2.2 Named Entity Recognition
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Metabolic Fingerprinting of Leontopodium Species (Asteraceae
Phytochemistry 72 (2011) 1379–1389 Contents lists available at ScienceDirect Phytochemistry journal homepage: www.elsevier.com/locate/phytochem Metabolic fingerprinting of Leontopodium species (Asteraceae) by means of 1H NMR and HPLC–ESI-MS Stefan Safer a, Serhat S. Cicek a, Valerio Pieri a, Stefan Schwaiger a, Peter Schneider a, Volker Wissemann b, ⇑ Hermann Stuppner a, a Institute of Pharmacy/Pharmacognosy, Faculty of Chemistry and Pharmacy, Center for Molecular Biosciences Innsbruck (CMBI), University of Innsbruck, Innrain 52c, A-6020 Innsbruck, Austria b Institute of Botany, Systematic Botany Group, Justus-Liebig-University Gießen, Heinrich-Buff-Ring 38, D-35392 Gießen, Germany article info abstract Article history: The genus Leontopodium, mainly distributed in Central and Eastern Asia, consists of ca. 34–58 different Received 30 December 2010 species. The European Leontopodium alpinum, commonly known as Edelweiss, has a long tradition in folk Received in revised form 7 April 2011 medicine. Recent research has resulted in the identification of prior unknown secondary metabolites, Available online 7 May 2011 some of them with interesting biological activities. Despite this, nearly nothing is known about the Asian species of the genus. In this study, we applied proton nuclear magnetic resonance (1H NMR) spectroscopy Keywords: and liquid chromatography–mass spectrometry (LC–MS) metabolic fingerprinting to reveal insights into Leontopodium the metabolic patterns of 11 different Leontopodium species, and to conclude on their taxonomic relation- Asteraceae ship. Principal component analysis (PCA) of 1H NMR fingerprints revealed two species groups. Discrimi- Metabolic fingerprinting 1H NMR nators for these groups were identified as fatty acids and sucrose for group A, and ent-kaurenoic acid and LC–MS derivatives thereof for group B. -

Protecting the Natural Endangered Heritage in Romania, Croatia, Poland and Slovenia
Available online at http://journals.usamvcluj.ro/index.php/promediu ProEnvironment ProEnvironment 11 (2018) 143-157 Review The Rights of Alive – Protecting the Natural Endangered Heritage in Romania, Croatia, Poland and Slovenia CIOANCĂ Lia-Maria1*, Luminița UJICĂ2, Marijana MIKULANDRA3, Ryszard SOŁTYSIK4, Maja ČERNE5 1Babeș-Bolyai University Cluj-Napoca, University Extension Bistrița, Andrei Mureşanu st., no. 3-5, Romania 2High Scool with Sportive Program Bistrița, Calea Moldovei no. 18. Romania 3OŠ Tina Ujevi Osnovna škola Tina Ujevića Koturaška cesta 75 10000 Zagreb, Croatia 4Zespół Szkół Nr1 w Humniskach, 36 – 206, Huminska 264, Poland 5OŠ Rogaška Slatina, Kidričeva ulica 24, 3250 Rogaška Slatina Slovenia Received 23 July 2018; received and revised form 18 September 2018; accepted 25 September 2018 Available online 30 September 2018 Abstract This article deals with the impact of destructive actions of human population on natural world. As a consequence of relying on non-renewable energy sources and reckless encroachment on natural habitats a lot of plant and animal species have become extinct and more and more species are getting endangered. Thus celebrating biodiversity and solidarity for all life forms, from the tiniest one to the most complex eco-systems, has been in the centre of our attention and operational activities. Keywords: durable development, ecology, endangered species. 1. Introduction Within the massive destruction of forests and forest climate, we witness significant changes, Just as the man has passed from the stage of sometimes radical of the environment. For the animal hunter and collector up to animal raiser and farmer, and plants which have survived through a long period the natural vegetation has increasingly been subject of adaptation, a new difficult era starts again. -

