Marco Infussi
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hungarian Keyboard Label Instructions and Specifications
Smart Keyboard Solutions 1855 E Southern Avenue, Suite #213 Mesa, AZ 85204 Phone: 877-477-1988 Visit our web site at: Buy this product online SmartKeyboardSolutions.com Hungarian Keyboard Label Instructions and Specifications Table of Contents Product Description Configuring Windows 8 for Hungarian Configuring Windows 7 for Hungarian Configuring Windows XP for Hungarian Configuring Microsoft Office for Hungarian How to Install the Labels How to Use the Keyboard Layout in Windows 8 How to Use the Keyboard Layout for Windows 7, Vista, and XP How to Type Hungarian Characters Product Features 1 Product Description: The Hungarian keyboard labels are clear labels with Hungarian characters on the right side. This allows you to convert any keyboard to a bilingual Hungarian keyboard. The labels are available in green (for light or beige colored keyboards) and white (for black keyboards). Language Compatibility. The Hungarian keyboard labels are compatible with the Windows keyboard layouts used for Hungary. The labels might be compatible with earlier versions of Windows, but they have not been tested to ensure complete compatibility. Windows Compatibility. The Hungarian keyboard labels are compatible with the Hungarian keyboard layouts in Windows 8, 7, Vista, and XP. The labels might be compatible with earlier versions of Windows, but they have not been tested to ensure complete compatibility. Hardware Compatibility. Most keyboards feature the printed characters in the upper left corner of the key or the left side of the key. However, some keyboards, such as Logitech® standard keyboards, feature the characters printed in the middle of the key. The Smart Keyboard Solutions Hungarian labels are designed to be compatible with keyboards that have the keys printed on the left. -

TECCS Tutorial on Keyboard Shortcuts
TECCS Computer Repairs & IT Services Keyboard Keys & Keyboard Shortcuts www.teccs.co.uk Contents Alt ..........................................................8 AltGr......................................................8 Document Information.....................................1 Ctrl..........................................................9 Author....................................................1 Shift........................................................9 Acknowledgements...............................1 Navigation Keys.................................................9 Publication Date....................................1 Arrow Keys............................................9 Category and Level...............................1 End..........................................................9 Getting Started...................................................2 Home......................................................9 Keyboard Keys & Keyboard Shortcuts Explained................................................2 Navigation Keys...............................................10 Tutorial Outline and Outcome............2 Page Down...........................................10 Tutorial Requirements.........................2 Page Up................................................10 Additional Requirements.....................2 Tab........................................................10 The Keyboard.....................................................3 System and GUI Keys......................................10 Character, Number and Symbol -

Turkish Q Keyboard Label Instructions and Specifications
Smart Keyboard Solutions 1855 E Southern Avenue, Suite #213 Mesa, AZ 85204 Phone: 877-477-1988 Visit our web site at: Buy this product online SmartKeyboardSolutions.com Turkish Q Keyboard Label Instructions and Specifications Table of Contents Configuring Windows 8 for Turkish Configuring Windows 7 and Vista for Turkish Q Configuring Windows XP for Turkish Q Configuring Microsoft Office for Turkish Q How to Install the Labels How to Use the Keyboard Layout in Windows 8 How to Use the Keyboard Layout in Windows 7, Vista, and XP How to Type Turkish Q Characters Product Features 1 Product Description: The Turkish Q keyboard labels are clear labels with Turkish Q characters on the right side. This allows you to convert any keyboard to a bilingual Turkish Q keyboard. The labels are available in green (for light or beige colored keyboards) and white (for black keyboards). Language Compatibility. The Turkish Q keyboard labels are compatible with the Windows Turkish Q keyboard layout. The Turkish F keyboard layout is widely used in Turkey; the Turkish Q keyboard layout is used everywhere else because it is very similar to the US QWERTY keyboard layout. Windows Compatibility. The Turkish Q keyboard labels are compatible with the Turkish Q keyboard layouts in Windows 8, 7, Vista, and XP. The labels might be compatible with other versions of Windows, but they have not been tested to ensure complete compatibility. Note: the Alt+Gr "T" character that is in Windows 8 does not appear in the sticker set. Hardware Compatibility. Most keyboards feature the printed characters in the upper left corner of the key or the left side of the key. -

