Modeling Overdispersion with the Normalized Tempered Stable Distribution
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Random Variable X with Pdf G(X) = Λα Γ(Α) X ≥ 0 Has Gamma
DISTRIBUTIONS DERIVED FROM THE NORMAL DISTRIBUTION Definition: A random variable X with pdf λα g(x) = xα−1e−λx x ≥ 0 Γ(α) has gamma distribution with parameters α > 0 and λ > 0. The gamma function Γ(x), is defined as Z ∞ Γ(x) = ux−1e−udu. 0 Properties of the Gamma Function: (i) Γ(x + 1) = xΓ(x) (ii) Γ(n + 1) = n! √ (iii) Γ(1/2) = π. Remarks: 1. Notice that an exponential rv with parameter 1/θ = λ is a special case of a gamma rv. with parameters α = 1 and λ. 2. The sum of n independent identically distributed (iid) exponential rv, with parameter λ has a gamma distribution, with parameters n and λ. 3. The sum of n iid gamma rv with parameters α and λ has gamma distribution with parameters nα and λ. Definition: If Z is a standard normal rv, the distribution of U = Z2 called the chi-square distribution with 1 degree of freedom. 2 The density function of U ∼ χ1 is −1/2 x −x/2 fU (x) = √ e , x > 0. 2π 2 Remark: A χ1 random variable has the same density as a random variable with gamma distribution, with parameters α = 1/2 and λ = 1/2. Definition: If U1,U2,...,Uk are independent chi-square rv-s with 1 degree of freedom, the distribution of V = U1 + U2 + ... + Uk is called the chi-square distribution with k degrees of freedom. 2 Using Remark 3. and the above remark, a χk rv. follows gamma distribution with parameters 2 α = k/2 and λ = 1/2. -

An Introduction to Poisson Regression Russ Lavery, K&L Consulting Services, King of Prussia, PA, U.S.A
NESUG 2010 Statistics and Analysis An Animated Guide: An Introduction To Poisson Regression Russ Lavery, K&L Consulting Services, King of Prussia, PA, U.S.A. ABSTRACT: This paper will be a brief introduction to Poisson regression (theory, steps to be followed, complications and interpretation) via a worked example. It is hoped that this will increase motivation towards learning this useful statistical technique. INTRODUCTION: Poisson regression is available in SAS through the GENMOD procedure (generalized modeling). It is appropriate when: 1) the process that generates the conditional Y distributions would, theoretically, be expected to be a Poisson random process and 2) when there is no evidence of overdispersion and 3) when the mean of the marginal distribution is less than ten (preferably less than five and ideally close to one). THE POISSON DISTRIBUTION: The Poison distribution is a discrete Percent of observations where the random variable X is expected distribution and is appropriate for to have the value x, given that the Poisson distribution has a mean modeling counts of observations. of λ= P(X=x, λ ) = (e - λ * λ X) / X! Counts are observed cases, like the 0.4 count of measles cases in cities. You λ can simply model counts if all data 0.35 were collected in the same measuring 0.3 unit (e.g. the same number of days or 0.3 0.5 0.8 same number of square feet). 0.25 λ 1 0.2 3 You can use the Poisson Distribution = 5 for modeling rates (rates are counts 0.15 20 per unit) if the units of collection were 8 different. -

Stat 5101 Notes: Brand Name Distributions
Stat 5101 Notes: Brand Name Distributions Charles J. Geyer February 14, 2003 1 Discrete Uniform Distribution Symbol DiscreteUniform(n). Type Discrete. Rationale Equally likely outcomes. Sample Space The interval 1, 2, ..., n of the integers. Probability Function 1 f(x) = , x = 1, 2, . , n n Moments n + 1 E(X) = 2 n2 − 1 var(X) = 12 2 Uniform Distribution Symbol Uniform(a, b). Type Continuous. Rationale Continuous analog of the discrete uniform distribution. Parameters Real numbers a and b with a < b. Sample Space The interval (a, b) of the real numbers. 1 Probability Density Function 1 f(x) = , a < x < b b − a Moments a + b E(X) = 2 (b − a)2 var(X) = 12 Relation to Other Distributions Beta(1, 1) = Uniform(0, 1). 3 Bernoulli Distribution Symbol Bernoulli(p). Type Discrete. Rationale Any zero-or-one-valued random variable. Parameter Real number 0 ≤ p ≤ 1. Sample Space The two-element set {0, 1}. Probability Function ( p, x = 1 f(x) = 1 − p, x = 0 Moments E(X) = p var(X) = p(1 − p) Addition Rule If X1, ..., Xk are i. i. d. Bernoulli(p) random variables, then X1 + ··· + Xk is a Binomial(k, p) random variable. Relation to Other Distributions Bernoulli(p) = Binomial(1, p). 4 Binomial Distribution Symbol Binomial(n, p). 2 Type Discrete. Rationale Sum of i. i. d. Bernoulli random variables. Parameters Real number 0 ≤ p ≤ 1. Integer n ≥ 1. Sample Space The interval 0, 1, ..., n of the integers. Probability Function n f(x) = px(1 − p)n−x, x = 0, 1, . , n x Moments E(X) = np var(X) = np(1 − p) Addition Rule If X1, ..., Xk are independent random variables, Xi being Binomial(ni, p) distributed, then X1 + ··· + Xk is a Binomial(n1 + ··· + nk, p) random variable. -

