Subgradients
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CORE View Metadata, Citation and Similar Papers at Core.Ac.Uk
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Bulgarian Digital Mathematics Library at IMI-BAS Serdica Math. J. 27 (2001), 203-218 FIRST ORDER CHARACTERIZATIONS OF PSEUDOCONVEX FUNCTIONS Vsevolod Ivanov Ivanov Communicated by A. L. Dontchev Abstract. First order characterizations of pseudoconvex functions are investigated in terms of generalized directional derivatives. A connection with the invexity is analysed. Well-known first order characterizations of the solution sets of pseudolinear programs are generalized to the case of pseudoconvex programs. The concepts of pseudoconvexity and invexity do not depend on a single definition of the generalized directional derivative. 1. Introduction. Three characterizations of pseudoconvex functions are considered in this paper. The first is new. It is well-known that each pseudo- convex function is invex. Then the following question arises: what is the type of 2000 Mathematics Subject Classification: 26B25, 90C26, 26E15. Key words: Generalized convexity, nonsmooth function, generalized directional derivative, pseudoconvex function, quasiconvex function, invex function, nonsmooth optimization, solution sets, pseudomonotone generalized directional derivative. 204 Vsevolod Ivanov Ivanov the function η from the definition of invexity, when the invex function is pseudo- convex. This question is considered in Section 3, and a first order necessary and sufficient condition for pseudoconvexity of a function is given there. It is shown that the class of strongly pseudoconvex functions, considered by Weir [25], coin- cides with pseudoconvex ones. The main result of Section 3 is applied to characterize the solution set of a nonlinear programming problem in Section 4. The base results of Jeyakumar and Yang in the paper [13] are generalized there to the case, when the function is pseudoconvex. -

Convexity I: Sets and Functions
Convexity I: Sets and Functions Ryan Tibshirani Convex Optimization 10-725/36-725 See supplements for reviews of basic real analysis • basic multivariate calculus • basic linear algebra • Last time: why convexity? Why convexity? Simply put: because we can broadly understand and solve convex optimization problems Nonconvex problems are mostly treated on a case by case basis Reminder: a convex optimization problem is of ● the form ● ● min f(x) x2D ● ● subject to gi(x) 0; i = 1; : : : m ≤ hj(x) = 0; j = 1; : : : r ● ● where f and gi, i = 1; : : : m are all convex, and ● hj, j = 1; : : : r are affine. Special property: any ● local minimizer is a global minimizer ● 2 Outline Today: Convex sets • Examples • Key properties • Operations preserving convexity • Same for convex functions • 3 Convex sets n Convex set: C R such that ⊆ x; y C = tx + (1 t)y C for all 0 t 1 2 ) − 2 ≤ ≤ In words, line segment joining any two elements lies entirely in set 24 2 Convex sets Figure 2.2 Some simple convexn and nonconvex sets. Left. The hexagon, Convex combinationwhich includesof x1; its : :boundary : xk (shownR : darker), any linear is convex. combinationMiddle. The kidney shaped set is not convex, since2 the line segment between the twopointsin the set shown as dots is not contained in the set. Right. The square contains some boundaryθ1x points1 + but::: not+ others,θkxk and is not convex. k with θi 0, i = 1; : : : k, and θi = 1. Convex hull of a set C, ≥ i=1 conv(C), is all convex combinations of elements. Always convex P 4 Figure 2.3 The convex hulls of two sets in R2. -

