen | Mathematics & Statistics, San Jos´e State University5/24 Generalized Linear Models (GLMs) In GLM, the response is typically assumed to have a distribution in the exponential family, which is a large class of probability distributions that have pdfs of the form f(x | θ) = a(x)b(θ) exp(c(θ) · T (x)), including • Normal - ordinary linear regression • Bernoulli - Logistic regression, modeling binary data • Binomial - Multinomial logistic regression, modeling general cate- gorical data • Poisson - Poisson regression, modeling count data • Exponential, Gamma - survival analysis Dr. -

Generalized Linear Models with Poisson Family: Applications in Ecology
UNIVERSITY OF ABOMEY- CALAVI *********** FACULTY OF AGRONOMIC SCIENCES *************** **************** Master Program in Statistics, Major Biostatistics 1st batch Generalized linear models with Poisson family: applications in ecology A thesis submitted to the Faculty of Agronomic Sciences in partial fulfillment of the requirements for the degree of the Master of Sciences in Biostatistics Presented by: LOKONON Enagnon Bruno Supervisor: Pr Romain L. GLELE KAKAÏ, Professor of Biostatistics and Forest estimation Academic year: 2014-2015 UNIVERSITE D’ABOMEY- CALAVI *********** FACULTE DES SCIENCES AGRONOMIQUES *************** ************** Programme de Master en Biostatistiques 1ère Promotion Modèles linéaires généralisés de la famille de Poisson : applications en écologie Mémoire soumis à la Faculté des Sciences Agronomiques pour obtenir le Diplôme de Master recherche en Biostatistiques Présenté par: LOKONON Enagnon Bruno Superviseur: Pr Romain L. GLELE KAKAÏ, Professeur titulaire de Biostatistiques et estimation forestière Année académique: 2014-2015 Certification I certify that this work has been achieved by LOKONON E. Bruno under my entire supervision at the University of Abomey-Calavi (Benin) in order to obtain his Master of Science degree in Biostatistics. Pr Romain L. GLELE KAKAÏ Professor of Biostatistics and Forest estimation i Acknowledgements This research was supported by WAAPP/PPAAO-BENIN (West African Agricultural Productivity Program/ Programme de Productivité Agricole en Afrique de l‟Ouest). This dissertation could only have been possible through the generous contributions of many people. First and foremost, I am grateful to my supervisor Pr Romain L. GLELE KAKAÏ, Professor of Biostatistics and Forest estimation who tirelessly played key role in orientation, scientific writing and mentoring during this research. In particular, I thank him for his prompt availability whenever needed. -

Overdispersion, and How to Deal with It in R and JAGS (Requires R-Packages AER, Coda, Lme4, R2jags, Dharma/Devtools) Carsten F
Overdispersion, and how to deal with it in R and JAGS (requires R-packages AER, coda, lme4, R2jags, DHARMa/devtools) Carsten F. Dormann 07 December, 2016 Contents 1 Introduction: what is overdispersion? 1 2 Recognising (and testing for) overdispersion 1 3 “Fixing” overdispersion 5 3.1 Quasi-families . .5 3.2 Different distribution (here: negative binomial) . .6 3.3 Observation-level random effects (OLRE) . .8 4 Overdispersion in JAGS 12 1 Introduction: what is overdispersion? Overdispersion describes the observation that variation is higher than would be expected. Some distributions do not have a parameter to fit variability of the observation. For example, the normal distribution does that through the parameter σ (i.e. the standard deviation of the model), which is constant in a typical regression. In contrast, the Poisson distribution has no such parameter, and in fact the variance increases with the mean (i.e. the variance and the mean have the same value). In this latter case, for an expected value of E(y) = 5, we also expect that the variance of observed data points is 5. But what if it is not? What if the observed variance is much higher, i.e. if the data are overdispersed? (Note that it could also be lower, underdispersed. This is less often the case, and not all approaches below allow for modelling underdispersion, but some do.) Overdispersion arises in different ways, most commonly through “clumping”. Imagine the number of seedlings in a forest plot. Depending on the distance to the source tree, there may be many (hundreds) or none. The same goes for shooting stars: either the sky is empty, or littered with shooting stars. -

