Measures of Fit for Logistic Regression Paul D
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Goodness of Fit: What Do We Really Want to Know? I
PHYSTAT2003, SLAC, Stanford, California, September 8-11, 2003 Goodness of Fit: What Do We Really Want to Know? I. Narsky California Institute of Technology, Pasadena, CA 91125, USA Definitions of the goodness-of-fit problem are discussed. A new method for estimation of the goodness of fit using distance to nearest neighbor is described. Performance of several goodness-of-fit methods is studied for time-dependent CP asymmetry measurements of sin(2β). 1. INTRODUCTION of the test is then defined as the probability of ac- cepting the null hypothesis given it is true, and the The goodness-of-fit problem has recently attracted power of the test, 1 − αII , is defined as the probabil- attention from the particle physics community. In ity of rejecting the null hypothesis given the alterna- modern particle experiments, one often performs an tive is true. Above, αI and αII denote Type I and unbinned likelihood fit to data. The experimenter Type II errors, respectively. An ideal hypothesis test then needs to estimate how accurately the fit function is uniformly most powerful (UMP) because it gives approximates the observed distribution. A number of the highest power among all possible tests at the fixed methods have been used to solve this problem in the confidence level. In most realistic problems, it is not past [1], and a number of methods have been recently possible to find a UMP test and one has to consider proposed [2, 3] in the physics literature. various tests with acceptable power functions. For binned data, one typically applies a χ2 statistic There is a long-standing controversy about the con- to estimate the fit quality. -

On Assessing Binary Regression Models Based on Ungrouped Data
Biometrics 000, 1{18 DOI: 000 000 0000 On Assessing Binary Regression Models Based on Ungrouped Data Chunling Lu Division of Global Health, Brigham and Women's Hospital & Department of Global Health and Social Medicine Harvard University, Boston, U.S. email: chunling [email protected] and Yuhong Yang School of Statistics, University of Minnesota, Minnesota, U.S. email: [email protected] Summary: Assessing a binary regression model based on ungrouped data is a commonly encountered but very challenging problem. Although tests, such as Hosmer-Lemeshow test and le Cessie-van Houwelingen test, have been devised and widely used in applications, they often have low power in detecting lack of fit and not much theoretical justification has been made on when they can work well. In this paper, we propose a new approach based on a cross validation voting system to address the problem. In addition to a theoretical guarantee that the probabilities of type I and II errors both converge to zero as the sample size increases for the new method under proper conditions, our simulation results demonstrate that it performs very well. Key words: Goodness of fit; Hosmer-Lemeshow test; Model assessment; Model selection diagnostics. This paper has been submitted for consideration for publication in Biometrics Goodness of Fit for Ungrouped Data 1 1. Introduction 1.1 Motivation Parametric binary regression is one of the most widely used statistical tools in real appli- cations. A central component in parametric regression is assessment of a candidate model before accepting it as a satisfactory description of the data. In that regard, goodness of fit tests are needed to reveal significant lack-of-fit of the model to assess (MTA), if any. -

Linear Regression: Goodness of Fit and Model Selection
Linear Regression: Goodness of Fit and Model Selection 1 Goodness of Fit I Goodness of fit measures for linear regression are attempts to understand how well a model fits a given set of data. I Models almost never describe the process that generated a dataset exactly I Models approximate reality I However, even models that approximate reality can be used to draw useful inferences or to prediction future observations I ’All Models are wrong, but some are useful’ - George Box 2 Goodness of Fit I We have seen how to check the modelling assumptions of linear regression: I checking the linearity assumption I checking for outliers I checking the normality assumption I checking the distribution of the residuals does not depend on the predictors I These are essential qualitative checks of goodness of fit 3 Sample Size I When making visual checks of data for goodness of fit is important to consider sample size I From a multiple regression model with 2 predictors: I On the left is a histogram of the residuals I On the right is residual vs predictor plot for each of the two predictors 4 Sample Size I The histogram doesn’t look normal but there are only 20 datapoint I We should not expect a better visual fit I Inferences from the linear model should be valid 5 Outliers I Often (particularly when a large dataset is large): I the majority of the residuals will satisfy the model checking assumption I a small number of residuals will violate the normality assumption: they will be very big or very small I Outliers are often generated by a process distinct from those which we are primarily interested in. -