Convex Functions
Convex Functions Prof. Daniel P. Palomar ELEC5470/IEDA6100A - Convex Optimization The Hong Kong University of Science and Technology (HKUST) Fall 2020-21 Outline of Lecture • Definition convex function • Examples on R, Rn, and Rn×n • Restriction of a convex function to a line • First- and second-order conditions • Operations that preserve convexity • Quasi-convexity, log-convexity, and convexity w.r.t. generalized inequalities (Acknowledgement to Stephen Boyd for material for this lecture.) Daniel P. Palomar 1 Definition of Convex Function • A function f : Rn −! R is said to be convex if the domain, dom f, is convex and for any x; y 2 dom f and 0 ≤ θ ≤ 1, f (θx + (1 − θ) y) ≤ θf (x) + (1 − θ) f (y) : • f is strictly convex if the inequality is strict for 0 < θ < 1. • f is concave if −f is convex. Daniel P. Palomar 2 Examples on R Convex functions: • affine: ax + b on R • powers of absolute value: jxjp on R, for p ≥ 1 (e.g., jxj) p 2 • powers: x on R++, for p ≥ 1 or p ≤ 0 (e.g., x ) • exponential: eax on R • negative entropy: x log x on R++ Concave functions: • affine: ax + b on R p • powers: x on R++, for 0 ≤ p ≤ 1 • logarithm: log x on R++ Daniel P. Palomar 3 Examples on Rn • Affine functions f (x) = aT x + b are convex and concave on Rn. n • Norms kxk are convex on R (e.g., kxk1, kxk1, kxk2). • Quadratic functions f (x) = xT P x + 2qT x + r are convex Rn if and only if P 0. -

Sum of Squares and Polynomial Convexity
CONFIDENTIAL. Limited circulation. For review only. Sum of Squares and Polynomial Convexity Amir Ali Ahmadi and Pablo A. Parrilo Abstract— The notion of sos-convexity has recently been semidefiniteness of the Hessian matrix is replaced with proposed as a tractable sufficient condition for convexity of the existence of an appropriately defined sum of squares polynomials based on sum of squares decomposition. A multi- decomposition. As we will briefly review in this paper, by variate polynomial p(x) = p(x1; : : : ; xn) is said to be sos-convex if its Hessian H(x) can be factored as H(x) = M T (x) M (x) drawing some appealing connections between real algebra with a possibly nonsquare polynomial matrix M(x). It turns and numerical optimization, the latter problem can be re- out that one can reduce the problem of deciding sos-convexity duced to the feasibility of a semidefinite program. of a polynomial to the feasibility of a semidefinite program, Despite the relative recency of the concept of sos- which can be checked efficiently. Motivated by this computa- convexity, it has already appeared in a number of theo- tional tractability, it has been speculated whether every convex polynomial must necessarily be sos-convex. In this paper, we retical and practical settings. In [6], Helton and Nie use answer this question in the negative by presenting an explicit sos-convexity to give sufficient conditions for semidefinite example of a trivariate homogeneous polynomial of degree eight representability of semialgebraic sets. In [7], Lasserre uses that is convex but not sos-convex. sos-convexity to extend Jensen’s inequality in convex anal- ysis to linear functionals that are not necessarily probability I. -

NP-Hardness of Deciding Convexity of Quartic Polynomials and Related Problems
NP-hardness of Deciding Convexity of Quartic Polynomials and Related Problems Amir Ali Ahmadi, Alex Olshevsky, Pablo A. Parrilo, and John N. Tsitsiklis ∗y Abstract We show that unless P=NP, there exists no polynomial time (or even pseudo-polynomial time) algorithm that can decide whether a multivariate polynomial of degree four (or higher even degree) is globally convex. This solves a problem that has been open since 1992 when N. Z. Shor asked for the complexity of deciding convexity for quartic polynomials. We also prove that deciding strict convexity, strong convexity, quasiconvexity, and pseudoconvexity of polynomials of even degree four or higher is strongly NP-hard. By contrast, we show that quasiconvexity and pseudoconvexity of odd degree polynomials can be decided in polynomial time. 1 Introduction The role of convexity in modern day mathematical programming has proven to be remarkably fundamental, to the point that tractability of an optimization problem is nowadays assessed, more often than not, by whether or not the problem benefits from some sort of underlying convexity. In the famous words of Rockafellar [39]: \In fact the great watershed in optimization isn't between linearity and nonlinearity, but convexity and nonconvexity." But how easy is it to distinguish between convexity and nonconvexity? Can we decide in an efficient manner if a given optimization problem is convex? A class of optimization problems that allow for a rigorous study of this question from a com- putational complexity viewpoint is the class of polynomial optimization problems. These are op- timization problems where the objective is given by a polynomial function and the feasible set is described by polynomial inequalities. -

