How to Accelerate Your Internet. a Practical Guide to Bandwidth
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Proceedings of the Bsdcon 2002 Conference
USENIX Association Proceedings of the BSDCon 2002 Conference San Francisco, California, USA February 11-14, 2002 THE ADVANCED COMPUTING SYSTEMS ASSOCIATION © 2002 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Flexible Packet Filtering: Providing a Rich Toolbox Kurt J. Lidl Deborah G. Lidl Paul R. Borman Zero Millimeter LLC Wind River Systems Wind River Systems Potomac, MD Potomac, MD Mendota Heights, MN [email protected] [email protected] [email protected] Abstract The BSD/OS IPFW packet filtering system is a well engineered, flexible kernel framework for filtering (accepting, rejecting, logging, or modifying) IP packets. IPFW uses the well understood, widely available Berkeley Packet Filter (BPF) system as the basis of its packet matching abilities, and extends BPF in several straightforward areas. Since the first implementation of IPFW, the system has been enhanced several times to support additional functions, such as rate filtering, network address translation (NAT), and traffic flow monitoring. This paper examines the motivation behind IPFW and the design of the system. Comparisons with some contemporary packet filtering systems are provided. Potential future enhancements for the IPFW system are discussed. 1 Packet Filtering: An Overview might choose to copy only this data. -
On Ttethernet for Integrated Fault-Tolerant Spacecraft Networks
On TTEthernet for Integrated Fault-Tolerant Spacecraft Networks Andrew Loveless∗ NASA Johnson Space Center, Houston, TX, 77058 There has recently been a push for adopting integrated modular avionics (IMA) princi- ples in designing spacecraft architectures. This consolidation of multiple vehicle functions to shared computing platforms can significantly reduce spacecraft cost, weight, and de- sign complexity. Ethernet technology is attractive for inclusion in more integrated avionic systems due to its high speed, flexibility, and the availability of inexpensive commercial off-the-shelf (COTS) components. Furthermore, Ethernet can be augmented with a variety of quality of service (QoS) enhancements that enable its use for transmitting critical data. TTEthernet introduces a decentralized clock synchronization paradigm enabling the use of time-triggered Ethernet messaging appropriate for hard real-time applications. TTEther- net can also provide two forms of event-driven communication, therefore accommodating the full spectrum of traffic criticality levels required in IMA architectures. This paper explores the application of TTEthernet technology to future IMA spacecraft architectures as part of the Avionics and Software (A&S) project chartered by NASA's Advanced Ex- ploration Systems (AES) program. Nomenclature A&S = Avionics and Software Project AA2 = Ascent Abort 2 AES = Advanced Exploration Systems Program ANTARES = Advanced NASA Technology Architecture for Exploration Studies API = Application Program Interface ARM = Asteroid Redirect Mission -

Alternatív Valóság Kovács Ákos Hálózatok 10+ Tb/S 6,4 Tb/S 1,6 Tb/S 1 Tb/S
Számítógép hálózatok Alternatív valóság Kovács Ákos Hálózatok 10+ Tb/s 6,4 Tb/s 1,6 Tb/s 1 Tb/s 800 Gb/s 400 Gb/s 2017? • A jelen és a jövő 200 Gb/s 2018-2020? • Egyre nagyobb informatikai átviteli 50 Gb/s sebesség kell, jó minőségben 100 Gb/s 2018-2020? 2010 • Switchek minden hálózat alapjai 25 Gb/s 40 Gb/s 2016? 2010 5 Gb/s 10 Gb/s 2016? 2002 2,5 Gb/s 2016? 1 Gb/s 1998 100 Mb/s 1995 10 Mb/s 1983 Switchek • Switch-ekről általában • HUB, Bridge, L2 Switch, L3 Switch, Router • 10/100/1000/10GE switch-ek 2,5GE, 5GE (multiGIG switchek) • Néhány fontosabb működési paraméter • Hátlap (backplane) sávszélesség (Gbps) • Csomag továbbítási sebesség (packet forwarding rate, Mpps) • Switch-elési módok (switching methods, forwarding modes) • Fast Forward (cut-through, fragment-free) • Store-and-Forward • Adaptive (intelligent) L2 Switchek • L2 kommunikációra • Csak a MAC cím alapján (lokális hálózatokhoz LAN) MAC cím (48 bit) 24 bit 24 bit Organizationally Unique Identifier A gyártó osztja ki (OUI) L2 Switchek • A switch nem kérdezi meg a MAC címeket, csak megjegyzi • Ha nem tudja merre kellene menni akkor jön a flood (minden portjára elküldi kivéve amin kapta) • Ha erre válaszolnak, akkor azt MAC-PORT párost megjegyzi L2 Switchek döntési lánca • Layer 2 • CAM Content Addressable memory MAC címek • TCAM (ACL, QoS táblák) 3 értéke lehet, 0,1,X ahol x a „don’t care” bit • Kérdések melyekre válaszolni kell: • Merre továbbítsam a csomagot? • Továbbítsam a csomagot? • Milyen QoS értékekkel továbbítsam a csomagot? • InLine sebesség (ASIC) L3 switchek • Más néven Multi-layer switchek • További döntési lehetőségek a magasabb rétegek alapján mint pl. -