On a Problem Connected with Beta and Gamma Distributions by R
ON A PROBLEM CONNECTED WITH BETA AND GAMMA DISTRIBUTIONS BY R. G. LAHA(i) 1. Introduction. The random variable X is said to have a Gamma distribution G(x;0,a)if du for x > 0, (1.1) P(X = x) = G(x;0,a) = JoT(a)" 0 for x ^ 0, where 0 > 0, a > 0. Let X and Y be two independently and identically distributed random variables each having a Gamma distribution of the form (1.1). Then it is well known [1, pp. 243-244], that the random variable W = X¡iX + Y) has a Beta distribution Biw ; a, a) given by 0 for w = 0, (1.2) PiW^w) = Biw;x,x)=\ ) u"-1il-u)'-1du for0<w<l, Ío T(a)r(a) 1 for w > 1. Now we can state the converse problem as follows : Let X and Y be two independently and identically distributed random variables having a common distribution function Fix). Suppose that W = Xj{X + Y) has a Beta distribution of the form (1.2). Then the question is whether £(x) is necessarily a Gamma distribution of the form (1.1). This problem was posed by Mauldon in [9]. He also showed that the converse problem is not true in general and constructed an example of a non-Gamma distribution with this property using the solution of an integral equation which was studied by Goodspeed in [2]. In the present paper we carry out a systematic investigation of this problem. In §2, we derive some general properties possessed by this class of distribution laws Fix). -

A Form of Multivariate Gamma Distribution
Ann. Inst. Statist. Math. Vol. 44, No. 1, 97-106 (1992) A FORM OF MULTIVARIATE GAMMA DISTRIBUTION A. M. MATHAI 1 AND P. G. MOSCHOPOULOS2 1 Department of Mathematics and Statistics, McOill University, Montreal, Canada H3A 2K6 2Department of Mathematical Sciences, The University of Texas at El Paso, El Paso, TX 79968-0514, U.S.A. (Received July 30, 1990; revised February 14, 1991) Abstract. Let V,, i = 1,...,k, be independent gamma random variables with shape ai, scale /3, and location parameter %, and consider the partial sums Z1 = V1, Z2 = 171 + V2, . • •, Zk = 171 +. • • + Vk. When the scale parameters are all equal, each partial sum is again distributed as gamma, and hence the joint distribution of the partial sums may be called a multivariate gamma. This distribution, whose marginals are positively correlated has several interesting properties and has potential applications in stochastic processes and reliability. In this paper we study this distribution as a multivariate extension of the three-parameter gamma and give several properties that relate to ratios and conditional distributions of partial sums. The general density, as well as special cases are considered. Key words and phrases: Multivariate gamma model, cumulative sums, mo- ments, cumulants, multiple correlation, exact density, conditional density. 1. Introduction The three-parameter gamma with the density (x _ V)~_I exp (x-7) (1.1) f(x; a, /3, 7) = ~ , x>'7, c~>O, /3>0 stands central in the multivariate gamma distribution of this paper. Multivariate extensions of gamma distributions such that all the marginals are again gamma are the most common in the literature. -