Chapter 5 Convex Optimization in Function Space 5.1 Foundations of Convex Analysis
Chapter 5 Convex Optimization in Function Space 5.1 Foundations of Convex Analysis Let V be a vector space over lR and k ¢ k : V ! lR be a norm on V . We recall that (V; k ¢ k) is called a Banach space, if it is complete, i.e., if any Cauchy sequence fvkglN of elements vk 2 V; k 2 lN; converges to an element v 2 V (kvk ¡ vk ! 0 as k ! 1). Examples: Let be a domain in lRd; d 2 lN. Then, the space C() of continuous functions on is a Banach space with the norm kukC() := sup ju(x)j : x2 The spaces Lp(); 1 · p < 1; of (in the Lebesgue sense) p-integrable functions are Banach spaces with the norms Z ³ ´1=p p kukLp() := ju(x)j dx : The space L1() of essentially bounded functions on is a Banach space with the norm kukL1() := ess sup ju(x)j : x2 The (topologically and algebraically) dual space V ¤ is the space of all bounded linear functionals ¹ : V ! lR. Given ¹ 2 V ¤, for ¹(v) we often write h¹; vi with h¢; ¢i denoting the dual product between V ¤ and V . We note that V ¤ is a Banach space equipped with the norm j h¹; vi j k¹k := sup : v2V nf0g kvk Examples: The dual of C() is the space M() of Radon measures ¹ with Z h¹; vi := v d¹ ; v 2 C() : The dual of L1() is the space L1(). The dual of Lp(); 1 < p < 1; is the space Lq() with q being conjugate to p, i.e., 1=p + 1=q = 1. -

Estimation of the Derivative of the Convex Function by Means of Its
Journal of Inequalities in Pure and Applied Mathematics http://jipam.vu.edu.au/ Volume 6, Issue 4, Article 113, 2005 ESTIMATION OF THE DERIVATIVE OF THE CONVEX FUNCTION BY MEANS OF ITS UNIFORM APPROXIMATION KAKHA SHASHIASHVILI AND MALKHAZ SHASHIASHVILI TBILISI STATE UNIVERSITY FACULTY OF MECHANICS AND MATHEMATICS 2, UNIVERSITY STR., TBILISI 0143 GEORGIA [email protected] Received 15 June, 2005; accepted 26 August, 2005 Communicated by I. Gavrea ABSTRACT. Suppose given the uniform approximation to the unknown convex function on a bounded interval. Starting from it the objective is to estimate the derivative of the unknown convex function. We propose the method of estimation that can be applied to evaluate optimal hedging strategies for the American contingent claims provided that the value function of the claim is convex in the state variable. Key words and phrases: Convex function, Energy estimate, Left-derivative, Lower convex envelope, Hedging strategies the American contingent claims. 2000 Mathematics Subject Classification. 26A51, 26D10, 90A09. 1. INTRODUCTION Consider the continuous convex function f(x) on a bounded interval [a, b] and suppose that its explicit analytical form is unknown to us, whereas there is the possibility to construct its continuous uniform approximation fδ, where δ is a small parameter. Our objective consists in constructing the approximation to the unknown left-derivative f 0(x−) based on the known ^ function fδ(x). For this purpose we consider the lower convex envelope f δ(x) of fδ(x), that is the maximal convex function, less than or equal to fδ(x). Geometrically it represents the thread stretched from below over the graph of the function fδ(x). -

