Mastering the Game of Go Without Human Knowledge
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

W2go4e-Book.Pdf
American Go Association The AGA is dedicated to promotion of the game of go in America. It works to encourage people to learn more about and enjoy this remarkable game and to strengthen the U.S. go playing community. The AGA: • Publishes the American Go e-Journal, free to everyone with Legal Note: The Way To Go is a copyrighted work. special weekly editions for members Permission is granted to make complete copies for • Publishes the American Go Journal Yearbook – free to members personal use. Copies may be distributed freely to • Sanctions and promotes AGA-rated tournaments others either in print or electronic form, provided • Maintains a nationwide rating system no fee is charged for distribution and all copies contain • Organizes the annual U.S. Go Congress and Championship this copyright notice. • Organizes the summer U.S. Go Camp for children • Organizes the annual U.S. Youth Go Championship • Manages U.S. participation in international go events Information on these services and much more is available at the AGA’s website at www.usgo.org. E R I C M A N A American Go Association G Box 397 Old Chelsea Station F O O N U I O New York, NY 10113 N D A T http://www.usgo.org American Go Foundation The American Go Foundation is a 501(c)(3) charitable organiza- tion devoted to the promotion of go in the United States. With our help thousands of youth have learned go from hundreds of teachers. Cover print: Two Immortals and the Woodcutter Our outreach includes go related educational and cultural activities A watercolor by Seikan. -

Reinforcement Learning (1) Key Concepts & Algorithms
Winter 2020 CSC 594 Topics in AI: Advanced Deep Learning 5. Deep Reinforcement Learning (1) Key Concepts & Algorithms (Most content adapted from OpenAI ‘Spinning Up’) 1 Noriko Tomuro Reinforcement Learning (RL) • Reinforcement Learning (RL) is a type of Machine Learning where an agent learns to achieve a goal by interacting with the environment -- trial and error. • RL is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning. • The purpose of RL is to learn an optimal policy that maximizes the return for the sequences of agent’s actions (i.e., optimal policy). https://en.wikipedia.org/wiki/Reinforcement_learning 2 • RL have recently enjoyed a wide variety of successes, e.g. – Robot controlling in simulation as well as in the real world Strategy games such as • AlphaGO (by Google DeepMind) • Atari games https://en.wikipedia.org/wiki/Reinforcement_learning 3 Deep Reinforcement Learning (DRL) • A policy is essentially a function, which maps the agent’s each action to the expected return or reward. Deep Reinforcement Learning (DRL) uses deep neural networks for the function (and other components). https://spinningup.openai.com/en/latest/spinningup/rl_intro.html 4 5 Some Key Concepts and Terminology 1. States and Observations – A state s is a complete description of the state of the world. For now, we can think of states belonging in the environment. – An observation o is a partial description of a state, which may omit information. – A state could be fully or partially observable to the agent. If partial, the agent forms an internal state (or state estimation). https://spinningup.openai.com/en/latest/spinningup/rl_intro.html 6 • States and Observations (cont.) – In deep RL, we almost always represent states and observations by a real-valued vector, matrix, or higher-order tensor. -

OLIVAW: Mastering Othello with Neither Humans Nor a Penny Antonio Norelli, Alessandro Panconesi Dept
1 OLIVAW: Mastering Othello with neither Humans nor a Penny Antonio Norelli, Alessandro Panconesi Dept. of Computer Science, Universita` La Sapienza, Rome, Italy Abstract—We introduce OLIVAW, an AI Othello player adopt- of companies. Another aspect of the same problem is the ing the design principles of the famous AlphaGo series. The main amount of training needed. AlphaGo Zero required 4.9 million motivation behind OLIVAW was to attain exceptional competence games played during self-play. While to attain the level of in a non-trivial board game at a tiny fraction of the cost of its illustrious predecessors. In this paper, we show how the grandmaster for games like Starcraft II and Dota 2 the training AlphaGo Zero’s paradigm can be successfully applied to the required 200 years and more than 10,000 years of gameplay, popular game of Othello using only commodity hardware and respectively [7], [8]. free cloud services. While being simpler than Chess or Go, Thus one of the major problems to emerge in the wake Othello maintains a considerable search space and difficulty of these breakthroughs is whether comparable results can be in evaluating board positions. To achieve this result, OLIVAW implements some improvements inspired by recent works to attained at a much lower cost– computational and financial– accelerate the standard AlphaGo Zero learning process. The and with just commodity hardware. In this paper we take main modification implies doubling the positions collected per a small step in this direction, by showing that AlphaGo game during the training phase, by including also positions not Zero’s successful paradigm can be replicated for the game played but largely explored by the agent. -

