Wiring the Microbial Web of Earth – New Approaches for Scalable Computational Prediction of Interpretable Microbial Ecosystem Structure
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
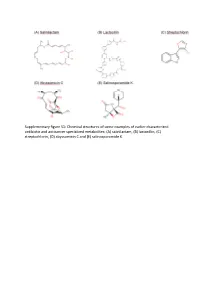
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

Phylogenomics Provides Robust Support for a Two-Domains Tree of Life
ARTICLES https://doi.org/10.1038/s41559-019-1040-x Phylogenomics provides robust support for a two-domains tree of life Tom A. Williams! !1*, Cymon J. Cox! !2, Peter G. Foster3, Gergely J. Szöllősi4,5,6 and T. Martin Embley7* Hypotheses about the origin of eukaryotic cells are classically framed within the context of a universal ‘tree of life’ based on conserved core genes. Vigorous ongoing debate about eukaryote origins is based on assertions that the topology of the tree of life depends on the taxa included and the choice and quality of genomic data analysed. Here we have reanalysed the evidence underpinning those claims and apply more data to the question by using supertree and coalescent methods to interrogate >3,000 gene families in archaea and eukaryotes. We find that eukaryotes consistently originate from within the archaea in a two-domains tree when due consideration is given to the fit between model and data. Our analyses support a close relation- ship between eukaryotes and Asgard archaea and identify the Heimdallarchaeota as the current best candidate for the closest archaeal relatives of the eukaryotic nuclear lineage. urrent hypotheses about eukaryotic origins generally pro- Indeed, it has previously been suggested that it is the 3D tree, rather pose at least two partners in that process: a bacterial endo- than the 2D tree, that is an artefact of long-branch attraction5,9–11, symbiont that became the mitochondrion and a host cell for both because analyses under better-fitting models have recovered C 1–4 that endosymbiosis . The identity of the host has been informed a 2D tree but also because the 3D topology is one in which the two by analyses of conserved genes for the transcription and transla- longest branches in the tree of life—the stems leading to bacteria and tion machinery that are considered essential for cellular life5. -

Computational Pan-Genomics: Status, Promises and Challenges
bioRxiv preprint doi: https://doi.org/10.1101/043430; this version posted March 12, 2016. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Computational Pan-Genomics: Status, Promises and Challenges Tobias Marschall1,2, Manja Marz3,60,61,62, Thomas Abeel49, Louis Dijkstra6,7, Bas E. Dutilh8,9,10, Ali Ghaffaari1,2, Paul Kersey11, Wigard P. Kloosterman12, Veli M¨akinen13, Adam Novak15, Benedict Paten15, David Porubsky16, Eric Rivals17,63, Can Alkan18, Jasmijn Baaijens5, Paul I. W. De Bakker12, Valentina Boeva19,64,65,66, Francesca Chiaromonte20, Rayan Chikhi21, Francesca D. Ciccarelli22, Robin Cijvat23, Erwin Datema24,25,26, Cornelia M. Van Duijn27, Evan E. Eichler28, Corinna Ernst29, Eleazar Eskin30,31, Erik Garrison32, Mohammed El-Kebir5,33,34, Gunnar W. Klau5, Jan O. Korbel11,35, Eric-Wubbo Lameijer36, Benjamin Langmead37, Marcel Martin59, Paul Medvedev38,39,40, John C. Mu41, Pieter Neerincx36, Klaasjan Ouwens42,67, Pierre Peterlongo43, Nadia Pisanti44,45, Sven Rahmann29, Ben Raphael46,47, Knut Reinert48, Dick de Ridder50, Jeroen de Ridder49, Matthias Schlesner51, Ole Schulz-Trieglaff52, Ashley Sanders53, Siavash Sheikhizadeh50, Carl Shneider54, Sandra Smit50, Daniel Valenzuela13, Jiayin Wang70,71,72, Lodewyk Wessels56, Ying Zhang23,5, Victor Guryev16,12, Fabio Vandin57,34, Kai Ye68,69,72 and Alexander Sch¨onhuth5 1Center for Bioinformatics, Saarland University, Saarbr¨ucken, Germany; 2Max Planck Institute for Informatics, Saarbr¨ucken, -

