Microbiome Profiling by Illumina Sequencing of Combinatorial Sequence-Tagged PCR Products
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
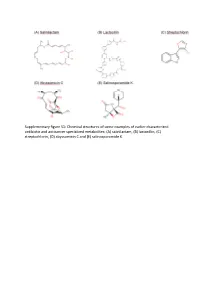
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

Table S5. the Information of the Bacteria Annotated in the Soil Community at Species Level
Table S5. The information of the bacteria annotated in the soil community at species level No. Phylum Class Order Family Genus Species The number of contigs Abundance(%) 1 Firmicutes Bacilli Bacillales Bacillaceae Bacillus Bacillus cereus 1749 5.145782459 2 Bacteroidetes Cytophagia Cytophagales Hymenobacteraceae Hymenobacter Hymenobacter sedentarius 1538 4.52499338 3 Gemmatimonadetes Gemmatimonadetes Gemmatimonadales Gemmatimonadaceae Gemmatirosa Gemmatirosa kalamazoonesis 1020 3.000970902 4 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas indica 797 2.344876284 5 Firmicutes Bacilli Lactobacillales Streptococcaceae Lactococcus Lactococcus piscium 542 1.594633558 6 Actinobacteria Thermoleophilia Solirubrobacterales Conexibacteraceae Conexibacter Conexibacter woesei 471 1.385742446 7 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas taxi 430 1.265115184 8 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas wittichii 388 1.141545794 9 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas sp. FARSPH 298 0.876754244 10 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sorangium cellulosum 260 0.764953367 11 Proteobacteria Deltaproteobacteria Myxococcales Polyangiaceae Sorangium Sphingomonas sp. Cra20 260 0.764953367 12 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas panacis 252 0.741416341 -

The Power of Partnership » AP2.Com MOLECULAR TEST MENU
The Power of Partnership » AP2.com MOLECULAR TEST MENU AP2 provides the most comprehensive Women’s Health Care molecular menu. AP2 can perform most of these tests from our scientifically developed UniSwabTM as well as from the liquid based platforms SurePathTM and ThinPrep®. The following is a comprehensive list of molecular tests available from AP2. If one molecular test is ordered upfront, add-on testing is available for 45 days on UniSwabTM, ThinPrep® and SurePathTM. If no molecular test is ordered up front, add-on testing is available for 28 days on UniSwabTM and ThinPrep®. HPV and CT/NG testing can be added on to ThinPrep® specimens prior to 28 days after collection. UniSwab ThinPrep SurePath 70142 Atopobium vaginae 70142 Atopobium vaginae 70142 Atopobium vaginae 60135 Bacterial vaginosis panel 60135 Bacterial vaginosis panel 60135 Bacterial vaginosis panel (Mobiluncus mulieris and M. curtisii, Gardnerella (Mobiluncus mulieris and M. curtisii, Gardnerella (Mobiluncus mulieris and M. curtisii, Gardnerella vaginalis, Atopobium vaginae, Mycoplasma vaginalis, Atopobium vaginae, Mycoplasma vaginalis, Atopobium vaginae, Mycoplasma genitalium and hominis) genitalium and hominis) genitalium and hominis) 70125 Bacteroides fragilis 70125 Bacteroides fragilis 70125 Bacteroides fragilis 70164 BVAB2 70164 BVAB2 70164 BVAB2 70551 Candida albicans 70551 Candida albicans 70551 Candida albicans 70559 Candida glabrata 70559 Candida glabrata 70559 Candida glabrata 70561 Candida kefyr 70561 Candida kefyr 70561 Candida kefyr 70560 Candida krusei 70560 -

