Development of Information System for Aggregation and Ranking of News Taking Into Account the User Needs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Groupwise Mobility Quick Start for Microsoft Outlook Users
GroupWise Mobility Quick Start for Microsoft Outlook Users August 2016 GroupWise Mobility Service 2014 R2 allows the Microsoft Outlook client for Windows to run against a GroupWise backend via Microsoft ActiveSync 14.1 protocol. This document helps you set up your Outlook client to access your GroupWise account and provides known limitations you should be aware of while using Outlook against GroupWise. Supported Microsoft Outlook Clients CREATING THE GROUPWISE PROFILE MANUALLY Microsoft Outlook 2013 or 21016 for Windows 1 On the machine, open Control Panel > User Accounts and Family Safety. Microsoft Outlook Mobile App Adding a GroupWise Account to the Microsoft Outlook Client You must configure the Microsoft Outlook client in order to access your GroupWise account. The following instructions assume that the Outlook client is already installed on your machine. You can use the GroupWise Profile Setup utility to set the profile up automatically or you can manually create the GroupWise profile for Outlook. Using the GroupWise Profile Setup Utility Creating the GroupWise Profile Manually 2 Click Mail. 3 (Conditional) If a Mail Setup dialog box is displayed, USING THE GROUPWISE PROFILE SETUP UTILITY click Show Profiles to display the Mail dialog box. You must first obtain a copy of the GWProfileSetup.zip from If GroupWise is installed on the machine, the Profiles your system administrator before following the steps below list includes a GroupWise profile, as shown in the to create the profile on your workstation. following screenshot. You need to keep this profile and create a new profile. 1 Extract the GWProfileSetup.zip to a temporary location on your workstation. -

Virtual Planetary Space Weather Services Offered by the Europlanet H2020 Research Infrastructure
Article PSS PSWS deadline 15/11 Virtual Planetary Space Weather Services offered by the Europlanet H2020 Research Infrastructure N. André1, M. Grande2, N. Achilleos3, M. Barthélémy4, M. Bouchemit1, K. Benson3, P.-L. Blelly1, E. Budnik1, S. Caussarieu5, B. Cecconi6, T. Cook2, V. Génot1, P. Guio3, A. Goutenoir1, B. Grison7, R. Hueso8, M. Indurain1, G. H. Jones9,10, J. Lilensten4, A. Marchaudon1, D. Matthiäe11, A. Opitz12, A. Rouillard1, I. Stanislawska13, J. Soucek7, C. Tao14, L. Tomasik13, J. Vaubaillon6 1Institut de Recherche en Astrophysique et Planétologie, CNRS, Université Paul Sabatier, Toulouse, France ([email protected]) 2Department of Physics, Aberystwyth University, Wales, UK 3University College London, London, UK 4Institut de Planétologie et d'Astrophysique de Grenoble, UGA/CNRS-INSU, Grenoble, France 5GFI Informatique, Toulouse, France 6LESIA, Observatoire de Paris, CNRS, UPMC, University Paris Diderot, Meudon, France 7Institute of Atmospheric Physics (IAP), Czech Academy of Science, Prague, Czech Republic 8Departamento de Física Aplicada I, Escuela de Ingeniería de Bilbao, Universidad del País Vasco UPV /EHU, Bilbao, Spain 9Mullard Space Science Laboratory, University College London, Holmbury Saint Mary, UK 10The Centre for Planetary Sciences at UCL/Birkbeck, London, UK 11German Aerospace Center (DLR), Institute of Aerospace Medicine, Linder Höhe, 51147 Cologne, Germany 12Wigner Research Centre for Physics, Budapest, Hungary 13Space Research Centre, Polish Academy of Sciences, Warsaw, Poland 14National Institute of Information -

Netscape 6.2.3 Software for Solaris Operating Environment
What’s New in Netscape 6.2 Netscape 6.2 builds on the successful release of Netscape 6.1 and allows you to do more online with power, efficiency and safety. New is this release are: Support for the latest operating systems ¨ BETTER INTEGRATION WITH WINDOWS XP q Netscape 6.2 is now only one click away within the Windows XP Start menu if you choose Netscape as your default browser and mail applications. Also, you can view the number of incoming email messages you have from your Windows XP login screen. ¨ FULL SUPPORT FOR MACINTOSH OS X Other enhancements Netscape 6.2 offers a more seamless experience between Netscape Mail and other applications on the Windows platform. For example, you can now easily send documents from within Microsoft Word, Excel or Power Point without leaving that application. Simply choose File, “Send To” to invoke the Netscape Mail client to send the document. What follows is a more comprehensive list of the enhancements delivered in Netscape 6.1 CONFIDENTIAL UNTIL AUGUST 8, 2001 Netscape 6.1 Highlights PR Contact: Catherine Corre – (650) 937-4046 CONFIDENTIAL UNTIL AUGUST 8, 2001 Netscape Communications Corporation ("Netscape") and its licensors retain all ownership rights to this document (the "Document"). Use of the Document is governed by applicable copyright law. Netscape may revise this Document from time to time without notice. THIS DOCUMENT IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND. IN NO EVENT SHALL NETSCAPE BE LIABLE FOR INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES OF ANY KIND ARISING FROM ANY ERROR IN THIS DOCUMENT, INCLUDING WITHOUT LIMITATION ANY LOSS OR INTERRUPTION OF BUSINESS, PROFITS, USE OR DATA. -