Serratia Marcescens: Outer Membrane Porins and Comparative Genomics
Serratia marcescens: Outer Membrane Porins and Comparative Genomics By Alexander Diamandas A Thesis submitted to the Faculty of Graduate Studies of The University of Manitoba In partial fulfillment of the requirements of the degree of Master of Science Department of Microbiology University of Manitoba Winnipeg Copyright © 2019 by Alexander Diamandas Table of Contents Abstract ........................................................................................................................................................ v Acknowledgments ...................................................................................................................................... vi List of Tables .............................................................................................................................................. vii List of Figures ............................................................................................................................................ viii 1. Literature Review: ............................................................................................................................ 10 1.1. Serratia marcescens .................................................................................................................... 10 1.1.1. Species ................................................................................................................................ 11 1.1.2. Incidence and Mortality ..................................................................................................... -

CURRICULUM VITAE George M. Weinstock, Ph.D
CURRICULUM VITAE George M. Weinstock, Ph.D. DATE September 26, 2014 BIRTHDATE February 6, 1949 CITIZENSHIP USA ADDRESS The Jackson Laboratory for Genomic Medicine 10 Discovery Drive Farmington, CT 06032 [email protected] phone: 860-837-2420 PRESENT POSITION Associate Director for Microbial Genomics Professor Jackson Laboratory for Genomic Medicine UNDERGRADUATE 1966-1967 Washington University EDUCATION 1967-1970 University of Michigan 1970 B.S. (with distinction) Biophysics, Univ. Mich. GRADUATE 1970-1977 PHS Predoctoral Trainee, Dept. Biology, EDUCATION Mass. Institute of Technology, Cambridge, MA 1977 Ph.D., Advisor: David Botstein Thesis title: Genetic and physical studies of bacteriophage P22 genomes containing translocatable drug resistance elements. POSTDOCTORAL 1977-1980 Postdoctoral Fellow, Department of Biochemistry TRAINING Stanford University Medical School, Stanford, CA. Advisor: Dr. I. Robert Lehman. ACADEMIC POSITIONS/EMPLOYMENT/EXPERIENCE 1980-1981 Staff Scientist, Molec. Gen. Section, NCI-Frederick Cancer Research Facility, Frederick, MD 1981-1983 Staff Scientist, Laboratory of Genetics and Recombinant DNA, NCI-Frederick Cancer Research Facility, Frederick, MD 1981-1984 Adjunct Associate Professor, Department of Biological Sciences, University of Maryland, Baltimore County, Catonsville, MD 1983-1984 Senior Scientist and Head, DNA Metabolism Section, Lab. Genetics and Recombinant DNA, NCI-Frederick Cancer Research Facility, Frederick, MD 1984-1990 Associate Professor with tenure (1985) Department of Biochemistry -

Table S5. the Information of the Bacteria Annotated in the Soil Community at Species Level
Table S5. The information of the bacteria annotated in the soil community at species level No. Phylum Class Order Family Genus Species The number of contigs Abundance(%) 1 Firmicutes Bacilli Bacillales Bacillaceae Bacillus Bacillus cereus 1749 5.145782459 2 Bacteroidetes Cytophagia Cytophagales Hymenobacteraceae Hymenobacter Hymenobacter sedentarius 1538 4.52499338 3 Gemmatimonadetes Gemmatimonadetes Gemmatimonadales Gemmatimonadaceae Gemmatirosa Gemmatirosa kalamazoonesis 1020 3.000970902 4 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas indica 797 2.344876284 5 Firmicutes Bacilli Lactobacillales Streptococcaceae Lactococcus Lactococcus piscium 542 1.594633558 6 Actinobacteria Thermoleophilia Solirubrobacterales Conexibacteraceae Conexibacter Conexibacter woesei 471 1.385742446 7 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas taxi 430 1.265115184 8 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas wittichii 388 1.141545794 9 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas sp. FARSPH 298 0.876754244 10 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sorangium cellulosum 260 0.764953367 11 Proteobacteria Deltaproteobacteria Myxococcales Polyangiaceae Sorangium Sphingomonas sp. Cra20 260 0.764953367 12 Proteobacteria Alphaproteobacteria Sphingomonadales Sphingomonadaceae Sphingomonas Sphingomonas panacis 252 0.741416341 -