A Genomic Journey Through a Genus of Large DNA Viruses
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Virology Papers Virology, Nebraska Center for 2013 Towards defining the chloroviruses: a genomic journey through a genus of large DNA viruses Adrien Jeanniard Aix-Marseille Université David D. Dunigan University of Nebraska-Lincoln, [email protected] James Gurnon University of Nebraska-Lincoln, [email protected] Irina V. Agarkova University of Nebraska-Lincoln, [email protected] Ming Kang University of Nebraska-Lincoln, [email protected] See next page for additional authors Follow this and additional works at: https://digitalcommons.unl.edu/virologypub Part of the Biological Phenomena, Cell Phenomena, and Immunity Commons, Cell and Developmental Biology Commons, Genetics and Genomics Commons, Infectious Disease Commons, Medical Immunology Commons, Medical Pathology Commons, and the Virology Commons Jeanniard, Adrien; Dunigan, David D.; Gurnon, James; Agarkova, Irina V.; Kang, Ming; Vitek, Jason; Duncan, Garry; McClung, O William; Larsen, Megan; Claverie, Jean-Michel; Van Etten, James L.; and Blanc, Guillaume, "Towards defining the chloroviruses: a genomic journey through a genus of large DNA viruses" (2013). Virology Papers. 245. https://digitalcommons.unl.edu/virologypub/245 This Article is brought to you for free and open access by the Virology, Nebraska Center for at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Virology Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Authors Adrien Jeanniard, David D. Dunigan, James Gurnon, Irina V. Agarkova, Ming Kang, Jason Vitek, Garry Duncan, O William McClung, Megan Larsen, Jean-Michel Claverie, James L. Van Etten, and Guillaume Blanc This article is available at DigitalCommons@University of Nebraska - Lincoln: https://digitalcommons.unl.edu/ virologypub/245 Jeanniard, Dunigan, Gurnon, Agarkova, Kang, Vitek, Duncan, McClung, Larsen, Claverie, Van Etten & Blanc in BMC Genomics (2013) 14. -

Actinomyces As Actinomyces Suis Comb
INTERNATIONALJOURNAL OF SYSTEMATICBACTERIOLOGY, Jan. 1992, p. 161-165 Vol. 42, No. 1 0020-7713/92/010161-05$02.00/0 Phylogenetic Evidence for the Transfer of Eubacterium suis to the Genus Actinomyces as Actinomyces suis comb. nov. W. LUDWIG,l* G. KIRCHHOF,l M. WEIZENEGGER,l AND N. WEISS2 Lehrstuhl fur Mikrobiologie, Technische Universitat, 0-8000 Munich, and Deutsche Sammlung von Mikroorganismen und Zellkulturen, 0-3300 Braunschweig, Germany The 16s rRNA primary structures of Eubacterium suis DSM 20639T (T = type strain) and Bijidobacterium bijidum DSM 20456T were determined by sequencing in vitro amplified rDNA. Sequence comparisons indicated that B. bijidum is moderately related to representatives of the genera Actinomyces and Mobiluncus. The closest relative of E. suis is Actinomyces pyogenes. E. suis and A. pyogenes are more closely related phylogenetically to one another than to the other Actinomyces species that have been investigated by using comparative 16s rRNA analysis. Therefore, we propose that E. suis should be transferred to the genus Actinomyces as Actinomyces suis comb. nov. Eubacterium suis Wegienek and Reddy 1982, a commonly MATERIALS AND METHODS occurring swine pathogen (23), was originally isolated by Soltys and Spratling in 1957 (20). The name “Corynebacte- Bacterial strains and culture conditions. B. bifidum DSM rium suis” was proposed for this bacterium because of the 20456T (T = type strain) was cultured anaerobically at 37°C diphtheroid morphology of the anaerobic organism. In 1982 in a medium which contained (per liter of distilled water) 10 in a taxonomic study, Wegienek and Reddy described the g of tryptone, 5 g of meat extract, 5 g of yeast extract, 10 g morphological, cultural, and biochemical characteristics of of glucose, 3 g of K2HP0,, 5 g of NaC1, 10 ml of Tween 80, this organism and proposed the name Eubacterium suis. -

