“Economics of News Aggregators"
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Groupwise Mobility Quick Start for Microsoft Outlook Users
GroupWise Mobility Quick Start for Microsoft Outlook Users August 2016 GroupWise Mobility Service 2014 R2 allows the Microsoft Outlook client for Windows to run against a GroupWise backend via Microsoft ActiveSync 14.1 protocol. This document helps you set up your Outlook client to access your GroupWise account and provides known limitations you should be aware of while using Outlook against GroupWise. Supported Microsoft Outlook Clients CREATING THE GROUPWISE PROFILE MANUALLY Microsoft Outlook 2013 or 21016 for Windows 1 On the machine, open Control Panel > User Accounts and Family Safety. Microsoft Outlook Mobile App Adding a GroupWise Account to the Microsoft Outlook Client You must configure the Microsoft Outlook client in order to access your GroupWise account. The following instructions assume that the Outlook client is already installed on your machine. You can use the GroupWise Profile Setup utility to set the profile up automatically or you can manually create the GroupWise profile for Outlook. Using the GroupWise Profile Setup Utility Creating the GroupWise Profile Manually 2 Click Mail. 3 (Conditional) If a Mail Setup dialog box is displayed, USING THE GROUPWISE PROFILE SETUP UTILITY click Show Profiles to display the Mail dialog box. You must first obtain a copy of the GWProfileSetup.zip from If GroupWise is installed on the machine, the Profiles your system administrator before following the steps below list includes a GroupWise profile, as shown in the to create the profile on your workstation. following screenshot. You need to keep this profile and create a new profile. 1 Extract the GWProfileSetup.zip to a temporary location on your workstation. -

Virtual Planetary Space Weather Services Offered by the Europlanet H2020 Research Infrastructure
Article PSS PSWS deadline 15/11 Virtual Planetary Space Weather Services offered by the Europlanet H2020 Research Infrastructure N. André1, M. Grande2, N. Achilleos3, M. Barthélémy4, M. Bouchemit1, K. Benson3, P.-L. Blelly1, E. Budnik1, S. Caussarieu5, B. Cecconi6, T. Cook2, V. Génot1, P. Guio3, A. Goutenoir1, B. Grison7, R. Hueso8, M. Indurain1, G. H. Jones9,10, J. Lilensten4, A. Marchaudon1, D. Matthiäe11, A. Opitz12, A. Rouillard1, I. Stanislawska13, J. Soucek7, C. Tao14, L. Tomasik13, J. Vaubaillon6 1Institut de Recherche en Astrophysique et Planétologie, CNRS, Université Paul Sabatier, Toulouse, France ([email protected]) 2Department of Physics, Aberystwyth University, Wales, UK 3University College London, London, UK 4Institut de Planétologie et d'Astrophysique de Grenoble, UGA/CNRS-INSU, Grenoble, France 5GFI Informatique, Toulouse, France 6LESIA, Observatoire de Paris, CNRS, UPMC, University Paris Diderot, Meudon, France 7Institute of Atmospheric Physics (IAP), Czech Academy of Science, Prague, Czech Republic 8Departamento de Física Aplicada I, Escuela de Ingeniería de Bilbao, Universidad del País Vasco UPV /EHU, Bilbao, Spain 9Mullard Space Science Laboratory, University College London, Holmbury Saint Mary, UK 10The Centre for Planetary Sciences at UCL/Birkbeck, London, UK 11German Aerospace Center (DLR), Institute of Aerospace Medicine, Linder Höhe, 51147 Cologne, Germany 12Wigner Research Centre for Physics, Budapest, Hungary 13Space Research Centre, Polish Academy of Sciences, Warsaw, Poland 14National Institute of Information -

Netscape 6.2.3 Software for Solaris Operating Environment
What’s New in Netscape 6.2 Netscape 6.2 builds on the successful release of Netscape 6.1 and allows you to do more online with power, efficiency and safety. New is this release are: Support for the latest operating systems ¨ BETTER INTEGRATION WITH WINDOWS XP q Netscape 6.2 is now only one click away within the Windows XP Start menu if you choose Netscape as your default browser and mail applications. Also, you can view the number of incoming email messages you have from your Windows XP login screen. ¨ FULL SUPPORT FOR MACINTOSH OS X Other enhancements Netscape 6.2 offers a more seamless experience between Netscape Mail and other applications on the Windows platform. For