Typing in Greek Sarah Abowitz Smith College Classics Department
Typing in Greek Sarah Abowitz Smith College Classics Department Windows 1. Down at the lower right corner of the screen, click the letters ENG, then select Language Preferences in the pop-up menu. If these letters are not present at the lower right corner of the screen, open Settings, click on Time & Language, then select Region & Language in the sidebar to get to the proper screen for step 2. 2. When this window opens, check if Ελληνικά/Greek is in the list of keyboards on your computer under Languages. If so, go to step 3. Otherwise, click Add A New Language. Clicking Add A New Language will take you to this window. Look for Ελληνικά/Greek and click it. When you click Ελληνικά/Greek, the language will be added and you will return to the previous screen. 3. Now that Ελληνικά is listed in your computer’s languages, click it and then click Options. 4. Click Add A Keyboard and add the Greek Polytonic option. If you started this tutorial without the pictured keyboard menu in step 1, it should be in the lower right corner of your screen now. 5. To start typing in Greek, click the letters ENG next to the clock in the lower right corner of the screen. Choose “Greek Polytonic keyboard” to start typing in greek, and click “US keyboard” again to go back to English. Mac 1. Click the apple button in the top left corner of your screen. From the drop-down menu, choose System Preferences. When the window below appears, click the “Keyboard” icon. -

E U R O P E a N C O M M I S S I
E U R O P E A N C O M M I S S I O N RECOMMENDATION FOR THE PLACEMENT OF THE EURO SIGN ON COMPUTER KEYBOARDS AND SIMILAR INFORMATION PROCESSING EQUIPMENT Status: Recommendation Latest Update : 19 / 06 / 1998 Author: Lazaros Tossounidis v. 1. 5. 1 FINAL PROPOSAL - 2 - Date: 19/06/98 UPDATE TO THE INITIAL DOCUMENT The current version of this document was finalised on the 19th of June 1998. Due to the agreements and the decisions made by the Commission since the appearance of the initial version of the document (7/10/97 - draft proposal) some statements contained previously in the initial version are no longer valid. However, for reasons of clarity and continuity, these statements were preserved in the current version. Where appropriate, newly added footnotes signal the changes that were made. The status of the present version of the document is: EC official recommendation. For more information, please contact: Mr. Jose Marin Address: European Commission Informatics Directorate Rue Alcide de Gasperi L - 2920, Luxembourg e-mail: [email protected] What is new in version 1.5 The version 1.5 includes the official resolution of the CEN/TC304 in regard with the present EC official recommendation (see below). The resolution was taken on the 4th of February 1998, during the plenary CEN/TC304 meeting in Brussels. It reads as follows: “ CEN/TC304 recognises that there is no need to develop a European keyboard layout standard based on the euro requirments only. However, CEN/TC304 recommends the implementation of the proposed recommendation from the European Commission (as described in doc N774) which matches what the IT industry and customers have requested. -

Get Started with Narrator Content Provided by Microsoft Applies To: Windows 10
Get started with Narrator Content provided by Microsoft Applies to: Windows 10 Narrator is a screen-reading app built into Windows 10. This guide describes how to use Narrator with the Windows 10 April 2018 Update on desktop PCs, providing you with enough info to start exploring Windows, using apps, and browsing the web. It’s written for those who use a screen reader regularly. To use this guide, choose a link from the following table of contents. When you’re done reading a chapter or appendix, select the Back button in your browser to return to this page and select another chapter. There are also links at the end of each chapter and appendix to go to the next chapter or return to this table of contents. Following the table of contents on this page, there is a section about what's new in Narrator in the Windows 10 April 2018 Update. Note This content is available online. This document was up to date as of July 17, 2018. You can also download a previous version in braille (US English non-UEB grade 2 braille). To obtain additional languages or grades, contact the Disability Answer Desk. Table of contents Chapter What's in it Chapter 1: Introducing An overview of Narrator including how to start and stop it. Narrator Chapter 2: Learning How to get around the screen, find and open apps, change Narrator basics what Narrator reads, and adjust speech rate and volume. Chapter 3: Using scan mode How to use scan mode to navigate apps, email, and the web. -