Diversity and Prevalence of ANTAR Rnas Across Actinobacteria
bioRxiv preprint doi: https://doi.org/10.1101/2020.10.11.335034; this version posted October 11, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Diversity and prevalence of ANTAR RNAs across actinobacteria Dolly Mehta1,2 and Arati Ramesh1,+ 1National Centre for Biological Sciences, Tata Institute of Fundamental Research, GKVK Campus, Bellary Road, Bangalore, India 560065. 2SASTRA University, Tirumalaisamudram, Thanjavur – 613401. +Corresponding Author: Arati Ramesh National Centre for Biological Sciences GKVK Campus, Bellary Road Bangalore, 560065 Tel. 91-80-23666930 e-mail: [email protected] Running title: Identification of ANTAR RNAs across Actinobacteria Keywords: ANTAR protein:RNA regulatory system, structured RNA, actinobacteria 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.10.11.335034; this version posted October 11, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. ABSTRACT Computational approaches are often used to predict regulatory RNAs in bacteria, but their success is limited to RNAs that are highly conserved across phyla, in sequence and structure. The ANTAR regulatory system consists of a family of RNAs (the ANTAR-target RNAs) that selectively recruit ANTAR proteins. This protein-RNA complex together regulates genes at the level of translation or transcriptional elongation. -

Laboratory Diagnosis of Sexually Transmitted Infections, Including Human Immunodeficiency Virus
Laboratory diagnosis of sexually transmitted infections, including human immunodeficiency virus human immunodeficiency including Laboratory transmitted infections, diagnosis of sexually Laboratory diagnosis of sexually transmitted infections, including human immunodeficiency virus Editor-in-Chief Magnus Unemo Editors Ronald Ballard, Catherine Ison, David Lewis, Francis Ndowa, Rosanna Peeling For more information, please contact: Department of Reproductive Health and Research World Health Organization Avenue Appia 20, CH-1211 Geneva 27, Switzerland ISBN 978 92 4 150584 0 Fax: +41 22 791 4171 E-mail: [email protected] www.who.int/reproductivehealth 7892419 505840 WHO_STI-HIV_lab_manual_cover_final_spread_revised.indd 1 02/07/2013 14:45 Laboratory diagnosis of sexually transmitted infections, including human immunodeficiency virus Editor-in-Chief Magnus Unemo Editors Ronald Ballard Catherine Ison David Lewis Francis Ndowa Rosanna Peeling WHO Library Cataloguing-in-Publication Data Laboratory diagnosis of sexually transmitted infections, including human immunodeficiency virus / edited by Magnus Unemo … [et al]. 1.Sexually transmitted diseases – diagnosis. 2.HIV infections – diagnosis. 3.Diagnostic techniques and procedures. 4.Laboratories. I.Unemo, Magnus. II.Ballard, Ronald. III.Ison, Catherine. IV.Lewis, David. V.Ndowa, Francis. VI.Peeling, Rosanna. VII.World Health Organization. ISBN 978 92 4 150584 0 (NLM classification: WC 503.1) © World Health Organization 2013 All rights reserved. Publications of the World Health Organization are available on the WHO web site (www.who.int) or can be purchased from WHO Press, World Health Organization, 20 Avenue Appia, 1211 Geneva 27, Switzerland (tel.: +41 22 791 3264; fax: +41 22 791 4857; e-mail: [email protected]). Requests for permission to reproduce or translate WHO publications – whether for sale or for non-commercial distribution – should be addressed to WHO Press through the WHO web site (www.who.int/about/licensing/copyright_form/en/index.html). -

