DECADES JURIMETRICS Arxiv:2001.00476V1 [Cs.CY] 30 Dec
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Descriptive Statistics (Part 2): Interpreting Study Results
Statistical Notes II Descriptive statistics (Part 2): Interpreting study results A Cook and A Sheikh he previous paper in this series looked at ‘baseline’. Investigations of treatment effects can be descriptive statistics, showing how to use and made in similar fashion by comparisons of disease T interpret fundamental measures such as the probability in treated and untreated patients. mean and standard deviation. Here we continue with descriptive statistics, looking at measures more The relative risk (RR), also sometimes known as specific to medical research. We start by defining the risk ratio, compares the risk of exposed and risk and odds, the two basic measures of disease unexposed subjects, while the odds ratio (OR) probability. Then we show how the effect of a disease compares odds. A relative risk or odds ratio greater risk factor, or a treatment, can be measured using the than one indicates an exposure to be harmful, while relative risk or the odds ratio. Finally we discuss the a value less than one indicates a protective effect. ‘number needed to treat’, a measure derived from the RR = 1.2 means exposed people are 20% more likely relative risk, which has gained popularity because of to be diseased, RR = 1.4 means 40% more likely. its clinical usefulness. Examples from the literature OR = 1.2 means that the odds of disease is 20% higher are used to illustrate important concepts. in exposed people. RISK AND ODDS Among workers at factory two (‘exposed’ workers) The probability of an individual becoming diseased the risk is 13 / 116 = 0.11, compared to an ‘unexposed’ is the risk. -

Teacher Guide 12.1 Gambling Page 1
TEACHER GUIDE 12.1 GAMBLING PAGE 1 Standard 12: The student will explain and evaluate the financial impact and consequences of gambling. Risky Business Priority Academic Student Skills Personal Financial Literacy Objective 12.1: Analyze the probabilities involved in winning at games of chance. Objective 12.2: Evaluate costs and benefits of gambling to Simone, Paula, and individuals and society (e.g., family budget; addictive behaviors; Randy meet in the library and the local and state economy). every afternoon to work on their homework. Here is what is going on. Ryan is flipping a coin, and he is not cheating. He has just flipped seven heads in a row. Is Ryan’s next flip more likely to be: Heads; Tails; or Heads and tails are equally likely. Paula says heads because the first seven were heads, so the next one will probably be heads too. Randy says tails. The first seven were heads, so the next one must be tails. Lesson Objectives Simone says that it could be either heads or tails Recognize gambling as a form of risk. because both are equally Calculate the probabilities of winning in games of chance. likely. Who is correct? Explore the potential benefits of gambling for society. Explore the potential costs of gambling for society. Evaluate the personal costs and benefits of gambling. © 2008. Oklahoma State Department of Education. All rights reserved. Teacher Guide 12.1 2 Personal Financial Literacy Vocabulary Dependent event: The outcome of one event affects the outcome of another, changing the TEACHING TIP probability of the second event. This lesson is based on risk. -

Odds: Gambling, Law and Strategy in the European Union Anastasios Kaburakis* and Ryan M Rodenberg†
63 Odds: Gambling, Law and Strategy in the European Union Anastasios Kaburakis* and Ryan M Rodenberg† Contemporary business law contributions argue that legal knowledge or ‘legal astuteness’ can lead to a sustainable competitive advantage.1 Past theses and treatises have led more academic research to endeavour the confluence between law and strategy.2 European scholars have engaged in the Proactive Law Movement, recently adopted and incorporated into policy by the European Commission.3 As such, the ‘many futures of legal strategy’ provide * Dr Anastasios Kaburakis is an assistant professor at the John Cook School of Business, Saint Louis University, teaching courses in strategic management, sports business and international comparative gaming law. He holds MS and PhD degrees from Indiana University-Bloomington and a law degree from Aristotle University in Thessaloniki, Greece. Prior to academia, he practised law in Greece and coached basketball at the professional club and national team level. He currently consults international sport federations, as well as gaming operators on regulatory matters and policy compliance strategies. † Dr Ryan Rodenberg is an assistant professor at Florida State University where he teaches sports law analytics. He earned his JD from the University of Washington-Seattle and PhD from Indiana University-Bloomington. Prior to academia, he worked at Octagon, Nike and the ATP World Tour. 1 See C Bagley, ‘What’s Law Got to Do With It?: Integrating Law and Strategy’ (2010) 47 American Business Law Journal 587; C -

