Article (Published Version)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

List of Union Reference Dates A
Active substance name (INN) EU DLP BfArM / BAH DLP yearly PSUR 6-month-PSUR yearly PSUR bis DLP (List of Union PSUR Submission Reference Dates and Frequency (List of Union Frequency of Reference Dates and submission of Periodic Frequency of submission of Safety Update Reports, Periodic Safety Update 30 Nov. 2012) Reports, 30 Nov. -

Etats Rapides
List of European Pharmacopoeia Reference Standards Effective from 2015/12/24 Order Reference Standard Batch n° Quantity Sale Information Monograph Leaflet Storage Price Code per vial Unit Y0001756 Exemestane for system suitability 1 10 mg 1 2766 Yes +5°C ± 3°C 79 ! Y0001561 Abacavir sulfate 1 20 mg 1 2589 Yes +5°C ± 3°C 79 ! Y0001552 Abacavir for peak identification 1 10 mg 1 2589 Yes +5°C ± 3°C 79 ! Y0001551 Abacavir for system suitability 1 10 mg 1 2589 Yes +5°C ± 3°C 79 ! Y0000055 Acamprosate calcium - reference spectrum 1 n/a 1 1585 79 ! Y0000116 Acamprosate impurity A 1 50 mg 1 3-aminopropane-1-sulphonic acid 1585 Yes +5°C ± 3°C 79 ! Y0000500 Acarbose 3 100 mg 1 See leaflet ; Batch 2 is valid until 31 August 2015 2089 Yes +5°C ± 3°C 79 ! Y0000354 Acarbose for identification 1 10 mg 1 2089 Yes +5°C ± 3°C 79 ! Y0000427 Acarbose for peak identification 3 20 mg 1 Batch 2 is valid until 31 January 2015 2089 Yes +5°C ± 3°C 79 ! A0040000 Acebutolol hydrochloride 1 50 mg 1 0871 Yes +5°C ± 3°C 79 ! Y0000359 Acebutolol impurity B 2 10 mg 1 -[3-acetyl-4-[(2RS)-2-hydroxy-3-[(1-methylethyl)amino] propoxy]phenyl] 0871 Yes +5°C ± 3°C 79 ! acetamide (diacetolol) Y0000127 Acebutolol impurity C 1 20 mg 1 N-(3-acetyl-4-hydroxyphenyl)butanamide 0871 Yes +5°C ± 3°C 79 ! Y0000128 Acebutolol impurity I 2 0.004 mg 1 N-[3-acetyl-4-[(2RS)-3-(ethylamino)-2-hydroxypropoxy]phenyl] 0871 Yes +5°C ± 3°C 79 ! butanamide Y0000056 Aceclofenac - reference spectrum 1 n/a 1 1281 79 ! Y0000085 Aceclofenac impurity F 2 15 mg 1 benzyl[[[2-[(2,6-dichlorophenyl)amino]phenyl]acetyl]oxy]acetate -

Cardiac Sigma Receptors – an Update
Physiol. Res. 67 (Suppl. 4): S561-S576, 2018 https://doi.org/10.33549/physiolres.934052 REVIEW Cardiac Sigma Receptors – An Update T. STRACINA1, M. NOVAKOVA1 1Department of Physiology, Faculty of Medicine, Masaryk University, Brno, Czech Republic Received March 25, 2018 Accepted September 12, 2018 Summary (Martin et al. 1976). The authors believed that sigma More than four decades passed since sigma receptors were first receptor represents an opioid receptor subtype, which mentioned. Since then, existence of at least two receptor mediates psychomimetic and stimulatory behavioral subtypes and their tissue distributions have been proposed. effects of N-allylnormetazocine (SKF-10047) in chronic Nowadays, it is clear, that sigma receptors are unique ubiquitous spinal dog. Subsequent binding studies in guinea pig and proteins with pluripotent function, which can interact with so rat showed that binding profile of sigma receptor differs many different classes of proteins. As the endoplasmic resident from any other known subtype of opioid receptor as well proteins, they work as molecular chaperones – accompany as other receptor classes (Su 1982, Tam 1983). Therefore, various proteins during their folding, ensure trafficking of the the sigma receptor was defined as novel receptor type maturated proteins between cellular organelles and regulate their (Su 1982). functions. In the heart, sigma receptor type 1 is more dominant. Cardiac sigma 1 receptors regulate response to endoplasmic Two subtypes of sigma receptor reticulum stress, modulates calcium signaling in cardiomyocyte Further research led to differentiation among at and can affect function of voltage-gated ion channels. They least two subtypes of sigma receptors. Based on their contributed in pathophysiology of cardiac hypertrophy, heart diverse ligand selectivity and stereospecificity, association failure and many other cardiovascular disorders. -

