The CPU and Memory
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computer Organization
IT 110 Computer Organization From Week #1 to Week#7 IT 110 Page 1 Introduction: Why study computer organization? To be a professional in any field of computing today, one should not regard the computer as just a black box that executes programs by magic. All students of computing should acquire some understanding and appreciation of a computer system’s functional components, their characteristics, their performance, and their interactions… in order to structure a program so that it runs more efficiently on a real machine… [and] understand the tradeoff among various components such as CPU clock speed vs. memory size. What is a system? A system is a collection of components linked together and organized in such a way as to be recognizable as a single unit. What is an architecture? The fundamental properties, and the patterns of relationships, connections, constraints, and linkages among the components and between the system and its environment are known collectively as the architecture of the system. IT 110 Page 2 Elements of an information system architecture o Hardware o Software o Data o People o Networks Models for computation IT 110 Page 3 Models for computation o Abstraction of hardware as a programming language o Input/output o Arithmetic, logic, and assignment o Selection, conditional branching (if-then-else, if-goto) o Looping, unconditional branching (while, for, repeat-until, goto) Summary o Studying computer organization is important for any technology professional. o Information systems consist of components and links between them (hardware, software, data, people, networks). o Information systems can be viewed at varying levels of detail and abstraction. -

High Performance Decimal Floating-Point Units
UNIVERSIDADE DE SANTIAGO DE COMPOSTELA DEPARTAMENTO DE ELECTRONICA´ E COMPUTACION´ PhD. Dissertation High-Performance Decimal Floating-Point Units Alvaro´ Vazquez´ Alvarez´ Santiago de Compostela, January 2009 To my family A´ mina˜ familia Acknowledgements It has been a long way to see this thesis successfully concluded, at least longer than what I imagined it. Perhaps the moment to thank and acknowledge everyone’s contributions is the most eagerly awaited. This thesis could not have been possible without the support of several people and organizations whose contributions I am very grateful. First of all, I want to express my sincere gratitude to my thesis advisor, Elisardo Antelo. Specially, I would like to emphasize the invaluable support he offered to me all these years. His ideas and contributions have a major influence on this thesis. I would like to thank all people in the Departamento de Electronica´ e Computacion´ for the material and personal help they gave me to carry out this thesis, and for providing a friendly place to work. In particular, I would like to mention to Prof. Javier D. Bruguera and the other staff of the Computer Architecture Group. Many thanks to Paula, David, Pichel, Marcos, Juanjo, Oscar,´ Roberto and my other workmates for their friendship and help. I am very grateful to IBM Germany for their financial support though a one-year research contract. I would like to thank Ralf Fischer, lead of hardware development, and Peter Roth and Stefan Wald, team managers at IBM Deutchland Entwicklung in Boblingen.¨ I would like to extend my gratitude to the FPU design team, in special to Silvia Muller¨ and Michael Kroner,¨ for their help and the warm welcome I received during my stay in Boblingen.¨ I would also like to thank Eric Schwarz from IBM for his support. -

Fully Redundant Decimal Arithmetic
2009 19th IEEE International Symposium on Computer Arithmetic Fully Redundant Decimal Arithmetic Saeid Gorgin and Ghassem Jaberipur Dept. of Electrical & Computer Engr., Shahid Beheshti Univ. and School of Computer Science, institute for research in fundamental sciences (IPM), Tehran, Iran [email protected], [email protected] Abstract In both decimal and binary arithmetic, partial products in multipliers and partial remainders in Hardware implementation of all the basic radix-10 dividers are often represented via a redundant number arithmetic operations is evolving as a new trend in the system (e.g., Binary signed digit [11], decimal carry- design and implementation of general purpose digital save [5], double-decimal [6], and minimally redundant processors. Redundant representation of partial decimal [9]). Such use of redundant digit sets, where products and remainders is common in the the number of digits is sufficiently more than the radix, multiplication and division hardware algorithms, allows for carry-free addition and subtraction as the respectively. Carry-free implementation of the more basic operations that build-up the product and frequent add/subtract operations, with the byproduct of remainder, respectively. In the aforementioned works enhancing the speed of multiplication and division, is on decimal multipliers and dividers, inputs and outputs possible with redundant number representation. are nonredundant decimal numbers. However, a However, conversion of redundant results to redundant representation is used for the intermediate conventional representations entails slow carry partial products or remainders. The intermediate propagation that can be avoided if the results are kept additions and subtractions are semi-redundant in redundant format for later use as operands of other operations in that only one of the operands as well as arithmetic operations. -