Statistical Approaches for Highly Skewed Data 1
Running head: STATISTICAL APPROACHES FOR HIGHLY SKEWED DATA 1 (in press) Journal of Clinical Child and Adolescent Psychology Statistical Approaches for Highly Skewed Data: Evaluating Relations between Child Maltreatment and Young Adults’ Non-Suicidal Self-injury Ana Gonzalez-Blanks, PhD Jessie M. Bridgewater, MA *Tuppett M. Yates, PhD Department of Psychology University of California, Riverside Acknowledgments: We gratefully acknowledge Dr. Chandra Reynolds who provided generous instruction and consultation throughout the execution of the analyses reported herein. *Please address correspondence to: Tuppett M. Yates, Department of Psychology, University of California, Riverside CA, 92521. Email: [email protected]. STATISTICAL APPROACHES FOR HIGHLY SKEWED DATA 2 Abstract Objective: Clinical phenomena often feature skewed distributions with an overabundance of zeros. Unfortunately, empirical methods for dealing with this violation of distributional assumptions underlying regression are typically discussed in statistical journals with limited translation to applied researchers. Therefore, this investigation compared statistical approaches for addressing highly skewed data as applied to the evaluation of relations between child maltreatment and non-suicidal self-injury (NSSI). Method: College students (N = 2,651; 64.2% female; 85.2% non-White) completed the Child Abuse and Trauma Scale and the Functional Assessment of Self-Mutilation. Statistical models were applied to cross-sectional data to provide illustrative comparisons across predictions to a) raw, highly skewed NSSI outcomes, b) natural log, square-root, and inverse NSSI transformations to reduce skew, c) zero-inflated Poisson (ZIP) and negative-binomial zero- inflated (NBZI) regression models to account for both disproportionate zeros and skewness in the NSSI data, and d) the skew-t distribution to model NSSI skewness. -

Negative Binomial Regression Models and Estimation Methods
Appendix D: Negative Binomial Regression Models and Estimation Methods By Dominique Lord Texas A&M University Byung-Jung Park Korea Transport Institute This appendix presents the characteristics of Negative Binomial regression models and discusses their estimating methods. Probability Density and Likelihood Functions The properties of the negative binomial models with and without spatial intersection are described in the next two sections. Poisson-Gamma Model The Poisson-Gamma model has properties that are very similar to the Poisson model discussed in Appendix C, in which the dependent variable yi is modeled as a Poisson variable with a mean i where the model error is assumed to follow a Gamma distribution. As it names implies, the Poisson-Gamma is a mixture of two distributions and was first derived by Greenwood and Yule (1920). This mixture distribution was developed to account for over-dispersion that is commonly observed in discrete or count data (Lord et al., 2005). It became very popular because the conjugate distribution (same family of functions) has a closed form and leads to the negative binomial distribution. As discussed by Cook (2009), “the name of this distribution comes from applying the binomial theorem with a negative exponent.” There are two major parameterizations that have been proposed and they are known as the NB1 and NB2, the latter one being the most commonly known and utilized. NB2 is therefore described first. Other parameterizations exist, but are not discussed here (see Maher and Summersgill, 1996; Hilbe, 2007). NB2 Model Suppose that we have a series of random counts that follows the Poisson distribution: i e i gyii; (D-1) yi ! where yi is the observed number of counts for i 1, 2, n ; and i is the mean of the Poisson distribution. -

A Weakly Informative Default Prior Distribution for Logistic and Other
The Annals of Applied Statistics 2008, Vol. 2, No. 4, 1360–1383 DOI: 10.1214/08-AOAS191 c Institute of Mathematical Statistics, 2008 A WEAKLY INFORMATIVE DEFAULT PRIOR DISTRIBUTION FOR LOGISTIC AND OTHER REGRESSION MODELS By Andrew Gelman, Aleks Jakulin, Maria Grazia Pittau and Yu-Sung Su Columbia University, Columbia University, University of Rome, and City University of New York We propose a new prior distribution for classical (nonhierarchi- cal) logistic regression models, constructed by first scaling all nonbi- nary variables to have mean 0 and standard deviation 0.5, and then placing independent Student-t prior distributions on the coefficients. As a default choice, we recommend the Cauchy distribution with cen- ter 0 and scale 2.5, which in the simplest setting is a longer-tailed version of the distribution attained by assuming one-half additional success and one-half additional failure in a logistic regression. Cross- validation on a corpus of datasets shows the Cauchy class of prior dis- tributions to outperform existing implementations of Gaussian and Laplace priors. We recommend this prior distribution as a default choice for rou- tine applied use. It has the advantage of always giving answers, even when there is complete separation in logistic regression (a common problem, even when the sample size is large and the number of pre- dictors is small), and also automatically applying more shrinkage to higher-order interactions. This can be useful in routine data analy- sis as well as in automated procedures such as chained equations for missing-data imputation. We implement a procedure to fit generalized linear models in R with the Student-t prior distribution by incorporating an approxi- mate EM algorithm into the usual iteratively weighted least squares. -

