A Weakly Informative Default Prior Distribution for Logistic and Other
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On Assessing Binary Regression Models Based on Ungrouped Data
Biometrics 000, 1{18 DOI: 000 000 0000 On Assessing Binary Regression Models Based on Ungrouped Data Chunling Lu Division of Global Health, Brigham and Women's Hospital & Department of Global Health and Social Medicine Harvard University, Boston, U.S. email: chunling [email protected] and Yuhong Yang School of Statistics, University of Minnesota, Minnesota, U.S. email: [email protected] Summary: Assessing a binary regression model based on ungrouped data is a commonly encountered but very challenging problem. Although tests, such as Hosmer-Lemeshow test and le Cessie-van Houwelingen test, have been devised and widely used in applications, they often have low power in detecting lack of fit and not much theoretical justification has been made on when they can work well. In this paper, we propose a new approach based on a cross validation voting system to address the problem. In addition to a theoretical guarantee that the probabilities of type I and II errors both converge to zero as the sample size increases for the new method under proper conditions, our simulation results demonstrate that it performs very well. Key words: Goodness of fit; Hosmer-Lemeshow test; Model assessment; Model selection diagnostics. This paper has been submitted for consideration for publication in Biometrics Goodness of Fit for Ungrouped Data 1 1. Introduction 1.1 Motivation Parametric binary regression is one of the most widely used statistical tools in real appli- cations. A central component in parametric regression is assessment of a candidate model before accepting it as a satisfactory description of the data. In that regard, goodness of fit tests are needed to reveal significant lack-of-fit of the model to assess (MTA), if any. -

Frequency Response and Bode Plots
1 Frequency Response and Bode Plots 1.1 Preliminaries The steady-state sinusoidal frequency-response of a circuit is described by the phasor transfer function Hj( ) . A Bode plot is a graph of the magnitude (in dB) or phase of the transfer function versus frequency. Of course we can easily program the transfer function into a computer to make such plots, and for very complicated transfer functions this may be our only recourse. But in many cases the key features of the plot can be quickly sketched by hand using some simple rules that identify the impact of the poles and zeroes in shaping the frequency response. The advantage of this approach is the insight it provides on how the circuit elements influence the frequency response. This is especially important in the design of frequency-selective circuits. We will first consider how to generate Bode plots for simple poles, and then discuss how to handle the general second-order response. Before doing this, however, it may be helpful to review some properties of transfer functions, the decibel scale, and properties of the log function. Poles, Zeroes, and Stability The s-domain transfer function is always a rational polynomial function of the form Ns() smm as12 a s m asa Hs() K K mm12 10 (1.1) nn12 n Ds() s bsnn12 b s bsb 10 As we have seen already, the polynomials in the numerator and denominator are factored to find the poles and zeroes; these are the values of s that make the numerator or denominator zero. If we write the zeroes as zz123,, zetc., and similarly write the poles as pp123,, p , then Hs( ) can be written in factored form as ()()()s zsz sz Hs() K 12 m (1.2) ()()()s psp12 sp n 1 © Bob York 2009 2 Frequency Response and Bode Plots The pole and zero locations can be real or complex. -

Computational Entropy and Information Leakage∗
Computational Entropy and Information Leakage∗ Benjamin Fuller Leonid Reyzin Boston University fbfuller,[email protected] February 10, 2011 Abstract We investigate how information leakage reduces computational entropy of a random variable X. Recall that HILL and metric computational entropy are parameterized by quality (how distinguishable is X from a variable Z that has true entropy) and quantity (how much true entropy is there in Z). We prove an intuitively natural result: conditioning on an event of probability p reduces the quality of metric entropy by a factor of p and the quantity of metric entropy by log2 1=p (note that this means that the reduction in quantity and quality is the same, because the quantity of entropy is measured on logarithmic scale). Our result improves previous bounds of Dziembowski and Pietrzak (FOCS 2008), where the loss in the quantity of entropy was related to its original quality. The use of metric entropy simplifies the analogous the result of Reingold et. al. (FOCS 2008) for HILL entropy. Further, we simplify dealing with information leakage by investigating conditional metric entropy. We show that, conditioned on leakage of λ bits, metric entropy gets reduced by a factor 2λ in quality and λ in quantity. ∗Most of the results of this paper have been incorporated into [FOR12a] (conference version in [FOR12b]), where they are applied to the problem of building deterministic encryption. This paper contains a more focused exposition of the results on computational entropy, including some results that do not appear in [FOR12a]: namely, Theorem 3.6, Theorem 3.10, proof of Theorem 3.2, and results in Appendix A. -