Development of Atmega 328P Micro-Controller Emulator for Educational Purposes
Acta Univ. Sapientiae Informatica 12, 2 (2020) 159{182 DOI: 10.2478/ausi-2020-0010 Development of ATmega 328P micro-controller emulator for educational purposes Michal SIPOˇ Sˇ Slavom´ır SIMOˇ NˇAK´ IBM Slovakia, Ltd., branch office Koˇsice Technical University of Koˇsice Aupark Tower, Protifaˇsistick´ych Koˇsice,Slovak Republic bojovn´ıkov 11, Koˇsice, Slovak Republic email: [email protected] email: [email protected] Abstract. The paper presents some of our recent results in the field of computer emulation for supporting and enhancing the educational pro- cesses. The ATmega 328P micro-controller emulator has been developed as a set of emuStudio emulation platform extension modules (plug-ins). The platform is used at the Department of Computers and Informatics as a studying and teaching support tool. Within the Assembler course, currently, the Intel 8080 architecture and language is briefly described as a preliminary preparation material for the study of Intel x86 architecture, and the Intel 8080 emuStudio emulator module is used here. The aim of this work is to explore the possibility to enrich the course by introducing a more up-to-date and relevant technology and the ATmega is the heart of Arduino { a popular hardware and software prototyping platform. We consider the options to make the process of studying the assembly lan- guage principles more attractive for students and using the ATmega AVR architecture, which is broadly deployed in embedded systems, seems to be one of them. Computing Classification System 1998: K.3.2, C.1.0 Mathematics Subject Classification 2010: 68U20, 68M01 Key words and phrases: emuStudio, emulation, Atmega, Arduino 159 160 M. -

The Great Telecom Meltdown for a Listing of Recent Titles in the Artech House Telecommunications Library, Turn to the Back of This Book
The Great Telecom Meltdown For a listing of recent titles in the Artech House Telecommunications Library, turn to the back of this book. The Great Telecom Meltdown Fred R. Goldstein a r techhouse. com Library of Congress Cataloging-in-Publication Data A catalog record for this book is available from the U.S. Library of Congress. British Library Cataloguing in Publication Data Goldstein, Fred R. The great telecom meltdown.—(Artech House telecommunications Library) 1. Telecommunication—History 2. Telecommunciation—Technological innovations— History 3. Telecommunication—Finance—History I. Title 384’.09 ISBN 1-58053-939-4 Cover design by Leslie Genser © 2005 ARTECH HOUSE, INC. 685 Canton Street Norwood, MA 02062 All rights reserved. Printed and bound in the United States of America. No part of this book may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage and retrieval system, without permission in writing from the publisher. All terms mentioned in this book that are known to be trademarks or service marks have been appropriately capitalized. Artech House cannot attest to the accuracy of this information. Use of a term in this book should not be regarded as affecting the validity of any trademark or service mark. International Standard Book Number: 1-58053-939-4 10987654321 Contents ix Hybrid Fiber-Coax (HFC) Gave Cable Providers an Advantage on “Triple Play” 122 RBOCs Took the Threat Seriously 123 Hybrid Fiber-Coax Is Developed 123 Cable Modems -

Algorithms and Architectures for Decimal Transcendental Function Computation
Algorithms and Architectures for Decimal Transcendental Function Computation A Thesis Submitted to the College of Graduate Studies and Research in Partial Fulfillment of the Requirements for the degree of Doctor of Philosophy in the Department of Electrical and Computer Engineering University of Saskatchewan Saskatoon, Saskatchewan, Canada By Dongdong Chen c Dongdong Chen, January, 2011. All rights reserved. Permission to Use In presenting this thesis in partial fulfilment of the requirements for a Postgraduate degree from the University of Saskatchewan, I agree that the Libraries of this University may make it freely available for inspection. I further agree that permission for copying of this thesis in any manner, in whole or in part, for scholarly purposes may be granted by the professor or professors who supervised my thesis work or, in their absence, by the Head of the Department or the Dean of the College in which my thesis work was done. It is understood that any copying or publication or use of this thesis or parts thereof for financial gain shall not be allowed without my written permission. It is also understood that due recognition shall be given to me and to the University of Saskatchewan in any scholarly use which may be made of any material in my thesis. Requests for permission to copy or to make other use of material in this thesis in whole or part should be addressed to: Head of the Department of Electrical and Computer Engineering 57 Campus Drive University of Saskatchewan Saskatoon, Saskatchewan Canada S7N 5A9 i Abstract Nowadays, there are many commercial demands for decimal floating-point (DFP) arith- metic operations such as financial analysis, tax calculation, currency conversion, Internet based applications, and e-commerce. -
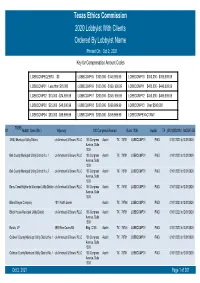
Texas Ethics Commission 2020 Lobbyist with Clients Ordered by Lobbyist Name Printed on Oct 2, 2021 Key for Compensation Amount Codes
Texas Ethics Commission 2020 Lobbyist With Clients Ordered By Lobbyist Name Printed On Oct 2, 2021 Key for Compensation Amount Codes LOBBCOMPEQZERO $0 LOBBCOMP05 $100,000 - $149,999.99 LOBBCOMP10 $350,000 - $399,999.99 LOBBCOMP01 Less than $10,000 LOBBCOMP06 $150,000 - $199, 999.99 LOBBCOMP11 $400,000 - $449,999.99 LOBBCOMP02 $10,000 - $24,999.99 LOBBCOMP07 $200,000 - $249, 999.99 LOBBCOMP12 $450,000 - $499,999.99 LOBBCOMP03 $25,000 - $49,000.99 LOBBCOMP08 $250,000 - $299,999.99 LOBBCOMP13 Over $500,000 LOBBCOMP04 $50,000 - $99,999.99 LOBBCOMP09 $300,000 - $349,999.99 LOBBCOMPEXACTAMT 70358 #1 Abbott, Sean (Mr.) Attorney 100 Congress Avenue Suite 1300 Austin TX (512)4352334 MODIFIED 3 B&J Municipal Utility District c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Bell County Municipal Utility District No. 1 c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Bell County Municipal Utility District No. 2 c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Berry Creek Highlands Municipal Utility District c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Blake Magee Company 1011 North Lamar Austin TX 78704 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Block House Municipal Utility District c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Bonzo, LP 3939 Bee Caves Rd. -

