Medical Statistics PDF File 9
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Descriptive Statistics (Part 2): Interpreting Study Results
Statistical Notes II Descriptive statistics (Part 2): Interpreting study results A Cook and A Sheikh he previous paper in this series looked at ‘baseline’. Investigations of treatment effects can be descriptive statistics, showing how to use and made in similar fashion by comparisons of disease T interpret fundamental measures such as the probability in treated and untreated patients. mean and standard deviation. Here we continue with descriptive statistics, looking at measures more The relative risk (RR), also sometimes known as specific to medical research. We start by defining the risk ratio, compares the risk of exposed and risk and odds, the two basic measures of disease unexposed subjects, while the odds ratio (OR) probability. Then we show how the effect of a disease compares odds. A relative risk or odds ratio greater risk factor, or a treatment, can be measured using the than one indicates an exposure to be harmful, while relative risk or the odds ratio. Finally we discuss the a value less than one indicates a protective effect. ‘number needed to treat’, a measure derived from the RR = 1.2 means exposed people are 20% more likely relative risk, which has gained popularity because of to be diseased, RR = 1.4 means 40% more likely. its clinical usefulness. Examples from the literature OR = 1.2 means that the odds of disease is 20% higher are used to illustrate important concepts. in exposed people. RISK AND ODDS Among workers at factory two (‘exposed’ workers) The probability of an individual becoming diseased the risk is 13 / 116 = 0.11, compared to an ‘unexposed’ is the risk. -

Teacher Guide 12.1 Gambling Page 1
TEACHER GUIDE 12.1 GAMBLING PAGE 1 Standard 12: The student will explain and evaluate the financial impact and consequences of gambling. Risky Business Priority Academic Student Skills Personal Financial Literacy Objective 12.1: Analyze the probabilities involved in winning at games of chance. Objective 12.2: Evaluate costs and benefits of gambling to Simone, Paula, and individuals and society (e.g., family budget; addictive behaviors; Randy meet in the library and the local and state economy). every afternoon to work on their homework. Here is what is going on. Ryan is flipping a coin, and he is not cheating. He has just flipped seven heads in a row. Is Ryan’s next flip more likely to be: Heads; Tails; or Heads and tails are equally likely. Paula says heads because the first seven were heads, so the next one will probably be heads too. Randy says tails. The first seven were heads, so the next one must be tails. Lesson Objectives Simone says that it could be either heads or tails Recognize gambling as a form of risk. because both are equally Calculate the probabilities of winning in games of chance. likely. Who is correct? Explore the potential benefits of gambling for society. Explore the potential costs of gambling for society. Evaluate the personal costs and benefits of gambling. © 2008. Oklahoma State Department of Education. All rights reserved. Teacher Guide 12.1 2 Personal Financial Literacy Vocabulary Dependent event: The outcome of one event affects the outcome of another, changing the TEACHING TIP probability of the second event. This lesson is based on risk. -

Limitations of the Odds Ratio in Gauging the Performance of a Diagnostic, Prognostic, Or Screening Marker
American Journal of Epidemiology Vol. 159, No. 9 Copyright © 2004 by the Johns Hopkins Bloomberg School of Public Health Printed in U.S.A. All rights reserved DOI: 10.1093/aje/kwh101 Limitations of the Odds Ratio in Gauging the Performance of a Diagnostic, Prognostic, or Screening Marker Margaret Sullivan Pepe1,2, Holly Janes2, Gary Longton1, Wendy Leisenring1,2,3, and Polly Newcomb1 1 Division of Public Health Sciences, Fred Hutchinson Cancer Research Center, Seattle, WA. 2 Department of Biostatistics, University of Washington, Seattle, WA. 3 Division of Clinical Research, Fred Hutchinson Cancer Research Center, Seattle, WA. Downloaded from Received for publication June 24, 2003; accepted for publication October 28, 2003. A marker strongly associated with outcome (or disease) is often assumed to be effective for classifying persons http://aje.oxfordjournals.org/ according to their current or future outcome. However, for this assumption to be true, the associated odds ratio must be of a magnitude rarely seen in epidemiologic studies. In this paper, an illustration of the relation between odds ratios and receiver operating characteristic curves shows, for example, that a marker with an odds ratio of as high as 3 is in fact a very poor classification tool. If a marker identifies 10% of controls as positive (false positives) and has an odds ratio of 3, then it will correctly identify only 25% of cases as positive (true positives). The authors illustrate that a single measure of association such as an odds ratio does not meaningfully describe a marker’s ability to classify subjects. Appropriate statistical methods for assessing and reporting the classification power of a marker are described. -