3 Autocorrelation
3 Autocorrelation Autocorrelation refers to the correlation of a time series with its own past and future values. Autocorrelation is also sometimes called “lagged correlation” or “serial correlation”, which refers to the correlation between members of a series of numbers arranged in time. Positive autocorrelation might be considered a specific form of “persistence”, a tendency for a system to remain in the same state from one observation to the next. For example, the likelihood of tomorrow being rainy is greater if today is rainy than if today is dry. Geophysical time series are frequently autocorrelated because of inertia or carryover processes in the physical system. For example, the slowly evolving and moving low pressure systems in the atmosphere might impart persistence to daily rainfall. Or the slow drainage of groundwater reserves might impart correlation to successive annual flows of a river. Or stored photosynthates might impart correlation to successive annual values of tree-ring indices. Autocorrelation complicates the application of statistical tests by reducing the effective sample size. Autocorrelation can also complicate the identification of significant covariance or correlation between time series (e.g., precipitation with a tree-ring series). Autocorrelation implies that a time series is predictable, probabilistically, as future values are correlated with current and past values. Three tools for assessing the autocorrelation of a time series are (1) the time series plot, (2) the lagged scatterplot, and (3) the autocorrelation function. 3.1 Time series plot Positively autocorrelated series are sometimes referred to as persistent because positive departures from the mean tend to be followed by positive depatures from the mean, and negative departures from the mean tend to be followed by negative departures (Figure 3.1). -
3. Probability Theory
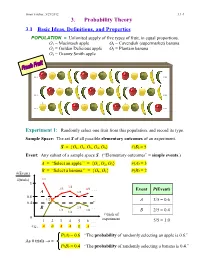
Ismor Fischer, 5/29/2012 3.1-1 3. Probability Theory 3.1 Basic Ideas, Definitions, and Properties POPULATION = Unlimited supply of five types of fruit, in equal proportions. O1 = Macintosh apple O4 = Cavendish (supermarket) banana O2 = Golden Delicious apple O5 = Plantain banana O3 = Granny Smith apple … … … … … … Experiment 1: Randomly select one fruit from this population, and record its type. Sample Space: The set S of all possible elementary outcomes of an experiment. S = {O1, O2, O3, O4, O5} #(S) = 5 Event: Any subset of a sample space S. (“Elementary outcomes” = simple events.) A = “Select an apple.” = {O1, O2, O3} #(A) = 3 B = “Select a banana.” = {O , O } #(B) = 2 #(Event) 4 5 #(trials) 1/1 1 3/4 2/3 4/6 . Event P(Event) A 3/5 0.6 1/2 A 3/5 = 0.6 0.4 B 2/5 . 1/3 2/6 1/4 B 2/5 = 0.4 # trials of 0 experiment 1 2 3 4 5 6 . 5/5 = 1.0 e.g., A B A A B A . P(A) = 0.6 “The probability of randomly selecting an apple is 0.6.” As # trials → ∞ P(B) = 0.4 “The probability of randomly selecting a banana is 0.4.” Ismor Fischer, 5/29/2012 3.1-2 General formulation may be facilitated with the use of a Venn diagram: Experiment ⇒ Sample Space: S = {O1, O2, …, Ok} #(S) = k A Om+1 Om+2 O2 O1 O3 Om+3 O 4 . Om . Ok Event A = {O1, O2, …, Om} ⊆ S #(A) = m ≤ k Definition: The probability of event A, denoted P(A), is the long-run relative frequency with which A is expected to occur, as the experiment is repeated indefinitely. -