Western Ghats & Sri Lanka Biodiversity Hotspot
Ecosystem Profile WESTERN GHATS & SRI LANKA BIODIVERSITY HOTSPOT WESTERN GHATS REGION FINAL VERSION MAY 2007 Prepared by: Kamal S. Bawa, Arundhati Das and Jagdish Krishnaswamy (Ashoka Trust for Research in Ecology & the Environment - ATREE) K. Ullas Karanth, N. Samba Kumar and Madhu Rao (Wildlife Conservation Society) in collaboration with: Praveen Bhargav, Wildlife First K.N. Ganeshaiah, University of Agricultural Sciences Srinivas V., Foundation for Ecological Research, Advocacy and Learning incorporating contributions from: Narayani Barve, ATREE Sham Davande, ATREE Balanchandra Hegde, Sahyadri Wildlife and Forest Conservation Trust N.M. Ishwar, Wildlife Institute of India Zafar-ul Islam, Indian Bird Conservation Network Niren Jain, Kudremukh Wildlife Foundation Jayant Kulkarni, Envirosearch S. Lele, Centre for Interdisciplinary Studies in Environment & Development M.D. Madhusudan, Nature Conservation Foundation Nandita Mahadev, University of Agricultural Sciences Kiran M.C., ATREE Prachi Mehta, Envirosearch Divya Mudappa, Nature Conservation Foundation Seema Purshothaman, ATREE Roopali Raghavan, ATREE T. R. Shankar Raman, Nature Conservation Foundation Sharmishta Sarkar, ATREE Mohammed Irfan Ullah, ATREE and with the technical support of: Conservation International-Center for Applied Biodiversity Science Assisted by the following experts and contributors: Rauf Ali Gladwin Joseph Uma Shaanker Rene Borges R. Kannan B. Siddharthan Jake Brunner Ajith Kumar C.S. Silori ii Milind Bunyan M.S.R. Murthy Mewa Singh Ravi Chellam Venkat Narayana H. Sudarshan B.A. Daniel T.S. Nayar R. Sukumar Ranjit Daniels Rohan Pethiyagoda R. Vasudeva Soubadra Devy Narendra Prasad K. Vasudevan P. Dharma Rajan M.K. Prasad Muthu Velautham P.S. Easa Asad Rahmani Arun Venkatraman Madhav Gadgil S.N. Rai Siddharth Yadav T. Ganesh Pratim Roy Santosh George P.S. -

Biodiversity and Ecology of Critically Endangered, Rûens Silcrete Renosterveld in the Buffeljagsrivier Area, Swellendam
Biodiversity and Ecology of Critically Endangered, Rûens Silcrete Renosterveld in the Buffeljagsrivier area, Swellendam by Johannes Philippus Groenewald Thesis presented in fulfilment of the requirements for the degree of Masters in Science in Conservation Ecology in the Faculty of AgriSciences at Stellenbosch University Supervisor: Prof. Michael J. Samways Co-supervisor: Dr. Ruan Veldtman December 2014 Stellenbosch University http://scholar.sun.ac.za Declaration I hereby declare that the work contained in this thesis, for the degree of Master of Science in Conservation Ecology, is my own work that have not been previously published in full or in part at any other University. All work that are not my own, are acknowledge in the thesis. ___________________ Date: ____________ Groenewald J.P. Copyright © 2014 Stellenbosch University All rights reserved ii Stellenbosch University http://scholar.sun.ac.za Acknowledgements Firstly I want to thank my supervisor Prof. M. J. Samways for his guidance and patience through the years and my co-supervisor Dr. R. Veldtman for his help the past few years. This project would not have been possible without the help of Prof. H. Geertsema, who helped me with the identification of the Lepidoptera and other insect caught in the study area. Also want to thank Dr. K. Oberlander for the help with the identification of the Oxalis species found in the study area and Flora Cameron from CREW with the identification of some of the special plants growing in the area. I further express my gratitude to Dr. Odette Curtis from the Overberg Renosterveld Project, who helped with the identification of the rare species found in the study area as well as information about grazing and burning of Renosterveld. -

Fruiting Body Form, Not Nutritional Mode, Is the Major Driver of Diversification in Mushroom-Forming Fungi
Fruiting body form, not nutritional mode, is the major driver of diversification in mushroom-forming fungi Marisol Sánchez-Garcíaa,b, Martin Rybergc, Faheema Kalsoom Khanc, Torda Vargad, László G. Nagyd, and David S. Hibbetta,1 aBiology Department, Clark University, Worcester, MA 01610; bUppsala Biocentre, Department of Forest Mycology and Plant Pathology, Swedish University of Agricultural Sciences, SE-75005 Uppsala, Sweden; cDepartment of Organismal Biology, Evolutionary Biology Centre, Uppsala University, 752 36 Uppsala, Sweden; and dSynthetic and Systems Biology Unit, Institute of Biochemistry, Biological Research Center, 6726 Szeged, Hungary Edited by David M. Hillis, The University of Texas at Austin, Austin, TX, and approved October 16, 2020 (received for review December 22, 2019) With ∼36,000 described species, Agaricomycetes are among the and the evolution of enclosed spore-bearing structures. It has most successful groups of Fungi. Agaricomycetes display great di- been hypothesized that the loss of ballistospory is irreversible versity in fruiting body forms and nutritional modes. Most have because it involves a complex suite of anatomical features gen- pileate-stipitate fruiting bodies (with a cap and stalk), but the erating a “surface tension catapult” (8, 11). The effect of gas- group also contains crust-like resupinate fungi, polypores, coral teroid fruiting body forms on diversification rates has been fungi, and gasteroid forms (e.g., puffballs and stinkhorns). Some assessed in Sclerodermatineae, Boletales, Phallomycetidae, and Agaricomycetes enter into ectomycorrhizal symbioses with plants, Lycoperdaceae, where it was found that lineages with this type of while others are decayers (saprotrophs) or pathogens. We constructed morphology have diversified at higher rates than nongasteroid a megaphylogeny of 8,400 species and used it to test the following lineages (12). -