Marrakesh Agreement Establishing the World Trade Organization
No. 31874 Multilateral Marrakesh Agreement establishing the World Trade Organ ization (with final act, annexes and protocol). Concluded at Marrakesh on 15 April 1994 Authentic texts: English, French and Spanish. Registered by the Director-General of the World Trade Organization, acting on behalf of the Parties, on 1 June 1995. Multilat ral Accord de Marrakech instituant l©Organisation mondiale du commerce (avec acte final, annexes et protocole). Conclu Marrakech le 15 avril 1994 Textes authentiques : anglais, français et espagnol. Enregistré par le Directeur général de l'Organisation mondiale du com merce, agissant au nom des Parties, le 1er juin 1995. Vol. 1867, 1-31874 4_________United Nations — Treaty Series • Nations Unies — Recueil des Traités 1995 Table of contents Table des matières Indice [Volume 1867] FINAL ACT EMBODYING THE RESULTS OF THE URUGUAY ROUND OF MULTILATERAL TRADE NEGOTIATIONS ACTE FINAL REPRENANT LES RESULTATS DES NEGOCIATIONS COMMERCIALES MULTILATERALES DU CYCLE D©URUGUAY ACTA FINAL EN QUE SE INCORPOR N LOS RESULTADOS DE LA RONDA URUGUAY DE NEGOCIACIONES COMERCIALES MULTILATERALES SIGNATURES - SIGNATURES - FIRMAS MINISTERIAL DECISIONS, DECLARATIONS AND UNDERSTANDING DECISIONS, DECLARATIONS ET MEMORANDUM D©ACCORD MINISTERIELS DECISIONES, DECLARACIONES Y ENTEND MIENTO MINISTERIALES MARRAKESH AGREEMENT ESTABLISHING THE WORLD TRADE ORGANIZATION ACCORD DE MARRAKECH INSTITUANT L©ORGANISATION MONDIALE DU COMMERCE ACUERDO DE MARRAKECH POR EL QUE SE ESTABLECE LA ORGANIZACI N MUND1AL DEL COMERCIO ANNEX 1 ANNEXE 1 ANEXO 1 ANNEX -

Federal Register / Vol. 60, No. 80 / Wednesday, April 26, 1995 / Notices DIX to the HTSUS—Continued
20558 Federal Register / Vol. 60, No. 80 / Wednesday, April 26, 1995 / Notices DEPARMENT OF THE TREASURY Services, U.S. Customs Service, 1301 TABLE 1.ÐPHARMACEUTICAL APPEN- Constitution Avenue NW, Washington, DIX TO THE HTSUSÐContinued Customs Service D.C. 20229 at (202) 927±1060. CAS No. Pharmaceutical [T.D. 95±33] Dated: April 14, 1995. 52±78±8 ..................... NORETHANDROLONE. A. W. Tennant, 52±86±8 ..................... HALOPERIDOL. Pharmaceutical Tables 1 and 3 of the Director, Office of Laboratories and Scientific 52±88±0 ..................... ATROPINE METHONITRATE. HTSUS 52±90±4 ..................... CYSTEINE. Services. 53±03±2 ..................... PREDNISONE. 53±06±5 ..................... CORTISONE. AGENCY: Customs Service, Department TABLE 1.ÐPHARMACEUTICAL 53±10±1 ..................... HYDROXYDIONE SODIUM SUCCI- of the Treasury. NATE. APPENDIX TO THE HTSUS 53±16±7 ..................... ESTRONE. ACTION: Listing of the products found in 53±18±9 ..................... BIETASERPINE. Table 1 and Table 3 of the CAS No. Pharmaceutical 53±19±0 ..................... MITOTANE. 53±31±6 ..................... MEDIBAZINE. Pharmaceutical Appendix to the N/A ............................. ACTAGARDIN. 53±33±8 ..................... PARAMETHASONE. Harmonized Tariff Schedule of the N/A ............................. ARDACIN. 53±34±9 ..................... FLUPREDNISOLONE. N/A ............................. BICIROMAB. 53±39±4 ..................... OXANDROLONE. United States of America in Chemical N/A ............................. CELUCLORAL. 53±43±0 -