Examining the Link Between Macrophyte Diversity, Bacterial
EXAMINING THE LINK BETWEEN MACROPHYTE DIVERSITY, BACTERIAL DIVERSITY, AND DENITRIFICATION FUNCTION IN WETLANDS DISSERTATION Presented in Partial Fulfillment of the Requirements for The Degree of Doctor of Philosophy in the Graduate School of The Ohio State University By Janice M. Gilbert, B.E.S., B.Ed., M.E.S., M.S. ***** The Ohio State University 2004 Dissertation Committee: Professor Virginie Bouchard, Adviser Approved by Professor Serita D. Frey, Co-adviser Professor Olli H. Tuovinen Professor Frederick C. Michel, Jr. Adviser Environmental Science Graduate Program ABSTRACT The relationship between aquatic plant (macrophyte) diversity, bacterial diversity, and the biochemical reduction of nitrate (denitrification) within wetlands was examined. Denitrification occurs under anoxic conditions when nitrate is reduced to either nitrous oxide (N2O), or dinitrogen (N2). Although previous studies have identified physical and chemical factors regulating the production of either gas in wetlands, the role that macrophyte diversity plays in this process is not known. The central hypothesis, based on the niche-complimentarity mechanism, was that an increase in macrophyte diversity would lead to increased bacterial diversity, increased denitrification, and decreased N2O flux. This hypothesis was investigated in two mesocosm studies to control environmental conditions while altering macrophyte functional groups (FG) and functional group diversity. In Study #1, five macrophyte functional groups (clonal dominants, tussocks, reeds, facultative annuals, and obligate annuals) were each represented by two species. Fifty-five mesocosms with 5-6 replicates of 0, 1, 2, 3, 4, or 5 macrophyte FG (0-10 species) were established in the spring of 2001 and sampled in August 2001, September 2001, and April 2002. -

Phylogenetic Microarrays
Phylogenetic Microarrays Phylogenetic Microarrays Oleg Paliy, Vijay Shankar and Marketa Sagova-Mareckova 9 Abstract microbial members. Many of these communities Environmental microbial communities are known play pivotal roles in ecosystem processes such as to be highly diverse, often comprising hundreds energy flow, elemental cycling, and biomass pro- and thousands of different species. Such great duction. Energy and nutrients in these systems complexity of these populations, as well as the are processed by intricate networks of metabolic fastidious nature of many of the microorganisms, pathways through multiple community members makes culture-based techniques both inefficient (Duncan et al., 2004; Belenguer et al., 2006; Flint and challenging to study these communities. The et al., 2008; De Vuyst and Leroy, 2011). The sheer analyses of such communities are best accom- complexity of such networks and the difficulty plished by the use of high-throughput molecular involved in culturing the individual members of methods such as phylogenetic microarrays and these communities have challenged researchers next generation sequencing. Phylogenetic micro- who have tried to gain a clearer understanding of arrays have recently become a popular tool for these interactions. Recent advances in molecular the compositional analysis of complex microbial technologies have significantly simplified the communities, owing to their ability to provide analysis of these communities because they simultaneous quantitative measurements of many remove the need to culture and grow community community members. This chapter describes the members individually. Some of the currently currently available phylogenetic microarrays used available molecular techniques include high- in the interrogation of complex microbial commu- throughput sequencing (discussed in chapter 8 of nities, the technology used to construct the arrays, this book), terminal restriction fragment length as well as several key features that distinguish them polymorphism (discussed in Chapter 6), cheq- from other approaches. -

Wiring the Microbial Web of Earth – New Approaches for Scalable Computational Prediction of Interpretable Microbial Ecosystem Structure
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2019 Wiring the Microbial Web of Earth – New Approaches for Scalable Computational Prediction of Interpretable Microbial Ecosystem Structure Tackmann, Janko Abstract: Microorganisms are the principal biotic driver of life on Earth. They shape virtually every aspect of the planet’s biosphere, through both the maintenance of global biogeochemical cycles and via essential symbiotic relationships with multi-cellular organisms. Questions related to how individual mi- crobial species form interacting communities (ecosystems)—with a drastic impact on their hosts and environments— are being studied with rapidly accelerating intensity by the Microbial Ecology field. En- abled through recent innovations in sequencing technologies, staggering amounts of knowledge are lately being generated, which already yielded fascinating insights: microorganisms have now been identified in even the most extreme environments, all across the globe, and intriguing connections between hosts and their microbiota are continuously being discovered, including for instance links to disease develop- ment and host behavior. So far, insights have mainly been gained through comparatively straightfor- ward, descriptive analyses of static microbial community snapshots. Such workflows employ for instance diversity-based comparisons of community profiles or the identification of community members thatare strongly associated with a condition of interest (e.g. a disease or lifestyle factor). Less research has how- ever focused on disentangling the underlying interaction structures, which dictate ecosystem dynamics and thus ultimately mold the observed community patterns. Elucidating these complex relationships would allow a system-level understanding of microbial communities and inform experiments aimed at mechanistic understanding. -

