The Overlooked Potential of Generalized Linear Models in Astronomy, I: Binomial Regression
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On Assessing Binary Regression Models Based on Ungrouped Data
Biometrics 000, 1{18 DOI: 000 000 0000 On Assessing Binary Regression Models Based on Ungrouped Data Chunling Lu Division of Global Health, Brigham and Women's Hospital & Department of Global Health and Social Medicine Harvard University, Boston, U.S. email: chunling [email protected] and Yuhong Yang School of Statistics, University of Minnesota, Minnesota, U.S. email: [email protected] Summary: Assessing a binary regression model based on ungrouped data is a commonly encountered but very challenging problem. Although tests, such as Hosmer-Lemeshow test and le Cessie-van Houwelingen test, have been devised and widely used in applications, they often have low power in detecting lack of fit and not much theoretical justification has been made on when they can work well. In this paper, we propose a new approach based on a cross validation voting system to address the problem. In addition to a theoretical guarantee that the probabilities of type I and II errors both converge to zero as the sample size increases for the new method under proper conditions, our simulation results demonstrate that it performs very well. Key words: Goodness of fit; Hosmer-Lemeshow test; Model assessment; Model selection diagnostics. This paper has been submitted for consideration for publication in Biometrics Goodness of Fit for Ungrouped Data 1 1. Introduction 1.1 Motivation Parametric binary regression is one of the most widely used statistical tools in real appli- cations. A central component in parametric regression is assessment of a candidate model before accepting it as a satisfactory description of the data. In that regard, goodness of fit tests are needed to reveal significant lack-of-fit of the model to assess (MTA), if any. -

Statistical Approaches for Highly Skewed Data 1
Running head: STATISTICAL APPROACHES FOR HIGHLY SKEWED DATA 1 (in press) Journal of Clinical Child and Adolescent Psychology Statistical Approaches for Highly Skewed Data: Evaluating Relations between Child Maltreatment and Young Adults’ Non-Suicidal Self-injury Ana Gonzalez-Blanks, PhD Jessie M. Bridgewater, MA *Tuppett M. Yates, PhD Department of Psychology University of California, Riverside Acknowledgments: We gratefully acknowledge Dr. Chandra Reynolds who provided generous instruction and consultation throughout the execution of the analyses reported herein. *Please address correspondence to: Tuppett M. Yates, Department of Psychology, University of California, Riverside CA, 92521. Email: [email protected]. STATISTICAL APPROACHES FOR HIGHLY SKEWED DATA 2 Abstract Objective: Clinical phenomena often feature skewed distributions with an overabundance of zeros. Unfortunately, empirical methods for dealing with this violation of distributional assumptions underlying regression are typically discussed in statistical journals with limited translation to applied researchers. Therefore, this investigation compared statistical approaches for addressing highly skewed data as applied to the evaluation of relations between child maltreatment and non-suicidal self-injury (NSSI). Method: College students (N = 2,651; 64.2% female; 85.2% non-White) completed the Child Abuse and Trauma Scale and the Functional Assessment of Self-Mutilation. Statistical models were applied to cross-sectional data to provide illustrative comparisons across predictions to a) raw, highly skewed NSSI outcomes, b) natural log, square-root, and inverse NSSI transformations to reduce skew, c) zero-inflated Poisson (ZIP) and negative-binomial zero- inflated (NBZI) regression models to account for both disproportionate zeros and skewness in the NSSI data, and d) the skew-t distribution to model NSSI skewness. -

