Variance Partitioning in Multilevel Logistic Models That Exhibit Overdispersion
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Introduction to Poisson Regression Russ Lavery, K&L Consulting Services, King of Prussia, PA, U.S.A
NESUG 2010 Statistics and Analysis An Animated Guide: An Introduction To Poisson Regression Russ Lavery, K&L Consulting Services, King of Prussia, PA, U.S.A. ABSTRACT: This paper will be a brief introduction to Poisson regression (theory, steps to be followed, complications and interpretation) via a worked example. It is hoped that this will increase motivation towards learning this useful statistical technique. INTRODUCTION: Poisson regression is available in SAS through the GENMOD procedure (generalized modeling). It is appropriate when: 1) the process that generates the conditional Y distributions would, theoretically, be expected to be a Poisson random process and 2) when there is no evidence of overdispersion and 3) when the mean of the marginal distribution is less than ten (preferably less than five and ideally close to one). THE POISSON DISTRIBUTION: The Poison distribution is a discrete Percent of observations where the random variable X is expected distribution and is appropriate for to have the value x, given that the Poisson distribution has a mean modeling counts of observations. of λ= P(X=x, λ ) = (e - λ * λ X) / X! Counts are observed cases, like the 0.4 count of measles cases in cities. You λ can simply model counts if all data 0.35 were collected in the same measuring 0.3 unit (e.g. the same number of days or 0.3 0.5 0.8 same number of square feet). 0.25 λ 1 0.2 3 You can use the Poisson Distribution = 5 for modeling rates (rates are counts 0.15 20 per unit) if the units of collection were 8 different. -

Logistic Regression, Dependencies, Non-Linear Data and Model Reduction
COMP6237 – Logistic Regression, Dependencies, Non-linear Data and Model Reduction Markus Brede [email protected] Lecture slides available here: http://users.ecs.soton.ac.uk/mb8/stats/datamining.html (Thanks to Jason Noble and Cosma Shalizi whose lecture materials I used to prepare) COMP6237: Logistic Regression ● Outline: – Introduction – Basic ideas of logistic regression – Logistic regression using R – Some underlying maths and MLE – The multinomial case – How to deal with non-linear data ● Model reduction and AIC – How to deal with dependent data – Summary – Problems Introduction ● Previous lecture: Linear regression – tried to predict a continuous variable from variation in another continuous variable (E.g. basketball ability from height) ● Here: Logistic regression – Try to predict results of a binary (or categorical) outcome variable Y from a predictor variable X – This is a classification problem: classify X as belonging to one of two classes – Occurs quite often in science … e.g. medical trials (will a patient live or die dependent on medication?) Dependent variable Y Predictor Variables X The Oscars Example ● A fictional data set that looks at what it takes for a movie to win an Oscar ● Outcome variable: Oscar win, yes or no? ● Predictor variables: – Box office takings in millions of dollars – Budget in millions of dollars – Country of origin: US, UK, Europe, India, other – Critical reception (scores 0 … 100) – Length of film in minutes – This (fictitious) data set is available here: https://www.southampton.ac.uk/~mb1a10/stats/filmData.txt Predicting Oscar Success ● Let's start simple and look at only one of the predictor variables ● Do big box office takings make Oscar success more likely? ● Could use same techniques as below to look at budget size, film length, etc. -

Overdispersion, and How to Deal with It in R and JAGS (Requires R-Packages AER, Coda, Lme4, R2jags, Dharma/Devtools) Carsten F
Overdispersion, and how to deal with it in R and JAGS (requires R-packages AER, coda, lme4, R2jags, DHARMa/devtools) Carsten F. Dormann 07 December, 2016 Contents 1 Introduction: what is overdispersion? 1 2 Recognising (and testing for) overdispersion 1 3 “Fixing” overdispersion 5 3.1 Quasi-families . .5 3.2 Different distribution (here: negative binomial) . .6 3.3 Observation-level random effects (OLRE) . .8 4 Overdispersion in JAGS 12 1 Introduction: what is overdispersion? Overdispersion describes the observation that variation is higher than would be expected. Some distributions do not have a parameter to fit variability of the observation. For example, the normal distribution does that through the parameter σ (i.e. the standard deviation of the model), which is constant in a typical regression. In contrast, the Poisson distribution has no such parameter, and in fact the variance increases with the mean (i.e. the variance and the mean have the same value). In this latter case, for an expected value of E(y) = 5, we also expect that the variance of observed data points is 5. But what if it is not? What if the observed variance is much higher, i.e. if the data are overdispersed? (Note that it could also be lower, underdispersed. This is less often the case, and not all approaches below allow for modelling underdispersion, but some do.) Overdispersion arises in different ways, most commonly through “clumping”. Imagine the number of seedlings in a forest plot. Depending on the distance to the source tree, there may be many (hundreds) or none. The same goes for shooting stars: either the sky is empty, or littered with shooting stars. -