Probability Cheatsheet V2.0 Thinking Conditionally Law of Total Probability (LOTP)
Probability Cheatsheet v2.0 Thinking Conditionally Law of Total Probability (LOTP) Let B1;B2;B3; :::Bn be a partition of the sample space (i.e., they are Compiled by William Chen (http://wzchen.com) and Joe Blitzstein, Independence disjoint and their union is the entire sample space). with contributions from Sebastian Chiu, Yuan Jiang, Yuqi Hou, and Independent Events A and B are independent if knowing whether P (A) = P (AjB )P (B ) + P (AjB )P (B ) + ··· + P (AjB )P (B ) Jessy Hwang. Material based on Joe Blitzstein's (@stat110) lectures 1 1 2 2 n n A occurred gives no information about whether B occurred. More (http://stat110.net) and Blitzstein/Hwang's Introduction to P (A) = P (A \ B1) + P (A \ B2) + ··· + P (A \ Bn) formally, A and B (which have nonzero probability) are independent if Probability textbook (http://bit.ly/introprobability). Licensed and only if one of the following equivalent statements holds: For LOTP with extra conditioning, just add in another event C! under CC BY-NC-SA 4.0. Please share comments, suggestions, and errors at http://github.com/wzchen/probability_cheatsheet. P (A \ B) = P (A)P (B) P (AjC) = P (AjB1;C)P (B1jC) + ··· + P (AjBn;C)P (BnjC) P (AjB) = P (A) P (AjC) = P (A \ B1jC) + P (A \ B2jC) + ··· + P (A \ BnjC) P (BjA) = P (B) Last Updated September 4, 2015 Special case of LOTP with B and Bc as partition: Conditional Independence A and B are conditionally independent P (A) = P (AjB)P (B) + P (AjBc)P (Bc) given C if P (A \ BjC) = P (AjC)P (BjC). -

The Bayesian Approach to Statistics
THE BAYESIAN APPROACH TO STATISTICS ANTHONY O’HAGAN INTRODUCTION the true nature of scientific reasoning. The fi- nal section addresses various features of modern By far the most widely taught and used statisti- Bayesian methods that provide some explanation for the rapid increase in their adoption since the cal methods in practice are those of the frequen- 1980s. tist school. The ideas of frequentist inference, as set out in Chapter 5 of this book, rest on the frequency definition of probability (Chapter 2), BAYESIAN INFERENCE and were developed in the first half of the 20th century. This chapter concerns a radically differ- We first present the basic procedures of Bayesian ent approach to statistics, the Bayesian approach, inference. which depends instead on the subjective defini- tion of probability (Chapter 3). In some respects, Bayesian methods are older than frequentist ones, Bayes’s Theorem and the Nature of Learning having been the basis of very early statistical rea- Bayesian inference is a process of learning soning as far back as the 18th century. Bayesian from data. To give substance to this statement, statistics as it is now understood, however, dates we need to identify who is doing the learning and back to the 1950s, with subsequent development what they are learning about. in the second half of the 20th century. Over that time, the Bayesian approach has steadily gained Terms and Notation ground, and is now recognized as a legitimate al- ternative to the frequentist approach. The person doing the learning is an individual This chapter is organized into three sections. -