Science & Policy Meeting Jennifer Lippincott-Schwartz Science in The
SUMMER 2014 ISSUE 27 encounters page 9 Science in the desert EMBO | EMBL Anniversary Science & Policy Meeting pageS 2 – 3 ANNIVERSARY TH page 8 Interview Jennifer E M B O 50 Lippincott-Schwartz H ©NI Membership expansion EMBO News New funding for senior postdoctoral In perspective Georgina Ferry’s enlarges its membership into evolution, researchers. EMBO Advanced Fellowships book tells the story of the growth and ecology and neurosciences on the offer an additional two years of financial expansion of EMBO since 1964. occasion of its 50th anniversary. support to former and current EMBO Fellows. PAGES 4 – 6 PAGE 11 PAGES 16 www.embo.org HIGHLIGHTS FROM THE EMBO|EMBL ANNIVERSARY SCIENCE AND POLICY MEETING transmissible cancer: the Tasmanian devil facial Science meets policy and politics tumour disease and the canine transmissible venereal tumour. After a ceremony to unveil the 2014 marks the 50th anniversary of EMBO, the 45th anniversary of the ScienceTree (see box), an oak tree planted in soil European Molecular Biology Conference (EMBC), the organization of obtained from countries throughout the European member states who fund EMBO, and the 40th anniversary of the European Union to symbolize the importance of European integration, representatives from the govern- Molecular Biology Laboratory (EMBL). EMBO, EMBC, and EMBL recently ments of France, Luxembourg, Malta, Spain combined their efforts to put together a joint event at the EMBL Advanced and Switzerland took part in a panel discussion Training Centre in Heidelberg, Germany, on 2 and 3 July 2014. The moderated by Marja Makarow, Vice President for Research of the Academy of Finland. -

The Power of Partnership » AP2.Com MOLECULAR TEST MENU
The Power of Partnership » AP2.com MOLECULAR TEST MENU AP2 provides the most comprehensive Women’s Health Care molecular menu. AP2 can perform most of these tests from our scientifically developed UniSwabTM as well as from the liquid based platforms SurePathTM and ThinPrep®. The following is a comprehensive list of molecular tests available from AP2. If one molecular test is ordered upfront, add-on testing is available for 45 days on UniSwabTM, ThinPrep® and SurePathTM. If no molecular test is ordered up front, add-on testing is available for 28 days on UniSwabTM and ThinPrep®. HPV and CT/NG testing can be added on to ThinPrep® specimens prior to 28 days after collection. UniSwab ThinPrep SurePath 70142 Atopobium vaginae 70142 Atopobium vaginae 70142 Atopobium vaginae 60135 Bacterial vaginosis panel 60135 Bacterial vaginosis panel 60135 Bacterial vaginosis panel (Mobiluncus mulieris and M. curtisii, Gardnerella (Mobiluncus mulieris and M. curtisii, Gardnerella (Mobiluncus mulieris and M. curtisii, Gardnerella vaginalis, Atopobium vaginae, Mycoplasma vaginalis, Atopobium vaginae, Mycoplasma vaginalis, Atopobium vaginae, Mycoplasma genitalium and hominis) genitalium and hominis) genitalium and hominis) 70125 Bacteroides fragilis 70125 Bacteroides fragilis 70125 Bacteroides fragilis 70164 BVAB2 70164 BVAB2 70164 BVAB2 70551 Candida albicans 70551 Candida albicans 70551 Candida albicans 70559 Candida glabrata 70559 Candida glabrata 70559 Candida glabrata 70561 Candida kefyr 70561 Candida kefyr 70561 Candida kefyr 70560 Candida krusei 70560 -