Poisson Versus Negative Binomial Regression
Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Poisson versus Negative Binomial Regression Randall Reese Utah State University [email protected] February 29, 2016 Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution Other Applications and Analysis in R References Overview 1 Handling Count Data ADEM Overdispersion 2 The Negative Binomial Distribution Foundations of Negative Binomial Distribution Basic Properties of the Negative Binomial Distribution Fitting the Negative Binomial Model 3 Other Applications and Analysis in R 4 References Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Count Data Data whose values come from Z≥0, the non-negative integers. Classic example is deaths in the Prussian army per year by horse kick (Bortkiewicz) Example 2 of Notes 5. (Number of successful \attempts"). Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Poisson Distribution Support is the non-negative integers. (Count data). Described by a single parameter λ > 0. When Y ∼ Poisson(λ), then E(Y ) = Var(Y ) = λ Randall Reese Poisson and Neg. Binom Handling Count Data The Negative Binomial Distribution ADEM Other Applications and Analysis in R Overdispersion References Acute Disseminated Encephalomyelitis Acute Disseminated Encephalomyelitis (ADEM) is a neurological, immune disorder in which widespread inflammation of the brain and spinal cord damages tissue known as white matter. -
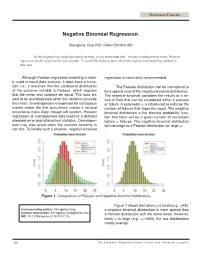
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Logistic Regression Maths and Statistics Help Centre
Logistic regression Maths and Statistics Help Centre Many statistical tests require the dependent (response) variable to be continuous so a different set of tests are needed when the dependent variable is categorical. One of the most commonly used tests for categorical variables is the Chi-squared test which looks at whether or not there is a relationship between two categorical variables but this doesn’t make an allowance for the potential influence of other explanatory variables on that relationship. For continuous outcome variables, Multiple regression can be used for a) controlling for other explanatory variables when assessing relationships between a dependent variable and several independent variables b) predicting outcomes of a dependent variable using a linear combination of explanatory (independent) variables The maths: For multiple regression a model of the following form can be used to predict the value of a response variable y using the values of a number of explanatory variables: y 0 1x1 2 x2 ..... q xq 0 Constant/ intercept , 1 q co efficients for q explanatory variables x1 xq The regression process finds the co-efficients which minimise the squared differences between the observed and expected values of y (the residuals). As the outcome of logistic regression is binary, y needs to be transformed so that the regression process can be used. The logit transformation gives the following: p ln 0 1x1 2 x2 ..... q xq 1 p p p probabilty of event occuring e.g. person dies following heart attack, odds ratio 1- p If probabilities of the event of interest happening for individuals are needed, the logistic regression equation exp x x .... -

Generalized Linear Models
CHAPTER 6 Generalized linear models 6.1 Introduction Generalized linear modeling is a framework for statistical analysis that includes linear and logistic regression as special cases. Linear regression directly predicts continuous data y from a linear predictor Xβ = β0 + X1β1 + + Xkβk.Logistic regression predicts Pr(y =1)forbinarydatafromalinearpredictorwithaninverse-··· logit transformation. A generalized linear model involves: 1. A data vector y =(y1,...,yn) 2. Predictors X and coefficients β,formingalinearpredictorXβ 1 3. A link function g,yieldingavectoroftransformeddataˆy = g− (Xβ)thatare used to model the data 4. A data distribution, p(y yˆ) | 5. Possibly other parameters, such as variances, overdispersions, and cutpoints, involved in the predictors, link function, and data distribution. The options in a generalized linear model are the transformation g and the data distribution p. In linear regression,thetransformationistheidentity(thatis,g(u) u)and • the data distribution is normal, with standard deviation σ estimated from≡ data. 1 1 In logistic regression,thetransformationistheinverse-logit,g− (u)=logit− (u) • (see Figure 5.2a on page 80) and the data distribution is defined by the proba- bility for binary data: Pr(y =1)=y ˆ. This chapter discusses several other classes of generalized linear model, which we list here for convenience: The Poisson model (Section 6.2) is used for count data; that is, where each • data point yi can equal 0, 1, 2, ....Theusualtransformationg used here is the logarithmic, so that g(u)=exp(u)transformsacontinuouslinearpredictorXiβ to a positivey ˆi.ThedatadistributionisPoisson. It is usually a good idea to add a parameter to this model to capture overdis- persion,thatis,variationinthedatabeyondwhatwouldbepredictedfromthe Poisson distribution alone. -

