Improving Optical Character Recognition of Finnish Historical
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Optical Character Recognition - a Combined ANN/HMM Approach
Optical Character Recognition - A Combined ANN/HMM Approach Dissertation submitted to the Department of Computer Science Technical University of Kaiserslautern for the fulfillment of the requirements for the doctoral degree Doctor of Engineering (Dr.-Ing.) by Sheikh Faisal Rashid Dean: Prof. Dr. Klaus Schneider Thesis supervisors: Prof. Dr. Thomas Breuel, TU Kaiserslautern Prof. Dr. Andreas Dengel, TU Kaiserslautern Chair of supervisory committee: Prof. Dr. Karsten Berns, TU Kaiserslautern Kaiserslautern, 11 July, 2014 D 386 Abstract Optical character recognition (OCR) of machine printed text is ubiquitously considered as a solved problem. However, error free OCR of degraded (broken and merged) and noisy text is still challenging for modern OCR systems. OCR of degraded text with high accuracy is very important due to many applications in business, industry and large scale document digitization projects. This thesis presents a new OCR method for degraded text recognition by introducing a combined ANN/HMM OCR approach. The approach provides significantly better performance in comparison with state-of-the-art HMM based OCR methods and existing open source OCR systems. In addition, the thesis introduces novel applications of ANNs and HMMs for document image preprocessing and recognition of low resolution text. Furthermore, the thesis provides psychophysical experiments to determine the effect of letter permutation in visual word recognition of Latin and Cursive script languages. HMMs and ANNs are widely employed pattern recognition paradigms and have been used in numerous pattern classification problems. This work presents a simple and novel method for combining the HMMs and ANNs in application to segmentation free OCR of degraded text. HMMs and ANNs are powerful pattern recognition strategies and their combination is interesting to improve current state-of-the-art research in OCR. -

Cap Height Body X-Height Crossbar Terminal Counter Bowl Stroke Loop
Cap Height Body X-height -height is the distance between the -Cap height refers to the height of a -In typography, the body height baseline of a line of type and tops capital letter above the baseline for refers to the distance between the of the main body of lower case a particular typeface top of the tallest letterform to the letters (i.e. excluding ascenders or bottom of the lowest one. descenders). Crossbar Terminal Counter -In typography, the terminal is a In typography, the enclosed or par- The (usually) horizontal stroke type of curve. Many sources con- tially enclosed circular or curved across the middle of uppercase A sider a terminal to be just the end negative space (white space) of and H. It CONNECTS the ends and (straight or curved) of any stroke some letters such as d, o, and s is not cross over them. that doesn’t include a serif the counter. Bowl Stroke Loop -In typography, it is the curved part -Stroke of a letter are the lines that of a letter that encloses the circular make up the character. Strokes may A curving or doubling of a line so or curved parts (counter) of some be straight, as k,l,v,w,x,z or curved. as to form a closed or partly open letters such as d, b, o, D, and B is Other letter parts such as bars, curve within itself through which the bowl. arms, stems, and bowls are collec- another line can be passed or into tively referred to as the strokes that which a hook may be hooked make up a letterform Ascender Baseline Descnder In typography, the upward vertical Lowercases that extends or stem on some lowercase letters, such In typography, the baseline descends below the baselines as h and b, that extends above the is the imaginary line upon is the descender x-height is the ascender. -
INTRODUCTORY CONCEPTS Desktop Publishing Terms Overview
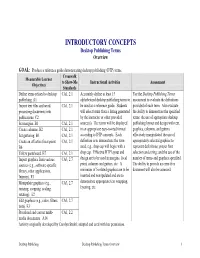
INTRODUCTORY CONCEPTS Desktop Publishing Terms Overview GOAL: Produce a reference guide demonstrating desktop publishing (DTP) terms. Crosswalk Measurable Learner to Show-Me Instructional Activities Assessment Objectives Standards Define terms related to desktop CA1, 2.1 Accurately define at least 15 Use the Desktop Publishing Terms publishing. A1 alphabetized desktop publishing terms to assessment to evaluate the definitions Import text files and word CA1, 2.1 be used as a reference guide. Students provided of each term. Also evaluate processing documents into will select terms from a listing generated the ability to demonstrate the specified publications. C2 by the instructor or other provided terms; the use of appropriate desktop Set margins. B1 CA1, 2.1 source(s). The terms will be displayed publishing layout and design with text, Create columns. B2 CA1, 2.1 in an appropriate easy-to-read format graphics, columns, and gutters Set guttering. B3 CA1, 2.1 according to DTP concepts. Each effectively manipulated; the use of Create an effective focal point. CA1, 2.1 definition is to demonstrate the term appropriately selected graphics to B6 used, e.g., drop cap will begin with a represent definitions; proper font Utilize pasteboard. B7 CA1, 2.1 drop cap. Effective DTP layout and selection and sizing; and the use of the Import graphics from various CA3, 2.7 design are to be used in margins, focal number of terms and graphics specified. sources (e.g., software-specific point, columns and gutters, etc. A The ability to provide an error-free library, other applications, minimum of 5 related graphics are to be document will also be assessed. -