An Asian Orchid, Eulophia Graminea (Orchidaceae: Cymbidieae), Naturalizes in Florida
LANKESTERIANA 8(1): 5-14. 2008. AN ASIAN ORCHID, EULOPHIA GRAMINEA (ORCHIDACEAE: CYMBIDIEAE), NATURALIZES IN FLORIDA ROBE R T W. PEMBE R TON 1,3, TIMOTHY M. COLLINS 2 & SUZANNE KO P TU R 2 1Fairchild Tropical Botanic Garden, 2121 SW 28th Terrace Ft. Lauderdale, Florida 33312 2Department of Biological Sciences, Florida International University, Miami, FL 33199 3Author for correspondence: [email protected] ABST R A C T . Eulophia graminea, a terrestrial orchid native to Asia, has naturalized in southern Florida. Orchids naturalize less often than other flowering plants or ferns, butE. graminea has also recently become naturalized in Australia. Plants were found growing in five neighborhoods in Miami-Dade County, spanning 35 km from the most northern to the most southern site, and growing only in woodchip mulch at four of the sites. Plants at four sites bore flowers, and fruit were observed at two sites. Hand pollination treatments determined that the flowers are self compatible but fewer fruit were set in selfed flowers (4/10) than in out-crossed flowers (10/10). No fruit set occurred in plants isolated from pollinators, indicating that E. graminea is not autogamous. Pollinia removal was not detected at one site, but was 24.3 % at the other site evaluated for reproductive success. A total of 26 and 92 fruit were found at these two sites, where an average of 6.5 and 3.4 fruit were produced per plant. These fruits ripened and dehisced rapidly; some dehiscing while their inflorescences still bore open flowers. Fruit set averaged 9.2 and 4.5 % at the two sites. -

Rock Garden Quarterly
ROCK GARDEN QUARTERLY VOLUME 53 NUMBER 1 WINTER 1995 COVER: Aquilegia scopulorum with vespid wasp by Cindy Nelson-Nold of Lakewood, Colorado All Material Copyright © 1995 North American Rock Garden Society ROCK GARDEN QUARTERLY BULLETIN OF THE NORTH AMERICAN ROCK GARDEN SOCIETY formerly Bulletin of the American Rock Garden Society VOLUME 53 NUMBER 1 WINTER 1995 FEATURES Alpine Gesneriads of Europe, by Darrell Trout 3 Cassiopes and Phyllodoces, by Arthur Dome 17 Plants of Mt. Hutt, a New Zealand Preview, by Ethel Doyle 29 South Africa: Part II, by Panayoti Kelaidis 33 South African Sampler: A Dozen Gems for the Rock Garden, by Panayoti Kelaidis 54 The Vole Story, by Helen Sykes 59 DEPARTMENTS Plant Portrait 62 Books 65 Ramonda nathaliae 2 ROCK GARDEN QUARTERLY VOL. 53:1 ALPINE GESNERIADS OF EUROPE by Darrell Trout J. he Gesneriaceae, or gesneriad Institution and others brings the total family, is a diverse family of mostly Gesneriaceae of China to a count of 56 tropical and subtropical plants with genera and about 413 species. These distribution throughout the world, should provide new horticultural including the north and south temper• material for the rock garden and ate and tropical zones. The 125 genera, alpine house. Yet the choicest plants 2850-plus species include terrestrial for the rock garden or alpine house and epiphytic herbs, shrubs, vines remain the European genera Ramonda, and, rarely, small trees. Botanically, Jancaea, and Haberlea. and in appearance, it is not always easy to separate the family History Gesneriaceae from the closely related The family was named for Konrad Scrophulariaceae (Verbascum, Digitalis, von Gesner, a sixteenth century natu• Calceolaria), the Orobanchaceae, and ralist. -