Guide to Customizing and Distributing Netscape 7.0
Guide to Customizing and Distributing Netscape 7.0 28 August 2002 Copyright © 2002 Netscape Communications Corporation. All rights reserved. Netscape and the Netscape N logo are registered trademarks of Netscape Communications Corporation in the U.S. and other countries. Other Netscape logos, product names, and service names are also trademarks of Netscape Communications Corporation, which may be registered in other countries. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation. No part of the product or this document may be reproduced in any form by any means without prior written authorization of Netscape and its licensors, if any. THIS DOCUMENTATION IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. Contents Preface . 9 Who Should Read This Guide . 10 About the CCK Tool . 10 If You've Used a Previous Version of CCK . 11 Using Existing Customized Files . 12 How to Use This Guide . 13 Where to Go for Related Information . 15 Chapter 1 Getting Started . 17 Why Customize and Distribute Netscape? . 18 Why Do Users Prefer Netscape 7.0? . 18 Overview of the Customization and Distribution Process . 20 System Requirements . 23 Platform Support . 25 Installing the Client Customization Kit Tool . 26 What Customizations Can I Make? . 27 Netscape Navigator Customizations . 27 Mail and News Customizations . 32 CD Autorun Screen Customizations . 32 Installer Customizations . 33 Customization Services Options . 34 Which Customizations Can I Make Quickly? . -
Instant Messaging Video Converter, Iphone Converter Application
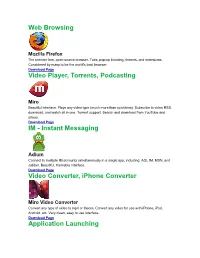
Web Browsing Mozilla Firefox The premier free, open-source browser. Tabs, pop-up blocking, themes, and extensions. Considered by many to be the world's best browser. Download Page Video Player, Torrents, Podcasting Miro Beautiful interface. Plays any video type (much more than quicktime). Subscribe to video RSS, download, and watch all in one. Torrent support. Search and download from YouTube and others. Download Page IM - Instant Messaging Adium Connect to multiple IM accounts simultaneously in a single app, including: AOL IM, MSN, and Jabber. Beautiful, themable interface. Download Page Video Converter, iPhone Converter Miro Video Converter Convert any type of video to mp4 or theora. Convert any video for use with iPhone, iPod, Android, etc. Very clean, easy to use interface. Download Page Application Launching Quicksilver Quicksilver lets you start applications (and do just about everything) with a few quick taps of your fingers. Warning: start using Quicksilver and you won't be able to imagine using a Mac without it. Download Page Email Mozilla Thunderbird Powerful spam filtering, solid interface, and all the features you need. Download Page Utilities The Unarchiver Uncompress RAR, 7zip, tar, and bz2 files on your Mac. Many new Mac users will be puzzled the first time they download a RAR file. Do them a favor and download UnRarX for them! Download Page DVD Ripping Handbrake DVD ripper and MPEG-4 / H.264 encoding. Very simple to use. Download Page RSS Vienna Very nice, native RSS client. Download Page RSSOwl Solid cross-platform RSS client. Download Page Peer-to-Peer Filesharing Cabos A simple, easy to use filesharing program. -
Web Browser Set-Up Guide for New BARC
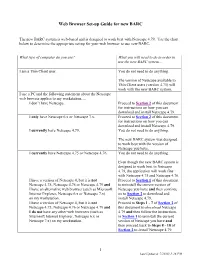
Web Browser Set-up Guide for new BARC The new BARC system is web-based and is designed to work best with Netscape 4.79. Use the chart below to determine the appropriate set-up for your web browser to use new BARC. What type of computer do you use? What you will need to do in order to use the new BARC system… I am a Thin Client user. You do not need to do anything. The version of Netscape available to Thin Client users (version 4.75) will work with the new BARC system. I use a PC and the following statement about the Netscape web browser applies to my workstation…. I don’t have Netscape. Proceed to Section 2 of this document for instructions on how you can download and install Netscape 4.79. I only have Netscape 6.x or Netscape 7.x. Proceed to Section 2 of this document for instructions on how you can download and install Netscape 4.79. I currently have Netscape 4.79. You do not need to do anything. The new BARC system was designed to work best with the version of Netscape you have. I currently have Netscape 4.75 or Netscape 4.76. You do not need to do anything. Even though the new BARC system is designed to work best in Netscape 4.79, the application will work fine with Netscape 4.75 and Netscape 4.76. I have a version of Netscape 4, but it is not Proceed to Section 1 of this document Netscape 4.75, Netscape 4.76 or Netscape 4.79 and to uninstall the current version of I have an alternative web browser (such as Microsoft Netscape you have and then continue Internet Explorer, Netscape 6.x or Netscape 7.x) on to Section 2 to download and on my workstation. -