Poisson Versus Negative Binomial Regression
Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Poisson versus Negative Binomial Regression Randall Reese Utah State University [email protected] February 29, 2016 Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Overview 1 Handling Count Data ADEM Overdispersion 2 The Negative Binomial Distribution Foundations of Negative Binomial Distribution Basic Properties of the Negative Binomial Distribution Fitting the Negative Binomial Model 3 Other Applications and Analysis in R 4 References Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Data whose values come from Z≥0, the non-negative integers. Classic example is deaths in the Prussian army per year by horse kick (Bortkiewicz) Example 2 of Notes 5. (Number of successful \attempts"). Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Poisson Distribution Support is the non-negative integers. (Count data). Described by a single parameter λ > 0. When Y ∼ Poisson(λ), then E(Y ) = Var(Y ) = λ Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Acute Disseminated Encephalomyelitis Acute Disseminated Encephalomyelitis (ADEM) is a neurological, immune disorder in which widespread inflammation of the brain and spinal cord damages tissue known as white matter. -
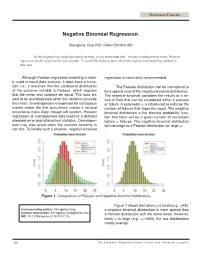
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Heteroscedastic Errors
Heteroscedastic Errors ◮ Sometimes plots and/or tests show that the error variances 2 σi = Var(ǫi ) depend on i ◮ Several standard approaches to fixing the problem, depending on the nature of the dependence. ◮ Weighted Least Squares. ◮ Transformation of the response. ◮ Generalized Linear Models. Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Weighted Least Squares ◮ Suppose variances are known except for a constant factor. 2 2 ◮ That is, σi = σ /wi . ◮ Use weighted least squares. (See Chapter 10 in the text.) ◮ This usually arises realistically in the following situations: ◮ Yi is an average of ni measurements where you know ni . Then wi = ni . 2 ◮ Plots suggest that σi might be proportional to some power of 2 γ γ some covariate: σi = kxi . Then wi = xi− . Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Variances depending on (mean of) Y ◮ Two standard approaches are available: ◮ Older approach is transformation. ◮ Newer approach is use of generalized linear model; see STAT 402. Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Transformation ◮ Compute Yi∗ = g(Yi ) for some function g like logarithm or square root. ◮ Then regress Yi∗ on the covariates. ◮ This approach sometimes works for skewed response variables like income; ◮ after transformation we occasionally find the errors are more nearly normal, more homoscedastic and that the model is simpler. ◮ See page 130ff and check under transformations and Box-Cox in the index. Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Generalized Linear Models ◮ Transformation uses the model T E(g(Yi )) = xi β while generalized linear models use T g(E(Yi )) = xi β ◮ Generally latter approach offers more flexibility. -

Generalized Linear Models
CHAPTER 6 Generalized linear models 6.1 Introduction Generalized linear modeling is a framework for statistical analysis that includes linear and logistic regression as special cases. Linear regression directly predicts continuous data y from a linear predictor Xβ = β0 + X1β1 + + Xkβk.Logistic regression predicts Pr(y =1)forbinarydatafromalinearpredictorwithaninverse-··· logit transformation. A generalized linear model involves: 1. A data vector y =(y1,...,yn) 2. Predictors X and coefficients β,formingalinearpredictorXβ 1 3. A link function g,yieldingavectoroftransformeddataˆy = g− (Xβ)thatare used to model the data 4. A data distribution, p(y yˆ) | 5. Possibly other parameters, such as variances, overdispersions, and cutpoints, involved in the predictors, link function, and data distribution. The options in a generalized linear model are the transformation g and the data distribution p. In linear regression,thetransformationistheidentity(thatis,g(u) u)and • the data distribution is normal, with standard deviation σ estimated from≡ data. 1 1 In logistic regression,thetransformationistheinverse-logit,g− (u)=logit− (u) • (see Figure 5.2a on page 80) and the data distribution is defined by the proba- bility for binary data: Pr(y =1)=y ˆ. This chapter discusses several other classes of generalized linear model, which we list here for convenience: The Poisson model (Section 6.2) is used for count data; that is, where each • data point yi can equal 0, 1, 2, ....Theusualtransformationg used here is the logarithmic, so that g(u)=exp(u)transformsacontinuouslinearpredictorXiβ to a positivey ˆi.ThedatadistributionisPoisson. It is usually a good idea to add a parameter to this model to capture overdis- persion,thatis,variationinthedatabeyondwhatwouldbepredictedfromthe Poisson distribution alone. -