Chapter 2 Simple Linear Regression Analysis the Simple
Chapter 2 Simple Linear Regression Analysis The simple linear regression model We consider the modelling between the dependent and one independent variable. When there is only one independent variable in the linear regression model, the model is generally termed as a simple linear regression model. When there are more than one independent variables in the model, then the linear model is termed as the multiple linear regression model. The linear model Consider a simple linear regression model yX01 where y is termed as the dependent or study variable and X is termed as the independent or explanatory variable. The terms 0 and 1 are the parameters of the model. The parameter 0 is termed as an intercept term, and the parameter 1 is termed as the slope parameter. These parameters are usually called as regression coefficients. The unobservable error component accounts for the failure of data to lie on the straight line and represents the difference between the true and observed realization of y . There can be several reasons for such difference, e.g., the effect of all deleted variables in the model, variables may be qualitative, inherent randomness in the observations etc. We assume that is observed as independent and identically distributed random variable with mean zero and constant variance 2 . Later, we will additionally assume that is normally distributed. The independent variables are viewed as controlled by the experimenter, so it is considered as non-stochastic whereas y is viewed as a random variable with Ey()01 X and Var() y 2 . Sometimes X can also be a random variable. -

A Study of Some Issues of Goodness-Of-Fit Tests for Logistic Regression Wei Ma
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2018 A Study of Some Issues of Goodness-of-Fit Tests for Logistic Regression Wei Ma Follow this and additional works at the DigiNole: FSU's Digital Repository. For more information, please contact [email protected] FLORIDA STATE UNIVERSITY COLLEGE OF ARTS AND SCIENCES A STUDY OF SOME ISSUES OF GOODNESS-OF-FIT TESTS FOR LOGISTIC REGRESSION By WEI MA A Dissertation submitted to the Department of Statistics in partial fulfillment of the requirements for the degree of Doctor of Philosophy 2018 Copyright c 2018 Wei Ma. All Rights Reserved. Wei Ma defended this dissertation on July 17, 2018. The members of the supervisory committee were: Dan McGee Professor Co-Directing Dissertation Qing Mai Professor Co-Directing Dissertation Cathy Levenson University Representative Xufeng Niu Committee Member The Graduate School has verified and approved the above-named committee members, and certifies that the dissertation has been approved in accordance with university requirements. ii ACKNOWLEDGMENTS First of all, I would like to express my sincere gratitude to my advisors, Dr. Dan McGee and Dr. Qing Mai, for their encouragement, continuous support of my PhD study, patient guidance. I could not have completed this dissertation without their help and immense knowledge. I have been extremely lucky to have them as my advisors. I would also like to thank the rest of my committee members: Dr. Cathy Levenson and Dr. Xufeng Niu for their support, comments and help for my thesis. I would like to thank all the staffs and graduate students in my department. -