Empire, Trade, and the Use of Agents in the 19Th Century: the “Reception” of the Undisclosed Principal Rule in Louisiana Law and Scots Law
Louisiana Law Review Volume 79 Number 4 Summer 2019 Article 6 6-19-2019 Empire, Trade, and the Use of Agents in the 19th Century: The “Reception” of the Undisclosed Principal Rule in Louisiana Law and Scots Law Laura Macgregor Follow this and additional works at: https://digitalcommons.law.lsu.edu/lalrev Part of the Agency Commons, and the Commercial Law Commons Repository Citation Laura Macgregor, Empire, Trade, and the Use of Agents in the 19th Century: The “Reception” of the Undisclosed Principal Rule in Louisiana Law and Scots Law, 79 La. L. Rev. (2019) Available at: https://digitalcommons.law.lsu.edu/lalrev/vol79/iss4/6 This Article is brought to you for free and open access by the Law Reviews and Journals at LSU Law Digital Commons. It has been accepted for inclusion in Louisiana Law Review by an authorized editor of LSU Law Digital Commons. For more information, please contact [email protected]. Empire, Trade, and the Use of Agents in the 19th Century: The “Reception” of the Undisclosed Principal Rule in Louisiana Law and Scots Law Laura Macgregor* TABLE OF CONTENTS Introduction .................................................................................. 986 I. The Nature and Economic Benefits of Undisclosed Agency ..................................................................... 992 II. The Concept of a “Mixed Legal System” and Agency Law in Mixed Legal System Scholarship ....................... 997 III. Nature and Historical Development of Scots Law ..................... 1002 A. The Reception of Roman Law ............................................. 1002 B. The Institutional Period and Union with England ............... 1004 C. The Development of Scots Commercial Law ...................... 1006 D. When Did Scots Law Become Mixed in Nature? ................ 1008 IV. Undisclosed and Unidentified Agency in English Law ............ -

Using Epidemiological Evidence in Tort Law: a Practical Guide Aleksandra Kobyasheva
Using epidemiological evidence in tort law: a practical guide Aleksandra Kobyasheva Introduction Epidemiology is the study of disease patterns in populations which seeks to identify and understand causes of disease. By using this data to predict how and when diseases are likely to arise, it aims to prevent the disease and its consequences through public health regulation or the development of medication. But can this data also be used to tell us something about an event that has already occurred? To illustrate, consider a case where a claimant is exposed to a substance due to the defendant’s negligence and subsequently contracts a disease. There is not enough evidence available to satisfy the traditional ‘but-for’ test of causation.1 However, an epidemiological study shows that there is a potential causal link between the substance and the disease. What is, or what should be, the significance of this study? In Sienkiewicz v Greif members of the Supreme Court were sceptical that epidemiological evidence can have a useful role to play in determining questions of causation.2 The issue in that case was a narrow one that did not present the full range of concerns raised by epidemiological evidence, but the court’s general attitude was not unusual. Few English courts have thought seriously about the ways in which epidemiological evidence should be approached or interpreted; in particular, the factors which should be taken into account when applying the ‘balance of probability’ test, or the weight which should be attached to such factors. As a result, this article aims to explore this question from a practical perspective. -

Analysis of Scientific Research on Eyewitness Identification
ANALYSIS OF SCIENTIFIC RESEARCH ON EYEWITNESS IDENTIFICATION January 2018 Patricia A. Riley U.S. Attorney’s Office, DC Table of Contents RESEARCH DOES NOT PROVIDE A FIRM FOUNDATION FOR JURY INSTRUCTIONS OF THE TYPE ADOPTED BY SOME COURTS OR, IN SOME INSTANCES, FOR EXPERT TESTIMONY ...................................................... 6 RESEARCH DOES NOT PROVIDE A FIRM FOUNDATION FOR JURY INSTRUCTIONS OF THE TYPE ADOPTED BY SOME COURTS AND, IN SOME INSTANCES, FOR EXPERT TESTIMONY .................................................... 8 Introduction ............................................................................................................................................. 8 Courts should not comment on the evidence or take judicial notice of contested facts ................... 11 Jury Instructions based on flawed or outdated research should not be given .................................. 12 AN OVERVIEW OF THE RESEARCH ON EYEWITNESS IDENTIFICATION OF STRANGERS, NEW AND OLD .... 16 Important Points .................................................................................................................................... 16 System Variables .................................................................................................................................... 16 Simultaneous versus sequential presentation ................................................................................... 16 Double blind, blind, blinded administration (unless impracticable ................................................... -