Guidance for Industry E2E Pharmacovigilance Planning
Guidance for Industry E2E Pharmacovigilance Planning U.S. Department of Health and Human Services Food and Drug Administration Center for Drug Evaluation and Research (CDER) Center for Biologics Evaluation and Research (CBER) April 2005 ICH Guidance for Industry E2E Pharmacovigilance Planning Additional copies are available from: Office of Training and Communication Division of Drug Information, HFD-240 Center for Drug Evaluation and Research Food and Drug Administration 5600 Fishers Lane Rockville, MD 20857 (Tel) 301-827-4573 http://www.fda.gov/cder/guidance/index.htm Office of Communication, Training and Manufacturers Assistance, HFM-40 Center for Biologics Evaluation and Research Food and Drug Administration 1401 Rockville Pike, Rockville, MD 20852-1448 http://www.fda.gov/cber/guidelines.htm. (Tel) Voice Information System at 800-835-4709 or 301-827-1800 U.S. Department of Health and Human Services Food and Drug Administration Center for Drug Evaluation and Research (CDER) Center for Biologics Evaluation and Research (CBER) April 2005 ICH Contains Nonbinding Recommendations TABLE OF CONTENTS I. INTRODUCTION (1, 1.1) ................................................................................................... 1 A. Background (1.2) ..................................................................................................................2 B. Scope of the Guidance (1.3)...................................................................................................2 II. SAFETY SPECIFICATION (2) ..................................................................................... -

Relative Risks, Odds Ratios and Cluster Randomised Trials . (1)
1 Relative Risks, Odds Ratios and Cluster Randomised Trials Michael J Campbell, Suzanne Mason, Jon Nicholl Abstract It is well known in cluster randomised trials with a binary outcome and a logistic link that the population average model and cluster specific model estimate different population parameters for the odds ratio. However, it is less well appreciated that for a log link, the population parameters are the same and a log link leads to a relative risk. This suggests that for a prospective cluster randomised trial the relative risk is easier to interpret. Commonly the odds ratio and the relative risk have similar values and are interpreted similarly. However, when the incidence of events is high they can differ quite markedly, and it is unclear which is the better parameter . We explore these issues in a cluster randomised trial, the Paramedic Practitioner Older People’s Support Trial3 . Key words: Cluster randomized trials, odds ratio, relative risk, population average models, random effects models 1 Introduction Given two groups, with probabilities of binary outcomes of π0 and π1 , the Odds Ratio (OR) of outcome in group 1 relative to group 0 is related to Relative Risk (RR) by: . If there are covariates in the model , one has to estimate π0 at some covariate combination. One can see from this relationship that if the relative risk is small, or the probability of outcome π0 is small then the odds ratio and the relative risk will be close. One can also show, using the delta method, that approximately (1). ________________________________________________________________________________ Michael J Campbell, Medical Statistics Group, ScHARR, Regent Court, 30 Regent St, Sheffield S1 4DA [email protected] 2 Note that this result is derived for non-clustered data. -