1 1. Data Transformations
260 Archives ofDisease in Childhood 1993; 69: 260-264 STATISTICS FROM THE INSIDE Arch Dis Child: first published as 10.1136/adc.69.2.260 on 1 August 1993. Downloaded from 1 1. Data transformations M J R Healy Additive and multiplicative effects adding a constant quantity to the correspond- In the statistical analyses for comparing two ing before readings. Exactly the same is true of groups of continuous observations which I the unpaired situation, as when we compare have so far considered, certain assumptions independent samples of treated and control have been made about the data being analysed. patients. Here the assumption is that we can One of these is Normality of distribution; in derive the distribution ofpatient readings from both the paired and the unpaired situation, the that of control readings by shifting the latter mathematical theory underlying the signifi- bodily along the axis, and this again amounts cance probabilities attached to different values to adding a constant amount to each of the of t is based on the assumption that the obser- control variate values (fig 1). vations are drawn from Normal distributions. This is not the only way in which two groups In the unpaired situation, we make the further of readings can be related in practice. Suppose assumption that the distributions in the two I asked you to guess the size of the effect of groups which are being compared have equal some treatment for (say) increasing forced standard deviations - this assumption allows us expiratory volume in one second in asthmatic to simplify the analysis and to gain a certain children. -

Measures of Fit for Logistic Regression Paul D
Paper 1485-2014 SAS Global Forum Measures of Fit for Logistic Regression Paul D. Allison, Statistical Horizons LLC and the University of Pennsylvania ABSTRACT One of the most common questions about logistic regression is “How do I know if my model fits the data?” There are many approaches to answering this question, but they generally fall into two categories: measures of predictive power (like R-square) and goodness of fit tests (like the Pearson chi-square). This presentation looks first at R-square measures, arguing that the optional R-squares reported by PROC LOGISTIC might not be optimal. Measures proposed by McFadden and Tjur appear to be more attractive. As for goodness of fit, the popular Hosmer and Lemeshow test is shown to have some serious problems. Several alternatives are considered. INTRODUCTION One of the most frequent questions I get about logistic regression is “How can I tell if my model fits the data?” Often the questioner is expressing a genuine interest in knowing whether a model is a good model or a not-so-good model. But a more common motivation is to convince someone else--a boss, an editor, or a regulator--that the model is OK. There are two very different approaches to answering this question. One is to get a statistic that measures how well you can predict the dependent variable based on the independent variables. I’ll refer to these kinds of statistics as measures of predictive power. Typically, they vary between 0 and 1, with 0 meaning no predictive power whatsoever and 1 meaning perfect predictions. -
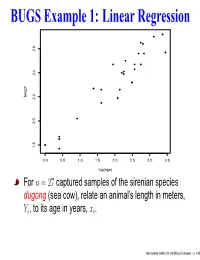
BUGS Example 1: Linear Regression Length 1.8 2.0 2.2 2.4 2.6
BUGS Example 1: Linear Regression length 1.8 2.0 2.2 2.4 2.6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 log(age) For n = 27 captured samples of the sirenian species dugong (sea cow), relate an animal’s length in meters, Yi, to its age in years, xi. Intermediate WinBUGS and BRugs Examples – p. 1/35 BUGS Example 1: Linear Regression length 1.8 2.0 2.2 2.4 2.6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 log(age) For n = 27 captured samples of the sirenian species dugong (sea cow), relate an animal’s length in meters, Yi, to its age in years, xi. To avoid a nonlinear model for now, transform xi to the log scale; plot of Y versus log(x) looks fairly linear! Intermediate WinBUGS and BRugs Examples – p. 1/35 Simple linear regression in WinBUGS Yi = β0 + β1 log(xi) + ǫi, i = 1,...,n iid where ǫ N(0,τ) and τ = 1/σ2, the precision in the data. i ∼ Prior distributions: flat for β0, β1 vague gamma on τ (say, Gamma(0.1, 0.1), which has mean 1 and variance 10) is traditional Intermediate WinBUGS and BRugs Examples – p. 2/35 Simple linear regression in WinBUGS Yi = β0 + β1 log(xi) + ǫi, i = 1,...,n iid where ǫ N(0,τ) and τ = 1/σ2, the precision in the data. i ∼ Prior distributions: flat for β0, β1 vague gamma on τ (say, Gamma(0.1, 0.1), which has mean 1 and variance 10) is traditional posterior correlation is reduced by centering the log(xi) around their own mean Intermediate WinBUGS and BRugs Examples – p. -