Microcomputers: NQS PUBLICATIONS Introduction to Features and Uses
of Commerce Computer Science National Bureau and Technology of Standards NBS Special Publication 500-110 Microcomputers: NQS PUBLICATIONS Introduction to Features and Uses QO IGf) .U57 500-110 NATIONAL BUREAU OF STANDARDS The National Bureau of Standards' was established by an act ot Congress on March 3, 1901. The Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research and provides; (1) a basis for the Nation's physical measurement system, (2) scientific and technological services for industry and government, (3) a technical basis for equity in trade, and (4) technical services to promote public safety. The Bureau's technical work is per- formed by the National Measurement Laboratory, the National Engineering Laboratory, and the Institute for Computer Sciences and Technology. THE NATIONAL MEASUREMENT LABORATORY provides the national system of physical and chemical and materials measurement; coordinates the system with measurement systems of other nations and furnishes essential services leading to accurate and uniform physical and chemical measurement throughout the Nation's scientific community, industry, and commerce; conducts materials research leading to improved methods of measurement, standards, and data on the properties of materials needed by industry, commerce, educational institutions, and Government; provides advisory and research services to other Government agencies; develops, produces, and -

History of Binary and Other Nondecimal Numeration
HISTORY OF BINARY AND OTHER NONDECIMAL NUMERATION BY ANTON GLASER Professor of Mathematics, Pennsylvania State University TOMASH PUBLISHERS Copyright © 1971 by Anton Glaser Revised Edition, Copyright 1981 by Anton Glaser All rights reserved Printed in the United States of America Library of Congress Cataloging in Publication Data Glaser, Anton, 1924- History of binary and other nondecimal numeration. Based on the author's thesis (Ph. D. — Temple University), presented under the title: History of modern numeration systems. Bibliography: p. 193 Includes Index. 1. Numeration — History. I. Title QA141.2.G55 1981 513'.5 81-51176 ISBN 0-938228-00-5 AACR2 To My Wife, Ruth ACKNOWLEDGMENTS THIS BOOK is based on the author’s doctoral dissertation, History of Modern Numeration Systems, written under the guidance of Morton Alpren, Sara A. Rhue, and Leon Steinberg of Temple University in Philadelphia, Pa. Extensive help was received from the libraries of the Academy of the New Church (Bryn Athyn, Pa.), the American Philosophical Society, Pennsylvania State University, Temple University, the University of Michigan, and the University of Pennsylvania. The photograph of Figure 7 was made available by the New York Public Library; the library of the University of Pennsylvania is the source of the photographs in Figures 2 and 6. The author is indebted to Harold Hanes, Joseph E. Hofmann, Donald E. Knuth, and Brian J. Winkel, who were kind enough to communicate their comments about the strengths and weaknesses of the original edition. The present revised edition is the better for it. A special thanks is also owed to John Wagner for his careful editorial work and to Adele Clark for her thorough preparation of the Index. -
Related Links History of the Radio Shack Computers
Home Page Links Search About Buy/Sell! Timeline: Show Images Radio Shack TRS-80 Model II 1970 Datapoint 2200 Catalog: 26-4002 1971 Kenbak-1 Announced: May 1979 1972 HP-9830A Released: October 1979 Micral Price: $3450 (32K RAM) 1973 Scelbi-8H $3899 (64K RAM) 1974 Mark-8 CPU: Zilog Z-80A, 4 MHz MITS Altair 8800 RAM: 32K, 64K SwTPC 6800 Ports: Two serial ports 1975 Sphere One parallel port IMSAI 8080 IBM 5100 Display: Built-in 12" monochrome monitor MOS KIM-1 40 X 24 or 80 X 24 text. Sol-20 Storage: One 500K 8-inch built-in floppy drive. Hewlett-Packard 9825 External Expansion w/ 3 floppy bays. PolyMorphic OS: TRS-DOS, BASIC. 1976 Cromemco Z-1 Apple I The Digital Group Rockwell AIM 65 Compucolor 8001 ELF, SuperELF Wameco QM-1A Vector Graphic Vector-1 RCA COSMAC VIP Apple II 1977 Commodore PET Radio Shack TRS-80 Atari VCS (2600) NorthStar Horizon Heathkit H8 Intel MCS-85 Heathkit H11 Bally Home Library Computer Netronics ELF II IBM 5110 VideoBrain Family Computer The TRS-80 Model II microcomputer system, designed and manufactured by Radio Shack in Fort Worth, TX, was not intended to replace or obsolete Compucolor II the Model I, it was designed to take up where the Model I left off - a machine with increased capacity and speed in every respect, targeted directly at the Exidy Sorcerer small-business application market. Ohio Scientific 1978 Superboard II Synertek SYM-1 The Model II contains a single-sided full-height Shugart 8-inch floppy drive, which holds 500K bytes of data, compared to only 87K bytes on the 5-1/4 Interact Model One inch drives of the Model I. -

