A Comparison of Processor Technologies
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AMD Athlon™ Processor X86 Code Optimization Guide
AMD AthlonTM Processor x86 Code Optimization Guide © 2000 Advanced Micro Devices, Inc. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. No license, whether express, implied, arising by estoppel or otherwise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other applica- tion in which the failure of AMD’s product could create a situation where per- sonal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD logo, AMD Athlon, K6, 3DNow!, and combinations thereof, AMD-751, K86, and Super7 are trademarks, and AMD-K6 is a registered trademark of Advanced Micro Devices, Inc. Microsoft, Windows, and Windows NT are registered trademarks of Microsoft Corporation. -

Validated Products List, 1995 No. 3: Programming Languages, Database
NISTIR 5693 (Supersedes NISTIR 5629) VALIDATED PRODUCTS LIST Volume 1 1995 No. 3 Programming Languages Database Language SQL Graphics POSIX Computer Security Judy B. Kailey Product Data - IGES Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 July 1995 QC 100 NIST .056 NO. 5693 1995 NISTIR 5693 (Supersedes NISTIR 5629) VALIDATED PRODUCTS LIST Volume 1 1995 No. 3 Programming Languages Database Language SQL Graphics POSIX Computer Security Judy B. Kailey Product Data - IGES Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 July 1995 (Supersedes April 1995 issue) U.S. DEPARTMENT OF COMMERCE Ronald H. Brown, Secretary TECHNOLOGY ADMINISTRATION Mary L. Good, Under Secretary for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY Arati Prabhakar, Director FOREWORD The Validated Products List (VPL) identifies information technology products that have been tested for conformance to Federal Information Processing Standards (FIPS) in accordance with Computer Systems Laboratory (CSL) conformance testing procedures, and have a current validation certificate or registered test report. The VPL also contains information about the organizations, test methods and procedures that support the validation programs for the FIPS identified in this document. The VPL includes computer language processors for programming languages COBOL, Fortran, Ada, Pascal, C, M[UMPS], and database language SQL; computer graphic implementations for GKS, COM, PHIGS, and Raster Graphics; operating system implementations for POSIX; Open Systems Interconnection implementations; and computer security implementations for DES, MAC and Key Management. -
Computer Organization
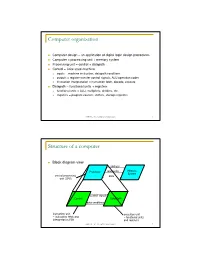
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Contrpl Data Nos Version 2 Administration Handbook
60459840 CONTRPL DATA NOS VERSION 2 ADMINISTRATION HANDBOOK /fP^v CDC® OPERATING SYSTEMS: CYBER 180 CYBER 170 CYBER 70 MODELS 71, 72, 73, 74 6000 REVISION RECORD T-gSZBZaSESEl jiito wminan REVISION DESCRIPTION Manual released; reflects NOS 2.3 at PSR level 617. Features include default charge restriction, (10-05-84) terminal input and output count at logoff, password randomization, a new CHARGE directive for the SUBMIT command, and support of the Mass Storage Archival Subsystem. Supports CYBER 180 computer systems. B Revision B reflects NOS 2.4.2 at PSR level 642. It incorporates new features such as support of (09-26-85) CYBER 180 Models 840, 850, 860, and 990, Printer Support Utility, and NAM Application Switching. Revision C reflects NOS 2.5.1 at PSR level 664. It documents the personal identification (09-30-86) v a l i d a t i o n , t h e s i n g l e t e r m i n a l s e s s i o n r e s t r i c t i o n , a n d o t h e r m i s c e l l a n e o u s t e c h n i c a l c h a n g e s . Revision D reflects NOS 2.6.1 at PSR level 700. It includes miscellaneous corrections and minor (04-14-88) additions. Publication No, 60459840 REVISION LETTERS I. O. Q. S. X AND Z ARE NOT USED. Address comments concerning this manual to: Control Data Technical Publications 4201 N. -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