Gigabit Ethernet - CH 3 - Ethernet, Fast Ethernet, and Gigabit Ethern
Switched, Fast, and Gigabit Ethernet - CH 3 - Ethernet, Fast Ethernet, and Gigabit Ethern.. Page 1 of 36 [Figures are not included in this sample chapter] Switched, Fast, and Gigabit Ethernet - 3 - Ethernet, Fast Ethernet, and Gigabit Ethernet Standards This chapter discusses the theory and standards of the three versions of Ethernet around today: regular 10Mbps Ethernet, 100Mbps Fast Ethernet, and 1000Mbps Gigabit Ethernet. The goal of this chapter is to educate you as a LAN manager or IT professional about essential differences between shared 10Mbps Ethernet and these newer technologies. This chapter focuses on aspects of Fast Ethernet and Gigabit Ethernet that are relevant to you and doesn’t get into too much technical detail. Read this chapter and the following two (Chapter 4, "Layer 2 Ethernet Switching," and Chapter 5, "VLANs and Layer 3 Switching") together. This chapter focuses on the different Ethernet MAC and PHY standards, as well as repeaters, also known as hubs. Chapter 4 examines Ethernet bridging, also known as Layer 2 switching. Chapter 5 discusses VLANs, some basics of routing, and Layer 3 switching. These three chapters serve as a precursor to the second half of this book, namely the hands-on implementation in Chapters 8 through 12. After you understand the key differences between yesterday’s shared Ethernet and today’s Switched, Fast, and Gigabit Ethernet, evaluating products and building a network with these products should be relatively straightforward. The chapter is split into seven sections: l "Ethernet and the OSI Reference Model" discusses the OSI Reference Model and how Ethernet relates to the physical (PHY) and Media Access Control (MAC) layers of the OSI model. -
![Ispconfig 3 Manual]](https://docslib.b-cdn.net/cover/9381/ispconfig-3-manual-89381.webp)
Ispconfig 3 Manual]
[ISPConfig 3 Manual] ISPConfig 3 Manual Version 1.0 for ISPConfig 3.0.3 Author: Falko Timme <[email protected]> Last edited 09/30/2010 1 The ISPConfig 3 manual is protected by copyright. No part of the manual may be reproduced, adapted, translated, or made available to a third party in any form by any process (electronic or otherwise) without the written specific consent of projektfarm GmbH. You may keep backup copies of the manual in digital or printed form for your personal use. All rights reserved. This copy was issued to: Thomas CARTER - [email protected] - Date: 2010-11-20 [ISPConfig 3 Manual] ISPConfig 3 is an open source hosting control panel for Linux and is capable of managing multiple servers from one control panel. ISPConfig 3 is licensed under BSD license. Managed Services and Features • Manage one or more servers from one control panel (multiserver management) • Different permission levels (administrators, resellers and clients) + email user level provided by a roundcube plugin for ISPConfig • Httpd (virtual hosts, domain- and IP-based) • FTP, SFTP, SCP • WebDAV • DNS (A, AAAA, ALIAS, CNAME, HINFO, MX, NS, PTR, RP, SRV, TXT records) • POP3, IMAP • Email autoresponder • Server-based mail filtering • Advanced email spamfilter and antivirus filter • MySQL client-databases • Webalizer and/or AWStats statistics • Harddisk quota • Mail quota • Traffic limits and statistics • IP addresses 2 The ISPConfig 3 manual is protected by copyright. No part of the manual may be reproduced, adapted, translated, or made available to a third party in any form by any process (electronic or otherwise) without the written specific consent of projektfarm GmbH. -

Study of the Time Triggered Ethernet Dataflow