Codeine and Its Alternates for Pain and Cough Relief
Codeine and its Alternates for Pain and Cough Relief 3. The Antitussive Action of Codeine-Mechanism, Methodology and Evaluation This report-the third of a series on codeine and its alternates for pain and cough relief-presents a detailed review of the physiology and pathophysiology of cough, the methods for the experimental and clinical measurement of the antitussive action of drugs, possible mechanisms of action of antitussive agents, and includes a compilation of experi mental results and clinical experience with codeine as an antitussive. CONTENTS INTRODUCTION 127 PHARMACOLOGICAL COMPONENTS OF THE ANTITUSSIVE EFFECT • MECHANISM AND SIGNIFICANCE OF COUGH 128 136 ANTITUSSIVE ACTION OF CODEINE 143 METHODS FOR THE STUDY OF ANTITUSSIVE RESUME 153 ACTION 130 REFERENCES 154 INTRODUCTION of codeine has increased greatly in recent years (see Part 4) but the popularity of codeine continues and Codeine was first used as a therapeutic antitussive its annual consumption remains at a high level, paral agent soon after its separation as an alkaloidal entity leling the high frequency of need for relief of cough (Martin, 1834) and some of the earliest accounts of as a symptom, especially chronic cough. Bickerman dosage and of the circumstances of its use are sum (1960) estimated, not so long ago, that 13% of the marized by K.rueger, Eddy & Sumwalt (1943). population of the United States of America was more Codeine has indeed dominated the picture with than 65 years old and that there were not less than respect to the symptomatic management of cough, 1 300 000 chronic coughers. Watt (1958) estimated with only minor variations, and this situation has that in the United Kingdom of Great Britain and been influenced little by the intro,duction of sub Northern Ireland 10% of all prescriptions were for stances claimed to be superior in effectiveness and cough relief. -

Review of Cough and Cold Medicines in Children
Review of cough and cold medicines in children 21 April 2009 Review of cough and cold medicines in children Contents 1. Terms of Reference ....................................................................................................3 2. Conflict of interest and disclaimer............................................................................4 3. Setting the scene........................................................................................................4 4. Current product availability and label claims ..........................................................5 5. ‘Coughs and colds’ – what are we treating? ............................................................7 6. Who uses these medicines? What do they expect from them? .............................8 7. Sedation: side-effect or desired effect? ...................................................................9 8. The need for better drugs ........................................................................................10 9. Epidemiology of childhood poisoning....................................................................10 10. Cough and cold medicines: Australia compared with US.................................12 11. TGA, cough and cold medicines and the general public...................................13 12. Dosage considerations.........................................................................................13 13. Review of the evidence.........................................................................................14 13.1 Antitussives -

Stembook 2018.Pdf
The use of stems in the selection of International Nonproprietary Names (INN) for pharmaceutical substances FORMER DOCUMENT NUMBER: WHO/PHARM S/NOM 15 WHO/EMP/RHT/TSN/2018.1 © World Health Organization 2018 Some rights reserved. This work is available under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 IGO licence (CC BY-NC-SA 3.0 IGO; https://creativecommons.org/licenses/by-nc-sa/3.0/igo). Under the terms of this licence, you may copy, redistribute and adapt the work for non-commercial purposes, provided the work is appropriately cited, as indicated below. In any use of this work, there should be no suggestion that WHO endorses any specific organization, products or services. The use of the WHO logo is not permitted. If you adapt the work, then you must license your work under the same or equivalent Creative Commons licence. If you create a translation of this work, you should add the following disclaimer along with the suggested citation: “This translation was not created by the World Health Organization (WHO). WHO is not responsible for the content or accuracy of this translation. The original English edition shall be the binding and authentic edition”. Any mediation relating to disputes arising under the licence shall be conducted in accordance with the mediation rules of the World Intellectual Property Organization. Suggested citation. The use of stems in the selection of International Nonproprietary Names (INN) for pharmaceutical substances. Geneva: World Health Organization; 2018 (WHO/EMP/RHT/TSN/2018.1). Licence: CC BY-NC-SA 3.0 IGO. Cataloguing-in-Publication (CIP) data. -