Testing Goodness Of
Dr. Wolfgang Rolke University of Puerto Rico - Mayaguez CERN Phystat Seminar 1 Problem statement Hypothesis testing Chi-square Methods based on empirical distribution function Other tests Power studies Running several tests Tests for multi-dimensional data 2 ➢ We have a probability model ➢ We have data from an experiment ➢ Does the data agree with the probability model? 3 Good Model? Or maybe needs more? 4 F: cumulative distribution function 퐻0: 퐹 = 퐹0 Usually more useful: 퐻0: 퐹 ∊ ℱ0 ℱ0 a family of distributions, indexed by parameters. 5 Type I error: reject true null hypothesis Type II error: fail to reject false null hypothesis A: HT has to have a true type I error probability no higher than the nominal one (α) B: probability of committing the type II error (β) should be as low as possible (subject to A) Historically A was achieved either by finding an exact test or having a large enough sample. p value = probability to reject true null hypothesis when repeating the experiment and observing value of test statistic or something even less likely. If method works p-value has uniform distribution. 6 Note above: no alternative hypothesis 퐻1 Different problem: 퐻0: 퐹 = 푓푙푎푡 vs 퐻0: 퐹 = 푙푖푛푒푎푟 → model selection Usually better tests: likelihood ratio test, F tests, BIC etc. Easy to confuse: all GOF papers do power studies, those need specific alternative. Our question: is F a good enough model for data? We want to guard against any alternative. 7 Not again … Actually no, GOF equally important to both (everybody has a likelihood) Maybe more so for Bayesians, no non- parametric methods. -
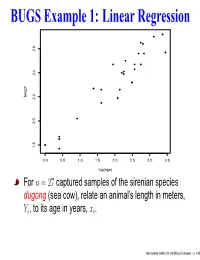
BUGS Example 1: Linear Regression Length 1.8 2.0 2.2 2.4 2.6
BUGS Example 1: Linear Regression length 1.8 2.0 2.2 2.4 2.6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 log(age) For n = 27 captured samples of the sirenian species dugong (sea cow), relate an animal’s length in meters, Yi, to its age in years, xi. Intermediate WinBUGS and BRugs Examples – p. 1/35 BUGS Example 1: Linear Regression length 1.8 2.0 2.2 2.4 2.6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 log(age) For n = 27 captured samples of the sirenian species dugong (sea cow), relate an animal’s length in meters, Yi, to its age in years, xi. To avoid a nonlinear model for now, transform xi to the log scale; plot of Y versus log(x) looks fairly linear! Intermediate WinBUGS and BRugs Examples – p. 1/35 Simple linear regression in WinBUGS Yi = β0 + β1 log(xi) + ǫi, i = 1,...,n iid where ǫ N(0,τ) and τ = 1/σ2, the precision in the data. i ∼ Prior distributions: flat for β0, β1 vague gamma on τ (say, Gamma(0.1, 0.1), which has mean 1 and variance 10) is traditional Intermediate WinBUGS and BRugs Examples – p. 2/35 Simple linear regression in WinBUGS Yi = β0 + β1 log(xi) + ǫi, i = 1,...,n iid where ǫ N(0,τ) and τ = 1/σ2, the precision in the data. i ∼ Prior distributions: flat for β0, β1 vague gamma on τ (say, Gamma(0.1, 0.1), which has mean 1 and variance 10) is traditional posterior correlation is reduced by centering the log(xi) around their own mean Intermediate WinBUGS and BRugs Examples – p. -

Goodness of Fit of a Straight Line to Data
5. A linear trend. 10.4 The Least Squares Regression Line LEARNING OBJECTIVES 1. To learn how to measure how well a straight line fits a collection of data. 2. To learn how to construct the least squares regression line, the straight line that best fits a collection of data. 3. To learn the meaning of the slope of the least squares regression line. 4. To learn how to use the least squares regression line to estimate the response variable y in terms of the predictor variablex. Goodness of Fit of a Straight Line to Data Once the scatter diagram of the data has been drawn and the model assumptions described in the previous sections at least visually verified (and perhaps the correlation coefficient r computed to quantitatively verify the linear trend), the next step in the analysis is to find the straight line that best fits the data. We will explain how to measure how well a straight line fits a collection of points by examining how well the line y=12x−1 fits the data set Saylor URL: http://www.saylor.org/books Saylor.org 503 To each point in the data set there is associated an “error,” the positive or negative vertical distance from the point to the line: positive if the point is above the line and negative if it is below theline. The error can be computed as the actual y-value of the point minus the y-value yˆ that is “predicted” by inserting the x-value of the data point into the formula for the line: error at data point (x,y)=(true y)−(predicted y)=y−yˆ The computation of the error for each of the five points in the data set is shown in Table 10.1 "The Errors in Fitting Data with a Straight Line". -
Using Minitab to Run a Goodness‐Of‐Fit Test 1. Enter the Values of A
Using Minitab to run a Goodness‐of‐fit Test 1. Enter the values of a qualitative variable under C1. 2. Click on “Stat”, choose “Tables” and then “Chi‐square Goodness of Fit Test (One Variable)”. 3. Click on the circle next to “Categorical data:” and enter C1 in the box to the right. 4. Under “Tests”, click on the circle next to “Equal proportions”. 5. Click on the “Graphs” button and uncheck the boxes next to both types of bar chart. 6. Click on “OK” in that window and on “OK” in the next window. The test results will appear in the “Sessions” window under the heading “Chi‐square Goodness of Fit Test for Categorical Variable: … ”. The test statistic will appear under “Chi‐Sq”. The P‐value will appear under “P‐value”. Example (Navidi & Monk, Elementary Statistics, 2nd edition, #23 p.566): The significance level is 0.01. Since 1 – 0.01 = 0.99, the confidence is 99%. The null hypothesis is that all months are equally likely. The alternative is the months are not all equally likely. The data is shown in the table below. Month Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Alarms 32 15 37 38 45 48 46 42 34 36 28 26 Open Minitab and enter the alarms values under C1. A portion of the entered data is shown below. ↓ C1 C2 Alarms 1 32 2 15 3 37 4 38 5 45 6 48 7 46 8 42 9 34 10 36 Now click on “Stat” and then choose “Tables” and “Chi‐Square Goodness‐of‐Fit Test (One Variable) …”.