Modeling Overdispersion with the Normalized Tempered Stable Distribution
Modeling overdispersion with the normalized tempered stable distribution M. Kolossiatisa, J.E. Griffinb, M. F. J. Steel∗,c aDepartment of Hotel and Tourism Management, Cyprus University of Technology, P.O. Box 50329, 3603 Limassol, Cyprus. bInstitute of Mathematics, Statistics and Actuarial Science, University of Kent, Canterbury, CT2 7NF, U.K. cDepartment of Statistics, University of Warwick, Coventry, CV4 7AL, U.K. Abstract A multivariate distribution which generalizes the Dirichlet distribution is intro- duced and its use for modeling overdispersion in count data is discussed. The distribution is constructed by normalizing a vector of independent tempered sta- ble random variables. General formulae for all moments and cross-moments of the distribution are derived and they are found to have similar forms to those for the Dirichlet distribution. The univariate version of the distribution can be used as a mixing distribution for the success probability of a binomial distribution to define an alternative to the well-studied beta-binomial distribution. Examples of fitting this model to simulated and real data are presented. Keywords: Distribution on the unit simplex; Mice fetal mortality; Mixed bino- mial; Normalized random measure; Overdispersion 1. Introduction In many experiments we observe data as the number of observations in a sam- ple with some property. The binomial distribution is a natural model for this type of data. However, the data are often found to be overdispersed relative to that ∗Corresponding author. Tel.: +44-2476-523369; fax: +44-2476-524532 Email addresses: [email protected] (M. Kolossiatis), [email protected] (J.E. Griffin), [email protected] (M. -

An Introduction to Logistic Regression: from Basic Concepts to Interpretation with Particular Attention to Nursing Domain
J Korean Acad Nurs Vol.43 No.2, 154 -164 J Korean Acad Nurs Vol.43 No.2 April 2013 http://dx.doi.org/10.4040/jkan.2013.43.2.154 An Introduction to Logistic Regression: From Basic Concepts to Interpretation with Particular Attention to Nursing Domain Park, Hyeoun-Ae College of Nursing and System Biomedical Informatics National Core Research Center, Seoul National University, Seoul, Korea Purpose: The purpose of this article is twofold: 1) introducing logistic regression (LR), a multivariable method for modeling the relationship between multiple independent variables and a categorical dependent variable, and 2) examining use and reporting of LR in the nursing literature. Methods: Text books on LR and research articles employing LR as main statistical analysis were reviewed. Twenty-three articles published between 2010 and 2011 in the Journal of Korean Academy of Nursing were analyzed for proper use and reporting of LR models. Results: Logistic regression from basic concepts such as odds, odds ratio, logit transformation and logistic curve, assumption, fitting, reporting and interpreting to cautions were presented. Substantial short- comings were found in both use of LR and reporting of results. For many studies, sample size was not sufficiently large to call into question the accuracy of the regression model. Additionally, only one study reported validation analysis. Conclusion: Nurs- ing researchers need to pay greater attention to guidelines concerning the use and reporting of LR models. Key words: Logit function, Maximum likelihood estimation, Odds, Odds ratio, Wald test INTRODUCTION The model serves two purposes: (1) it can predict the value of the depen- dent variable for new values of the independent variables, and (2) it can Multivariable methods of statistical analysis commonly appear in help describe the relative contribution of each independent variable to general health science literature (Bagley, White, & Golomb, 2001). -