example, you can now easily send documents from within Microsoft Word, Excel or Power Point without leaving that application. Simply choose File, “Send To” to invoke the Netscape Mail client to send the document. What follows is a more comprehensive list of the enhancements delivered in Netscape 6.1 CONFIDENTIAL UNTIL AUGUST 8, 2001 Netscape 6.1 Highlights PR Contact: Catherine Corre – (650) 937-4046 CONFIDENTIAL UNTIL AUGUST 8, 2001 Netscape Communications Corporation ("Netscape") and its licensors retain all ownership rights to this document (the "Document"). Use of the Document is governed by applicable copyright law. Netscape may revise this Document from time to time without notice. THIS DOCUMENT IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND. IN NO EVENT SHALL NETSCAPE BE LIABLE FOR INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES OF ANY KIND ARISING FROM ANY ERROR IN THIS DOCUMENT, INCLUDING WITHOUT LIMITATION ANY LOSS OR INTERRUPTION OF BUSINESS, PROFITS, USE OR DATA. -

Guide to Customizing and Distributing Netscape 7.0
Guide to Customizing and Distributing Netscape 7.0 28 August 2002 Copyright © 2002 Netscape Communications Corporation. All rights reserved. Netscape and the Netscape N logo are registered trademarks of Netscape Communications Corporation in the U.S. and other countries. Other Netscape logos, product names, and service names are also trademarks of Netscape Communications Corporation, which may be registered in other countries. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation. No part of the product or this document may be reproduced in any form by any means without prior written authorization of Netscape and its licensors, if any. THIS DOCUMENTATION IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. Contents Preface . 9 Who Should Read This Guide . 10 About the CCK Tool . 10 If You've Used a Previous Version of CCK . 11 Using Existing Customized Files . 12 How to Use This Guide . 13 Where to Go for Related Information . 15 Chapter 1 Getting Started . 17 Why Customize and Distribute Netscape? . 18 Why Do Users Prefer Netscape 7.0? . 18 Overview of the Customization and Distribution Process . 20 System Requirements . 23 Platform Support . 25 Installing the Client Customization Kit Tool . 26 What Customizations Can I Make? . 27 Netscape Navigator Customizations . 27 Mail and News Customizations . 32 CD Autorun Screen Customizations . 32 Installer Customizations . 33 Customization Services Options . 34 Which Customizations Can I Make Quickly? . -
Instant Messaging Video Converter, Iphone Converter Application
Web Browsing Mozilla Firefox The premier free, open-source browser. Tabs, pop-up blocking, themes, and extensions. Considered by many to be the world's best browser. Download Page Video Player, Torrents, Podcasting Miro Beautiful interface. Plays any video type (much more than quicktime). Subscribe to video RSS, download, and watch all in one. Torrent support. Search and download from YouTube and others. Download Page IM - Instant Messaging Adium Connect to multiple IM accounts simultaneously in a single app, including: AOL IM, MSN, and Jabber. Beautiful, themable interface. Download Page Video Converter, iPhone Converter Miro Video Converter Convert any type of video to mp4 or theora. Convert any video for use with iPhone, iPod, Android, etc. Very clean, easy to use interface. Download Page Application Launching Quicksilver Quicksilver lets you start applications (and do just about everything) with a few quick taps of your fingers. Warning: start using Quicksilver and you won't be able to imagine using a Mac without it. Download Page Email Mozilla Thunderbird Powerful spam filtering, solid interface, and all the features you need. Download Page Utilities The Unarchiver Uncompress RAR, 7zip, tar, and bz2 files on your Mac. Many new Mac users will be puzzled the first time they download a RAR file. Do them a favor and download UnRarX for them! Download Page DVD Ripping Handbrake DVD ripper and MPEG-4 / H.264 encoding. Very simple to use. Download Page RSS Vienna Very nice, native RSS client. Download Page RSSOwl Solid cross-platform RSS client. Download Page Peer-to-Peer Filesharing Cabos A simple, easy to use filesharing program. -

