Embedded Networked Front Ends - Beyond the Crate∗
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

SPARC/CPU-5V Technical Reference Manual
SPARC/CPU-5V Technical Reference Manual P/N 203651 Edition 5.0 February 1998 FORCE COMPUTERS Inc./GmbH All Rights Reserved This document shall not be duplicated, nor its contents used for any purpose, unless express permission has been granted. Copyright by FORCE COMPUTERS CPU-5V Technical Reference Manual Table of Contents SECTION 1 INTRODUCTION ....................................................................................1 1. Getting Started ..................................................................................................................................... 1 1.1. The SPARC CPU-5V Technical Reference Manual Set.................................................................. 1 1.2. Summary of the SPARC CPU-5V ................................................................................................... 2 1.3. Specifications ................................................................................................................................... 4 1.3.1. Ordering Information........................................................................................................... 6 1.4. History of the Manual ...................................................................................................................... 9 SECTION 2 INSTALLATION ....................................................................................11 2. Introduction........................................................................................................................................ 11 2.1. Caution -

Discontinued Emulex- Branded Products
Broadcom 1320 Ridder Park Drive San Jose, CA 95131 broadcom.com Discontinued Emulex- branded Products . Fibre Channel Host Bus Adapters . Fibre Channel HUBS . Switches . Software Solutions October 30, 2020 This document only applies to Emulex- branded products. Consult your supplier for specific information on OEM-branded products. Discontinued Emulex-branded Products Overview Broadcom Limited is committed to our customers by delivering product functionality and reliability that exceeds their expectation. Below is a description of key terminology and discontinued product tables. Table 1—Fibre Channel Host Bus Adapters . Table 2—Fibre Channel Optical Transceiver Kits . Table 3—Fibre Channel HUBs . Table 4—Switches . Table 5—Software Solutions Key Terminology End of Life (EOL) notification EOL indicates the date that distributors were notified of Broadcom intent to discontinue an Emulex model in production. Distributors are typically given a three-to-six month notice of Broadcom plans to discontinue a particular model. Final order This is the last date that Broadcom will accept orders from a customer or distributor. End of support This is the last date technical support is available for reporting software issues on discontinued models. The tables below indicate the last date of support or whether support has already ended. Software updates Active devices: Drivers for already supported operating system (OS) versions and firmware are updated periodically with new features and/ or corrections. Customers should check www.broadcom.com or call technical support for support of new OS versions for a given device. End of maintenance, Support Availability For software solutions, this is the last date software upgrades or updates are available. -

Sun Ultratm 2 Workstation Just the Facts
Sun UltraTM 2 Workstation Just the Facts Copyrights 1999 Sun Microsystems, Inc. All Rights Reserved. Sun, Sun Microsystems, the Sun Logo, Ultra, SunFastEthernet, Sun Enterprise, TurboGX, TurboGXplus, Solaris, VIS, SunATM, SunCD, XIL, XGL, Java, Java 3D, JDK, S24, OpenWindows, Sun StorEdge, SunISDN, SunSwift, SunTRI/S, SunHSI/S, SunFastEthernet, SunFDDI, SunPC, NFS, SunVideo, SunButtons SunDials, UltraServer, IPX, IPC, SLC, ELC, Sun-3, Sun386i, SunSpectrum, SunSpectrum Platinum, SunSpectrum Gold, SunSpectrum Silver, SunSpectrum Bronze, SunVIP, SunSolve, and SunSolve EarlyNotifier are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the United States and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the United States and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. OpenGL is a registered trademark of Silicon Graphics, Inc. UNIX is a registered trademark in the United States and other countries, exclusively licensed through X/Open Company, Ltd. Display PostScript and PostScript are trademarks of Adobe Systems, Incorporated. DLT is claimed as a trademark of Quantum Corporation in the United States and other countries. Just the Facts May 1999 Sun Ultra 2 Workstation Figure 1. The Sun UltraTM 2 workstation Sun Ultra 2 Workstation Scalable Computing Power for the Desktop Sun UltraTM 2 workstations are designed for the technical users who require high performance and multiprocessing (MP) capability. The Sun UltraTM 2 desktop series combines the power of multiprocessing with high-bandwidth networking, high-performance graphics, and exceptional application performance in a compact desktop package. Users of MP-ready and multithreaded applications will benefit greatly from the performance of the Sun Ultra 2 dual-processor capability. -