Chapter 10. 6110* Rupicolous Calcareous Or Basophilic Grasslands of the Alysso–Sedion Albi
Semi-natural grasslands 125 Chapter 10. 6110* Rupicolous in the Daugava River Valley between Pļaviņas and calcareous or basophilic Koknese (Rūsiņa 2013c) (Fig. 10.1.1). The total area grasslands of the of this habitat in the European boreal region is 230 ha, of which 1 ha is in Latvia and the rest in Sweden. Alysso–Sedion albi Based on vegetation composition and environ- mental conditions, EU protected habitat type 6110* 10.1 Characteristics of the Habitat Type Rupicolous calcareous or basophilic grasslands of the Alysso–Sedion albi can be divided into two variants 10.1.1 Brief Description (Auniņš (ed.) 2013) (Table 10.1.1). The largest locality of this habitat type is found Habitat type 6110* Rupicolous calcareous or basop- on the banks of the River Lielupe near Bauska (Fig. hilic grasslands of the Alysso–Sedion albi (referred 10.1.2) It occurs in the Daugava River Valley near to as rupicolous grasslands in the text) is characteri- Dzelmes (Fig. 10.1.3), but is in bad condition – hea- sed by sparse xerothermic pioneer communities on vily overgrown with trees and shrubs and adversely superficial calcareous soils, dominated by annual affected by nutrient runoff from adjacent agricul- plants and succulents. In most cases this habitat tural land. develops on horizontal or inclined (but not vertical) dolomite and limestone outcrops. Habitat corres- 10.1.2 Vegetation, Plant and Animal Species ponds to areas where the outcrop slope is equal to or lower than 45 degrees. Plants and vegetation. Habitat is characterised by In Latvia, the habitat is close to its northern xerothermic plants that form as pioneer commu- range of distribution. -
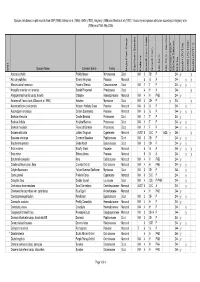
BFS244 Site Species List
Species lists based on plot records from DEP (1996), Gibson et al. (1994), Griffin (1993), Keighery (1996) and Weston et al. (1992). Taxonomy and species attributes according to Keighery et al. (2006) as of 16th May 2005. Species Name Common Name Family Major Plant Group Significant Species Endemic Growth Form Code Growth Form Life Form Life Form - aquatics Common SSCP Wetland Species BFS No beel01 (FCT28) beel02 (FCT23a) beel03 (FCT11) Wd? Acacia pulchella Prickly Moses Mimosaceae Dicot WA 3 SH P 244 y y * Aira caryophyllea Silvery Hairgrass Poaceae Monocot 5 G A 244 y y Allocasuarina fraseriana Fraser's Sheoak Casuarinaceae Dicot WA 1 T P 244 y y * Anagallis arvensis var. arvensis Scarlet Pimpernel Primulaceae Dicot 4 H A 244 y Anigozanthos humilis subsp. humilis Catspaw Haemodoraceae Monocot WA 4 H PAB 244 y Astartea aff. fascicularis (Gibson et al. 1994) Astartea Myrtaceae Dicot WA 3 SH P y 244 y Austrodanthonia occidentalis Western Wallaby Grass Poaceae Monocot WA 5 G P 244 y Austrostipa compressa Golden Speargrass Poaceae Monocot WA 5 G P 244 y y y Banksia attenuata Candle Banksia Proteaceae Dicot WA 1 T P 244 y Banksia ilicifolia Hollyleaf Banksia Proteaceae Dicot WA 1 T P 244 y y Banksia menziesii Firewood Banksia Proteaceae Dicot WA 1 T P 244 y y Baumea articulata Jointed Twigrush Cyperaceae Monocot AUST 6 S-C P AQE y 244 y Bossiaea eriocarpa Common Bossiaea Papilionaceae Dicot WA 3 SH P 244 y y Brachyloma preissii Globe Heath Epacridaceae Dicot WA 3 SH P 244 y y * Briza maxima Blowfly Grass Poaceae Monocot 5 G A 244 y y y * Briza minor Shivery Grass Poaceae Monocot 5 G A 244 y y Burchardia congesta Kara Colchicaceae Monocot WA 4 H PAB 244 y Caladenia flava subsp. -