Lesson Plans for Go in Schools
Go Lesson Plans 1 Lesson Plans for Go in Schools By Gordon E. Castanza, Ed. D. October 19, 2011 Published By Rittenberg Consulting Group 7806 108th St. NW Gig Harbor, WA 98332 253-853-4831 ©Gordon E. Castanza, Ed. D. 10/19/11 DRAFT Go Lesson Plans 2 Table of Contents Acknowledgements ......................................................................................................................... 4 Purpose/Rationale ........................................................................................................................... 5 Lesson Plan One ............................................................................................................................. 7 Basic Ideas .................................................................................................................................. 7 Introduction ............................................................................................................................... 11 The Puzzle ................................................................................................................................. 13 Surround to Capture .................................................................................................................. 14 First Capture Go ........................................................................................................................ 16 Lesson Plan Two ........................................................................................................................... 19 Units & -
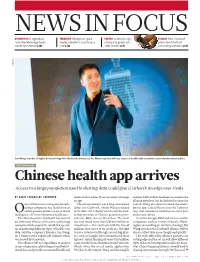
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Fml-Based Dynamic Assessment Agent for Human-Machine Cooperative System on Game of Go
Accepted for publication in International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems in July, 2017 FML-BASED DYNAMIC ASSESSMENT AGENT FOR HUMAN-MACHINE COOPERATIVE SYSTEM ON GAME OF GO CHANG-SHING LEE* MEI-HUI WANG, SHENG-CHI YANG Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan *[email protected], [email protected], [email protected] PI-HSIA HUNG, SU-WEI LIN Department of Education, National University of Tainan, Tainan, Taiwan [email protected], [email protected] NAN SHUO, NAOYUKI KUBOTA Dept. of System Design, Tokyo Metropolitan University, Japan [email protected], [email protected] CHUN-HSUN CHOU, PING-CHIANG CHOU Haifong Weiqi Academy, Taiwan [email protected], [email protected] CHIA-HSIU KAO Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan [email protected] Received (received date) Revised (revised date) Accepted (accepted date) In this paper, we demonstrate the application of Fuzzy Markup Language (FML) to construct an FML- based Dynamic Assessment Agent (FDAA), and we present an FML-based Human–Machine Cooperative System (FHMCS) for the game of Go. The proposed FDAA comprises an intelligent decision-making and learning mechanism, an intelligent game bot, a proximal development agent, and an intelligent agent. The intelligent game bot is based on the open-source code of Facebook’s Darkforest, and it features a representational state transfer application programming interface mechanism. The proximal development agent contains a dynamic assessment mechanism, a GoSocket mechanism, and an FML engine with a fuzzy knowledge base and rule base. -

Towards Incremental Agent Enhancement for Evolving Games
Evaluating Reinforcement Learning Algorithms For Evolving Military Games James Chao*, Jonathan Sato*, Crisrael Lucero, Doug S. Lange Naval Information Warfare Center Pacific *Equal Contribution ffi[email protected] Abstract games in 2013 (Mnih et al. 2013), Google DeepMind devel- oped AlphaGo (Silver et al. 2016) that defeated world cham- In this paper, we evaluate reinforcement learning algorithms pion Lee Sedol in the game of Go using supervised learning for military board games. Currently, machine learning ap- and reinforcement learning. One year later, AlphaGo Zero proaches to most games assume certain aspects of the game (Silver et al. 2017b) was able to defeat AlphaGo with no remain static. This methodology results in a lack of algorithm robustness and a drastic drop in performance upon chang- human knowledge and pure reinforcement learning. Soon ing in-game mechanics. To this end, we will evaluate general after, AlphaZero (Silver et al. 2017a) generalized AlphaGo game playing (Diego Perez-Liebana 2018) AI algorithms on Zero to be able to play more games including Chess, Shogi, evolving military games. and Go, creating a more generalized AI to apply to differ- ent problems. In 2018, OpenAI Five used five Long Short- term Memory (Hochreiter and Schmidhuber 1997) neural Introduction networks and a Proximal Policy Optimization (Schulman et al. 2017) method to defeat a professional DotA team, each AlphaZero (Silver et al. 2017a) described an approach that LSTM acting as a player in a team to collaborate and achieve trained an AI agent through self-play to achieve super- a common goal. AlphaStar used a transformer (Vaswani et human performance. -