Aggravated with Aggregators: Can International Copyright Law Help Save the News Room?
Emory International Law Review Volume 26 Issue 2 2012 Aggravated with Aggregators: Can International Copyright Law Help Save the News Room? Alexander Weaver Follow this and additional works at: https://scholarlycommons.law.emory.edu/eilr Recommended Citation Alexander Weaver, Aggravated with Aggregators: Can International Copyright Law Help Save the News Room?, 26 Emory Int'l L. Rev. 1161 (2012). Available at: https://scholarlycommons.law.emory.edu/eilr/vol26/iss2/19 This Comment is brought to you for free and open access by the Journals at Emory Law Scholarly Commons. It has been accepted for inclusion in Emory International Law Review by an authorized editor of Emory Law Scholarly Commons. For more information, please contact [email protected]. WEAVER GALLEYSPROOFS1 5/2/2013 9:30 AM AGGRAVATED WITH AGGREGATORS: CAN INTERNATIONAL COPYRIGHT LAW HELP SAVE THE NEWSROOM? INTRODUCTION The creation of the World Wide Web was based on a concept of universality that would allow a link to connect to anywhere on the Internet.1 Although the Internet has transformed from a technical luxury into an indispensable tool in today’s society, this concept of universality remains. Internet users constantly click from link to link as they explore the rich tapestry of the World Wide Web to view current events, research, media, and more. Yet, few Internet users pause their daily online activity to think of the legal consequences of these actions.2 Recent Internet censorship measures intended to prevent illegal downloading, such as the proposed Stop Online Piracy Act (“SOPA”), have been at the forefront of the public’s attention due to fears of legislative limits on online free speech and innovation.3 However, the more common activity of Internet linking also creates the potential for legal liability 1 See Tim Berners-Lee, Realising the Full Potential of the Web, 46 TECHNICAL COMM. -

Student & Client Support Services Student Guide
Student & Client Support Services Student Guide Wireless Config - Mac For all wireless configurations done by CNS technicians and helpdesk consultant, an Authorization & Indemnification for configuration support form should be filled in by the user. In exception to walk-in wireless configuration support, all wireless configuration support should be done after a call was logged and assigned to the Ticket Coordinator (TC) who would assign the ticket to a technician that will do the actual configuration on the user’s machine and close the ticket there after. WIRELESS ACCESS FOR MAC AIRPORT: Mac OSX 10.6.x Snow Leopard Please note that the following guide is for connecting to the Wits network via Airport and not via Ethernet. Please make sure that your Wi-Fi is turned on and follow this guide. NOTES: The proxy configuration may need to be done in various applications depending on which web browser you are using. The supported web browsers in this guide are Safari, Firefox, Opera, Camino and Google Chrome. If you are using Camino or Google Chrome please follow the Safari instructions. Once you have completed the configuration and you open either Camino or Google Chrome and visit a web site you will be prompted for authentication and need to enter your User Name and Password. In the User Name field enter your Student/Staff Number preceded by “students\” for students or “ds\” for staff. The format of the User Name field looks as follows: “students\student number” or “ds\staff number”. Now enter your Password and click OK. SAFARI Open System Preferences, in System Preferences select Network Now you need to create a new Location. -