The State Board of Education
THE STAte OF the RELIGIOUS RIGht { 2008 } THE STATE BOARD OF EDUCATION: DRAGGING TEXAS SCHOOLS INTO THE CULTURE WARS THE STAte OF the RELIGIOUS RIGht { 2008 } THE STATE BOARD OF EDUCATION: DRAGGING TEXAS SCHOOLS INTO THE CULTURE WARS A R E p ort f ro m the T exas f R E E D O m N etwor k E ducation f U N D kathy miller, TFN president Dan Quinn, TFN communications director Bren Gorman, researcher Judie Niskala, researcher Emily Sentilles, researcher A bout the T f N E ducation f U N D The Texas Freedom Network Education Fund is a 501(c)(3) tax-exempt, nonprofit corporation. Created in 1996, the TFN Education Fund researches the agenda, activities and funding of the religious right. It also educates mainstream people of faith in how to formulate and to advocate a faith-based response to the religious right’s policy agenda. TfN Education fund Board of Directors Rebecca Lightsey, chair Janis pinnelli, treasurer Rev. Dr. Larry Bethune Grace Garcia Diane Ireson Dale Linebarger Table Of Contents Introduction. .2. Watch List: 2008. .5 1: The State Board of Education in Texas. .11 2: A History of Censorship in Texas. .17 3: The Right Ascendant. 21 4: Targeting Curriculum Standards (TEKS). .25 Appendices Appendix A: Who’s Who in Texas Textbook Censorship . .30 Appendix B: Textbook Censorship in Texas: A Timeline. .32 Appendix C: Textbook Censorship in Texas: The Record. .35 Appendix D: They Really Said It: Quoting the Religious Right in 2007 .. .. .. .. .. .. .. ...36 Appendix E: Organizations of the Religious Right in Texas. -

The IA-32 Processor Architecture
The IA-32 processor architecture Nicholas FitzRoy-Dale Document Revision: 1 Date: 2006/05/30 22:31:24 [email protected] http://www.cse.unsw.edu.au/∼disy/ Operating Systems and Distributed Systems Group School of Computer Science and Engineering The University of New South Wales UNSW Sydney 2052, Australia 1 Introduction This report discusses the most common instruction set architecture for desktop microprocessors: IA- 32. From a programmer’s perspective, IA-32 has not changed changed significantly since its introduc- tion with the Intel 80386 processor in 1985. IA-32 implementations, however, have undergone dra- matic changes in order to stay competitive with more modern architectures, particularly in the area of instruction-level parallelism. This report discusses the history of IA-32, and then the architectural features of recent IA-32 im- plementations, with particular regard to caching, multiprocessing, and instruction-level parallelism. An archtectural description is not particularly useful in isolation. Therefore, to provide context, each as- pect is compared with analogous features of other architectures, with particular attention paid to the RISC-style ARM processor and the VLIW-inspired Itanium. 2 A brief history of IA-32 IA-32 first appeared with the 80386 processor, but the architecture was by no means completely new. IA-32’s 8-bit predecessor first appeared in the Datapoint 2200 programmable terminal, released in 1971. Under contract to produce a single-chip version of the terminal’s multiple-chip TTL design, Intel’s im- plementation, the 8008, was not included in the terminal. Intel released the chip in 1972.