Word 2010 Basics I
Microsoft Word Fonts [email protected] Microsoft Word Fonts 1.0 hours Format Font ............................................................................................. 3 Font Dialog Box ........................................................................................ 4 Effects ................................................................................................ 4 Set as Default… .................................................................................. 4 Text Effects .............................................................................................. 5 Format Text Effects Pane ................................................................... 6 Typography .............................................................................................. 7 Advanced Font Features .......................................................................... 8 Drop Cap ................................................................................................. 8 Symbols .................................................................................................... 9 Class Exercise ......................................................................................... 10 Exercise 1: Simple Font Formatting ................................................. 10 Exercise 2: Advanced Options .......................................................... 12 Exercise 3: Text Effects, Symbols, Superscript, Subscript ................ 13 Exercise 4: More Formats ............................................................... -

Path to a Baseline Proposal for Copper and Backplane PMD Clauses
November 2014 IEEE 802.3 25 Gb/s Ethernet Study Group 1 Path to a baseline proposal for copper and backplane PMD clauses Adee Ran Intel October 2014 November 2014 IEEE 802.3 25 Gb/s Ethernet Study Group 2 Introduction • This presentation aims at laying out the required components of a cable/backplane PMDs baseline proposal: • Suggested editorial structure • Technical components that require some work • Choices that do not seem obvious • The three objectives accepted by the study group in the September interim serve as the foundation: November 2014 IEEE 802.3 25 Gb/s Ethernet Study Group 3 General ideas • Assume a new clause will be created for a single-lane copper cable PMD • Refer back to clause 92 wherever appropriate • Assume a new clause will be created for a single-lane backplane PMD • Refer back to clause 93 wherever appropriate • Share structure and content between the backplane and cable PMD clauses where possible • Possible new concepts for the cable PMD: • More than one PMD “class” (exact definition has to be decided), so multiple electrical specifications • More than one loss budget, so multiple channel constructions • Choice of using FEC, possibly two FEC types, possibly different PCS encodings • Choice of MDIs Note: “class” used here temporarily until we decide on nomenclature (type, subtype, optional feature, or combinations ) November 2014 IEEE 802.3 25 Gb/s Ethernet Study Group 4 General structure – copper cable clause Subclauses of clause 92 (Boldface text means a possibly non-obvious change; strikethrough text means subclause can be omitted) 1. Overview 2. PMD service interface 3. -

Digital Desktop Publishing Course Code: 5176
DIGITAL DESKTOP PUBLISHING COURSE CODE: 5176 COURSE DESCRIPTION: This course brings together graphics and text to create professional level documents and publications. Students create, format, illustrate, design, edit/revise, and print publications. Improved productivity of digitally produced newsletters, flyers, brochures, reports, advertising materials, catalogs, and other publications is emphasized. OBJECTIVE: Given the necessary equipment, supplies, and facilities, the student will be able to successfully complete all of the following core competencies for a course granting one unit of credit. RECOMMENDED GRADE LEVELS: 10–12 COURSE CREDIT: 1 Carnegie unit PREREQUISITE: Computer Applications or Integrated Business Applications 1 RECOMMENDED SOFTWARE: Adobe InDesign COMPUTER REQUIREMENT: One computer per student OTHER APPLICABLE SOFTWARE: Adobe Illustrator, Adobe Photoshop, Microsoft Publisher, and Microsoft Word RESOURCES: www.mysctextbooks.com A. SAFETY 1. Review school safety policies and procedures. 2. Review classroom safety rules and procedures. 3. Review safety procedures for using equipment in the classroom. 4. Identify major causes of work-related accidents in office environments. 5. Demonstrate safety skills in an office/work environment. B. STUDENT ORGANIZATIONS 1. Identify the purpose and goals of a Career and Technology Student Organization (CTSO). 2. Explain how CTSOs are integral parts of specific clusters, majors, and/or courses. 3. Explain the benefits and responsibilities of being a member of a CTSO. 4. List leadership opportunities that are available to students through participation in CTSO conferences, competitions, community service, philanthropy, and other activities. October 2014 5. Explain how participation in CTSOs can promote lifelong benefits in other professional and civic organizations. C. TECHNOLOGY KNOWLEDGE 1. Demonstrate proficiency and skills associated with the use of technologies that are common to a specific occupation. -