The Complete Genome Sequence of Mycobacterium Bovis
The complete genome sequence of Mycobacterium bovis Thierry Garnier*, Karin Eiglmeier*, Jean-Christophe Camus*†, Nadine Medina*, Huma Mansoor‡, Melinda Pryor*†, Stephanie Duthoy*, Sophie Grondin*, Celine Lacroix*, Christel Monsempe*, Sylvie Simon*, Barbara Harris§, Rebecca Atkin§, Jon Doggett§, Rebecca Mayes§, Lisa Keating‡, Paul R. Wheeler‡, Julian Parkhill§, Bart G. Barrell§, Stewart T. Cole*, Stephen V. Gordon‡¶, and R. Glyn Hewinson‡ *Unite´deGe´ne´ tique Mole´culaire Bacte´rienne and †PT4 Annotation, Ge´nopole, Institut Pasteur, 28 Rue du Docteur Roux, 75724 Paris Cedex 15, France; ‡Tuberculosis Research Group, Veterinary Laboratories Agency Weybridge, Woodham Lane, New Haw, Addlestone, Surrey KT15 3NB, United Kingdom; and §The Wellcome Trust Sanger Institute, Wellcome Trust Genome Campus, Hinxton, Cambridge CB10 1SA, United Kingdom Edited by John J. Mekalanos, Harvard Medical School, Boston, MA, and approved March 19, 2003 (received for review January 24, 2003) Mycobacterium bovis is the causative agent of tuberculosis in a The disease is caused by M. bovis, a Gram-positive bacillus range of animal species and man, with worldwide annual losses to with zoonotic potential that is highly genetically related to agriculture of $3 billion. The human burden of tuberculosis caused Mycobacterium tuberculosis, the causative agent of human tu- by the bovine tubercle bacillus is still largely unknown. M. bovis berculosis (5, 6). Although the human and bovine tubercle bacilli was also the progenitor for the M. bovis bacillus Calmette–Gue´rin can be differentiated by host range, virulence and physiological vaccine strain, the most widely used human vaccine. Here we features the genetic basis for these differences is unknown. M. describe the 4,345,492-bp genome sequence of M. -

EMBO Conference Takes to the Sea Life Sciences in Portugal
SUMMER 2013 ISSUE 24 encounters page 3 page 7 Life sciences in Portugal The limits of privacy page 8 EMBO Conference takes to the sea EDITORIAL Maria Leptin, Director of EMBO, INTERVIEW EMBO Associate Member Tom SPOTLIGHT Read about how the EMBO discusses the San Francisco Declaration Cech shares his views on science in Europe and Courses & Workshops Programme funds on Research Assessment and some of the describes some recent productive collisions. meetings for life scientists in Europe. concerns about Journal Impact Factors. PAGE 2 PAGE 5 PAGE 9 www.embo.org COMMENTARY INSIDE SCIENTIFIC PUBLISHING panels have to evaluate more than a hundred The San Francisco Declaration on applicants to establish a short list for in-depth assessment, they cannot be expected to form their views by reading the original publications Research Assessment of all of the applicants. I believe that the quality of the journal in More than 7000 scientists and 250 science organizations have by now put which research is published can, in principle, their names to a joint statement called the San Francisco Declaration on be used for assessment because it reflects how the expert community who is most competent Research Assessment (DORA; am.ascb.org/dora). The declaration calls to judge it views the science. There has always on the world’s scientific community to avoid misusing the Journal Impact been a prestige factor associated with the publi- Factor in evaluating research for funding, hiring, promotion, or institutional cation of papers in certain journals even before the impact factor existed. This prestige is in many effectiveness. -