Institutionen f¨ordatavetenskap Department of Computer and Information Science Final thesis Study of the Time Triggered Ethernet Dataflow by Niclas Rosenvik LIU-IDA/LITH-EX-G{15/011|SE 2015-07-08 Linköpings universitet Linköpings universitet SE-581 83 Linköping, Sweden 581 83 Linköping Link¨opingsuniversitet Institutionen f¨ordatavetenskap Final thesis Study of the Time Triggered Ethernet Dataflow by Niclas Rosenvik LIU-IDA/LITH-EX-G{15/011|SE 2015-07-08 Supervisor: Unmesh Bordoloi Examiner: Petru Eles Abstract In recent years Ethernet has caught the attention of the real-time commu- nity. The main reason for this is that it has a high data troughput, 10Mbit/s and higher, and good EMI characteristics. As a protocol that might be used in real-time environments such as control systems for cars etc, it seems to fulfil the requirements. TTEthernet is a TDMA extension to normal Eth- ernet, designed to meet the hard deadlines required by real-time networks. This thesis describes how TTEthernet handles frames and the mathemat- ical formulas to calculate shuffle delay of frames in such a network. Open problems related to TTEthernet are also discussed. iii Contents 1 Introduction 1 2 Ethernet 2 2.1 Switching . 2 2.2 Ethernet frame format . 3 2.3 The need for TTEthernet . 4 3 TTEthernet 6 3.1 TTEthernet spec . 6 3.1.1 Protocol control frames . 6 3.1.2 Time-triggered frames . 7 3.1.3 Rate constrained frames . 9 3.1.4 Best effort frames . 10 3.2 Integration Algorithms . 10 3.2.1 Shuffling . 10 3.2.2 Preemption . -

Networking Tutorial
EDUCATION Ethernet Technology Allen Light, Broadcom Corp. SNIA Legal Notice EDUCATION • The material contained in this tutorial is copyrighted by the SNIA. • Member companies and individuals may use this material in presentations and literature under the following conditions: – Any slide or slides used must be reproduced without modification – The SNIA must be acknowledged as source of any material used in the body of any document containing material from these presentations. • This presentation is a project of the SNIA Education Committee. SNIA© 2007 Storage Networking Industry Association. All Rights Reserved. Ethernet Technology 2 Abstract EDUCATION Ethernet, the standard local area network (LAN) access method. A specification for "LAN," "LAN connection" or "network card" automatically implies Ethernet without saying so. This session provides an overview of Ethernet technology, with an emphasis on the evolution of the standards from the original implementation of Ethernet on coax cable to the latest 10Gb Ethernet implementations. SNIA© 2007 Storage Networking Industry Association. All Rights Reserved. Ethernet Technology 3 Agenda EDUCATION • The Original Standard • Evolution of Ethernet • Elements of Ethernet • The Frame / Addressing • Media Access Controller • Physical Media SNIA© 2007 Storage Networking Industry Association. All Rights Reserved. Ethernet Technology 4 'net-"w&rk EDUCATION • A system of computers, terminals, and databases connected by communications lines Local Area Network (LAN) • A network of personal computers in a small area (like an office) that are linked by cable, can communicate directly with other devices in the network and can share resources (from Merriam Webster) • So why is this guy talking about a LAN technology at a storage networking conference? SNIA© 2007 Storage Networking Industry Association. -

Campus Networking Best Practices Session 5: Wireless
Campus Networking Best Practices Session 5: Wireless LAN Hervey Allen Dale Smith NSRC & University of Oregon University of Oregon & NSRC [email protected] [email protected] Wireless LAN • Provide wireless network across your campus that has the following characteristics: – Authentication – only allow your users – Roaming – allow users to start up in one section of your network, then move to another location – Runs on your campus network Firewall/ Border Traffic Shaper Router Wireless REN switch Authentication Core Gateway Router Core Servers Network Access Control (NAC) Enterprise Identity Management • Processes and Documentation of users. – Now you must deal with this. – What to use as the back-end user store? • LDAP • Active Directory • Kerberos • Other? – Will