A PROGRAMMABLE COMPUTER INTERFACE for CAMAC F by Robert W
NASA TECHNICAL NOTE NASA TN D-7148 A PROGRAMMABLE COMPUTER INTERFACE FOR CAMAC f by Robert W. Bercaw, Theodore E. Fessler, \ and Jeffrey M. Arnold Lewis Research Center Cleveland, Ohio 44135 NATIONAL AERONAUTICS AND SPACE ADMINISTRATION • WASHINGTON, D. C. • MARCH 1973 1. Report No. 2. Government Accession No. 3. Recipient's Catalog No. NASA TN D-7148 4. Title and Subtitle 5. Report Date March 1973 A PROGRAMMABLE COMPUTER INTERFACE FOR CAMAC 6. Performing Organization Code 7. Author(s) 8. Performing Organization Report No. Robert W. Bercaw, Theodore E. Fessler, and Jeffrey M. Arnold E-6957 10. Work Unit No. 9. Performing Organization Name and Address 503-10 Lewis Research Center 11. Contract or Grant No. National Aeronautics and Space Administration Cleveland, Ohio 44135 13. Type of Report and Period Covered 12. Sponsoring Agency Name and Address Technical Note National Aeronautics and Space Administration 14. Sponsoring Agency Code Washington, B.C. 20546 15. Supplementary Notes 16. Abstract An interface has been developed for CAMAC instrumentation systems that implements data transfers controlled either by the computer CPU or by an autonomous (data-channel) processor in the interface unit. The data channel processor executes programs stored in the computer memory. These programs consist of standard CAMAC module commands plus special control characters and commands for the processor itself. The interface was built for the PDP-15 computer, which has an 18-bit word structure, but both 18- and 24-bit data transfers can be made. A software system has been written that exploits the many features of the processor. 17. Key Words (Suggested by Author(s)) 18. -

Mi!!Lxlosalamos SCIENTIFIC LABORATORY
LA=8902-MS C3b ClC-l 4 REPORT COLLECTION REPRODUCTION COPY VAXNMS Benchmarking 1-’ > .— u) 9 g .— mi!!lxLOS ALAMOS SCIENTIFIC LABORATORY Post Office Box 1663 Los Alamos. New Mexico 87545 — wAifiimative Action/Equal Opportunity Employer b . l)lS(”L,\l\ll K “Thisreport wm prcpmd J, an xcttunt ,,1”wurk ,pmwrd by an dgmcy d the tlnitwl SIdtcs (kvcm. mm:. Ncit her t hc llniml SIJIL.. ( Lwcrnmcm nor any .gcncy tlhmd. nor my 08”Ihcif cmployccs. makci my wur,nly. mprcss w mphd. or JwImL.s m> lcg.d Iululity ur rcspmuhdily ltw Ilw w.cur- acy. .vmplctcncs. w uscftthtc>. ttt”any ml’ormdt ml. dpprdl us. prudu.i. w proccw didowd. or rep. resent%Ihd IIS us wuukl not mfrm$e priwtcly mvnd rqdtts. Itcl”crmcti herein 10 my sp.xi!l tom. mrcial ptotlucr. prtxcm. or S.rvskc hy tdc mmw. Irdcnmrl.. nmu(a.lurm. or dwrwi~.. does nut mmwsuily mnstitutc or reply its mdursmwnt. rccummcnddton. or favorin: by the llniwd States (“mvcmment ormy qxncy thctcd. rhc V!C$VSmd opinmm d .mthor% qmxd herein do nut net’. UMrily r;~lt or died lhow. ol”the llnttcd SIJIL.S( ;ovwnnwnt or my ugcncy lhure of. UNITED STATES .. DEPARTMENT OF ENERGY CONTRACT W-7405 -ENG. 36 . ... LA-8902-MS UC-32 Issued: July 1981 G- . VAX/VMS Benchmarking Larry Creel —. I . .._- -- ----- ,. .- .-. .: .- ,.. .. ., ..,..: , .. .., . ... ..... - .-, ..:. .. *._–: - . VAX/VMS BENCHMARKING by Larry Creel ABSTRACT Primary emphasis in this report is on the perform- ance of three Digital Equipment Corporation VAX-11/780 computers at the Los Alamos National Laboratory. Programs used in the study are part of the Laboratory’s set of benchmark programs. -