Odds: Gambling, Law and Strategy in the European Union Anastasios Kaburakis* and Ryan M Rodenberg†
63 Odds: Gambling, Law and Strategy in the European Union Anastasios Kaburakis* and Ryan M Rodenberg† Contemporary business law contributions argue that legal knowledge or ‘legal astuteness’ can lead to a sustainable competitive advantage.1 Past theses and treatises have led more academic research to endeavour the confluence between law and strategy.2 European scholars have engaged in the Proactive Law Movement, recently adopted and incorporated into policy by the European Commission.3 As such, the ‘many futures of legal strategy’ provide * Dr Anastasios Kaburakis is an assistant professor at the John Cook School of Business, Saint Louis University, teaching courses in strategic management, sports business and international comparative gaming law. He holds MS and PhD degrees from Indiana University-Bloomington and a law degree from Aristotle University in Thessaloniki, Greece. Prior to academia, he practised law in Greece and coached basketball at the professional club and national team level. He currently consults international sport federations, as well as gaming operators on regulatory matters and policy compliance strategies. † Dr Ryan Rodenberg is an assistant professor at Florida State University where he teaches sports law analytics. He earned his JD from the University of Washington-Seattle and PhD from Indiana University-Bloomington. Prior to academia, he worked at Octagon, Nike and the ATP World Tour. 1 See C Bagley, ‘What’s Law Got to Do With It?: Integrating Law and Strategy’ (2010) 47 American Business Law Journal 587; C -

The Statistical Significance of Randomized Controlled Trial Results Is Frequently Fragile: a Case for a Fragility Index
The statistical significance of randomized controlled trial results is frequently fragile: A case for a Fragility Index Walsh, M., Srinathan, S. K., McAuley, D. F., Mrkobrada, M., Levine, O., Ribic, C., Molnar, A. O., Dattani, N. D., Burke, A., Guyatt, G., Thabane, L., Walter, S. D., Pogue, J., & Devereaux, P. J. (2014). The statistical significance of randomized controlled trial results is frequently fragile: A case for a Fragility Index. Journal of Clinical Epidemiology, 67(6), 622-628. https://doi.org/10.1016/j.jclinepi.2013.10.019 Published in: Journal of Clinical Epidemiology Document Version: Publisher's PDF, also known as Version of record Queen's University Belfast - Research Portal: Link to publication record in Queen's University Belfast Research Portal Publisher rights 2014 The Authors. Published by Elsevier Inc. This is an open access article published under a Creative Commons Attribution-NonCommercial-NoDerivs License (https://creativecommons.org/licenses/by-nc-nd/3.0/), which permits distribution and reproduction for non-commercial purposes, provided the author and source are cited. General rights Copyright for the publications made accessible via the Queen's University Belfast Research Portal is retained by the author(s) and / or other copyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associated with these rights. Take down policy The Research Portal is Queen's institutional repository that provides access to Queen's research output. Every effort has been made to ensure that content in the Research Portal does not infringe any person's rights, or applicable UK laws. -
3. Probability Theory
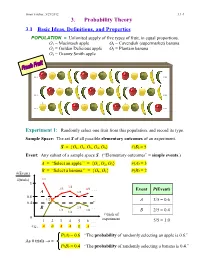
Ismor Fischer, 5/29/2012 3.1-1 3. Probability Theory 3.1 Basic Ideas, Definitions, and Properties POPULATION = Unlimited supply of five types of fruit, in equal proportions. O1 = Macintosh apple O4 = Cavendish (supermarket) banana O2 = Golden Delicious apple O5 = Plantain banana O3 = Granny Smith apple … … … … … … Experiment 1: Randomly select one fruit from this population, and record its type. Sample Space: The set S of all possible elementary outcomes of an experiment. S = {O1, O2, O3, O4, O5} #(S) = 5 Event: Any subset of a sample space S. (“Elementary outcomes” = simple events.) A = “Select an apple.” = {O1, O2, O3} #(A) = 3 B = “Select a banana.” = {O , O } #(B) = 2 #(Event) 4 5 #(trials) 1/1 1 3/4 2/3 4/6 . Event P(Event) A 3/5 0.6 1/2 A 3/5 = 0.6 0.4 B 2/5 . 1/3 2/6 1/4 B 2/5 = 0.4 # trials of 0 experiment 1 2 3 4 5 6 . 5/5 = 1.0 e.g., A B A A B A . P(A) = 0.6 “The probability of randomly selecting an apple is 0.6.” As # trials → ∞ P(B) = 0.4 “The probability of randomly selecting a banana is 0.4.” Ismor Fischer, 5/29/2012 3.1-2 General formulation may be facilitated with the use of a Venn diagram: Experiment ⇒ Sample Space: S = {O1, O2, …, Ok} #(S) = k A Om+1 Om+2 O2 O1 O3 Om+3 O 4 . Om . Ok Event A = {O1, O2, …, Om} ⊆ S #(A) = m ≤ k Definition: The probability of event A, denoted P(A), is the long-run relative frequency with which A is expected to occur, as the experiment is repeated indefinitely. -