Sbus Specification B.O Written by Edward H
SBus Specification B.O Written by Edward H. Frank and Jim Lyle. Edited by Jim Lyle and Mike Harvey. Copyright ©1990 Sun Microsystems, Inc.-Printed in U.S.A. The Sun logo, Sun Microsystems, and Sun Workstation are registered trademarks of Sun Microsystems, Inc. Sun, Sun-2, Sun-3, Sun-4, Sun386i, Sunlnstall, SunOS, SunView, NFS, SunLink, NeWS, SPARC, and SPARCstation 1 are trademarks of Sun Microsystems, Inc. UNIX is a registered trademark of AT&T. The Sun Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun's licensees. All other products or services mentioned in this document are identified by the trademarks or service marks of their respective companies or organizations, and Sun Microsystems, Inc. disclaims any responsibility for specifying which marks are owned by which companies or organizations. All rights reserved. No part of this work covered by copyright hereon may be reproduced in any form or by any means-graphic, electronic, or mechanical-including photocopying, recording, taping, or storage in an information retrieval system, without the prior written permission of the copyright owner. Restricted rights legend: use, duplication, or disclosure by the U.S. government is subject to restrictions set forth in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 52.227-7013 and in similar clauses in the FAR and NASA FAR Supplement. -

Archived: Getting Started with Your SB-GPIB and NI-488.2M for Solaris 1
Getting Started with Your SB-GPIB and the NI-488.2M™ Software for Solaris 1 November 1993 Edition Part Number 320299-01 © Copyright 1991, 1994 National Instruments Corporation. All Rights Reserved. National Instruments Corporate Headquarters 6504 Bridge Point Parkway Austin, TX 78730-5039 (512) 794-0100 Technical support fax: (800) 328-2203 (512) 794-5678 Branch Offices: Australia (03) 879 9422, Austria (0662) 435986, Belgium 02/757.00.20, Canada (Ontario) (519) 622-9310, Canada (Québec) (514) 694-8521, Denmark 45 76 26 00, Finland (90) 527 2321, France (1) 48 14 24 24, Germany 089/741 31 30, Italy 02/48301892, Japan (03) 3788-1921, Netherlands 03480-33466, Norway 32-848400, Spain (91) 640 0085, Sweden 08-730 49 70, Switzerland 056/20 51 51, U.K. 0635 523545 Limited Warranty The SB-GPIB is warranted against defects in materials and workmanship for a period of two years from the date of shipment, as evidenced by receipts or other documentation. National Instruments will, at its option, repair or replace equipment that proves to be defective during the warranty period. This warranty includes parts and labor. The media on which you receive National Instruments software are warranted not to fail to execute programming instructions, due to defects in materials and workmanship, for a period of 90 days from date of shipment, as evidenced by receipts or other documentation. National Instruments will, at its option, repair or replace software media that do not execute programming instructions if National Instruments receives notice of such defects during the warranty period. National Instruments does not warrant that the operation of the software shall be uninterrupted or error free. -

Draft Standard for a Common Mezzanine Card Family
Introduction IEEE P1386/Draft 2.0 04-APR-1995 Draft Standard for a Common Mezzanine Card Family: CMC Sponsored by the Bus Architecture Standards Committee of the IEEE Computer Society P1386/Draft 2.0 April 4, 1995 Sponsor Ballot Draft Abstract: This draft standard defines the mechanics of a common mezzaninecard family. Mez- zanine cards designed to this draft standard can be usedinterchangeably on VME64 boards, Multibus I boards, Multibus II boards, Futurebus+ modules, desktopcomputers, portable com- puters, servers and other similar types of applications.Mezzanine cards can provide modular front panel I/O, backplane I/O or general function expansion or acombination for host comput- ers. Single wide mezzanine cards are 75 mm wide by 150 mm deep by 8.2 mmhigh. Keywords: Backplane I/O, Bezel, Board, Card, Face Plate, Front Panel I/O,Futurebus+, Host Computer, I/O, Local Bus, Metric, Mezzanine, Module, Modular I/O,Multibus, PCI, SBus, VME, VME64 or VMEbus Copyright (c) 1995 by the The Institute of Electrical and Electronics Engineers, Inc. 345 East 47th Street New York, NY 10017-2394, USA All rights reserved. This is an unapproved draft of a proposed IEEE Standard, subjectto change. Permission is hereby granted for IEEE Standards Committee participants toreproduce this document for pur- poses of IEEE standardization activities. If this document is tobe submitted to ISO or IEC, noti- fication shall be given to the IEEE Copyright Administrator.Permission is also granted for member bodies and technical committees of ISO and IEC toreproduce this document for pur- poses of developing a national position. Other entities seekingpermission to reproduce this document for standardization or other activities, or to reproduceportions of this document for these or other uses must contact the IEEE Standards Department forthe appropriate license. -