A New Wave of Evidence: the Impact of School, Family, and Community
SEDL – Advancing Research, Improving Education A New Wave of Evidence The Impact of School, Family, and Community Connections on Student Achievement Annual Synthesis 2002 Anne T. Henderson Karen L. Mapp SEDL – Advancing Research, Improving Education A New Wave of Evidence The Impact of School, Family, and Community Connections on Student Achievement Annual Synthesis 2002 Anne T. Henderson Karen L. Mapp Contributors Amy Averett Deborah Donnelly Catherine Jordan Evangelina Orozco Joan Buttram Marilyn Fowler Margaret Myers Lacy Wood National Center for Family and Community Connections with Schools SEDL 4700 Mueller Blvd. Austin, Texas 78723 Voice: 512-476-6861 or 800-476-6861 Fax: 512-476-2286 Web site: www.sedl.org E-mail: [email protected] Copyright © 2002 by Southwest Educational Development Laboratory (SEDL). All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or any information storage and retrieval system, without permission in writing from SEDL or by submitting a copyright request form accessible at http://www.sedl.org/about/copyright_request.html on the SEDL Web site. This publication was produced in whole or in part with funds from the Institute of Education Sciences, U.S. Department of Education, under contract number ED-01-CO-0009. The content herein does not necessarily reflect the views of the U.S. Department of Education, or any other agency of the U.S. government, or any other source. To the late Susan McAllister Swap For more than 20 years, Sue worked tirelessly with both parents and edu- cators, exploring how to develop closer, richer, deeper partnerships. -

A Critical Guide for Designers, Writers, Editors, and Students
Type Anatomy anatomy caP height x-height baseline stem bowl serif descender ligature ascender finial terminal ascender sPine uPPercase small caPital cross bar counter lowercase 36 | thinking with tyPe cap height x-height baseline stem bowl serif descender ligature ascender finial visually sPeaking, baselines and x-heights determine the real edges of text ascender height caP height descender height Some elements may The distance from the The length of a letter’s extend slightly above baseline to the top of the descenders contributes the cap height. capital letter determines to its overall style and the letter’s point size. attitude. skin, Body x-height is the height of the the baseline is where all the overhang The curves at the main body of the lowercase letter letters sit. This is the most stable bottom of letters hang slightly (or the height of a lowercase x), axis along a line of text, and it below the baseline. Commas excluding its ascenders and is a crucial edge for aligning text and semicolons also cross the descenders. with images or with other text. baseline. If a typeface were not positioned this way, it would appear to teeter precariously. Without overhang, rounded letters would look smaller than Bone their flat-footed compatriots. Although kids learn to write using ruled paper that divides letters exactly in half, most typefaces are not designed that way. The x-height usually occupies more than half of the cap height. The Two blocks of text larger the x-height is in relation Hey, look! are often aligned along to the cap height, the bigger the They supersized a shared baseline. -

Calligraphy-Magic.Pdf
Calligraphy Magic How to Create Lettering, Knotwork, Coloring and More Cari Buziak Table of Contents Table of Contents Introduction Glossary of Terms CHAPTER 1 Calligraphy Tools and Supplies CHAPTER 2 How to Make Calligraphy Strokes CHAPTER 3 15 Alphabets From Basic to Fancy CHAPTER 4 Ornamentation, Gilding & Coloring CHAPTER 5 12 Calligraphy Projects Step by Step STATIONERY AND EVENT ANNOUNCEMENTS Bookplates Greeting Cards Bookmarks Logos Business Cards and Letterhead Wedding Announcements Invitations Place Cards and Thank-You’s DISPLAY PIECES Monograms Quotations Certifi cates Lettering with Celtic Decoration Illustrated Poems Lettering with Dragon Artwork CHAPTER 6 Creating Your Own Computer Fonts Pre-printed Celtic Knotwork Grid Paper Pre-ruled Calligraphy Practice Pages Index About the Author Dedication Acknowledgments Introduction Introduction Calligraphy is a fun craft to learn, as well as a useful one. Far from being an obsolete skill, more and more people today are picking up the pen and creating their own greeting cards, wedding invitations, fine art projects, and even creating their own computer fonts! In the old days, calligraphy tools were unique and specically crafted to their task. Today, a calligrapher has a wide variety of tools from which to choose, from traditional to completely modern, even digital! Calligraphers can now experiment with their artistic expression, freely mixing creative ideas and elements together to explore new artforms with their projects. In this book we’ll examine the basic techniques of calligraphy, covering calligraphy hands suitable for a wide variety of projects and easy for a beginner or intermediate calligrapher to practice and learn. We’ll also cover easy decorative techniques such as watercolor painting, Celtic knotwork, gold leang and illustration ideas to create a “toolkit” of creative techniques. -