Plastid-Localized Amino Acid Biosynthetic Pathways of Plantae Are Predominantly Composed of Non-Cyanobacterial Enzymes
Plastid-localized amino acid biosynthetic pathways of Plantae are predominantly SUBJECT AREAS: MOLECULAR EVOLUTION composed of non-cyanobacterial PHYLOGENETICS PLANT EVOLUTION enzymes PHYLOGENY Adrian Reyes-Prieto1* & Ahmed Moustafa2* Received 1 26 September 2012 Canadian Institute for Advanced Research and Department of Biology, University of New Brunswick, Fredericton, Canada, 2Department of Biology and Biotechnology Graduate Program, American University in Cairo, Egypt. Accepted 27 November 2012 Studies of photosynthetic eukaryotes have revealed that the evolution of plastids from cyanobacteria Published involved the recruitment of non-cyanobacterial proteins. Our phylogenetic survey of .100 Arabidopsis 11 December 2012 nuclear-encoded plastid enzymes involved in amino acid biosynthesis identified only 21 unambiguous cyanobacterial-derived proteins. Some of the several non-cyanobacterial plastid enzymes have a shared phylogenetic origin in the three Plantae lineages. We hypothesize that during the evolution of plastids some enzymes encoded in the host nuclear genome were mistargeted into the plastid. Then, the activity of those Correspondence and foreign enzymes was sustained by both the plastid metabolites and interactions with the native requests for materials cyanobacterial enzymes. Some of the novel enzymatic activities were favored by selective compartmentation should be addressed to of additional complementary enzymes. The mosaic phylogenetic composition of the plastid amino acid A.R.-P. ([email protected]) biosynthetic pathways and the reduced number of plastid-encoded proteins of non-cyanobacterial origin suggest that enzyme recruitment underlies the recompartmentation of metabolic routes during the evolution of plastids. * Equal contribution made by these authors. rimary plastids of plants and algae are the evolutionary outcome of an endosymbiotic association between eukaryotes and cyanobacteria1. -

Oral Sex and the Transmission of Non-Viral Stis Sex Transm Infect: First Published As 10.1136/Sti.74.2.95 on 1 April 1998
Sex Transm Inf 1998;74:95–100 95 Oral sex and the transmission of non-viral STIs Sex Transm Infect: first published as 10.1136/sti.74.2.95 on 1 April 1998. Downloaded from Review Sarah Edwards, Chris Carne Objectives: To review the literature on the role of oral sex in the transmission of non-viral sexu- ally transmitted infections (STIs). Method: A Medline search was performed using the keywords oro-genital sex, and those specific to each infection. Further references were then taken from each article read. Conclusions: Oral sex is a common sexual practice between both heterosexual and homosexual couples. Oro-genital sex is implicated as a route of transmission for gonorrhoea, syphilis, Chlamy- dia trachomatis, chancroid, and Neisseria meningitidis. Other respiratory organisms such as strep- tococci, Haemophilus influenzae, and Mycoplasma pneumoniae could also be transmitted by this route. Fellatio confers risk for acquisition of infection by the oral partner. Cunnilingus appears to predispose to recurrent vaginal candidiasis although the mechanism for this is unclear, while a link between oro-genital sex and bacterial vaginosis is currently being studied. Oro-anal sex is implicated in the transmission of various enteric infections. In view of the increased practice of oral sex this has become a more important potential route of transmission for oral, respiratory, and genital pathogens. (Sex Transm Inf 1998;74:95–100) Keywords: oral sex; STIs; enteric infections Introduction antimicrobial substances (for example, thio- This is the second of two articles which look at cyanate, lysozyme, and nitric oxide) in saliva8 the transmission of infection via oral contact.