International Keyboard Layouts
29 319772 APP. E 8/24/00 6:38 PM Page 565 APPENDIX E International Keyboard Layouts This section contains illustrations of all the keyboard layouts available in Windows 2000 and earlier versions of Windows. Each layout is shown in several available states in addition to the normal state, when the other state provides a different mapping of keys: • With the Shift key depressed • With the Caps Lock key depressed • With the ALTGR key depressed • With combinations of the above keys depressed If you are using Windows 2000, all these keyboard layouts are available from the Regional Options applet in the Control Panel. For some locales, you must make sure that language support has been enabled on the General tab (see Figure E.1). Then, after a reboot, you can choose the Input Locales tab and add input locales as needed (see Figure E.2). For some locales, there are several possible keyboard layouts; all the ones that exist in Windows 2000 are included here. A Special Thank You Microsoft has graciously given me permission to include the illustrations of the keyboard layouts here, as well as to include the dynamic version of these layouts on the CD. A special note of thanks also goes to KD Chang (who created the layouts) and Cathy Wissink/John McConnell (who currently manage the keyboard layouts of all Microsoft products). 29 319772 APP. E 8/24/00 6:38 PM Page 566 566 Appendix E Figure E.1 Figure E.2 Enabling support for a language is Adding an input locale is also very easily done on the General tab of the easy to do in the proper tab of the Regional Options dialog. -

Version 12.0 Release Notes
The tool of thought for expert programming Release Notes Version 12.0 Copyright 1982-2008 by Dyalog Limited. All rights reserved. Version 12.0.3 First Edition July 2008 No part of this publication may be reproduced in any form by any means without the prior written permission of Dyalog Limited, South Barn, Minchens Court, Minchens Lane, Bramley, Hampshire, RG26 5BH, United Kingdom. Dyalog Limited makes no representations or warranties with respect to the contents hereof and specifically disclaims any implied warranties of merchantability or fitness for any particular purpose. Dyalog Limited reserves the right to revise this publication without notification. TRADEMARKS: Intel, 386 and 486 are registered trademarks of Intel Corporation. IBM is a registered trademark of International Business Machines Corporation. Microsoft, MS and MS-DOS are registered trademarks of Microsoft Corporation. POSTSCRIPT is a registered trademark of Adobe Systems, Inc. SQAPL is copyright of Insight Systems ApS. The Dyalog APL True Type font is the copyright of Adrian Smith. TrueType is a registered trademark of Apple Computer, Inc. UNIX is a trademark of X/Open Ltd. Windows, Windows NT, Visual Basic and Excel are trademarks of Microsoft Corporation. All other trademarks and copyrights are acknowledged. iii Contents Contents .........................................................................................................................iii C H A P T E R 1 Introduction....................................................................................1 -
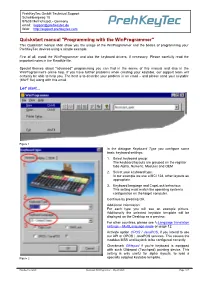
Quickstart Winprogrammer - May 20 2020 Page 1/27
PrehKeyTec GmbH Technical Support Scheinbergweg 10 97638 Mellrichstadt - Germany email: [email protected] Web: http://support.prehkeytec.com Quickstart manual "Programming with the WinProgrammer" This Quickstart manual shall show you the usage of the WinProgrammer and the basics of programming your PrehKeyTec devices using a simple example. First of all, install the WinProgrammer and also the keyboard drivers, if necessary. Please carefully read the important notes in the ReadMe file. Special themes about "advanced" programming you can find in the annex of this manual and also in the WinProgrammer's online help. If you have further problems when creating your keytable, our support team will certainly be able to help you. The best is to describe your problem in an email – and please send your keytable (MWF file) along with this email. Let' start... Figure 1 In the dialogue Keyboard Type you configure some basic keyboard settings: 1. Select keyboard group: The keyboard layouts are grouped on the register tabs Alpha, Numeric, Modules and OEM 2. Select your keyboard type: In our example we use a MCI 128, other layouts as appropriate. 3. Keyboard language and CapsLock behaviour: This setting must match the operating system's configuration on the target computer. Continue by pressing OK. Additional Information: For each type you will see an example picture. Additionally the selected keytable template will be displayed on the Desktop as a preview. For other countries, please see Language translation settings – MultiLanguage mode on page 12. Activate option OPOS / JavaPOS, if you intend to use our API or OPOS / JavaPOS services. This causes the modules MSR and keylock to be configured correctly. -