Understanding & Generalizing Alphago Zero
Under review as a conference paper at ICLR 2019 UNDERSTANDING &GENERALIZING ALPHAGO ZERO Anonymous authors Paper under double-blind review ABSTRACT AlphaGo Zero (AGZ) (Silver et al., 2017b) introduced a new tabula rasa rein- forcement learning algorithm that has achieved superhuman performance in the games of Go, Chess, and Shogi with no prior knowledge other than the rules of the game. This success naturally begs the question whether it is possible to develop similar high-performance reinforcement learning algorithms for generic sequential decision-making problems (beyond two-player games), using only the constraints of the environment as the “rules.” To address this challenge, we start by taking steps towards developing a formal understanding of AGZ. AGZ includes two key innovations: (1) it learns a policy (represented as a neural network) using super- vised learning with cross-entropy loss from samples generated via Monte-Carlo Tree Search (MCTS); (2) it uses self-play to learn without training data. We argue that the self-play in AGZ corresponds to learning a Nash equilibrium for the two-player game; and the supervised learning with MCTS is attempting to learn the policy corresponding to the Nash equilibrium, by establishing a novel bound on the difference between the expected return achieved by two policies in terms of the expected KL divergence (cross-entropy) of their induced distributions. To extend AGZ to generic sequential decision-making problems, we introduce a robust MDP framework, in which the agent and nature effectively play a zero-sum game: the agent aims to take actions to maximize reward while nature seeks state transitions, subject to the constraints of that environment, that minimize the agent’s reward. -

Computer Go: from the Beginnings to Alphago Martin Müller, University of Alberta
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk ✤ Game of Go ✤ Short history - Computer Go from the beginnings to AlphaGo ✤ The science behind AlphaGo ✤ The legacy of AlphaGo The Game of Go Go ✤ Classic two-player board game ✤ Invented in China thousands of years ago ✤ Simple rules, complex strategy ✤ Played by millions ✤ Hundreds of top experts - professional players ✤ Until 2016, computers weaker than humans Go Rules ✤ Start with empty board ✤ Place stone of your own color ✤ Goal: surround empty points or opponent - capture ✤ Win: control more than half the board Final score, 9x9 board ✤ Komi: first player advantage Measuring Go Strength ✤ People in Europe and America use the traditional Japanese ranking system ✤ Kyu (student) and Dan (master) levels ✤ Separate Dan ranks for professional players ✤ Kyu grades go down from 30 (absolute beginner) to 1 (best) ✤ Dan grades go up from 1 (weakest) to about 6 ✤ There is also a numerical (Elo) system, e.g. 2500 = 5 Dan Short History of Computer Go Computer Go History - Beginnings ✤ 1960’s: initial ideas, designs on paper ✤ 1970’s: first serious program - Reitman & Wilcox ✤ Interviews with strong human players ✤ Try to build a model of human decision-making ✤ Level: “advanced beginner”, 15-20 kyu ✤ One game costs thousands of dollars in computer time 1980-89 The Arrival of PC ✤ From 1980: PC (personal computers) arrive ✤ Many people get cheap access to computers ✤ Many start writing Go programs ✤ First competitions, Computer Olympiad, Ing Cup ✤ Level 10-15 kyu 1990-2005: Slow Progress ✤ Slow progress, commercial successes ✤ 1990 Ing Cup in Beijing ✤ 1993 Ing Cup in Chengdu ✤ Top programs Handtalk (Prof. -