Negative Binomial Regression Models and Estimation Methods
Appendix D: Negative Binomial Regression Models and Estimation Methods By Dominique Lord Texas A&M University Byung-Jung Park Korea Transport Institute This appendix presents the characteristics of Negative Binomial regression models and discusses their estimating methods. Probability Density and Likelihood Functions The properties of the negative binomial models with and without spatial intersection are described in the next two sections. Poisson-Gamma Model The Poisson-Gamma model has properties that are very similar to the Poisson model discussed in Appendix C, in which the dependent variable yi is modeled as a Poisson variable with a mean i where the model error is assumed to follow a Gamma distribution. As it names implies, the Poisson-Gamma is a mixture of two distributions and was first derived by Greenwood and Yule (1920). This mixture distribution was developed to account for over-dispersion that is commonly observed in discrete or count data (Lord et al., 2005). It became very popular because the conjugate distribution (same family of functions) has a closed form and leads to the negative binomial distribution. As discussed by Cook (2009), “the name of this distribution comes from applying the binomial theorem with a negative exponent.” There are two major parameterizations that have been proposed and they are known as the NB1 and NB2, the latter one being the most commonly known and utilized. NB2 is therefore described first. Other parameterizations exist, but are not discussed here (see Maher and Summersgill, 1996; Hilbe, 2007). NB2 Model Suppose that we have a series of random counts that follows the Poisson distribution: i e i gyii; (D-1) yi ! where yi is the observed number of counts for i 1, 2, n ; and i is the mean of the Poisson distribution. -

A Weakly Informative Default Prior Distribution for Logistic and Other
The Annals of Applied Statistics 2008, Vol. 2, No. 4, 1360–1383 DOI: 10.1214/08-AOAS191 c Institute of Mathematical Statistics, 2008 A WEAKLY INFORMATIVE DEFAULT PRIOR DISTRIBUTION FOR LOGISTIC AND OTHER REGRESSION MODELS By Andrew Gelman, Aleks Jakulin, Maria Grazia Pittau and Yu-Sung Su Columbia University, Columbia University, University of Rome, and City University of New York We propose a new prior distribution for classical (nonhierarchi- cal) logistic regression models, constructed by first scaling all nonbi- nary variables to have mean 0 and standard deviation 0.5, and then placing independent Student-t prior distributions on the coefficients. As a default choice, we recommend the Cauchy distribution with cen- ter 0 and scale 2.5, which in the simplest setting is a longer-tailed version of the distribution attained by assuming one-half additional success and one-half additional failure in a logistic regression. Cross- validation on a corpus of datasets shows the Cauchy class of prior dis- tributions to outperform existing implementations of Gaussian and Laplace priors. We recommend this prior distribution as a default choice for rou- tine applied use. It has the advantage of always giving answers, even when there is complete separation in logistic regression (a common problem, even when the sample size is large and the number of pre- dictors is small), and also automatically applying more shrinkage to higher-order interactions. This can be useful in routine data analy- sis as well as in automated procedures such as chained equations for missing-data imputation. We implement a procedure to fit generalized linear models in R with the Student-t prior distribution by incorporating an approxi- mate EM algorithm into the usual iteratively weighted least squares. -

Measures of Fit for Logistic Regression Paul D
Paper 1485-2014 SAS Global Forum Measures of Fit for Logistic Regression Paul D. Allison, Statistical Horizons LLC and the University of Pennsylvania ABSTRACT One of the most common questions about logistic regression is “How do I know if my model fits the data?” There are many approaches to answering this question, but they generally fall into two categories: measures of predictive power (like R-square) and goodness of fit tests (like the Pearson chi-square). This presentation looks first at R-square measures, arguing that the optional R-squares reported by PROC LOGISTIC might not be optimal. Measures proposed by McFadden and Tjur appear to be more attractive. As for goodness of fit, the popular Hosmer and Lemeshow test is shown to have some serious problems. Several alternatives are considered. INTRODUCTION One of the most frequent questions I get about logistic regression is “How can I tell if my model fits the data?” Often the questioner is expressing a genuine interest in knowing whether a model is a good model or a not-so-good model. But a more common motivation is to convince someone else--a boss, an editor, or a regulator--that the model is OK. There are two very different approaches to answering this question. One is to get a statistic that measures how well you can predict the dependent variable based on the independent variables. I’ll refer to these kinds of statistics as measures of predictive power. Typically, they vary between 0 and 1, with 0 meaning no predictive power whatsoever and 1 meaning perfect predictions. -
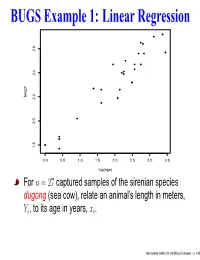
BUGS Example 1: Linear Regression Length 1.8 2.0 2.2 2.4 2.6
BUGS Example 1: Linear Regression length 1.8 2.0 2.2 2.4 2.6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 log(age) For n = 27 captured samples of the sirenian species dugong (sea cow), relate an animal’s length in meters, Yi, to its age in years, xi. Intermediate WinBUGS and BRugs Examples – p. 1/35 BUGS Example 1: Linear Regression length 1.8 2.0 2.2 2.4 2.6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 log(age) For n = 27 captured samples of the sirenian species dugong (sea cow), relate an animal’s length in meters, Yi, to its age in years, xi. To avoid a nonlinear model for now, transform xi to the log scale; plot of Y versus log(x) looks fairly linear! Intermediate WinBUGS and BRugs Examples – p. 1/35 Simple linear regression in WinBUGS Yi = β0 + β1 log(xi) + ǫi, i = 1,...,n iid where ǫ N(0,τ) and τ = 1/σ2, the precision in the data. i ∼ Prior distributions: flat for β0, β1 vague gamma on τ (say, Gamma(0.1, 0.1), which has mean 1 and variance 10) is traditional Intermediate WinBUGS and BRugs Examples – p. 2/35 Simple linear regression in WinBUGS Yi = β0 + β1 log(xi) + ǫi, i = 1,...,n iid where ǫ N(0,τ) and τ = 1/σ2, the precision in the data. i ∼ Prior distributions: flat for β0, β1 vague gamma on τ (say, Gamma(0.1, 0.1), which has mean 1 and variance 10) is traditional posterior correlation is reduced by centering the log(xi) around their own mean Intermediate WinBUGS and BRugs Examples – p. -