Sparc Cpu-8Vt
SPARC CPU-8VT Superior performance with redundancy features for business critical applications SPARC CPU-8VT — SPARCstation 5 compatibility with TurboSPARC performance in a single 6U VMEbus slot. The SPARC® CPU-8VT further enhances FORCE COMPUTERS single-slot SPARC family bringing TurboSPARC performance and redundancy features to your telecommunications and C3I applications. The addition of an external cache for the TurboSPARCTM doubles the perfor- mance of the fastest microSPARC CPU, while retaining the major microSPARC advantages of low power consumption and compact design. Couple this powerful CPU core with the integral workstation-type I/O found on the CPU-8VT and you have the ideal platform to develop and deploy powerful Solaris® and real-time applications. Further enhance this I/O with an integral sec- ond SCSI and a second Ethernet channel and you have a board that fulfils the typical requirements of most common high-availability and network routing applications without the necessity of adding SBus cards. Full compatibility with the established CPU-5VT provides a seamless upgrade path, extending our portfolio of high volume, premium price/performance embed- ded SPARC solutions for your applications. Facts... ...and features ◆ High-performance TurboSPARC processor ◆ Highest performance single-slot SPARC CPU ◆ 512 KByte L2 cache ◆ Functionally compatible with the Sun® SPARCstation 5 family and Solaris/SunOS® operating environment ◆ 16 to 128 MByte field upgradable Memory providing shared access to CPU, VME, SCSI, Ethernet & Centronics -
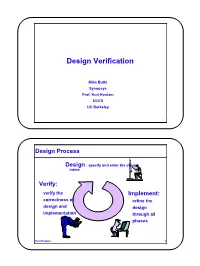
Design Verification
Design Verification Mike Butts Synopsys Prof. Kurt Keutzer EECS UC Berkeley 1 Design Process Design : specify and enter the design intent Verify: verify the Implement: correctness of refine the design and design implementation through all phases Kurt Keutzer 2 1 Design Verification HDL specification RTL manual Synthesis design netlist Is the Library/ design module logic generators optimization consistent with the original netlist specification? physical Is what I think I want design what I really want? layout Kurt Keutzer 3 Implementation Verification HDL RTL manual Synthesis design a 0 d netlist q b 1 Is the Library/ s clk implementation module logic generators optimization consistent with the original a 0 d q design intent? netlist b 1 s clk physical Is what I design implemented what I layout wanted? Kurt Keutzer 4 2 Manufacture Verification (Test) HDL Is the manufactured RTL manual circuit Synthesis design consistent with the a 0 d netlist q 1 Library/ b implemented s clk module logic design? generators optimization a 0 d Did they q b 1 netlist build s clk what I physical wanted? design layout Kurt Keutzer 5 Design Verification HDL specification RTL manual Synthesis design netlist Is the Library/ design module logic generators optimization consistent with the original netlist specification? physical Is what I think I want design what I really want? layout Kurt Keutzer 6 3 Verification is an Industry-Wide Issue Intel: Processor project verification: “Billions of generated vectors” “Our VHDL regression tests take 27 days to run. ” Sun: -

Applications of the Scalable Coherent Interface to Data Acquisition At
CERN LIBRARIES, GENEVA e8a ¥foi`<¥ lllll flliIllllllllllllllllllllllllllll SCOOOO0123 SP:. Ib RDC- EUROPEAN ORGANIZATION FOR NUCLEAR RESEARCH ... 3 Q` 6 CERN DRDC 92-6 QJan.DRDCPBS 2 , 1992 Add.1 Applications of the Scalable Coherent Interface to Data Acqu1s1t1on at LHC A. Bogaertsl, J. Buytaertz, R. Divia, H. Miillerl, C. Parkman, P. Ponting, D. Samyn CERN, Geneva, Switzerland B. Skaali, G. Midttun, D. Wormald, J. Wikne University of Oslo, Physics Department, Norway S. Falciano, F. Cesaroni INFN Sezione di Roma and University of Rome, La Sapienza, Italy V.I. Vinogradov Institute of Nuclear Research, Academy of Sciences, Moscow, Russia K. Lochsen, B. Solbergs Dolphin SCI Technology A.S., Oslo, Norway A. Guglielmi, A. Pastore Digital Equipment Corporation {DEC}, Joint Project at CERN F·H. Worm, J. Bovier Creative Electronic Systems {CES}, Geneva, Switzerland C. Davis Radstone Technology plc, Towcester, UK joint spokesmen Fellow at CERN Scientific associate at CERN, funded by Norwegian Research Council for Science and Humanities OCR Output $U?£(.<> Addendum to P33 The proposed work on SCI during 1992 has been revised due to delays in availibil ity of SCI chips. The revised plans are summarized in the new appendices A-D below. Some parts of the project for which the necessary items will not be available in 1992 (such as cache controller chip, the SCI-fiber version, the SCI-SCI bridge and the Futurebus+ bridge) have been postponed till 1993. This concerns primarily the cache coherent readout proposed for the 3"" level trigger. The content and spirit of proposal P33 is however unchanged. We will concentrate on building an SCI demonstration system which should test the data moving properties first, and at the same time prepare the first stage of an SCI ringlet system. -