GO WINDS Play Over 1000 Professional Games to Reach Recent Sets Have Focused on "How the Pros 1-Dan, It Is Said
NEW FROM YUTOPIAN ENTERPRISES GO GAMES ON DISK (GOGoD) SOFTWARE GO WINDS Play over 1000 professional games to reach Recent sets have focused on "How the pros 1-dan, it is said. How about 6-dan? Games of play the ...". So far there are sets covering the Go on Disk now offers over 6000 professional "Chinese Fuseki" Volume I (a second volume Volume 2 Number 4 Winter 1999 $3.00 games on disk, games that span the gamut of is in preparation), and "Nirensei", Volumes I go history - featuring players that helped and II. A "Sanrensei" volume is also in define the history. preparation. All these disks typically contain All game collections come with DOS or 300 games. Windows 95 viewing software, and most The latest addition to this series is a collections include the celebrated Go Scorer in "specialty" item - so special GoGoD invented which you can guess the pros' moves as you a new term for it. It is the "Sideways Chinese" play (with hints if necessary) and check your fuseki, which incorporates the Mini-Chinese score. pattern. Very rarely seen in western The star of the collection may well be "Go publications yet played by most of the top Seigen" - the lifetime games (over 800) of pros, this opening is illustrated by over 130 perhaps the century's greatest player, with games from Japan, China and Korea. Over more than 10% commented. "Kitani" 1000 half have brief comments. The next specialty makes an ideal matching set - most of the item in preparation is a set of games featuring lifetime games of his legendary rival, Kitani unusual fusekis - this will include rare New Minoru. -

Curriculum Guide for Go in Schools
Curriculum Guide 1 Curriculum Guide for Go In Schools by Gordon E. Castanza, Ed. D. October 19, 2011 Published By: Rittenberg Consulting Group 7806 108th St. NW Gig Harbor, WA 98332 253-853-4831 © 2005 by Gordon E. Castanza, Ed. D. Curriculum Guide 2 Table of Contents Acknowledgements ......................................................................................................................... 4 Purpose and Rationale..................................................................................................................... 5 About this curriculum guide ................................................................................................... 7 Introduction ..................................................................................................................................... 8 Overview ................................................................................................................................. 9 Building Go Instructor Capacity ........................................................................................... 10 Developing Relationships and Communicating with the Community ................................. 10 Using Resources Effectively ................................................................................................. 11 Conclusion ............................................................................................................................ 11 Major Trends and Issues .......................................................................................................... -

ELF Opengo: an Analysis and Open Reimplementation of Alphazero
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero Yuandong Tian 1 Jerry Ma * 1 Qucheng Gong * 1 Shubho Sengupta * 1 Zhuoyuan Chen 1 James Pinkerton 1 C. Lawrence Zitnick 1 Abstract However, these advances in playing ability come at signifi- The AlphaGo, AlphaGo Zero, and AlphaZero cant computational expense. A single training run requires series of algorithms are remarkable demonstra- millions of selfplay games and days of training on thousands tions of deep reinforcement learning’s capabili- of TPUs, which is an unattainable level of compute for the ties, achieving superhuman performance in the majority of the research community. When combined with complex game of Go with progressively increas- the unavailability of code and models, the result is that the ing autonomy. However, many obstacles remain approach is very difficult, if not impossible, to reproduce, in the understanding of and usability of these study, improve upon, and extend. promising approaches by the research commu- In this paper, we propose ELF OpenGo, an open-source nity. Toward elucidating unresolved mysteries reimplementation of the AlphaZero (Silver et al., 2018) and facilitating future research, we propose ELF algorithm for the game of Go. We then apply ELF OpenGo OpenGo, an open-source reimplementation of the toward the following three additional contributions. AlphaZero algorithm. ELF OpenGo is the first open-source Go AI to convincingly demonstrate First, we train a superhuman model for ELF OpenGo. Af- superhuman performance with a perfect (20:0) ter running our AlphaZero-style training software on 2,000 record against global top professionals. We ap- GPUs for 9 days, our 20-block model has achieved super- ply ELF OpenGo to conduct extensive ablation human performance that is arguably comparable to the 20- studies, and to identify and analyze numerous in- block models described in Silver et al.(2017) and Silver teresting phenomena in both the model training et al.(2018).