Multiple Binomial Regression Models of Learning Style Preferences of Students of Sidhu School, Wilkes University
International Journal of Statistics and Probability; Vol. 7, No. 3; May 2018 ISSN 1927-7032 E-ISSN 1927-7040 Published by Canadian Center of Science and Education Multiple Binomial Regression Models of Learning Style Preferences of Students of Sidhu School, Wilkes University Adekanmbi, D. B1 1 Department of Statistics, Ladoke Akintola University of Technology, Nigeria Correspondence: Adekanmbi, D.B, Department of Statistics, Ladoke Akintola University of Technology, Ogbomoso, Nigeria. Received: November 6, 2017 Accepted: November 27, 2017 Online Published: March 13, 2018 doi:10.5539/ijsp.v7n3p9 URL: https://doi.org/10.5539/ijsp.v7n3p9 Abstract The interest of this study is to explore the relationship between a dichotomous response, learning style preferences by university students of Sidhu School, Wilkes University, as a function of the following predictors: Gender, Age, employment status, cumulative grade point assessment (GPA) and level of study, as in usual generalized linear model. The response variable is the students’ preference for either Behaviorist or Humanist learning style. Four different binomial regression models were fitted to the data. Model A is a logit regression model that fits all the predictors, Model B is a probit model that fits all the predictors, Model C is a logit model with an effect modifier, while Model D is a probit model also with an effect modifier. Models A and B appeared to have performed poorly in fitting the data. Models C and D fit the data well as confirmed by the non-significant chi-square lack of fit with p-values 0.1409 and 0.1408 respectively. Among the four models considered for fitting the data, Model D, the probit model with effect modifier fit best. -

1D Regression Models Such As Glms
Chapter 4 1D Regression Models Such as GLMs ... estimates of the linear regression coefficients are relevant to the linear parameters of a broader class of models than might have been suspected. Brillinger (1977, p. 509) After computing β,ˆ one may go on to prepare a scatter plot of the points (βxˆ j, yj), j =1,...,n and look for a functional form for g( ). Brillinger (1983, p. 98) · This chapter considers 1D regression models including additive error re- gression (AER), generalized linear models (GLMs), and generalized additive models (GAMs). Multiple linear regression is a special case of these four models. See Definition 1.2 for the 1D regression model, sufficient predictor (SP = h(x)), estimated sufficient predictor (ESP = hˆ(x)), generalized linear model (GLM), and the generalized additive model (GAM). When using a GAM to check a GLM, the notation ESP may be used for the GLM, and EAP (esti- mated additive predictor) may be used for the ESP of the GAM. Definition 1.3 defines the response plot of ESP versus Y . Suppose the sufficient predictor SP = h(x). Often SP = xT β. If u only T T contains the nontrivial predictors, then SP = β1 + u β2 = α + u η is often T T T T T T used where β = (β1, β2 ) = (α, η ) and x = (1, u ) . 4.1 Introduction First we describe some regression models in the following three definitions. The most general model uses SP = h(x) as defined in Definition 1.2. The GAM with SP = AP will be useful for checking the model (often a GLM) with SP = xT β. -