Specifications for Implementing Web Feeds in DLXS Kevin S
Hawkins 1/5/2011 5:01:52 PM Page 1 of 5 * SCHOLARLY PUBLISHING OFFICE WHITEPAPER Specifications for implementing web feeds in DLXS Kevin S. Hawkins Executive Summary SPO uses DLXS to deliver nearly all of its publications online, but this software does not offer any functionality for web feeds (commonly called RSS feeds). The components of web feeds are reviewed, and recommendations are made for implementing Atom 1.0 web feeds in SPO publications using a script run during releasing which determines which content to push to the feed. Motivations Members of the editorial board of the Journal of Electronic Publishing (collid jep) and SPO staff have requested that web feed functionality be provided for SPO publications. This would allow end users to subscribe to feeds of not only serial content (the obvious use) but in theory any other collection to which content is added, especially on a regular basis. A feed could provide a single notice that a collection has been updated, perhaps with a table of contents (henceforth a small feed), or instead contain separate notices for each item added to the collection (a large feed). Components of a web feed A web feed operates with three necessary components: • a website that syndicates (or publishes) a feed • a feed standard being used by the website • the end user’s news aggregator (feed reader or news reader), which retrieves the feed periodically. A feed is an XML document containing individual entries (also items, stories, or articles). Syndicating a feed The content provider’s website often has buttons (icons called chicklets) to be used by the end user to add a feed to his or her news aggregator. -

Development of Information System for Aggregation and Ranking of News Taking Into Account the User Needs
Development of Information System for Aggregation and Ranking of News Taking into Account the User Needs Vasyl Andrunyk[0000-0003-0697-7384]1, Andrii Vasevych[0000-0003-4338-107X]2, Liliya Chyrun[0000-0003-4040-7588]3, Nadija Chernovol[0000-0001-9921-9077]4, Nataliya Antonyuk[0000- 0002-6297-0737]5, Aleksandr Gozhyj[0000-0002-3517-580X]6, Victor Gozhyj7, Irina Kalinina[0000- 0001-8359-2045]8, Maksym Korobchynskyi[0000-0001-8049-4730]9 1-4Lviv Polytechnic National University, Lviv, Ukraine 5Ivan Franko National University of Lviv, Lviv, Ukraine 5University of Opole, Opole, Poland 6-8Petro Mohyla Black Sea National University, Nikolaev, Ukraine 9Military-Diplomatic Academy named after Eugene Bereznyak, Kyiv, Ukraine [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] Abstract. The purpose of the work is to develop an intelligent information sys- tem that is designed for aggregation and ranking of news taking into account the needs of the user. During the work, the following tasks are set: 1) Analyze the online market for mass media and the needs of readers; the pur- pose of their searches and moments is not enough to find the news. 2) To construct a conceptual model of the information aggression system and ranking of news that would enable presentation of the work of the future intel- lectual information system, to show its structure. 3) To select the methods and means for implementation of the intellectual in- formation system. -
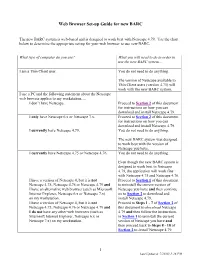
Web Browser Set-Up Guide for New BARC
Web Browser Set-up Guide for new BARC The new BARC system is web-based and is designed to work best with Netscape 4.79. Use the chart below to determine the appropriate set-up for your web browser to use new BARC. What type of computer do you use? What you will need to do in order to use the new BARC system… I am a Thin Client user. You do not need to do anything. The version of Netscape available to Thin Client users (version 4.75) will work with the new BARC system. I use a PC and the following statement about the Netscape web browser applies to my workstation…. I don’t have Netscape. Proceed to Section 2 of this document for instructions on how you can download and install Netscape 4.79. I only have Netscape 6.x or Netscape 7.x. Proceed to Section 2 of this document for instructions on how you can download and install Netscape 