Application Note Saving Data During a Power Failure Using the Dataflash® E-Series Family
Saving Data During a Power Failure Using the DataFlash® E-Series Family Application Note Saving Data During a Power Failure Using the DataFlash® E-Series Family Abstract This application note is intended to provide readers with information on how to save critical data to the Flash memory of DataFlash E-Series devices in the event of a power failure. The power failure is simulated by removing power to the devices. This document does not discuss how the power failure is detected, how the microcontroller may respond to the failure, or how the power rail is controlled for both the DataFlash device and the microcontroller. Product Highlights • Single 3V Read/Write Operation (1.65V - 3.6V Supply Range) • SPI Mode 0 and Mode 3 Compatible • Fast Read Access Times: 85 MHz Maximum Clock Frequency • Individual Hardware and Software Sector Protection • Security: 128-byte Register • JEDEC Standard Manufacturer and Device ID Read • Endurance: 100,000 Program/Erase Cycles per Page Minimum • Data Retention: 20 Years • Packaging Options: SOIC, DFN, WLCSP, Die/Wafer • Green (Pb/Halide-free) Packaging Options Application Note 114 11-Dec-2020 AN114 1 of 13 © 2020 Dialog Semiconductor Saving Data During a Power Failure Using the DataFlash® E-Series Family Revision History Revision Date Description A0 11-Dec-2020 Initial Release Application Note 114 11-Dec-2020 AN114 2 of 13 © 2020 Dialog Semiconductor Saving Data During a Power Failure Using the DataFlash® E-Series Family 1 Introduction The DataFlash E-series family of Flash memory devices are often used in applications such as server configuration, data logging, event counters and failure/error/status loggers. -

14-/12-Bit, 250MSPS, Ultralow-Power ADC with Analog Buffers Check for Samples: ADS41B29, ADS41B49
ADS41B29 ADS41B49 www.ti.com SBAS486E – NOVEMBER 2009–REVISED JULY 2012 14-/12-Bit, 250MSPS, Ultralow-Power ADC with Analog Buffers Check for Samples: ADS41B29, ADS41B49 1FEATURES DESCRIPTION The ADS41B29/B49 are members of the ultralow- 23• ADS41B49: 14-Bit, 250MSPS ADS41B29: 12-Bit, 250MSPS power ADS4xxx analog-to-digital converter (ADC) family, featuring integrated analog input buffers. • Integrated High-Impedance These devices use innovative design techniques to Analog Input Buffer: achieve high dynamic performance, while consuming – Input Capacitance: 2pF extremely low power. The analog input pins have – 200MHz Input Resistance: 3kΩ buffers, with benefits of constant performance and input impedance across a wide frequency range. The • Maximum Sample Rate: 250MSPS devices are well-suited for multi-carrier, wide • Ultralow Power: bandwidth communications applications such as PA – 1.8V Analog Power: 180mW linearization. – 3.3V Buffer Power: 96mW The ADS41B49/29 have features such as digital gain – I/O Power: 135mW (DDR LVDS) and offset correction. The gain option can be used to improve SFDR performance at lower full-scale input • High Dynamic Performance: ranges, especially at high input frequencies. The – SNR: 69dBFS at 170MHz integrated dc offset correction loop can be used to – SFDR: 82.5dBc at 170MHz estimate and cancel the ADC offset. At lower sampling rates, the ADC automatically operates at • Output Interface: scaled-down power with no loss in performance. – Double Data Rate (DDR) LVDS with Programmable Swing and Strength: The devices support both double data rate (DDR) low-voltage differential signaling (LVDS) and parallel – Standard Swing: 350mV CMOS digital output interfaces. The low data rate of – Low Swing: 200mV the DDR LVDS interface (maximum 500MBPS) – Default Strength: 100Ω Termination makes it possible to use low-cost field-programmable gate array (FPGA)-based receivers.