this play nice with future use? • email, student/staff information, resource access, ... Identity Management Cont. • An example of such a project can be seen here: – http://ccadmin.uoregon.edu/idm/ • This is a retrofit on to an already retrofitted system. • Learn from others and try to avoid this situation if possible. A Wireless Captive Portal The Wireless Captive Portal • Previous example was very simple. • A Captive Portal is your chance to: – Explain your Acceptable Use Policies – Decide if you must authenticate, or – Allow users on your network and monitor for problems instead (alternate solution). – Anything else? Branding? What's Happening? • remember our initial network diagrams...? • Do you think our hotel built their own solution? • Probably not... Commercial Solutions • Aruba http://www.arubanetworks.com/ • Bradford Networks – http://www.bradfordnetworks.com/ • Cisco NAC Appliance (Clean Access) – http://www.cisco.com/en/US/products/ps6128/ • Cisco Wireless LAN Controllers – http://www.cisco.com/en/US/products/hw/wireless/ • Enterasys http://www.enterasys.com/ • Vernier http://www.verniernetworks.com Open Source Solutions • CoovaChilli (morphed from Chillispot) – http://coova.org/wiki/index.php/CoovaChilli – Uses RADIUS for access and accounting. -

Análise De Usabilidade Da Ferramenta Ipfirewall Para Firewall
Furin e Machado Junior (2011). ANÁLISE DE USABILIDADE DA FERRAMENTA IPFIREWALL PARA FIREWALL Marcelo Antonio Ferreira Furin Graduado em Sistemas de Informação pela LIBERTAS Faculdades Integradas. Dorival Moreira Machado Junior Mestra em Sistemas de Informação e professor da LIBERTAS Faculdades Integradas. 1. INTRODUÇÃO A importância do firewall evidencia-se pela expansão da internet e o consequente aumento de usuários, muitas vezes, sem o conhecimento acerca da proteção de sua rede e sua máquina. Com isso, por meio da ferramenta IPFIREWALL, um filtro de pacotes do sistema operacional FreeBSD, será analisado suas funcionalidades nativas. Outro ponto de destaque para a importância do firewall é evitar que o craker (é o termo usado para designar quem pratica a quebra (ou cracking) de um sistema de segurança, de forma ilegal ou sem ética) invadam os arquivos não autorizados. Dentre as razões para se utilizar o firewall é ajudar a proteger à rede ou computador do usuário de acessos maliciosos de hacker (são indivíduos que elaboram e modificam software e hardware de computadores, seja desenvolvendo funcionalidades novas, seja adaptando as antigas). 2. PROBLEMA DE PESQUISA Utilizando a ferramenta IPFIREWALL para firewall, sem usar quaisquer, ferramentas para auxílio, tem-se o ambiente no qual se origina a pergunta de pesquisa que norteará o presente estudo: No que é possível fazer com as funcionalidades nativas do IPFW? 2.1 OBJETIVO GERAL O objetivo deste trabalho é descrever todas as funcionalidades nativas do IPFW, o qual vem como firewall padrão no sistema operacional FreeBSD, e comprovar que é 100 Furin e Machado Junior (2011). possível fazer o mesmo trabalho realizado pelo IPTABLES gerando um script com as regras. -

Generating Synthetic Voip Traffic for Analyzing Redundant Openbsd
UNIVERSITY OF OSLO Department of Informatics Generating Synthetic VoIP Traffic for Analyzing Redundant OpenBSD-Firewalls Master Thesis Maurice David Woernhard May 23, 2006 Generating Synthetic VoIP Traffic for Analyzing Redundant OpenBSD-Firewalls Maurice David Woernhard May 23, 2006 Abstract Voice over IP, short VoIP, is among the fastest growing broadband technologies in the private and commercial sector. Compared to the Plain Old Telephone System (POTS), Internet telephony has reduced availability, measured in uptime guarantees per a given time period. This thesis makes a contribution towards proper quantitative statements about network availability when using two redun- dant, state synchronized computers, acting as firewalls between the Internet (WAN) and the local area network (LAN). First, methods for generating adequate VoIP traffic volumes for loading a Gigabit Ethernet link are examined, with the goal of using a minimal set of hardware, namely one regular desktop computer. pktgen, the Linux kernel UDP packet generator, was chosen for generating synthetic/artificial