Guidance for the Production of Source Documents for Transcription Into Accessible Formats
G018 Guidance for the Production of Source Documents for Transcription into Accessible Formats Guidance from UKAAF UK Association for Accessible Formats (UKAAF) Because format quality matters Guidance for the Production of Source Documents for Transcription into Accessible Formats Why format quality matters "When organisations send me information in formats that I can read myself it allows me to be independent, feel informed and appreciated - just like every other customer." End-user "Producing consistently high quality accessible formats helps us to maintain our reputation, to gain new customers and to retain existing ones." Transcription agency "We are committed to ensuring that our customers with print disabilities receive the same information, of the same quality, as everyone else." Service provider Copyright © 2017 UK Association for Accessible Formats (UKAAF). Open University (OU) content reproduced with permission under Creative Commons License. Not for re-sale. You may reproduce in whole or in part with acknowledgement to UKAAF. Refer to inside back cover for citation guidance. Copyright © 2020 UK Association for Accessible Formats 3 Guidance for the Production of Source Documents for Transcription into Accessible Formats Who is this guidance for? This guidance from the UK Association for Accessible Formats (UKAAF) is primarily aimed at schools and academic institutions, awarding bodies, designers and transcribers. It will be particularly useful for any organisation producing an assessment in PDF format to ensure they are made accessible for candidates with print impairments. This document is guidance, for experienced desktop publishers: it is not a detailed training manual. Please refer to the Further Resources section for sources of training materials. -

Transliteration Keyboard Orientalistic Cuneiform Direct Keys Altgr Keys
Transliteration keyboard Orientalistic cuneiform (c) 2009 Alfredo Rizza1 Direct keys The standard charset UNICODE compatible with ANSI ISO-8859-1 is provided without resorting to dead keys through AltGr combinations. In doing so we can offer a single IME tool for normal ISO-8859-1 Latin charset that can be used for normal Latin-based scripts as well as for transliteration purposes that require special characters. Special characters are typed in using a AltGr - first key (dead key) - second key (compose key). In keyboards, such as the US one, where an AltGr key is not present, please use the Alt key on the right side of the keyboard. AltGr keys With AltGr we provide both direct alternative characters and dead keys to create special characters. Alternate characters (direct special characters) Some frequently used special characters utilized in transliteration, especially for cuneiform texts, are provided with a simple AltGr+key combination, e.g. AltGr+h = ḫ, AltGr+H (i.e. shift+h) = Ḫ A list of AltGr special characters is provided hereafter. Dead keys A dead key is selected by pressing AltGr together with a specific key, e.g. AltGr+a. First AltGr is to be pressed down, then, while still keeping AltGr down, press 'a'. Nothing appears on the screen as 'a' is considered a dead key if selected together with AltGr. Then release all keys and press, e.g.the letter 'e': on the screen an acute accent 'e', 'é' will appear. The following table provides a list of AltGr keys with their functional meaning. a: acute accent e.g.: AltGr+a+e = é d: dot over letter e.g.: AltGr+d+g = ġ g: grave accent e.g.: AltGr+g+a = à l: macron, sign of long vowels also used over some consonants (ā; ḡ) e.g.: AltGr+l+e = ē - (minus): minus diacritic below character (e.g. -

Python-Tcod Documentation Release 11.19.3 Kyle Stewart
python-tcod Documentation Release 11.19.3 Kyle Stewart Jan 22, 2021 Contents 1 Installation 3 1.1 Windows.................................................3 1.2 MacOS..................................................3 1.3 Linux (Debian-based)..........................................4 1.4 PyCharm.................................................4 1.5 Upgrading python-tcod..........................................4 1.6 Upgrading from libtcodpy to python-tcod................................4 1.7 Distributing................................................5 1.8 Python 2.7................................................5 2 Glossary 7 3 Changelog 9 3.1 Unreleased................................................9 3.2 11.19.3 - 2021-01-07...........................................9 3.3 11.19.2 - 2020-12-30...........................................9 3.4 11.19.1 - 2020-12-29...........................................9 3.5 11.19.0 - 2020-12-29........................................... 10 3.6 11.18.3 - 2020-12-28........................................... 10 3.7 11.18.2 - 2020-12-03........................................... 10 3.8 11.18.1 - 2020-11-30........................................... 10 3.9 11.18.0 - 2020-11-13........................................... 10 3.10 11.17.0 - 2020-10-30........................................... 11 3.11 11.16.1 - 2020-10-28........................................... 11 3.12 11.16.0 - 2020-10-23........................................... 11 3.13 11.15.3 - 2020-07-30..........................................