Regression Models for Count Data Jason Brinkley, Abt Associates
SESUG Paper SD135-2018 Regression Models for Count Data Jason Brinkley, Abt Associates ABSTRACT Outcomes in the form of counts are becoming an increasingly popular metric in a wide variety of fields. For example, studying the number of hospital, emergency room, or in-patient doctor’s office visits has been a major focal point for many recent health studies. Many investigators want to know the impact of many different variables on these counts and help describe ways in which interventions or therapies might bring those numbers down. Traditional least squares regression was the primary mechanism for studying this type of data for decades. However, alternative methods were developed some time ago that are far superior for dealing with this type of data. The focus of this paper is to illustrate how count regression models can outperform traditional methods while utilizing the data in a more appropriate manner. Poisson Regression and Negative Binomial Regression are popular techniques when the data are overdispersed and using Zero-Inflated techniques for data with many more zeroes than is expected under traditional count regression models. These examples are applied to studies with real data. INTRODUCTION Outcomes in the form of counts are becoming an increasingly popular metric in a wide variety of fields. In the health sciences examples include number of hospitalizations, chronic conditions, medications, and so on. Many investigators want to know the impact of many different variables on these counts and help describe ways in which interventions or therapies might bring those numbers down. Standard methods (regression, t-tests, ANOVA) are useful for some count data studies. -

Generalized Linear Models and Point Count Data: Statistical Considerations for the Design and Analysis of Monitoring Studies
Generalized Linear Models and Point Count Data: Statistical Considerations for the Design and Analysis of Monitoring Studies Nathaniel E. Seavy,1,2,3 Suhel Quader,1,4 John D. Alexander,2 and C. John Ralph5 ________________________________________ Abstract The success of avian monitoring programs to effec- Key words: Generalized linear models, juniper remov- tively guide management decisions requires that stud- al, monitoring, overdispersion, point count, Poisson. ies be efficiently designed and data be properly ana- lyzed. A complicating factor is that point count surveys often generate data with non-normal distributional pro- perties. In this paper we review methods of dealing with deviations from normal assumptions, and we Introduction focus on the application of generalized linear models (GLMs). We also discuss problems associated with Measuring changes in bird abundance over time and in overdispersion (more variation than expected). In order response to habitat management is widely recognized to evaluate the statistical power of these models to as an important aspect of ecological monitoring detect differences in bird abundance, it is necessary for (Greenwood et al. 1993). The use of long-term avian biologists to identify the effect size they believe is monitoring programs (e.g., the Breeding Bird Survey) biologically significant in their system. We illustrate to identify population trends is a powerful tool for bird one solution to this challenge by discussing the design conservation (Sauer and Droege 1990, Sauer and Link of a monitoring program intended to detect changes in 2002). Short-term studies comparing bird abundance in bird abundance as a result of Western juniper (Juniper- treated and untreated areas are also important because us occidentalis) reduction projects in central Oregon. -