Review of Existing Classification Efforts
Project No. TREN-05-FP6TR-S07.61320-518404-DRUID DRUID Driving under the Influence of Drugs, Alcohol and Medicines Integrated Project 1.6. Sustainable Development, Global Change and Ecosystem 1.6.2: Sustainable Surface Transport 6th Framework Programme Deliverable 4.1.1 Review of existing classification efforts Due date of deliverable: (15.01.2008) Actual submission date: (07.02.2008) Start date of project: 15.10.2006 Duration: 48 months Organisation name of lead contractor for this deliverable: UGent Revision 1.0 Project co-funded by the European Commission within the Sixth Framework Programme (2002-2006) Dissemination Level PU Public X PP Restricted to other programme participants (including the Commission Services) RE Restricted to a group specified by the consortium (including the Commission Services) CO Confidential, only for members of the consortium (including the Commission Services) Task 4.1 : Review of existing classification efforts Authors: Kristof Pil, Elke Raes, Thomas Van den Neste, An-Sofie Goessaert, Jolien Veramme, Alain Verstraete (Ghent University, Belgium) Partners: - F. Javier Alvarez (work package leader), M. Trinidad Gómez-Talegón, Inmaculada Fierro (University of Valladolid, Spain) - Monica Colas, Juan Carlos Gonzalez-Luque (DGT, Spain) - Han de Gier, Sylvia Hummel, Sholeh Mobaser (University of Groningen, the Netherlands) - Martina Albrecht, Michael Heiβing (Bundesanstalt für Straßenwesen, Germany) - Michel Mallaret, Charles Mercier-Guyon (University of Grenoble, Centre Regional de Pharmacovigilance, France) - Vassilis Papakostopoulos, Villy Portouli, Andriani Mousadakou (Centre for Research and Technology Hellas, Greece) DRUID 6th Framework Programme Deliverable D.4.1.1. Revision 1.0 Review of Existing Classification Efforts Page 2 of 127 Introduction DRUID work package 4 focusses on the classification and labeling of medicinal drugs according to their influence on driving performance. -

Supplement Ii to the Japanese Pharmacopoeia Seventeenth Edition
SUPPLEMENT II TO THE JAPANESE PHARMACOPOEIA SEVENTEENTH EDITION O‹cial from June 28, 2019 English Version THE MINISTRY OF HEALTH, LABOUR AND WELFARE Notice: This English Version of the Japanese Pharmacopoeia is published for the convenience of users unfamiliar with the Japanese language. When and if any discrepancy arises between the Japanese original and its English translation, the former is authentic. Printed in Japan The Ministry of Health, Labour and Welfare Ministerial Notification No. 49 Pursuant to Paragraph 1, Article 41 of Act on Securing Quality, Efficacy and Safety of Products Including Pharmaceuticals and Medical Devices (Act No. 145, 1960), this notification stated that a part of the Japanese Pharmacopoeia was revised as follows*. NEMOTO Takumi The Minister of Health, Labour and Welfare June 28, 2019 A part of the Japanese Pharmacopoeia (Ministerial Notification No. 64, 2016) was revised as follows*. (The text referred to by the term ``as follows'' are omitted here. All of the revised Japanese Pharmacopoeia in accordance with this notification (hereinafter referred to as ``new Pharmacopoeia'' in Supplement 2) are made available for public exhibition at the Pharmaceutical Evaluation Division, Pharmaceutical Safety and Environmen- tal Health Bureau, Ministry of Health, Labour and Welfare, at each Regional Bureau of Health and Welfare, and at each Prefectural Office in Japan). Supplementary Provisions (Effective Date) Article 1 This Notification is applied from June 28, 2019. (Transitional measures) Article 2 In the case of drugs which are listed in the Japanese Pharmacopoeia (hereinafter referred to as ``previous Pharmacopoeia'') [limited to those listed in new Pharmacopoeia] and drugs which have been approved as of June 28, 2019 as prescribed under Paragraph 1, Article 14 of Act on Securing Quality, Efficacy and Safety of Products Including Pharmaceuticals and Medical Devices [including drugs the Minister of Health, Labour and Welfare specifies (the Ministry of Health and Welfare Ministerial Notification No. -