Type Anatomy Type Classifications Type Height Measurements
California State University, Sacramento Department of Design College of Arts and Letters fall 2014 course # and title: GPHD 130 Typography II Instructor: John P. Forrest Jr. Type Classifications Type Anatomy Type Height Measurements California State University, Sacramento Department of Design College of Arts and Letters fall 2014 course # and title: GPHD 130 Typography II Instructor: John P. Forrest Jr. Terms Ascender Kerning Stroke on a lowercase letter that rises above the meanline. In typesetting, the process of subtracting space between spe- cific pairs of characters so that the overall letterspacing appears Baseline to be even. An imaginary horizontal line upon which the base of each capital letter rests. Leading In early typesetting, strips of lead were placed between lines of Cap height type for spacing, hence the term. The vertical distance between Height of the capital letters, measured from the baseline to the two lines of type measured from baseline to baseline. capline. Meanline Capline An imaginary line marking the tops of lowercase letters, not Imaginary horizontal line defined by the height of the including the ascenders. capital letters. Pica Counter Typographic unit of measurement: 12 points equal 1 pica. Six Space enclosed by the strokes of a letter form picas equal approximately one inch. Line lengths and column widths are sometimes measured in picas. Descender Stroke on a lowercase letter form that falls below the baseline. Point A measure of size used principally in typesetting. One point is Display type equal to 1/12 of a pica, or approximately 1/72 or an inch. It is Type sizes 14 point and above, used primarily for headlines and most often used to indicate the size of type or amount of lead- titles. -

Baseline Documentation Release 1.2.1
baseline Documentation Release 1.2.1 Dan Gass Dec 26, 2020 Contents 1 Quick Start 3 1.1 [baseline] About.............................................4 1.2 [baseline] API Reference.........................................5 1.3 [baseline] Installation..........................................5 1.4 [baseline] Release Notes.........................................6 1.5 [baseline] Usage.............................................8 Index 11 i ii baseline Documentation, Release 1.2.1 This tool streamlines creation and maintenance of tests which compare string output against a baseline. It offers a mechanism to compare a string against a baselined copy and update the baselined copy to match the new value when a mismatch occurs. The update process includes a manual step to facilitate a review of the change before acceptance. The tool uses multi-line string format for string baselines to improve readability for human review. Contents 1 baseline Documentation, Release 1.2.1 2 Contents CHAPTER 1 Quick Start Create an empty baseline with a triple quoted multi-line string. Place the ending triple quote on a separate line and indent it to the level you wish the string baseline update to be indented to. Add a compare of the string being tested to the baseline string. Then save the file as fox.py: from baseline import Baseline expected= Baseline(""" """) test_string= """THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG.""" assert test_string == expected Run fox.py and observe that the assert raises an exception since the strings are not equal. Because the comparison failed, the tool located the triple quoted baseline string in the source file and updated it with the mis-compared value. When the interpreter exited, the tool saved the updated source file but changed the file name to fox.py.update: from baseline import Baseline expected= Baseline(""" THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG. -

Font Features for Andika
Font Features for Andika When Andika is used in applications that support Graphite, and that provide an appropriate user interface, various user-controllable font features are available that allow access to alternatively-designed glyphs that might be preferable for use in some contexts. In LibreOffice 3.4.2+ (http://www.libreoffice.org/download/) or OpenOffice 3.2+ (http://www.openoffice.org/download/) the font features can be turned on by choosing the font (ie Andika), followed by a colon, followed by the feature ID, and then followed by the feature setting. So, for example, if the Uppercase eng alternate “Capital N with tail” is desired, the font selection would be “Andika:Engs=2”. (The Graphite feature IDs have changed. If you already have documents which specify the Graphite feature IDs as digits, you will need to change from digits to text. Both are documented in the table below. We are very sorry for the inconvenience.) If you wish to apply two (or more) features, you can separate them with an “&”. Thus, “Andika:Engs=2&smcp=1” would apply “Capital N with tail” plus the “Small capitals” feature. These same features are also available in OpenType. The OpenType feature IDs (“cvxx” for “Character Variant” and “ssxx” for “Stylistic Set”) are listed in the OpenType feature ID column. However, they are only available in a few applications. Mozilla Firefox (https://www.mozilla.org/firefox) is the only application that currently supports Character Variants. Adobe InDesign, Microsoft Word, Microsoft Publisher and Mozilla Firefox support Stylistic Sets. A glyph palette is available for accessing the alternate glyphs in some applications such as Adobe InDesign.