Acidofilní Ostrůvky U Matějovce
Acidofilní ostrůvky u Matějovce Autoři: Lucie Březinová, Natálie Fáberová, Marie Straková, Michaela Švecová, Michaela Vítková Vedoucí práce: Mgr. Dana Horázná Základní škola Sira Nicholase Wintona Kunžak 2010 Obsah: 1. Úvod .........................................................................................................................3 2. Anotace ....................................................................................................................4 3. Matějovec .................................................................................................................5 4. Biodiverzita .......................................................................................................... 6-7 5. Eutrofizace ........................................................................................................... 8-9 6. Acidofilní suché trávníky .......................................................................................10 7. Seznam rostlin .................................................................................................. 11-13 8. Netřesk výběžkatý ..................................................................................................14 9. Kociánek dvoudomý ..............................................................................................15 10. Konvalinka vonná ..................................................................................................16 11. Kokořík vonný .......................................................................................................17 -

Final Project Report (To Be Submitted by 30Th September 2016)
Final Project Report (to be submitted by 30th September 2016) Instructions: Document length: maximum 10 pages, excluding this cover page and the last page on project tags. Start with an abstract (max 1 page). Final report text: Do not forget to mention your methodology; the people involved (who, how many, what organization they are from – if applicable); and the expected added value for biodiversity, society and the company. Finally, state whether the results of your project can be implemented at a later stage, and please mention the ideal timing and estimated costs of implementation. Annexes are allowed but will not be taken into account by the jury and must be sent separately. Word/PDF Final Report files must be less than 10 MB. If you choose to submit your final report in your local language, you are required to also upload your final report in English if you wish to take part in the international competition. To be validated, your file must be uploaded to the Quarry Life Award website before 30th September 2016 (midnight, Central European Time). To do so, please log in, click on ‘My account’/ ‘My Final report’. In case of questions, please liaise with your national coordinator. 1. Contestant profile . Contestant name: Moldovan Ștefan . Contestant occupation: Ornithologist . University / Organisation Romanian Ornithological Society . E-mail: . Phone (incl. country code): . Number of people in your team: 7 2. Project overview Title: Search for the critically endangered Apollo Butterfly at Bicaz Chei Quarry Contest: Quarry Life Award Quarry name: Bicaz Chei Quarry Prize category: ☐ Education and Raising Awareness (select all appropriate) X Habitat and Species Research ☐ Biodiversity Management ☐ Student Project ☐ Beyond Quarry Borders 1/3 Abstract The Apollo butterfly (Parnassius apollo Linnaues 1758) is a post-glacial relict, considered extinct from the Romanian fauna by most lepideptorologists. -

Sistemática Y Evolución De Encyclia Hook
·>- POSGRADO EN CIENCIAS ~ BIOLÓGICAS CICY ) Centro de Investigación Científica de Yucatán, A.C. Posgrado en Ciencias Biológicas SISTEMÁTICA Y EVOLUCIÓN DE ENCYCLIA HOOK. (ORCHIDACEAE: LAELIINAE), CON ÉNFASIS EN MEGAMÉXICO 111 Tesis que presenta CARLOS LUIS LEOPARDI VERDE En opción al título de DOCTOR EN CIENCIAS (Ciencias Biológicas: Opción Recursos Naturales) Mérida, Yucatán, México Abril 2014 ( 1 CENTRO DE INVESTIGACIÓN CIENTÍFICA DE YUCATÁN, A.C. POSGRADO EN CIENCIAS BIOLÓGICAS OSCJRA )0 f CENCIAS RECONOCIMIENTO S( JIOI ÚGIC A'- CICY Por medio de la presente, hago constar que el trabajo de tesis titulado "Sistemática y evo lución de Encyclia Hook. (Orchidaceae, Laeliinae), con énfasis en Megaméxico 111" fue realizado en los laboratorios de la Unidad de Recursos Naturales del Centro de Investiga ción Científica de Yucatán , A.C. bajo la dirección de los Drs. Germán Carnevali y Gustavo A. Romero, dentro de la opción Recursos Naturales, perteneciente al Programa de Pos grado en Ciencias Biológicas de este Centro. Atentamente, Coordinador de Docencia Centro de Investigación Científica de Yucatán, A.C. Mérida, Yucatán, México; a 26 de marzo de 2014 DECLARACIÓN DE PROPIEDAD Declaro que la información contenida en la sección de Materiales y Métodos Experimentales, los Resultados y Discusión de este documento, proviene de las actividades de experimen tación realizadas durante el período que se me asignó para desarrollar mi trabajo de tesis, en las Unidades y Laboratorios del Centro de Investigación Científica de Yucatán, A.C., y que a razón de lo anterior y en contraprestación de los servicios educativos o de apoyo que me fueron brindados, dicha información, en términos de la Ley Federal del Derecho de Autor y la Ley de la Propiedad Industrial, le pertenece patrimonialmente a dicho Centro de Investigación.