C-17Bpages Pdf It
SPECIFICATION DEFINITIONS FOR LOGARITHMIC AMPLIFIERS This application note is presented to engineers who may use logarithmic amplifiers in a variety of system applica- tions. It is intended to help engineers understand logarithmic amplifiers, how to specify them, and how the loga- rithmic amplifiers perform in a system environment. A similar paper addressing the accuracy and error contributing elements in logarithmic amplifiers will follow this application note. INTRODUCTION The need to process high-density pulses with narrow pulse widths and large amplitude variations necessitates the use of logarithmic amplifiers in modern receiving systems. In general, the purpose of this class of amplifier is to condense a large input dynamic range into a much smaller, manageable one through a logarithmic transfer func- tion. As a result of this transfer function, the output voltage swing of a logarithmic amplifier is proportional to the input signal power range in dB. In most cases, logarithmic amplifiers are used as amplitude detectors. Since output voltage (in mV) is proportion- al to the input signal power (in dB), the amplitude information is displayed in a much more usable format than accomplished by so-called linear detectors. LOGARITHMIC TRANSFER FUNCTION INPUT RF POWER VS. DETECTED OUTPUT VOLTAGE 0V 50 MILLIVOLTS/DIV. 250 MILLIVOLTS/DIV. 0V 50.0 ns/DIV. 50.0 ns/DIV. There are three basic types of logarithmic amplifiers. These are: • Detector Log Video Amplifiers • Successive Detection Logarithmic Amplifiers • True Log Amplifiers DETECTOR LOG VIDEO AMPLIFIER (DLVA) is a type of logarithmic amplifier in which the envelope of the input RF signal is detected with a standard "linear" diode detector. -

1D Regression Models Such As Glms
Chapter 4 1D Regression Models Such as GLMs ... estimates of the linear regression coefficients are relevant to the linear parameters of a broader class of models than might have been suspected. Brillinger (1977, p. 509) After computing β,ˆ one may go on to prepare a scatter plot of the points (βxˆ j, yj), j =1,...,n and look for a functional form for g( ). Brillinger (1983, p. 98) · This chapter considers 1D regression models including additive error re- gression (AER), generalized linear models (GLMs), and generalized additive models (GAMs). Multiple linear regression is a special case of these four models. See Definition 1.2 for the 1D regression model, sufficient predictor (SP = h(x)), estimated sufficient predictor (ESP = hˆ(x)), generalized linear model (GLM), and the generalized additive model (GAM). When using a GAM to check a GLM, the notation ESP may be used for the GLM, and EAP (esti- mated additive predictor) may be used for the ESP of the GAM. Definition 1.3 defines the response plot of ESP versus Y . Suppose the sufficient predictor SP = h(x). Often SP = xT β. If u only T T contains the nontrivial predictors, then SP = β1 + u β2 = α + u η is often T T T T T T used where β = (β1, β2 ) = (α, η ) and x = (1, u ) . 4.1 Introduction First we describe some regression models in the following three definitions. The most general model uses SP = h(x) as defined in Definition 1.2. The GAM with SP = AP will be useful for checking the model (often a GLM) with SP = xT β. -

Linear and Logarithmic Scales
Linear and logarithmic scales. Defining Scale You may have thought of a scale as something to weigh yourself with or the outer layer on the bodies of fish and reptiles. For this lesson, we're using a different definition of a scale. A scale, in this sense, is a leveled range of values/numbers from lowest to highest that measures something at regular intervals. A great example is the classic number line that has numbers lined up at consistent intervals along a line. What Is a Linear Scale? A linear scale is much like the number line described above. They key to this type of scale is that the value between two consecutive points on the line does not change no matter how high or low you are on it. For instance, on the number line, the distance between the numbers 0 and 1 is 1 unit. The same distance of one unit is between the numbers 100 and 101, or -100 and -101. However you look at it, the distance between the points is constant (unchanging) regardless of the location on the line. A great way to visualize this is by looking at one of those old school intro to Geometry or mid- level Algebra examples of how to graph a line. One of the properties of a line is that it is the shortest distance between two points. Another is that it is has a constant slope. Having a constant slope means that the change in x and y from one point to another point on the line doesn't change. -

The Indefinite Logarithm, Logarithmic Units, and the Nature of Entropy
The Indefinite Logarithm, Logarithmic Units, and the Nature of Entropy Michael P. Frank FAMU-FSU College of Engineering Dept. of Electrical & Computer Engineering 2525 Pottsdamer St., Rm. 341 Tallahassee, FL 32310 [email protected] August 20, 2017 Abstract We define the indefinite logarithm [log x] of a real number x> 0 to be a mathematical object representing the abstract concept of the logarithm of x with an indeterminate base (i.e., not specifically e, 10, 2, or any fixed number). The resulting indefinite logarithmic quantities naturally play a mathematical role that is closely analogous to that of dimensional physi- cal quantities (such as length) in that, although these quantities have no definite interpretation as ordinary numbers, nevertheless the ratio of two of these entities is naturally well-defined as a specific, ordinary number, just like the ratio of two lengths. As a result, indefinite logarithm objects can serve as the basis for logarithmic spaces, which are natural systems of logarithmic units suitable for measuring any quantity defined on a log- arithmic scale. We illustrate how logarithmic units provide a convenient language for explaining the complete conceptual unification of the dis- parate systems of units that are presently used for a variety of quantities that are conventionally considered distinct, such as, in particular, physical entropy and information-theoretic entropy. 1 Introduction The goal of this paper is to help clear up what is perceived to be a widespread arXiv:physics/0506128v1 [physics.gen-ph] 15 Jun 2005 confusion that can found in many popular sources (websites, popular books, etc.) regarding the proper mathematical status of a variety of physical quantities that are conventionally defined on logarithmic scales. -