Lecture 3 Residual Analysis + Generalized Linear Models
Lecture 3 Residual Analysis + Generalized Linear Models Colin Rundel 1/23/2017 1 Residual Analysis 2 Atmospheric CO2 (ppm) from Mauna Loa 360 co2 350 1988 1992 1996 date 3 360 co2 350 1988 1992 1996 date 2.5 0.0 resid −2.5 1988 1992 1996 date Where to start? Well, it looks like stuff is going up on average … 4 360 co2 350 1988 1992 1996 date 2.5 0.0 resid −2.5 1988 1992 1996 date Where to start? Well, it looks like stuff is going up on average … 4 2.5 0.0 resid −2.5 1988 1992 1996 date 1.0 0.5 0.0 resid2 −0.5 −1.0 1988 1992 1996 date and then? Well there is some periodicity lets add the month … 5 2.5 0.0 resid −2.5 1988 1992 1996 date 1.0 0.5 0.0 resid2 −0.5 −1.0 1988 1992 1996 date and then? Well there is some periodicity lets add the month … 5 1.0 0.5 0.0 resid2 −0.5 −1.0 1988 1992 1996 date 0.8 0.4 0.0 resid3 −0.4 −0.8 1988 1992 1996 date and then and then? Maybe there is some different effect by year … 6 1.0 0.5 0.0 resid2 −0.5 −1.0 1988 1992 1996 date 0.8 0.4 0.0 resid3 −0.4 −0.8 1988 1992 1996 date and then and then? Maybe there is some different effect by year … 6 Too much (lm = lm(co2~date + month + as.factor(year), data=co2_df)) ## ## Call: ## lm(formula = co2 ~ date + month + as.factor(year), data = co2_df) ## ## Coefficients: ## (Intercept) date monthAug ## -2.645e+03 1.508e+00 -4.177e+00 ## monthDec monthFeb monthJan ## -3.612e+00 -2.008e+00 -2.705e+00 ## monthJul monthJun monthMar ## -2.035e+00 -3.251e-01 -1.227e+00 ## monthMay monthNov monthOct ## 4.821e-01 -4.838e+00 -6.135e+00 ## monthSep as.factor(year)1986 as.factor(year)1987 ## -6.064e+00 -2.585e-01 9.722e-03 ## as.factor(year)1988 as.factor(year)1989 as.factor(year)1990 ## 1.065e+00 9.978e-01 7.726e-01 ## as.factor(year)1991 as.factor(year)1992 as.factor(year)1993 ## 7.067e-01 1.236e-02 -7.911e-01 ## as.factor(year)1994 as.factor(year)1995 as.factor(year)1996 ## -4.146e-01 1.119e-01 3.768e-01 ## as.factor(year)1997 7 ## NA 360 co2 350 1988 1992 1996 date 8 Generalized Linear Models 9 Background A generalized linear model has three key components: 1. -

Generalized Linear Models I
Statistics 203: Introduction to Regression and Analysis of Variance Generalized Linear Models I Jonathan Taylor - p. 1/18 Today's class ● Today's class ■ Logistic regression. ● Generalized linear models ● Binary regression example ■ ● Binary outcomes Generalized linear models. ● Logit transform ■ ● Binary regression Deviance. ● Link functions: binary regression ● Link function inverses: binary regression ● Odds ratios & logistic regression ● Link & variance fns. of a GLM ● Binary (again) ● Fitting a binary regression GLM: IRLS ● Other common examples of GLMs ● Deviance ● Binary deviance ● Partial deviance tests 2 ● Wald χ tests - p. 2/18 Generalized linear models ● Today's class ■ All models we have seen so far deal with continuous ● Generalized linear models ● Binary regression example outcome variables with no restriction on their expectations, ● Binary outcomes ● Logit transform and (most) have assumed that mean and variance are ● Binary regression ● Link functions: binary unrelated (i.e. variance is constant). regression ● Link function inverses: binary ■ Many outcomes of interest do not satisfy this. regression ● Odds ratios & logistic ■ regression Examples: binary outcomes, Poisson count outcomes. ● Link & variance fns. of a GLM ● Binary (again) ■ A Generalized Linear Model (GLM) is a model with two ● Fitting a binary regression GLM: IRLS ingredients: a link function and a variance function. ● Other common examples of GLMs ◆ The link relates the means of the observations to ● Deviance ● Binary deviance predictors: linearization ● Partial deviance tests 2 ◆ ● Wald χ tests The variance function relates the means to the variances. - p. 3/18 Binary regression example ● Today's class ■ A local health clinic sent fliers to its clients to encourage ● Generalized linear models ● Binary regression example everyone, but especially older persons at high risk of ● Binary outcomes ● Logit transform complications, to get a flu shot in time for protection against ● Binary regression ● Link functions: binary an expected flu epidemic.