MOVIDRIVE® MDX60B/61B Communication and Fieldbus Unit Profile
Drive Technology \ Drive Automation \ System Integration \ Services MOVIDRIVE® MDX60B/61B Communication and Fieldbus Unit Profile Edition 04/2009 Manual 11264926 / EN SEW-EURODRIVE – Driving the world 1 General Information ............................................................................................... 6 1.1 How to use the documentation ...................................................................... 6 1.2 Structure of the safety notes .......................................................................... 6 1.3 Rights to claim under limited warranty ........................................................... 7 1.4 Exclusion of liability........................................................................................ 7 1.5 Copyright........................................................................................................ 7 2 Safety Notes ........................................................................................................... 8 2.1 Other applicable documentation .................................................................... 8 2.2 General notes on bus systems....................................................................... 8 2.3 Safety functions ............................................................................................. 8 2.4 Hoist applications........................................................................................... 8 2.5 Waste disposal.............................................................................................. -

UPA—Sun'shighperformance Graphicsconnection
UPA—Sun’sHighPerformance GraphicsConnection TechnicalWhitePaper 1999 Sun Microsystems, Inc. All rights reserved. Printed in the United States of America. 901 San Antonio Road, Palo Alto, California 94303 U.S.A. The product described in this manual may be protected by one or more U.S. patents, foreign patents, or pending applications. TRADEMARKS Sun, Sun Microsystems, the Sun logo, Ultra, Sun Elite3D, Sun Enterprise, Java 3D, PGX, Java, SBus, and VIS are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the United States and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. OpenGL is a registered trademark of Silicon Graphics, Inc. THIS PUBLICATION IS PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, OR NON-INFRINGEMENT. THIS PUBLICATION COULD INCLUDE TECHNICAL INACCURACIES OR TYPOGRAPHICAL ERRORS. CHANGES ARE PERIODICALLY ADDED TO THE INFORMATION HEREIN; THESE CHANGES WILL BE INCORPORATED IN NEW EDITIONS OF THE PUBLICATION. SUN MICROSYSTEMS, INC. MAY MAKE IMPROVEMENTS AND/OR CHANGES IN THE PRODUCT(S) AND/OR THE PROGRAM(S) DESCRIBED IN THIS PUBLICATION AT ANY TIME. Please Recycle Contents Introduction. 1 Analyzing System Design and Application Performance. 2 Design Trade-offs . 2 An Overview of the UPA Interconnect . 3 Scalability, High Bandwidth, and Efficiency . 5 The UPA64S Graphics Bus. 6 Characterizing Application Performance and Bus Traffic. 7 UPA64S and Other Graphics Bus Technologies . -

A Millenium Approach to Data Acquisition: SCI and PCI
A millenium approach to Data Acquisition: SCI and PCI Hans Müller, A.Bogaerts CERN, Division ECP, CH-1211 Geneva 23, Switzerland V.Lindenstruth LBL Berkeley, CA 94720 Berkeley, USA The international SCI standard IEEE/ANSI 1596a [Ref. 1.] is on its way to become the computer interconnect of the year 2000 since for a first time, low latency desktop multiprocessing and cluster computing can be implemented at low cost. The PCI bus is todays’s dominating local bus extension for all major computer platforms as well as for buses like VMEbus. PCI is a self configuring memory and I/O system for peripheral components with a hierarchical architecture. SCI is a scalable, bus-like interconnect for distributed processors and memories. It allows for optionally coherent data caching and assures errorfree data delivery. First measurement with commercial SCI products (SBUS-SCI) confirm simulations that SCI can handle even the highest data rates of LHC experiments. The eventbuilder layer for a millenium very high rate DAQ system can therefore be viewed as a SCI network ( bridges, cables & switches) interfaced between PCI buses on the front- end (VMEb ) side and on the processor farm ( Multi-CPU) side . Such a combination of SCI and PCI enables PCI-PCI memory access, transparently across SCI. It also allows for a novel, low level trigger technique: the trigger algorithm can access VME data buffers with bus-like latencies like local memory, i.e. full data transfers become redundent.. The first prototype of a PCI-SCI bridge for DAQ is presented as starting point for a test system with built-in scalability.