Chapter 2, Lecture 2: Convex Functions 1 Definition Of
Math 484: Nonlinear Programming1 Mikhail Lavrov Chapter 2, Lecture 2: Convex functions February 6, 2019 University of Illinois at Urbana-Champaign 1 Definition of convex functions n 00 Convex functions f : R ! R with Hf(x) 0 for all x, or functions f : R ! R with f (x) ≥ 0 for all x, are going to be our model of what we want convex functions to be. But we actually work with a slightly more general definition that doesn't require us to say anything about derivatives. n Let C ⊆ R be a convex set. A function f : C ! R is convex on C if, for all x; y 2 C, the inequality holds that f(tx + (1 − t)y) ≤ tf(x) + (1 − t)f(y): (We ask for C to be convex so that tx + (1 − t)y is guaranteed to stay in the domain of f.) This is easiest to visualize in one dimension: x1 x2 The point tx+(1−t)y is somewhere on the line segment [x; y]. The left-hand side of the definition, f(tx + (1 − t)y), is just the value of the function at that point: the green curve in the diagram. The right-hand side of the definition, tf(x) + (1 − t)f(y), is the dashed line segment: a straight line that meets f at x and y. So, geometrically, the definition says that secant lines of f always lie above the graph of f. Although the picture we drew is for a function R ! R, nothing different happens in higher dimen- sions, because only points on the line segment [x; y] (and f's values at those points) play a role in the inequality. -

DC Decomposition of Nonconvex Polynomials with Algebraic Techniques
Noname manuscript No. (will be inserted by the editor) DC Decomposition of Nonconvex Polynomials with Algebraic Techniques Amir Ali Ahmadi · Georgina Hall Received: date / Accepted: date Abstract We consider the problem of decomposing a multivariate polynomial as the difference of two convex polynomials. We introduce algebraic techniques which reduce this task to linear, second order cone, and semidefinite program- ming. This allows us to optimize over subsets of valid difference of convex decompositions (dcds) and find ones that speed up the convex-concave proce- dure (CCP). We prove, however, that optimizing over the entire set of dcds is NP-hard. Keywords Difference of convex programming, conic relaxations, polynomial optimization, algebraic decomposition of polynomials 1 Introduction A difference of convex (dc) program is an optimization problem of the form min f0(x) (1) s.t. fi(x) ≤ 0; i = 1; : : : ; m; where f0; : : : ; fm are difference of convex functions; i.e., fi(x) = gi(x) − hi(x); i = 0; : : : ; m; (2) The authors are partially supported by the Young Investigator Program Award of the AFOSR and the CAREER Award of the NSF. Amir Ali Ahmadi ORFE, Princeton University, Sherrerd Hall, Princeton, NJ 08540 E-mail: a a [email protected] Georgina Hall arXiv:1510.01518v2 [math.OC] 12 Sep 2018 ORFE, Princeton University, Sherrerd Hall, Princeton, NJ 08540 E-mail: [email protected] 2 Amir Ali Ahmadi, Georgina Hall n n and gi : R ! R; hi : R ! R are convex functions. The class of functions that can be written as a difference of convex functions is very broad containing for instance all functions that are twice continuously differentiable [18], [22]. -

Quasi-Convexity, Strictly Quasi-Convexity and Pseudo
REVUE FRANÇAISE D’AUTOMATIQUE, INFORMATIQUE, RECHERCHE OPÉRATIONNELLE.MATHÉMATIQUE BERNARD BEREANU Quasi-convexity, strictly quasi-convexity and pseudo-convexity of composite objective functions Revue française d’automatique, informatique, recherche opéra- tionnelle. Mathématique, tome 6, no 1 (1972), p. 15-26. <http://www.numdam.org/item?id=M2AN_1972__6_1_15_0> © AFCET, 1972, tous droits réservés. L’accès aux archives de la revue « Revue française d’automatique, informa- tique, recherche opérationnelle. Mathématique » implique l’accord avec les conditions générales d’utilisation (http://www.numdam.org/legal.php). Toute utilisation commerciale ou impression systématique est constitutive d’une infraction pénale. Toute copie ou impression de ce fichier doit conte- nir la présente mention de copyright. Article numérisé dans le cadre du programme Numérisation de documents anciens mathématiques http://www.numdam.org/ R A.I.R.O. (6e année, R-l, 1972, p. 15-26) QUASI-CONVEXITY, STRIGTLY QUASI-CONVEXITY AND PSEUDO-CONVEXITY OF COMPOSITE OBJECTIVE FUNCTIONS («) by Bernard BEREANU (2) Résumé. — Dans un article précédent on a donné une condition nécessaire et suffisante •qui assure qu'un certain type de composition de fonctions fait aboutir à des fonctions convexes. Dans cet article on étend ce résultat aux f onctions convexes généralisées (quasi- convexes, strictement quasi-convexes ou pseudo-convexes) fournissant ainsi une méthode pratique de reconnaissance des fonctions ayant ces propriétés. On discute des applications a Véconomie mathématique et à la programmation mathématique. 1. In practice the following situation occurs. One has some freedom to choose a real function ƒ in m variables which will appear in the mathematical model through its composition fou with a vector valued function u — (uu ..., um) of n variables. -