A Review of Graph and Network Complexity from an Algorithmic Information Perspective
entropy Review A Review of Graph and Network Complexity from an Algorithmic Information Perspective Hector Zenil 1,2,3,4,5,*, Narsis A. Kiani 1,2,3,4 and Jesper Tegnér 2,3,4,5 1 Algorithmic Dynamics Lab, Centre for Molecular Medicine, Karolinska Institute, 171 77 Stockholm, Sweden; [email protected] 2 Unit of Computational Medicine, Department of Medicine, Karolinska Institute, 171 77 Stockholm, Sweden; [email protected] 3 Science for Life Laboratory (SciLifeLab), 171 77 Stockholm, Sweden 4 Algorithmic Nature Group, Laboratoire de Recherche Scientifique (LABORES) for the Natural and Digital Sciences, 75005 Paris, France 5 Biological and Environmental Sciences and Engineering Division (BESE), King Abdullah University of Science and Technology (KAUST), Thuwal 23955, Saudi Arabia * Correspondence: [email protected] or [email protected] Received: 21 June 2018; Accepted: 20 July 2018; Published: 25 July 2018 Abstract: Information-theoretic-based measures have been useful in quantifying network complexity. Here we briefly survey and contrast (algorithmic) information-theoretic methods which have been used to characterize graphs and networks. We illustrate the strengths and limitations of Shannon’s entropy, lossless compressibility and algorithmic complexity when used to identify aspects and properties of complex networks. We review the fragility of computable measures on the one hand and the invariant properties of algorithmic measures on the other demonstrating how current approaches to algorithmic complexity are misguided and suffer of similar limitations than traditional statistical approaches such as Shannon entropy. Finally, we review some current definitions of algorithmic complexity which are used in analyzing labelled and unlabelled graphs. This analysis opens up several new opportunities to advance beyond traditional measures. -

Introduction to Bayesian Inference and Modeling Edps 590BAY
Introduction to Bayesian Inference and Modeling Edps 590BAY Carolyn J. Anderson Department of Educational Psychology c Board of Trustees, University of Illinois Fall 2019 Introduction What Why Probability Steps Example History Practice Overview ◮ What is Bayes theorem ◮ Why Bayesian analysis ◮ What is probability? ◮ Basic Steps ◮ An little example ◮ History (not all of the 705+ people that influenced development of Bayesian approach) ◮ In class work with probabilities Depending on the book that you select for this course, read either Gelman et al. Chapter 1 or Kruschke Chapters 1 & 2. C.J. Anderson (Illinois) Introduction Fall 2019 2.2/ 29 Introduction What Why Probability Steps Example History Practice Main References for Course Throughout the coures, I will take material from ◮ Gelman, A., Carlin, J.B., Stern, H.S., Dunson, D.B., Vehtari, A., & Rubin, D.B. (20114). Bayesian Data Analysis, 3rd Edition. Boco Raton, FL, CRC/Taylor & Francis.** ◮ Hoff, P.D., (2009). A First Course in Bayesian Statistical Methods. NY: Sringer.** ◮ McElreath, R.M. (2016). Statistical Rethinking: A Bayesian Course with Examples in R and Stan. Boco Raton, FL, CRC/Taylor & Francis. ◮ Kruschke, J.K. (2015). Doing Bayesian Data Analysis: A Tutorial with JAGS and Stan. NY: Academic Press.** ** There are e-versions these of from the UofI library. There is a verson of McElreath, but I couldn’t get if from UofI e-collection. C.J. Anderson (Illinois) Introduction Fall 2019 3.3/ 29 Introduction What Why Probability Steps Example History Practice Bayes Theorem A whole semester on this? p(y|θ)p(θ) p(θ|y)= p(y) where ◮ y is data, sample from some population.