Overdispersion, and How to Deal with It in R and JAGS (Requires R-Packages AER, Coda, Lme4, R2jags, Dharma/Devtools) Carsten F
Overdispersion, and how to deal with it in R and JAGS (requires R-packages AER, coda, lme4, R2jags, DHARMa/devtools) Carsten F. Dormann 07 December, 2016 Contents 1 Introduction: what is overdispersion? 1 2 Recognising (and testing for) overdispersion 1 3 “Fixing” overdispersion 5 3.1 Quasi-families . .5 3.2 Different distribution (here: negative binomial) . .6 3.3 Observation-level random effects (OLRE) . .8 4 Overdispersion in JAGS 12 1 Introduction: what is overdispersion? Overdispersion describes the observation that variation is higher than would be expected. Some distributions do not have a parameter to fit variability of the observation. For example, the normal distribution does that through the parameter σ (i.e. the standard deviation of the model), which is constant in a typical regression. In contrast, the Poisson distribution has no such parameter, and in fact the variance increases with the mean (i.e. the variance and the mean have the same value). In this latter case, for an expected value of E(y) = 5, we also expect that the variance of observed data points is 5. But what if it is not? What if the observed variance is much higher, i.e. if the data are overdispersed? (Note that it could also be lower, underdispersed. This is less often the case, and not all approaches below allow for modelling underdispersion, but some do.) Overdispersion arises in different ways, most commonly through “clumping”. Imagine the number of seedlings in a forest plot. Depending on the distance to the source tree, there may be many (hundreds) or none. The same goes for shooting stars: either the sky is empty, or littered with shooting stars. -

Poisson Versus Negative Binomial Regression
Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Poisson versus Negative Binomial Regression Randall Reese Utah State University [email protected] February 29, 2016 Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Overview 1 Handling Count Data ADEM Overdispersion 2 The Negative Binomial Distribution Foundations of Negative Binomial Distribution Basic Properties of the Negative Binomial Distribution Fitting the Negative Binomial Model 3 Other Applications and Analysis in R 4 References Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Data whose values come from Z≥0, the non-negative integers. Classic example is deaths in the Prussian army per year by horse kick (Bortkiewicz) Example 2 of Notes 5. (Number of successful \attempts"). Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Poisson Distribution Support is the non-negative integers. (Count data). Described by a single parameter λ > 0. When Y ∼ Poisson(λ), then E(Y ) = Var(Y ) = λ Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Acute Disseminated Encephalomyelitis Acute Disseminated Encephalomyelitis (ADEM) is a neurological, immune disorder in which widespread inflammation of the brain and spinal cord damages tissue known as white matter. -

A Note on the Existence of the Multivariate Gamma Distribution 1
- 1 - A Note on the Existence of the Multivariate Gamma Distribution Thomas Royen Fachhochschule Bingen, University of Applied Sciences e-mail: [email protected] Abstract. The p - variate gamma distribution in the sense of Krishnamoorthy and Parthasarathy exists for all positive integer degrees of freedom and at least for all real values pp 2, 2. For special structures of the “associated“ covariance matrix it also exists for all positive . In this paper a relation between central and non-central multivariate gamma distributions is shown, which implies the existence of the p - variate gamma distribution at least for all non-integer greater than the integer part of (p 1) / 2 without any additional assumptions for the associated covariance matrix. 1. Introduction The p-variate chi-square distribution (or more precisely: “Wishart-chi-square distribution“) with degrees of 2 freedom and the “associated“ covariance matrix (the p (,) - distribution) is defined as the joint distribu- tion of the diagonal elements of a Wp (,) - Wishart matrix. Its probability density (pdf) has the Laplace trans- form (Lt) /2 |ITp 2 | , (1.1) with the ()pp - identity matrix I p , , T diag( t1 ,..., tpj ), t 0, and the associated covariance matrix , which is assumed to be non-singular throughout this paper. The p - variate gamma distribution in the sense of Krishnamoorthy and Parthasarathy [4] with the associated covariance matrix and the “degree of freedom” 2 (the p (,) - distribution) can be defined by the Lt ||ITp (1.2) of its pdf g ( x1 ,..., xp ; , ). (1.3) 2 For values 2 this distribution differs from the p (,) - distribution only by a scale factor 2, but in this paper we are only interested in positive non-integer values 2 for which ||ITp is the Lt of a pdf and not of a function also assuming any negative values. -
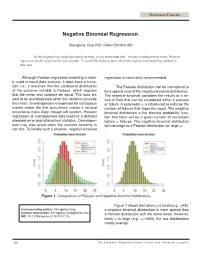
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Negative Binomial Regression Models and Estimation Methods
Appendix D: Negative Binomial Regression Models and Estimation Methods By Dominique Lord Texas A&M University Byung-Jung Park Korea Transport Institute This appendix presents the characteristics of Negative Binomial regression models and discusses their estimating methods. Probability Density and Likelihood Functions The properties of the negative binomial models with and without spatial intersection are described in the next two sections. Poisson-Gamma Model The Poisson-Gamma model has properties that are very similar to the Poisson model discussed in Appendix C, in which the dependent variable yi is modeled as a Poisson variable with a mean i where the model error is assumed to follow a Gamma distribution. As it names implies, the Poisson-Gamma is a mixture of two distributions and was first derived by Greenwood and Yule (1920). This mixture distribution was developed to account for over-dispersion that is commonly observed in discrete or count data (Lord et al., 2005). It became very popular because the conjugate distribution (same family of functions) has a closed form and leads to the negative binomial distribution. As discussed by Cook (2009), “the name of this distribution comes from applying the binomial theorem with a negative exponent.” There are two major parameterizations that have been proposed and they are known as the NB1 and NB2, the latter one being the most commonly known and utilized. NB2 is therefore described first. Other parameterizations exist, but are not discussed here (see Maher and Summersgill, 1996; Hilbe, 2007). NB2 Model Suppose that we have a series of random counts that follows the Poisson distribution: i e i gyii; (D-1) yi ! where yi is the observed number of counts for i 1, 2, n ; and i is the mean of the Poisson distribution. -