Why Do You Need a Biostatistician? Antonia Zapf1* , Geraldine Rauch2 and Meinhard Kieser3
Zapf et al. BMC Medical Research Methodology (2020) 20:23 https://doi.org/10.1186/s12874-020-0916-4 DEBATE Open Access Why do you need a biostatistician? Antonia Zapf1* , Geraldine Rauch2 and Meinhard Kieser3 Abstract The quality of medical research importantly depends, among other aspects, on a valid statistical planning of the study, analysis of the data, and reporting of the results, which is usually guaranteed by a biostatistician. However, there are several related professions next to the biostatistician, for example epidemiologists, medical informaticians and bioinformaticians. For medical experts, it is often not clear what the differences between these professions are and how the specific role of a biostatistician can be described. For physicians involved in medical research, this is problematic because false expectations often lead to frustration on both sides. Therefore, the aim of this article is to outline the tasks and responsibilities of biostatisticians in clinical trials as well as in other fields of application in medical research. Keywords: Medical research, Biostatistician, Tasks, Responsibilities Background Biometric Society (IBS) provides a definition of biomet- What is a biostatistician, what does he or she actually do rics as a ‘field of development of statistical and mathem- and what distinguishes him or her from, for example, an atical methods applicable in the biological sciences’ [2]. epidemiologist? If we would ask this our main cooper- In here, we will focus on (human) medicine as area of ation partners like physicians or biologists, they probably application, but the results can be easily transferred to could not give a satisfying answer. This is problematic the other biological sciences like, for example, agricul- because false expectations often lead to frustration on ture or ecology. -

Probability Cheatsheet V2.0 Thinking Conditionally Law of Total Probability (LOTP)
Probability Cheatsheet v2.0 Thinking Conditionally Law of Total Probability (LOTP) Let B1;B2;B3; :::Bn be a partition of the sample space (i.e., they are Compiled by William Chen (http://wzchen.com) and Joe Blitzstein, Independence disjoint and their union is the entire sample space). with contributions from Sebastian Chiu, Yuan Jiang, Yuqi Hou, and Independent Events A and B are independent if knowing whether P (A) = P (AjB )P (B ) + P (AjB )P (B ) + ··· + P (AjB )P (B ) Jessy Hwang. Material based on Joe Blitzstein's (@stat110) lectures 1 1 2 2 n n A occurred gives no information about whether B occurred. More (http://stat110.net) and Blitzstein/Hwang's Introduction to P (A) = P (A \ B1) + P (A \ B2) + ··· + P (A \ Bn) formally, A and B (which have nonzero probability) are independent if Probability textbook (http://bit.ly/introprobability). Licensed and only if one of the following equivalent statements holds: For LOTP with extra conditioning, just add in another event C! under CC BY-NC-SA 4.0. Please share comments, suggestions, and errors at http://github.com/wzchen/probability_cheatsheet. P (A \ B) = P (A)P (B) P (AjC) = P (AjB1;C)P (B1jC) + ··· + P (AjBn;C)P (BnjC) P (AjB) = P (A) P (AjC) = P (A \ B1jC) + P (A \ B2jC) + ··· + P (A \ BnjC) P (BjA) = P (B) Last Updated September 4, 2015 Special case of LOTP with B and Bc as partition: Conditional Independence A and B are conditionally independent P (A) = P (AjB)P (B) + P (AjBc)P (Bc) given C if P (A \ BjC) = P (AjC)P (BjC). -