4.79. I currently have Netscape 4.79. You do not need to do anything. The new BARC system was designed to work best with the version of Netscape you have. I currently have Netscape 4.75 or Netscape 4.76. You do not need to do anything. Even though the new BARC system is designed to work best in Netscape 4.79, the application will work fine with Netscape 4.75 and Netscape 4.76. I have a version of Netscape 4, but it is not Proceed to Section 1 of this document Netscape 4.75, Netscape 4.76 or Netscape 4.79 and to uninstall the current version of I have an alternative web browser (such as Microsoft Netscape you have and then continue Internet Explorer, Netscape 6.x or Netscape 7.x) on to Section 2 to download and on my workstation. -

EMERGING TECHNOLOGIES Skype and Podcasting: Disruptive Technologies for Language Learning
Language Learning & Technology September 2005, Volume 9, Number 3 http://llt.msu.edu/vol9num3/emerging/ pp. 9-12 EMERGING TECHNOLOGIES Skype and Podcasting: Disruptive Technologies for Language Learning Robert Godwin-Jones Virginia Comonwealth University New technologies, or new uses of existing technologies, continue to provide unique opportunities for language learning. This is in particular the case for several new network options for oral language practice. Both Skype and podcasting can be considered "disruptive technologies" in that they allow for new and different ways of doing familiar tasks, and in the process, may threaten traditional industries. Skype, the "people's telephone," is a free, Internet-based alternative to commercial phone service, while podcasting, the "radio for the people," provides a "narrowcasting" version of broadcast media. Both have sparked intense interest and have large numbers of users, although it is too soon to toll the bell for telephone companies and the radio industry. Skype and podcasting have had a political aspect to their embrace by early adopters -- a way of democratizing institutions -- but as they reach the mainstream, that is likely to become less important than the low cost and convenience the technologies offer. Both technologies offer intriguing opportunities for language professionals and learners, as they provide additional channels for oral communication. Skype and Internet Telephony Skype is a software product which provides telephone service through VoIP (Voice over IP), allowing your personal computer to act like a telephone. A microphone attached to the computer is necessary and headphones are desirable (to prevent echoes of the voice of your conversation partner). It is not the only such tool, nor the first, but because it provides good quality (through highly efficient compression) and is free, it has become widely used. -
Web 2.0: Beyond the Concept Practical Ways to Implement RSS, Podcasts, and Wikis
Web 2.0: Beyond the Concept Practical Ways to Implement RSS, Podcasts, and Wikis By Karen Huffman, National Geographic Society Abstract This article focuses on how the National Geographic Society’s Libraries & Information Services has implemented RSS, podcasts and wikis with suggested practical application for academic libraries. The article is an adaptation from a presentation given during the Special Libraries Association’s Annual Conference, June 2006 (Huffman & Ferry, 2006). The Sparks That Ignited Us…. National Geographic’s Libraries & Information Services (LIS) discovery and implementation of technologies dubbed “Web 2.0” has been an evolutionary, rather than revolutionary process. We watched the trends to evolve our products and services. In 2005 we began seeing online news sources like BBCnews.com offering alternative ways to access their content. New RSS-labeled icons appeared in the margins of websites with links to directories of feeds. These RSS directories generally organized their feeds either topically or by news section and often included frequently asked questions about RSS as well as recommended feed readers. As information organizers (and multi-taskers who streamline their work processes wherever possible), we initially saw RSS feeds as a way to keep current with news sources, blogs, and research sites that were regularly publishing content through XML-based feeds! We saw the arrival of podcasts on the heels of RSS. In January and February, 2005, the Pew Internet and American Life Project conducted a survey, and found 22 million, or 11%, Americans age 18 or older owned an iPod or MP3 player. Apple’s freely-available iTunes library brought podcasting to the mainstream with the launch of its “Podcasts” directory in June 2005. -