Modeling Overdispersion with the Normalized Tempered Stable Distribution
Modeling overdispersion with the normalized tempered stable distribution M. Kolossiatisa, J.E. Griffinb, M. F. J. Steel∗,c aDepartment of Hotel and Tourism Management, Cyprus University of Technology, P.O. Box 50329, 3603 Limassol, Cyprus. bInstitute of Mathematics, Statistics and Actuarial Science, University of Kent, Canterbury, CT2 7NF, U.K. cDepartment of Statistics, University of Warwick, Coventry, CV4 7AL, U.K. Abstract A multivariate distribution which generalizes the Dirichlet distribution is intro- duced and its use for modeling overdispersion in count data is discussed. The distribution is constructed by normalizing a vector of independent tempered sta- ble random variables. General formulae for all moments and cross-moments of the distribution are derived and they are found to have similar forms to those for the Dirichlet distribution. The univariate version of the distribution can be used as a mixing distribution for the success probability of a binomial distribution to define an alternative to the well-studied beta-binomial distribution. Examples of fitting this model to simulated and real data are presented. Keywords: Distribution on the unit simplex; Mice fetal mortality; Mixed bino- mial; Normalized random measure; Overdispersion 1. Introduction In many experiments we observe data as the number of observations in a sam- ple with some property. The binomial distribution is a natural model for this type of data. However, the data are often found to be overdispersed relative to that ∗Corresponding author. Tel.: +44-2476-523369; fax: +44-2476-524532 Email addresses: [email protected] (M. Kolossiatis), [email protected] (J.E. Griffin), [email protected] (M. -

Bayesian Hierarchical Poisson Regression Model for Overdispersed Count Data
Bayesian Hierarchical Poisson Regression Model for Overdispersed Count Data Overview This example uses the RANDOM statement in MCMC procedure to fit a Bayesian hierarchical Poisson regression model to overdispersed count data. The RANDOM statement, available in SAS/STAT 9.3 and later, provides a convenient way to specify random effects with substantionally improved performance. Overdispersion occurs when count data appear more dispersed than expected under a reference model. Overdispersion can be caused by positive correlation among the observations, an incorrect model, an in- correct distributional specification, or incorrect variance functions. The example displays how Bayesian hierarchical Poisson regression models are effective in capturing overdispersion and providing a better fit. The SAS source code for this example is available as a text file attachment. In Adobe Acrobat, right-click the icon in the margin and select Save Embedded File to Disk. You can also double-click the icon to open the file immediately. Analysis Count data frequently display overdispersion (more variation than expected from a standard parametric model). Breslow(1984) discusses these types of models and suggests several different ways to model them. Hierarchical Poisson models have been found effective in capturing the overdispersion in data sets with extra Poisson variation. Hierarchical Poisson regression models are expressed as Poisson models with a log link and a normal vari- ance on the mean parameter. More formally, a hierarchical Poisson regression model is written as Yij ij Poisson.ij / j log.ij / Xi ˇ ij D C 2 ij normal.0; / for i 1; :::; n, j 1; :::; J , and y 0; 1; 2; ::: . -

Variance Partitioning in Multilevel Logistic Models That Exhibit Overdispersion
J. R. Statist. Soc. A (2005) 168, Part 3, pp. 599–613 Variance partitioning in multilevel logistic models that exhibit overdispersion W. J. Browne, University of Nottingham, UK S. V. Subramanian, Harvard School of Public Health, Boston, USA K. Jones University of Bristol, UK and H. Goldstein Institute of Education, London, UK [Received July 2002. Final revision September 2004] Summary. A common application of multilevel models is to apportion the variance in the response according to the different levels of the data.Whereas partitioning variances is straight- forward in models with a continuous response variable with a normal error distribution at each level, the extension of this partitioning to models with binary responses or to proportions or counts is less obvious. We describe methodology due to Goldstein and co-workers for appor- tioning variance that is attributable to higher levels in multilevel binomial logistic models. This partitioning they referred to as the variance partition coefficient. We consider extending the vari- ance partition coefficient concept to data sets when the response is a proportion and where the binomial assumption may not be appropriate owing to overdispersion in the response variable. Using the literacy data from the 1991 Indian census we estimate simple and complex variance partition coefficients at multiple levels of geography in models with significant overdispersion and thereby establish the relative importance of different geographic levels that influence edu- cational disparities in India. Keywords: Contextual variation; Illiteracy; India; Multilevel modelling; Multiple spatial levels; Overdispersion; Variance partition coefficient 1. Introduction Multilevel regression models (Goldstein, 2003; Bryk and Raudenbush, 1992) are increasingly being applied in many areas of quantitative research. -