9: Analytical Standards
CATALOGUE NUMBER 9 ANALYTICAL STANDARDS Table of Contents Standards for Special Applications 3 Standards for Routine Analytical Applications 82 Certified Primary Pharmaceutical Standards 3 Environmental Standards 82 Certified GMO Materials 31 Particle Size Standards 115 Certified Clinical Chemistry Standards 33 Conductivity Standards 116 Other Certified Standards 34 Ion Chromatography Standards 116 Custom & OEM Standards 44 Redox Standards 117 Certified Industrial Raw Materials 44 Forensic & Veterinary Standards 117 Certified Drugs, Metabolites, & Impurities 45 Polymer Standards 126 Certified Food & Agriculture Standards 58 Petrochemical Standards 127 Proficiency Testing for Environmental Analysis 60 AAS/ICP Standards 130 Chromatography & CE Test Mixes 131 Selected Certified Reference Materials 64 TOC Standards 132 Environmental Standards 64 Melting Point Standards 132 Trace Cert Organics 75 Spectroscopy Standards—TraceCert 132 Occupational Hygiene Standards 76 MS Markers 134 Secondary Pharma Standards 76 Pharmaceutical & Clinical Standards 134 Titrimetric Substances 81 X-Ray Standards 135 Certified Spectroscopy Standards 81 Food & Beverage Standards 135 Gravimetry Standards 147 NMR Standards 147 Color Reference Solutions 148 Miscellaneous 148 NOTE: This publication is designed for electronic use only. Hazard and Safety information can be found on product detail pages and at sigma-aldrich.com/safetycenter. 2 Analytical Standards Technical Support: [email protected] Standards for Special Applications Certified Primary Pharmaceutical -
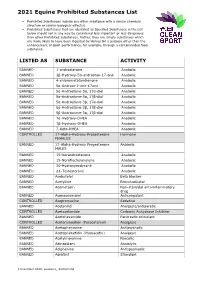
2021 Equine Prohibited Substances List
2021 Equine Prohibited Substances List . Prohibited Substances include any other substance with a similar chemical structure or similar biological effect(s). Prohibited Substances that are identified as Specified Substances in the List below should not in any way be considered less important or less dangerous than other Prohibited Substances. Rather, they are simply substances which are more likely to have been ingested by Horses for a purpose other than the enhancement of sport performance, for example, through a contaminated food substance. LISTED AS SUBSTANCE ACTIVITY BANNED 1-androsterone Anabolic BANNED 3β-Hydroxy-5α-androstan-17-one Anabolic BANNED 4-chlorometatandienone Anabolic BANNED 5α-Androst-2-ene-17one Anabolic BANNED 5α-Androstane-3α, 17α-diol Anabolic BANNED 5α-Androstane-3α, 17β-diol Anabolic BANNED 5α-Androstane-3β, 17α-diol Anabolic BANNED 5α-Androstane-3β, 17β-diol Anabolic BANNED 5β-Androstane-3α, 17β-diol Anabolic BANNED 7α-Hydroxy-DHEA Anabolic BANNED 7β-Hydroxy-DHEA Anabolic BANNED 7-Keto-DHEA Anabolic CONTROLLED 17-Alpha-Hydroxy Progesterone Hormone FEMALES BANNED 17-Alpha-Hydroxy Progesterone Anabolic MALES BANNED 19-Norandrosterone Anabolic BANNED 19-Noretiocholanolone Anabolic BANNED 20-Hydroxyecdysone Anabolic BANNED Δ1-Testosterone Anabolic BANNED Acebutolol Beta blocker BANNED Acefylline Bronchodilator BANNED Acemetacin Non-steroidal anti-inflammatory drug BANNED Acenocoumarol Anticoagulant CONTROLLED Acepromazine Sedative BANNED Acetanilid Analgesic/antipyretic CONTROLLED Acetazolamide Carbonic Anhydrase Inhibitor BANNED Acetohexamide Pancreatic stimulant CONTROLLED Acetominophen (Paracetamol) Analgesic BANNED Acetophenazine Antipsychotic BANNED Acetophenetidin (Phenacetin) Analgesic BANNED Acetylmorphine Narcotic BANNED Adinazolam Anxiolytic BANNED Adiphenine Antispasmodic BANNED Adrafinil Stimulant 1 December 2020, Lausanne, Switzerland 2021 Equine Prohibited Substances List . Prohibited Substances include any other substance with a similar chemical structure or similar biological effect(s).