Understanding Relative Risk, Odds Ratio, and Related Terms: As Simple As It Can Get Chittaranjan Andrade, MD
Understanding Relative Risk, Odds Ratio, and Related Terms: As Simple as It Can Get Chittaranjan Andrade, MD Each month in his online Introduction column, Dr Andrade Many research papers present findings as odds ratios (ORs) and considers theoretical and relative risks (RRs) as measures of effect size for categorical outcomes. practical ideas in clinical Whereas these and related terms have been well explained in many psychopharmacology articles,1–5 this article presents a version, with examples, that is meant with a view to update the knowledge and skills to be both simple and practical. Readers may note that the explanations of medical practitioners and examples provided apply mostly to randomized controlled trials who treat patients with (RCTs), cohort studies, and case-control studies. Nevertheless, similar psychiatric conditions. principles operate when these concepts are applied in epidemiologic Department of Psychopharmacology, National Institute research. Whereas the terms may be applied slightly differently in of Mental Health and Neurosciences, Bangalore, India different explanatory texts, the general principles are the same. ([email protected]). ABSTRACT Clinical Situation Risk, and related measures of effect size (for Consider a hypothetical RCT in which 76 depressed patients were categorical outcomes) such as relative risks and randomly assigned to receive either venlafaxine (n = 40) or placebo odds ratios, are frequently presented in research (n = 36) for 8 weeks. During the trial, new-onset sexual dysfunction articles. Not all readers know how these statistics was identified in 8 patients treated with venlafaxine and in 3 patients are derived and interpreted, nor are all readers treated with placebo. These results are presented in Table 1. -

Outcome Reporting Bias in COVID-19 Mrna Vaccine Clinical Trials
medicina Perspective Outcome Reporting Bias in COVID-19 mRNA Vaccine Clinical Trials Ronald B. Brown School of Public Health and Health Systems, University of Waterloo, Waterloo, ON N2L3G1, Canada; [email protected] Abstract: Relative risk reduction and absolute risk reduction measures in the evaluation of clinical trial data are poorly understood by health professionals and the public. The absence of reported absolute risk reduction in COVID-19 vaccine clinical trials can lead to outcome reporting bias that affects the interpretation of vaccine efficacy. The present article uses clinical epidemiologic tools to critically appraise reports of efficacy in Pfzier/BioNTech and Moderna COVID-19 mRNA vaccine clinical trials. Based on data reported by the manufacturer for Pfzier/BioNTech vaccine BNT162b2, this critical appraisal shows: relative risk reduction, 95.1%; 95% CI, 90.0% to 97.6%; p = 0.016; absolute risk reduction, 0.7%; 95% CI, 0.59% to 0.83%; p < 0.000. For the Moderna vaccine mRNA-1273, the appraisal shows: relative risk reduction, 94.1%; 95% CI, 89.1% to 96.8%; p = 0.004; absolute risk reduction, 1.1%; 95% CI, 0.97% to 1.32%; p < 0.000. Unreported absolute risk reduction measures of 0.7% and 1.1% for the Pfzier/BioNTech and Moderna vaccines, respectively, are very much lower than the reported relative risk reduction measures. Reporting absolute risk reduction measures is essential to prevent outcome reporting bias in evaluation of COVID-19 vaccine efficacy. Keywords: mRNA vaccine; COVID-19 vaccine; vaccine efficacy; relative risk reduction; absolute risk reduction; number needed to vaccinate; outcome reporting bias; clinical epidemiology; critical appraisal; evidence-based medicine Citation: Brown, R.B.