Working with Feeds, RSS, and Atom
CHAPTER 4 Working with Feeds, RSS, and Atom A fundamental enabling technology for mashups is syndication feeds, especially those packaged in XML. Feeds are documents used to transfer frequently updated digital content to users. This chapter introduces feeds, focusing on the specific examples of RSS and Atom. RSS and Atom are arguably the most widely used XML formats in the world. Indeed, there’s a good chance that any given web site provides some RSS or Atom feed—even if there is no XML-based API for the web site. Although RSS and Atom are the dominant feed format, other formats are also used to create feeds: JSON, PHP serialization, and CSV. I will also cover those formats in this chapter. So, why do feeds matter? Feeds give you structured information from applications that is easy to parse and reuse. Not only are feeds readily available, but there are many applications that use those feeds—all requiring no or very little programming effort from you. Indeed, there is an entire ecology of web feeds (the data formats, applications, producers, and consumers) that provides great potential for the remix and mashup of information—some of which is starting to be realized today. This chapter covers the following: * What feeds are and how they are used * The semantics and syntax of feeds, with a focus on RSS 2.0, RSS 1.0, and Atom 1.0 * The extension mechanism of RSS 2.0 and Atom 1.0 * How to get feeds from Flickr and other feed-producing applications and web sites * Feed formats other than RSS and Atom in the context of Flickr feeds * How feed autodiscovery can be used to find feeds * News aggregators for reading feeds and tools for validating and scraping feeds * How to remix and mashup feeds with Feedburner and Yahoo! Pipes Note In this chapter, I assume you have an understanding of the basics of XML, including XML namespaces and XML schemas. -

Aggravated with Aggregators: Can International Copyright Law Help Save the News Room?
Emory International Law Review Volume 26 Issue 2 2012 Aggravated with Aggregators: Can International Copyright Law Help Save the News Room? Alexander Weaver Follow this and additional works at: https://scholarlycommons.law.emory.edu/eilr Recommended Citation Alexander Weaver, Aggravated with Aggregators: Can International Copyright Law Help Save the News Room?, 26 Emory Int'l L. Rev. 1161 (2012). Available at: https://scholarlycommons.law.emory.edu/eilr/vol26/iss2/19 This Comment is brought to you for free and open access by the Journals at Emory Law Scholarly Commons. It has been accepted for inclusion in Emory International Law Review by an authorized editor of Emory Law Scholarly Commons. For more information, please contact [email protected]. WEAVER GALLEYSPROOFS1 5/2/2013 9:30 AM AGGRAVATED WITH AGGREGATORS: CAN INTERNATIONAL COPYRIGHT LAW HELP SAVE THE NEWSROOM? INTRODUCTION The creation of the World Wide Web was based on a concept of universality that would allow a link to connect to anywhere on the Internet.1 Although the Internet has transformed from a technical luxury into an indispensable tool in today’s society, this concept of universality remains. Internet users constantly click from link to link as they explore the rich tapestry of the World Wide Web to view current events, research, media, and more. Yet, few Internet users pause their daily online activity to think of the legal consequences of these actions.2 Recent Internet censorship measures intended to prevent illegal downloading, such as the proposed Stop Online Piracy Act (“SOPA”), have been at the forefront of the public’s attention due to fears of legislative limits on online free speech and innovation.3 However, the more common activity of Internet linking also creates the potential for legal liability 1 See Tim Berners-Lee, Realising the Full Potential of the Web, 46 TECHNICAL COMM.