November 2019 Volume 57 Issue 11 E00858-19 Journal of Clinical Microbiology Jcm.Asm.Org 1 Brown Et Al
BACTERIOLOGY crossm Pilot Evaluation of a Fully Automated Bioinformatics System for Analysis of Methicillin-Resistant Staphylococcus aureus Genomes and Detection of Outbreaks Nicholas M. Brown,a Beth Blane,b Kathy E. Raven,b Narender Kumar,b Danielle Leek,b Eugene Bragin,d Paul A. Rhodes,c Downloaded from David A. Enoch,a Rachel Thaxter,a Julian Parkhill,e Sharon J. Peacocka,b aClinical Microbiology and Public Health Laboratory, Cambridge University Hospitals NHS Foundation Trust, Cambridge, United Kingdom bDepartment of Medicine, University of Cambridge, Cambridge, United Kingdom cNext Gen Diagnostics, Mountain View, California, USA dNext Gen Diagnostics, Hinxton, United Kingdom eWellcome Sanger Institute, Hinxton, United Kingdom http://jcm.asm.org/ ABSTRACT Genomic surveillance that combines bacterial sequencing and epidemi- ological information will become the gold standard for outbreak detection, but its clinical translation is hampered by the lack of automated interpretation tools. We performed a prospective pilot study to evaluate the analysis of methicillin-resistant Staphylococcus aureus (MRSA) genomes using the Next Gen Diagnostics (NGD) auto- mated bioinformatics system. Seventeen unselected MRSA-positive patients were identified in a clinical microbiology laboratory in England over a period of 2 weeks in 2018, and 1 MRSA isolate per case was sequenced on the Illumina MiniSeq instru- on November 9, 2019 by guest ment. The NGD system automatically activated after sequencing and processed fastq folders to determine species, multilocus sequence type, the presence of a mec gene, antibiotic susceptibility predictions, and genetic relatedness based on mapping to a reference MRSA genome and detection of pairwise core genome single-nucleotide polymorphisms. The NGD system required 90 s per sample to automatically analyze data from each run, the results of which were automatically displayed. -

A Genomic Journey Through a Genus of Large DNA Viruses
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Virology Papers Virology, Nebraska Center for 2013 Towards defining the chloroviruses: a genomic journey through a genus of large DNA viruses Adrien Jeanniard Aix-Marseille Université David D. Dunigan University of Nebraska-Lincoln, [email protected] James Gurnon University of Nebraska-Lincoln, [email protected] Irina V. Agarkova University of Nebraska-Lincoln, [email protected] Ming Kang University of Nebraska-Lincoln, [email protected] See next page for additional authors Follow this and additional works at: https://digitalcommons.unl.edu/virologypub Part of the Biological Phenomena, Cell Phenomena, and Immunity Commons, Cell and Developmental Biology Commons, Genetics and Genomics Commons, Infectious Disease Commons, Medical Immunology Commons, Medical Pathology Commons, and the Virology Commons Jeanniard, Adrien; Dunigan, David D.; Gurnon, James; Agarkova, Irina V.; Kang, Ming; Vitek, Jason; Duncan, Garry; McClung, O William; Larsen, Megan; Claverie, Jean-Michel; Van Etten, James L.; and Blanc, Guillaume, "Towards defining the chloroviruses: a genomic journey through a genus of large DNA viruses" (2013). Virology Papers. 245. https://digitalcommons.unl.edu/virologypub/245 This Article is brought to you for free and open access by the Virology, Nebraska Center for at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Virology Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Authors Adrien Jeanniard, David D. Dunigan, James Gurnon, Irina V. Agarkova, Ming Kang, Jason Vitek, Garry Duncan, O William McClung, Megan Larsen, Jean-Michel Claverie, James L. Van Etten, and Guillaume Blanc This article is available at DigitalCommons@University of Nebraska - Lincoln: https://digitalcommons.unl.edu/ virologypub/245 Jeanniard, Dunigan, Gurnon, Agarkova, Kang, Vitek, Duncan, McClung, Larsen, Claverie, Van Etten & Blanc in BMC Genomics (2013) 14.