Randomization Does Not Justify Logistic Regression
Statistical Science 2008, Vol. 23, No. 2, 237–249 DOI: 10.1214/08-STS262 c Institute of Mathematical Statistics, 2008 Randomization Does Not Justify Logistic Regression David A. Freedman Abstract. The logit model is often used to analyze experimental data. However, randomization does not justify the model, so the usual esti- mators can be inconsistent. A consistent estimator is proposed. Ney- man’s non-parametric setup is used as a benchmark. In this setup, each subject has two potential responses, one if treated and the other if untreated; only one of the two responses can be observed. Beside the mathematics, there are simulation results, a brief review of the literature, and some recommendations for practice. Key words and phrases: Models, randomization, logistic regression, logit, average predicted probability. 1. INTRODUCTION nπT subjects at random and assign them to the treatment condition. The remaining nπ subjects The logit model is often fitted to experimental C are assigned to a control condition, where π = 1 data. As explained below, randomization does not C π . According to Neyman (1923), each subject has− justify the assumptions behind the model. Thus, the T two responses: Y T if assigned to treatment, and Y C conventional estimator of log odds is difficult to in- i i if assigned to control. The responses are 1 or 0, terpret; an alternative will be suggested. Neyman’s where 1 is “success” and 0 is “failure.” Responses setup is used to define parameters and prove re- are fixed, that is, not random. sults. (Grammatical niceties apart, the terms “logit If i is assigned to treatment (T ), then Y T is ob- model” and “logistic regression” are used interchange- i served. -

Chapter 19: Logistic Regression
DISCOVERING STATISTICS USING SPSS Chapter 19: Logistic regression Smart Alex’s Solutions Task 1 A ‘display rule’ refers to displaying an appropriate emotion in a given situation. For example, if you receive a Christmas present that you don’t like, the appropriate emotional display is to smile politely and say ‘Thank you Why did you buy me this Auntie Kate, I’ve always wanted a rotting cabbage’. The crappy statistics textbook for Christmas, Auntie Kate? inappropriate emotional display is to start crying and scream ‘Why did you buy me a rotting cabbage, you selfish old bag?’ A psychologist measured children’s understanding of display rules (with a task that they could either pass or fail), their age (months), and their ability to understand others’ mental states (‘theory of mind’, measured with a false-belief task that they could pass or fail). The data are in Display.sav. Can display rule understanding (did the child pass the test: yes/no?) be predicted from the theory of mind (did the child pass the false-belief task: yes/no?), age and their interaction? The main analysis To carry out logistic regression, the data must be entered as for normal regression: they are arranged in the data editor in three columns (one representing each variable). Open the file Display.sav. Looking at the data editor, you should notice that both of the categorical variables have been entered as coding variables; that is, numbers have been specified to represent categories. For ease of interpretation, the outcome variable should be coded 1 (event occurred) and 0 (event did not occur); in this case, 1 represents having display rule understanding, and 0 represents an absence of display rule understanding. -

An Introduction to Biostatistics: Part 2
An introduction to biostatistics: part 2 Cavan Reilly September 4, 2019 Table of contents Statistical models Maximum likelihood estimation Linear models Multiple regression Confounding Statistical adjustments Contrasts Interactions Generalized linear models Logistic regression Model selection Statistical models Statistical models can be powerful tools for understanding complex relationships among variables. We will first suppose that we observe 2 continuous variables. Typically we would start out by looking at a scatterplot: so let's look at an example. Let's read in some data from the genetic association study we looked at in the previous lecture: fms=read.delim("http://www.biostat.umn.edu/~cavanr/FMS_data.txt") Statistical models Then we can just use the plot command as follows. > pdf("wght-hght.pdf") > plot(fms$Pre.height,fms$Pre.weight,xlab="Height",ylab="Weight") > dev.off() It looks like the 2 variables increase together, but we clearly don't have an equation like: Weight = β0 + β1Height; for 2 constants β0 and β1. Note: we look at the distribution of the response variable conditional on the explanatory variable. Correlation A commonly used measure of the extent to which 2 continuous variables have a linear association is the correlation coefficient. The cor function in R allows one to compute this summary. If it is positive then large values of one variable are generally associated with large values of the other. If it is negative then large values of one variables are associated with small values of the other. If the absolute value of the correlation coefficient exceeds 0.7 then there is a strong association, if less than 0.3 then weak, otherwise moderate.