Generalized Linear Models
CHAPTER 6 Generalized linear models 6.1 Introduction Generalized linear modeling is a framework for statistical analysis that includes linear and logistic regression as special cases. Linear regression directly predicts continuous data y from a linear predictor Xβ = β0 + X1β1 + + Xkβk.Logistic regression predicts Pr(y =1)forbinarydatafromalinearpredictorwithaninverse-··· logit transformation. A generalized linear model involves: 1. A data vector y =(y1,...,yn) 2. Predictors X and coefficients β,formingalinearpredictorXβ 1 3. A link function g,yieldingavectoroftransformeddataˆy = g− (Xβ)thatare used to model the data 4. A data distribution, p(y yˆ) | 5. Possibly other parameters, such as variances, overdispersions, and cutpoints, involved in the predictors, link function, and data distribution. The options in a generalized linear model are the transformation g and the data distribution p. In linear regression,thetransformationistheidentity(thatis,g(u) u)and • the data distribution is normal, with standard deviation σ estimated from≡ data. 1 1 In logistic regression,thetransformationistheinverse-logit,g− (u)=logit− (u) • (see Figure 5.2a on page 80) and the data distribution is defined by the proba- bility for binary data: Pr(y =1)=y ˆ. This chapter discusses several other classes of generalized linear model, which we list here for convenience: The Poisson model (Section 6.2) is used for count data; that is, where each • data point yi can equal 0, 1, 2, ....Theusualtransformationg used here is the logarithmic, so that g(u)=exp(u)transformsacontinuouslinearpredictorXiβ to a positivey ˆi.ThedatadistributionisPoisson. It is usually a good idea to add a parameter to this model to capture overdis- persion,thatis,variationinthedatabeyondwhatwouldbepredictedfromthe Poisson distribution alone. -

Supplementary Information on the Negative Binomial Distribution
Supplementary information on the negative binomial distribution November 25, 2013 1 The Poisson distribution Consider a segment of DNA as a collection of a large number, say N, of individual intervals over which a break can take place. Furthermore, suppose the probability of a break in each interval is the same and is very small, say p(N), and breaks occur in the intervals independently of one another. Here, we need p to be a function of N because if there are more locations (i.e. N is increased) we need to make p smaller if we want to have the same model (since there are more opportunities for breaks). Since the number of breaks is a cumulative sum of iid Bernoulli variables, the distribution of breaks, y, is binomially distributed with parameters (N; p(N)), that is N P (y = k) = p(N)k(1 − p(N))N−k: k If we suppose p(N) = λ/N, for some λ, and we let N become arbitrarily large, then we find N P (y = k) = lim p(N)k(1 − p(N))N−k N!1 k N ··· (N − k + 1) = lim (λ/N)k(1 − λ/N)N−k N!1 k! λk N ··· (N − k + 1) = lim (1 − λ/N)N (1 − λ/N)−k N!1 k! N k = λke−λ=k! which is the Poisson distribution. It has a mean and variance of λ. The mean of a discrete random P 2 variable, y, is EY = k kP (Y = k) and the variance is E(Y − EY ) .