The Overlooked Potential of Generalized Linear Models in Astronomy, I: Binomial Regression
Astronomy and Computing 12 (2015) 21–32 Contents lists available at ScienceDirect Astronomy and Computing journal homepage: www.elsevier.com/locate/ascom Full length article The overlooked potential of Generalized Linear Models in astronomy, I: Binomial regression R.S. de Souza a,∗, E. Cameron b, M. Killedar c, J. Hilbe d,e, R. Vilalta f, U. Maio g,h, V. Biffi i, B. Ciardi j, J.D. Riggs k, for the COIN collaboration a MTA Eötvös University, EIRSA ``Lendulet'' Astrophysics Research Group, Budapest 1117, Hungary b Department of Zoology, University of Oxford, Tinbergen Building, South Parks Road, Oxford, OX1 3PS, United Kingdom c Universitäts-Sternwarte München, Scheinerstrasse 1, D-81679, München, Germany d Arizona State University, 873701, Tempe, AZ 85287-3701, USA e Jet Propulsion Laboratory, 4800 Oak Grove Dr., Pasadena, CA 91109, USA f Department of Computer Science, University of Houston, 4800 Calhoun Rd., Houston TX 77204-3010, USA g INAF — Osservatorio Astronomico di Trieste, via G. Tiepolo 11, 34135 Trieste, Italy h Leibniz Institute for Astrophysics, An der Sternwarte 16, 14482 Potsdam, Germany i SISSA — Scuola Internazionale Superiore di Studi Avanzati, Via Bonomea 265, 34136 Trieste, Italy j Max-Planck-Institut für Astrophysik, Karl-Schwarzschild-Str. 1, D-85748 Garching, Germany k Northwestern University, Evanston, IL, 60208, USA article info a b s t r a c t Article history: Revealing hidden patterns in astronomical data is often the path to fundamental scientific breakthroughs; Received 26 September 2014 meanwhile the complexity of scientific enquiry increases as more subtle relationships are sought. Con- Accepted 2 April 2015 temporary data analysis problems often elude the capabilities of classical statistical techniques, suggest- Available online 29 April 2015 ing the use of cutting edge statistical methods. -

Generalized Linear Models I
Statistics 203: Introduction to Regression and Analysis of Variance Generalized Linear Models I Jonathan Taylor - p. 1/18 Today's class ● Today's class ■ Logistic regression. ● Generalized linear models ● Binary regression example ■ ● Binary outcomes Generalized linear models. ● Logit transform ■ ● Binary regression Deviance. ● Link functions: binary regression ● Link function inverses: binary regression ● Odds ratios & logistic regression ● Link & variance fns. of a GLM ● Binary (again) ● Fitting a binary regression GLM: IRLS ● Other common examples of GLMs ● Deviance ● Binary deviance ● Partial deviance tests 2 ● Wald χ tests - p. 2/18 Generalized linear models ● Today's class ■ All models we have seen so far deal with continuous ● Generalized linear models ● Binary regression example outcome variables with no restriction on their expectations, ● Binary outcomes ● Logit transform and (most) have assumed that mean and variance are ● Binary regression ● Link functions: binary unrelated (i.e. variance is constant). regression ● Link function inverses: binary ■ Many outcomes of interest do not satisfy this. regression ● Odds ratios & logistic ■ regression Examples: binary outcomes, Poisson count outcomes. ● Link & variance fns. of a GLM ● Binary (again) ■ A Generalized Linear Model (GLM) is a model with two ● Fitting a binary regression GLM: IRLS ingredients: a link function and a variance function. ● Other common examples of GLMs ◆ The link relates the means of the observations to ● Deviance ● Binary deviance predictors: linearization ● Partial deviance tests 2 ◆ ● Wald χ tests The variance function relates the means to the variances. - p. 3/18 Binary regression example ● Today's class ■ A local health clinic sent fliers to its clients to encourage ● Generalized linear models ● Binary regression example everyone, but especially older persons at high risk of ● Binary outcomes ● Logit transform complications, to get a flu shot in time for protection against ● Binary regression ● Link functions: binary an expected flu epidemic.