Lecture 3: Convex Sets and Functions 3.1 Convex Sets
EE 227A: Convex Optimization and Applications January 24, 2012 Lecture 3: Convex Sets and Functions Lecturer: Laurent El Ghaoui Reading assignment: Chapters 2 (except x2.6) and sections 3.1, 3.2, 3.3 of BV. You can also look at section 3.1 of the web textbook. 3.1 Convex Sets Definition. A subset C of Rn is convex if and only if it contains the line segment between any two points in it: 8 x1; x2 2 C; 8 θ1 ≥ 0; θ2 ≥ 0; θ1 + θ2 = 1 : θ1x1 + θ2x2 2 C: Some important special cases of convex sets are the following. • The set is said to be an affine subspace if it contains the entire line passing through any two points. This corresponds to the condition above, with θ1; θ2 arbitrary. Subspaces and affine subspaces are convex. • The set is said to be a convex cone if the condition above holds, but with the restriction θ1 + θ2 = 1 removed. Examples. • The convex hull of a set of points fx1; : : : ; xmg is defined as ( m m ) X m X Co(x1; : : : ; xm) := λixi : λ 2 R+ ; λi = 1 ; i=1 i=1 and is convex. The conic hull: ( m ) X m λixi : λ 2 R+ i=1 is a convex cone. • For a 2 Rn, and b 2 R, the hyperplane H = fx : aT x = bg is affine. The half-space fx : aT x ≤ bg is convex. 3-1 EE 227A Lecture 3 | January 24, 2012 Sp'12 n×n n • For a square, non-singular matrix R 2 R , and xc 2 R , the ellipsoid fxc + Ru : kuk2 ≤ 1g is convex. -
The Second Derivative
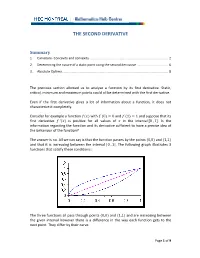
THE SECOND DERIVATIVE Summary 1. Curvature‐ Concavity and convexity ........................................................................................ 2 2. Determining the nature of a static point using the second derivative ................................... 6 3. Absolute Optima ...................................................................................................................... 8 The previous section allowed us to analyse a function by its first derivative. Static, critical, minimum and maximum points could all be determined with the first derivative. Even if the first derivative gives a lot of information about a function, it does not characterize it completely. Consider for example a function with 0 0 and 1 1 and suppose that its first derivative ’ is positive for all values of in the interval 0 , 1. Is the information regarding the function and its derivative sufficient to have a precise idea of the behaviour of the function? The answer is no. All we can say is that the function passes by the points 0,0 and 1,1 and that it is increasing between the interval 0 , 1. The following graph illustrates 3 functions that satisfy these conditions : The three functions all pass through points 0,0 and 1,1 and are increasing between the given interval however there is a difference in the way each function gets to the next point. They differ by their curve. Page 1 of 9 1. Curvature‐ concavity and convexity An intuitive definition: a function is said to be convex at an interval if, for all pairs of points on the graph, the line segment that connects these two points passes above the curve. A function is said to be concave at an interval if, for all pairs of points on the graph, the line segment that connects these two points passes below the curve.