traffic, reflecting the common VoIP packet characteristics packet size, changing sender and receiver address, as well as typical UDP-port usage. pktgen’s three main parameters influencing the generation rate are fixed inter-packet delay, packet size and total packet count. It was sought to relate these to more user-friendly val- ues of amount of simultaneous calls, voice codec employed and call duration. The proposed method fails to model VoIP traffic accurately, mostly due to the cur- rently unstable nature of pktgen. However, it is suited for generating enough packets for testing the firewalls. Second, the traffic forwarding limit and failover behavior of the redun- dant, state-synchronized firewalls was examined. -

Automated IT Service Fault Diagnosis Based on Event Correlation Techniques
Automated IT Service Fault Diagnosis Based on Event Correlation Techniques Dissertation an der Fakultat¨ fur¨ Mathematik, Informatik und Statistik der Ludwig-Maximilians-Universitat¨ Munchen¨ vorgelegt von Andreas Hanemann Tag der Einreichung: 22. Mai 2007 1. Berichterstatter: Professor Dr. Heinz-Gerd Hegering, Ludwig-Maximilians-Universit¨at M¨unchen 2. Berichterstatterin: Professor Dr. Gabrijela Dreo Rodosek, Universit¨at der Bundeswehr M¨unchen Automated IT Service Fault Diagnosis Based on Event Correlation Techniques Dissertation an der Fakultat¨ fur¨ Mathematik, Informatik und Statistik der Ludwig-Maximilians-Universitat¨ Munchen¨ vorgelegt von Andreas Hanemann Tag der Einreichung: 22. Mai 2007 Tag der m¨undlichen Pr¨ufung: 19. Juli 2007 1. Berichterstatter: Professor Dr. Heinz-Gerd Hegering, Ludwig-Maximilians-Universit¨at M¨unchen 2. Berichterstatterin: Professor Dr. Gabrijela Dreo Rodosek, Universit¨at der Bundeswehr M¨unchen Acknowledgments This thesis has been written as part of my work as a researcher at the Leib- niz Supercomputing Center (Leibniz-Rechenzentrum, LRZ) of the Bavarian Academy of Sciences and Humanities which was funded by the German Re- search Network (DFN-Verein) as well as in cooperation with the research group of Prof. Dr. Heinz-Gerd Hegering. Apart from the LRZ, this research group called MNM-Team (Munich Network Management Team) is located at the University of Munich (LMU), the Munich University of Technology (TUM) and the University of Federal Armed Forces in Munich. At first, I would like to thank my doctoral advisor Prof. Dr. Heinz-Gerd Hegering for his constant support and helpful advice during the whole prepa- ration time of this thesis. I would also like to express my special gratefulness to my second advisor, Prof. -
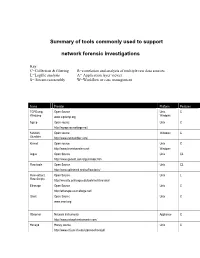
Network Forensic Tools Sidebar
Summary of tools commonly used to support network forensic investigations Key: C=Collection & filtering R=correlation and analysis of multiple raw data sources L=Logfile analysis A= Application layer viewer S= Stream reassembly W=Workflow or case management Name Provider Platform Features TCPDump, Open Source Unix, C Windump www.tcpdump.org Windows Ngrep Open source Unix C http://ngrep.sourceforge.net/ Network Open source Windows C Stumbler http://www.netstumbler.com/ Kismet Open source Unix C http://www.kismetwireless.net Windows Argus Open Source Unix CL http://www.qosient.com/argus/index.htm Flow-tools Open Source Unix CL http://www.splintered.net/sw/flow-tools/ Flow-extract, Open Source Unix L Flow Scripts http://security.uchicago.edu/tools/net-forensics/ Etherape Open Source Unix C http://etherape.sourceforge.net/ Snort Open Source Unix C www.snort.org Observer Network Instruments Appliance C http://www.networkinstruments.com/ Honeyd Honey source Unix C http://www.citi.umich.edu/u/provos/honeyd/ Ethereal Open Source Windows CLS www.Ethereal.com Unix Etherpeek Wild Packets, Inc. Windows CLS www.wildpackets.com SecureNet Intrusion Inc. Windows with CS http://www.intrusion.com collector appliance FLAG Open Source Unix L Forensic and http://www.dsd.gov.au/library/software/flag/ Log Analysis GUI ACID Analysis Console for Intrusion Databases Unix L http://www.andrew.cmu.edu/~rdanyliw/snort/snortacid.html Shadow http://www.nswc.navy.mil/ISSEC/CID/index.html Unix LS DeepNines and http://www.deepnines.com/sleuth9.html Unix CSR Sleuth9 Infinistream