Using Geographically Weighted Poisson Regression for County-Level Crash Modeling in California ⇑ Zhibin Li A,B, , Wei Wang A,1, Pan Liu A,2, John M
Safety Science 58 (2013) 89–97 Contents lists available at SciVerse ScienceDirect Safety Science journal homepage: www.elsevier.com/locate/ssci Using Geographically Weighted Poisson Regression for county-level crash modeling in California ⇑ Zhibin Li a,b, , Wei Wang a,1, Pan Liu a,2, John M. Bigham b,3, David R. Ragland b,3 a School of Transportation, Southeast University, Si Pai Lou #2, Nanjing 210096, China b Safe Transportation Research and Education Center, Institute of Transportation Studies, University of California, Berkeley, 2614 Dwight Way #7374, Berkeley, CA 94720-7374, United States article info abstract Article history: Development of crash prediction models at the county-level has drawn the interests of state agencies for Received 25 December 2012 forecasting the normal level of traffic safety according to a series of countywide characteristics. A com- Received in revised form 11 March 2013 mon technique for the county-level crash modeling is the generalized linear modeling (GLM) procedure. Accepted 13 April 2013 However, the GLM fails to capture the spatial heterogeneity that exists in the relationship between crash counts and explanatory variables over counties. This study aims to evaluate the use of a Geographically Weighted Poisson Regression (GWPR) to capture these spatially varying relationships in the county-level Keywords: crash data. The performance of a GWPR was compared to a traditional GLM. Fatal crashes and countywide Safety factors including traffic patterns, road network attributes, and socio-demographic characteristics were Crash County-level collected from the 58 counties in California. Results showed that the GWPR was useful in capturing Geographically Weighted Regression the spatially non-stationary relationships between crashes and predicting factors at the county level. -
Meta-Analysis of Count Data What Is Count Data Complicated by What Is
What is count data Meta-analysis of count data • Data that can only take the non-negative integer values 0, 1, 2, 3, ……. • Examples in RCTs – Episodes of exacerbation of asthma – Falls Peter Herbison – Number of incontinence episodes Department of Preventive and • Time scale can vary from the whole study Social Medicine period to the last few (pick your time University of Otago period). Complicated by What is large? • Different exposure times .4 – Withdrawals .3 – Deaths – Different diary periods .2 • Sometimes people only fill out some days of the Probability diary as well as the periods being different .1 • Counts with a large mean can be treated 0 as normally distributed 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 n Mean 1 Mean 2 Mean 3 Mean 4 Mean 5 Analysis as rates Meta-analysis of rate ratios • Count number of events in each arm • Formula for calculation in Handbook • Calculate person years at risk in each arm • Straightforward using generic inverse • Calculate rates in each arm variance • Divide to get a rate ratio • In addition to the one reference in the • Can also be done by poisson regression Handbook: family – Guevara et al. Meta-analytic methods for – Poisson, negative binomial, zero inflated pooling rates when follow up duration varies: poisson a case study. BMC Medical Research – Assumes constant underlying risk Methodology 2004;4:17 Dichotimizing Treat as continuous • Change data so that it is those who have • May not be too bad one or more events versus those who • Handbook says beware of skewness have none • Get a 2x2 table • Good if the purpose of the treatment is to prevent events rather than reduce the number of them • Meta-analyse as usual Time to event Not so helpful • Usually time to first event but repeated • Many people look at the distribution and events can be used think that the only distribution that exists is • Analyse by survival analysis (e.g.