Dell Cloud Client-Computing Interactive Brochure
Dell cloud client-computing Interactive brochure Welcome to Dell cloud client-computing Learn more here: Welcome to Dell cloud client-computing Dell offers a complete spectrum of virtual desktop solutions and service delivery models including both pre-configured and customized options, on-premise infrastructure options, hosted and managed services offerings, subscription-based Dell Workspace-as-a-Service, and desktop virtualization hardware and software components. Why Dell for Desktop Virtualization? Introduction Dell.com Why Dell for Desktop Virtualization? Dell cloud client-computing is comprised Benefits of our solutions of an integrated portfolio of end-to-end and Dell differentiators desktop virtualization components including: On endpoint devices, software and services. • Accelerate time to value with pre-configured, premise Wyse Datacenter solutions combine the latest pre-engineered solutions for Citrix, virtualization and management technologies Microsoft, VMware and Wyse vWorkspace Datacenter components with Dell’s powerful pre-integrated servers, • Flexible delivery models that include starter kits, As-a- Service storage, networking, virtualization software and mid-range and full rack systems and hyper- Dell Professional Services to simplify desktop converged infrastructure appliances to address management and scale effortlessly as your the realities of your environment Multiple business grows. • Variety of professional services that delivery enhance your capabilities: consulting, support, models Most importantly, the Dell’s implementation and management Wyse cloud cloud client-computing portfolio • Vertical solutions to address industry-specific clients Citrix, is designed to deliver a personalized challenges including: healthcare, government Microsoft, and education high fidelity experience for end users Dell Services Professional or VMware • One single point of service for the across a wide variety of devices. -

Thin Client Computing White Paper
Thin Client Computing White Paper Thin Client Computing Providing Solutions and Dispelling Myths 2 Less is more While minimalism in computing has been around since the 1990s, the concept only recently has hit its stride: Computer devices that only carry out essential applications, or “thin clients,” have a longer operational life span, cut energy use and are less expensive to purchase and maintain. As the phenomenon of software as a service gains traction, in fact, thin clients are already replacing desktop PCs in many government, commercial and educational settings. A pioneer in thin client software innovation, Citrix Systems, Inc. specializes in providing virtualization solutions to government, healthcare and educational organizations that improve security, reduce IT expense and ...thin clients have a increase flexibility. When applied appropriately, Citrix applications can longer operational optimize the thin client to be a cost-effective solution for task-based workers, administrative staff or even mobile users—anywhere, on any device, all life span, cut without losing application performance. energy use and are less expensive What does “thin client” mean? to purchase and The term “thin client”—also called a “slim” or “lean” client—is a computer maintain. that relies on a server to drive traditional computer tasks and therefore may not be equipped with standard hard drives, ports or installed software. As such, the thin client does not actually process data locally but rather acts merely as a user interface, while running programs and accessing data from the datacenter (conversely, the traditional “fat client” computer fulfills all roles by itself). The best analogy for this process would be residential satellite or cable TV service: A signal is sent from a centralized location, and the television set acts as a simple receiving device. -

Zenon Web Server and Zenon Web Server Pro
zenon manual zenon Web Server and zenon Web Server Pro v.7.11 ©2014 Ing. Punzenberger COPA-DATA GmbH All rights reserved. Distribution and/or reproduction of this document or parts thereof in any form are permitted solely with the written permission of the company COPA-DATA. The technical data contained herein has been provided solely for informational purposes and is not legally binding. Subject to change, technical or otherwise. Contents 1. Welcome to COPA-DATA help ...................................................................................................... 5 2. zenon Web Server and zenon Web Server Pro .............................................................................. 6 3. Versions ...................................................................................................................................... 7 4. Basics .......................................................................................................................................... 8 5. General limitations ...................................................................................................................... 9 6. Licensing ................................................................................................................................... 12 6.1 Dongle licensing ........................................................................................................................................ 16 6.2 Soft licensing ............................................................................................................................................ -

Aras Innovator 11 Client Settings for Internet Explorer on Windows
Aras Innovator 11 Client Settings for Internet Explorer on Windows Document #: 11.0.02015040601 Last Modified: 1/3/2017 Aras Innovator 11 Client Setup for Internet Explorer on Windows Copyright Information Copyright © 2017 Aras Corporation. All Rights Reserved. Aras Corporation 300 Brickstone Square Suite 700 Andover, MA 01810 Phone: 978-691-8900 Fax: 978-794-9826 E-mail: [email protected] Website: http://www.aras.com Notice of Rights Copyright © 2017 by Aras Corporation. This material may be distributed only subject to the terms and conditions set forth in the Open Publication License, V1.0 or later (the latest version is presently available at http://www.opencontent.org/openpub/). Distribution of substantively modified versions of this document is prohibited without the explicit permission of the copyright holder. Distribution of the work or derivative of the work in any standard (paper) book form for commercial purposes is prohibited unless prior permission is obtained from the copyright holder. Aras Innovator, Aras, and the Aras Corp "A" logo are registered trademarks of Aras Corporation in the United States and other countries. All other trademarks referenced herein are the property of their respective owners. Notice of Liability The information contained in this document is distributed on an "As Is" basis, without warranty of any kind, express or implied, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose or a warranty of non- infringement. Aras shall have no liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the information contained in this document or by the software or hardware products described herein.